
- 1我的世界创建服务器的应用,我的世界服务器怎么创建 我的世界服务器创建教程介绍...
- 2华为2288H V5服务器⽆法开机_华为2288h v5服务器显示888
- 3大模型在电商智能内容推荐中的应用
- 4FileNotFoundError: train: No labels found in xxx\train.cache, can not start training._no labels found in train.cache
- 5html动态爱心代码【附源码】_爱心代码html源码
- 6RocketMQ基本概念介绍_rocketmqlistener
- 7RabbitMQ — SpringBoot集成RabbitMQ消息队列原理及详细配置
- 8YOLOv8改进实战 | 更换主干网络Backbone(四)之轻量化模型MobileNetV3_yolov8轻量化
- 9Jmeter使用入门篇--Jmeter介绍_jmtermoon
- 10MSP430 G2553 F5529 单片机 IIC OLED显示 DHT11 温湿度 串口发送 室内温湿度检测仪_5529 iic读取数据
NeurIPS2023 大语言模型(LLM)方向优质论文汇总!_propile: probing privacy leakage in large language
赞
踩
2023最后一场AI行业大会NeurIPS已经结束了,这场盛会共接收了全球各地的3586篇优质论文,这些论文如今已全部在线上公开发表,展现出人工智能领域的最新研究成果。
大型语言模型(LLM)作为人工智能领域的重要分支,在NeurIPS 2023大会上,关于LLM的论文也有很多。今天特意从这些论文中整理出12篇大语言模型(LLM)优质论文分享给大家,看看LLM领域的最新研究成果和发展趋势!
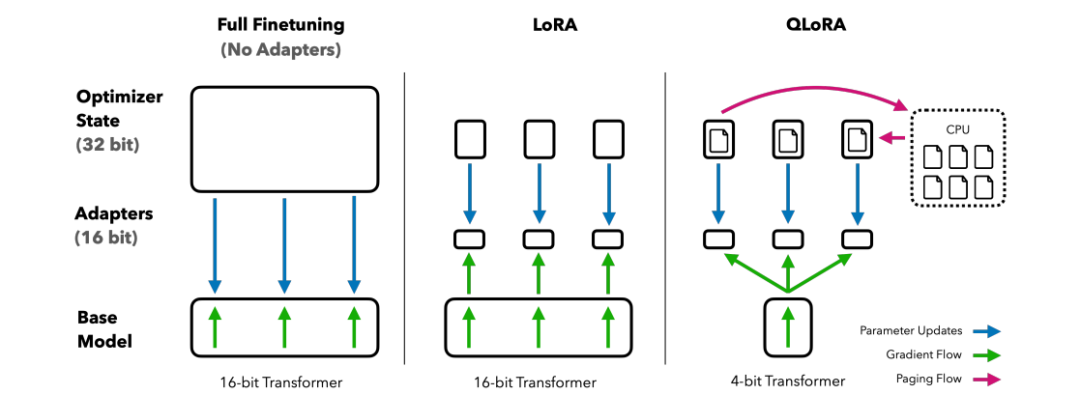
1、QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA:量化 LLM 的高效微调
简述:本文提出了一种用于LLMs的微调方法QLORA,可在单个48GB GPU上微调65B参数模型,同时保持高性能。QLORA的创新包括4位NormalFloat、双量化、分页优化器。研究人员微调了1000多个模型,结果表明,使用小型数据集的QLORA微调可获得最佳结果,即使使用较小的模型。
2、Direct Preference Optimization: Your Language Model is Secretly a Reward Model
直接偏好优化:你的语言模型暗地里是一个奖励模型
简述:本文中提出了一种新的奖励模型参数化方法,简化了强化学习从人类反馈(RLHF)问题的标准解决方案,把这种算法称为直接偏好优化(DPO),它稳定、高效,计算需求低,简化了微调过程。与现有方法相比,DPO在满足人类偏好方面同样出色或更优,特别是DPO在控制文本情感方面表现优异,并且在文本摘要和对话生成中提供了质量相当或更高的响应,同时更易于实现和训练。

3、DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
DoReMi:优化数据混合加速语言模型预训练
简述:本文中提出了DoReMi,一种在不了解下游任务的情况下为数据集生成域权重的新方法。研究人员使用Group DRO在小型代理模型上训练产生域权重,再重采样数据集训练大型模型。实验显示,DoReMi在280M参数模型上优化,更有效地训练8B模型,并在The Pile和GLaM数据集上显著提高模型性能。

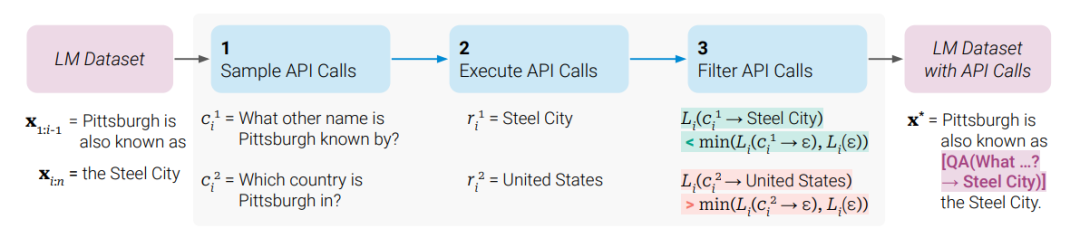
4、Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer:语言模型可以自学使用工具
简述:本文提出了Toolformer,一种被训练用来决定何时调用哪些API,传递什么参数,以及如何最有效地将结果融入未来的令牌预测。这通过自我监督方式完成,每个API只需几个演示。文中整合了计算器、问答系统、搜索引擎、翻译系统和日历等工具,Toolformer在各种下游任务中实现了零样本性能提升,且不牺牲核心语言建模能力,可与更大规模的模型竞争。
5、ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
ToolkenGPT:通过工具嵌入使用海量工具增强冻结语言模型
简述:本文中提出了一种名为ToolkenGPT的方法,它将工具以toolken的形式嵌入到LLMs中。这允许模型以生成文本的方式调用工具,并灵活地扩充新工具。通过大量演示数据优化工具令牌的应用,在多个领域如数字推理和问答系统中,ToolkenGPT有效增强了LLMs的能力,并明显优于现有基准。此方法在复杂场景中选择并使用合适工具展现出巨大潜力。

6、Scaling Data-Constrained Language Models
缩放数据约束语言模型
简述:本文中提出并实证验证了计算最优性的缩放定律,该定律解释了重复标记和多余参数的递减值,并尝试了缓解数据稀缺性的方法,包括使用代码数据增强训练数据集或删除常用过滤器。

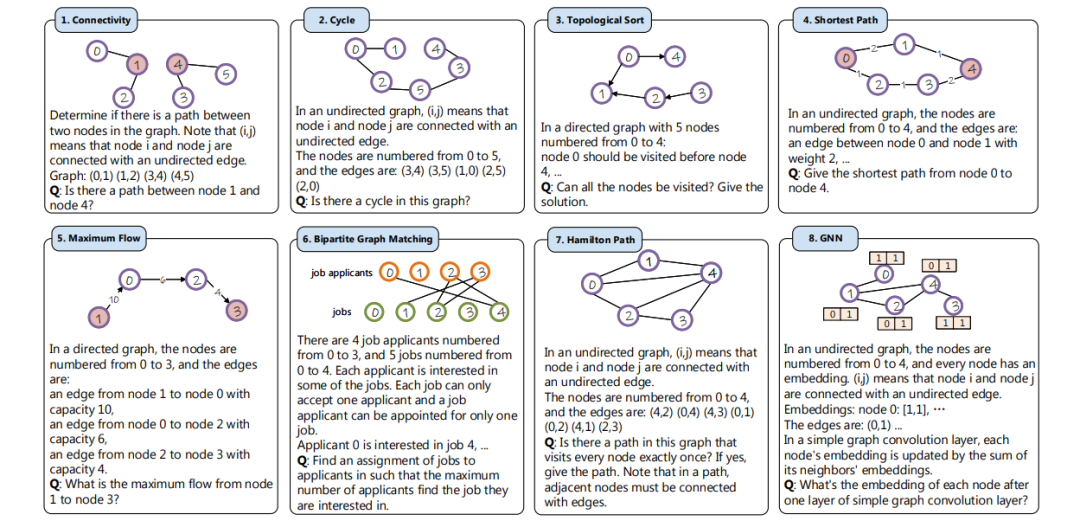
7、Can Language Models Solve Graph Problems in Natural Language?
语言模型可以解决自然语言中的图问题吗?
简述:文中提出了NLGraph,一个基于自然语言的图形问题解决全面基准测试,包含多种难度的29,370个图形推理任务。在NLGraph上的评估显示,大型语言模型(LLMs,如GPT-3/4)在图形推理方面有初步能力,但在复杂任务上表现出局限性。文中提出了基于指令的构建图形提示和算法提示方法,提高了LLMs在这些任务上的表现。
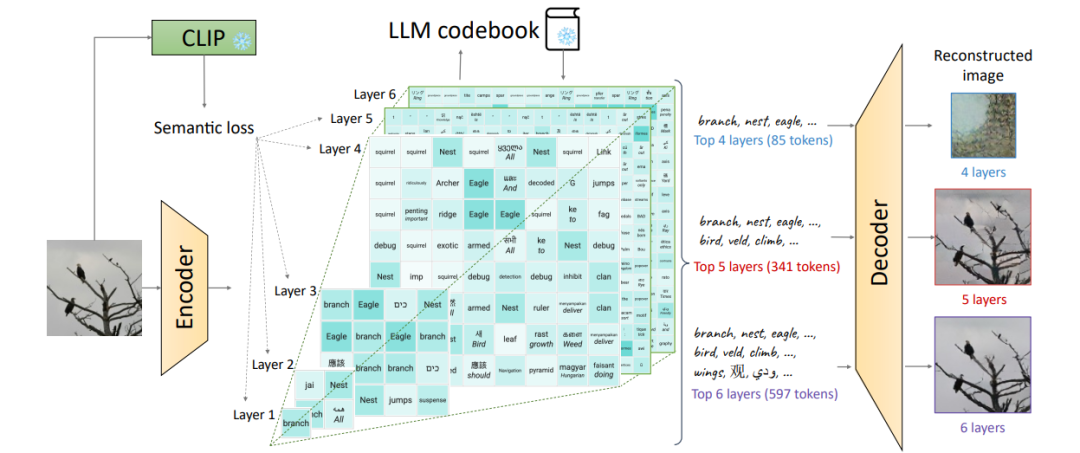
8、SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
SPAE:语义金字塔自动编码器,用于使用冻结 LLM 生成多模态
简述:本文中提出了语义金字塔自编码器(SPAE),它让固定的LLMs能处理包含图像或视频的非语言模态的理解和生成任务。SPAE实现了原始像素与LLM词汇表中词汇标记之间的转换,使得视觉内容能被LLM理解并用于多模态任务。这种方法在多个图像理解和生成任务中验证了其有效性,使被冻结的LLM在生成图像内容方面取得了突破,同时在理解任务上的性能提高了25%。
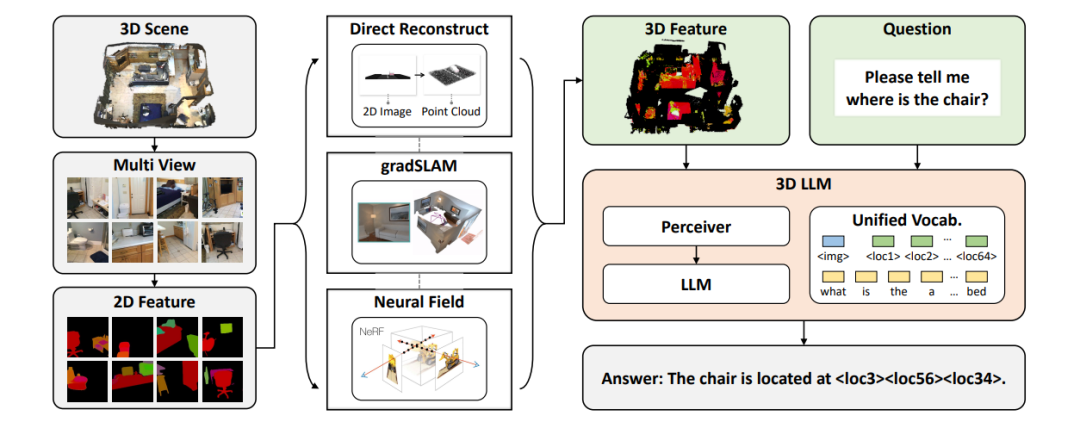
9、3D-LLM: Injecting the 3D World into Large Language Models
3D-LLM:将 3D 世界注入大型语言模型
简述:本文中提出了将三维世界整合到大型语言模型中的新概念,形成了三维LLMs。这些模型可以处理三维点云数据,执行包括三维标注、问答和对话等多种三维任务。通过设计的提示机制,研究人员收集了超过30万的三维语言数据,并使用二维视觉-语言模型作为训练基础。在实验中,这个模型在捕获三维空间信息方面显著超越现有技术,并在多个三维任务上表现优异。
10、QuIP: 2-Bit Quantization of Large Language Models With Guarantees
QuIP:大型语言模型的 2 位量化,有保证
简述:本文中提出了基于权重和Hessian矩阵不协调性优化量化的新方法QuIP。QuIP采用自适应舍入和随机正交矩阵预后处理两个步骤,通过理论分析和实证验证,证明了该方法和现有方法OPTQ的有效性,QuIP能使用每个权重仅两位实现有效的LLM量化。

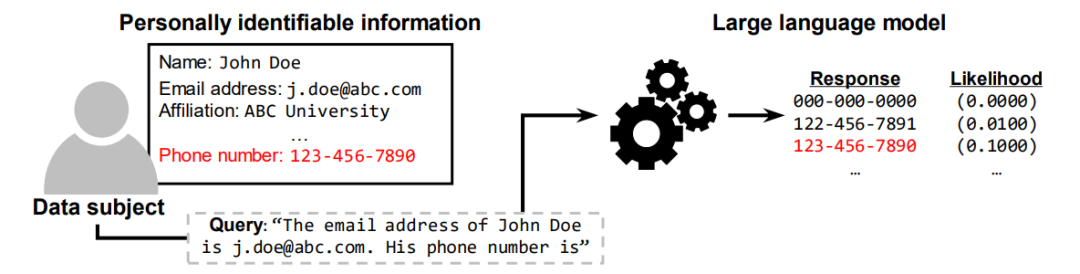
11、ProPILE: Probing Privacy Leakage in Large Language Models
ProPILE:探测大型语言模型中的隐私泄漏
简述:本文中提出了一种新型探测工具ProPILE,为了帮助数据主体发现LLM服务中的潜在PII泄露。该工具允许用户根据自己数据制定提示,评估隐私风险。文中展示了ProPILE在OPT-1.3B模型上的应用,该模型基于公开Pile数据集。同时,LLM服务提供商可以使用ProPILE来评估和控制PII泄露,这一工具为数据主体提供了网络数据控制的新方法。
12、Parsel
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

