
- 1一位计算机专业硕士毕业生的求职经历和感想_计算机研究生毕业后搞代码
- 2C#读写EXCEL(OLEDB方式)_c#中oledb的详细使用
- 3Qt入门小项目 超详细注释 附源码_qt 小项目
- 42024年Go最全Golang 游戏架构简介_golang分布式游戏框架,超全Golang中高级面试复习大纲_golang游戏服务器框架
- 5macos brew安装多版本protobuf,切换指定版本protobuf 为默认版本方法_brew指定版本安装
- 6[附源码]JAVA+ssm网络调查问卷系统(程序+Lw)_java网络编程网络调查
- 7HTTP、HTTPS 加密过程_http请求加密
- 8第31篇-SAP MRP最小安全库存和服务水平的研究学习、思考_sap里service level
- 9aurora和pcie的异同点,哪个更适合用作芯片间传输协议?_aurora总线
- 10如何下载android studio的历史版本_android studio历史版本下载
揭秘OpenAI新巨作Sora:技术报告全解析+训练流程_sora模型训练流程
赞
踩
最近,OpenAI再次以其令人瞩目的成就——Sora——震撼了世界。这个名为Sora的大型文本到视频模型,能够生成长达一分钟的视频,预示着一个更加宏大征程的开始。OpenAI将这一创新描述为构建“物理世界的通用模拟器”,这不仅是一项技术突破,也是探索人工智能潜力的一次大胆尝试。 在这篇博客中,我对OpenAI发布的Sora技术报告进行了深入的解读。我努力在保证内容全面性的同时,使其易于快速阅读,力图达到与官方技术报告相似的效果。为此,我还包含了大部分官网上的视频素材,使读者能够更直观地感受到Sora的强大能力。 在博客的最后,我也简单分享了自己对这一技术革新的看法。从对现实世界的精准模拟到未来可能的应用前景,Sora无疑开启了人工智能领域的一个新篇章。我们正处于这一变革的前沿,见证着人工智能如何逐渐成为我们生活中不可或缺的一部分。—— AI Dream,APlayBoy Teams!
引言解读
-
探索视频数据上的大规模生成模型训练:OpenAI在这部分强调了他们在视频数据上进行生成模型的大规模训练的努力。这表明了对动态和复杂数据类型的投入,突破了以往大多数研究仅限于静态图像的范畴。
-
多样性视频和图像生成的文本条件扩散模型:该模型不仅能够处理多种格式和尺寸的视频和图像,还能够根据文本条件生成相应的内容。这一点显示了模型在理解和生成内容方面的强大能力,尤其是在处理多种类型媒体时的灵活性。
-
采用Transformer架构处理视频和图像的时空信息:此处还提到了利用Transformer结构,可以处理视频和图像的时空数据。这种架构的引入对于理解视频内容的动态变化至关重要。
-
Sora模型:Sora模型可以高效生成高质量视频,强调了其在生成长达一分钟的高保真视频方面的能力。这显示了OpenAI在提高视频生成质量和时长方面取得的显著进展。
-
视频生成模型的未来:即,向通用物理世界模拟器迈进。这展望了扩展视频生成模型在未来模拟物理世界方面的潜力。
介绍解读

-
统一视觉数据表示法与大规模生成模型训练:报告首先聚焦于如何将各类视觉数据转化为统一的表示形式,这是实现生成模型大规模训练的关键。通过这种统一表示,模型能够更有效地学习和生成多样化的视觉内容。
-
Sora能力与局限性的定性评估:报告第二部分关注于定性评估Sora模型的能力和局限性。这意味着报告将展示Sora在实际应用中的表现,但不包括具体的模型和实现细节。
-
先前研究与Sora的比较:这部分还提到了先前在视频数据生成模型方面的研究,包括使用循环网络、生成对抗网络、自回归 Transformer 和 Diffusion Model 的方法。这些研究通常专注于特定类型的视觉数据、较短视频或固定尺寸的视频。相比之下,Sora作为一个通用的视觉数据模型,能够生成时长、宽高比和分辨率各异的视频和图像,甚至能够生成长达一分钟的高清视频。
实现说明
将视觉数据转化为patches
-
灵感来源于大型语言模型:这一部分指出,Sora模型的设计灵感来源于大型语言模型(LLM),LLM通过在大规模的互联网数据上进行训练来获得通用能力。大型语言模型的成功部分得益于它们使用的代表不同文本模态(如代码、数学和各种自然语言)的标记(tokens)。Sora模型试图将这种成功应用到视觉数据生成模型中。
-
Sora的视觉patches:在Sora模型中,对应于语言模型的文本标记的是视觉patches。之前的研究已经证明,视觉patches是一个有效的视觉数据模型表示形式。Sora模型采用视觉patches作为其核心表示手段,以处理多样化的视频和图像数据。

-
视频转化为patches的过程:在高层次上,Sora模型将视频转化为patches的过程包括两个步骤:首先将视频压缩到一个低维的潜在空间,然后将这个表示分解为时空patches。这种方法允许模型有效地处理视频数据,捕捉视频的动态特性和细节。
视频压缩网络
-
视觉数据降维的训练网络:报告介绍了一个专门用于降低视觉数据维度的网络。这个网络的作用是接收原始视频作为输入,并输出一个在时间和空间上都被压缩的潜在表示。这一步骤对于处理大规模视频数据至关重要,因为它减少了所需处理的数据量,同时保留了视频的关键信息。
-
Sora在压缩潜在空间中的训练和生成:Sora模型不仅可以在这种压缩的潜在空间上进行训练,而且还在这个空间内生成视频。这意味着Sora学习并模拟了视频数据的压缩表示,这是其处理和生成高质量视频的关键。
-
对应的解码器模型:报告还提到了一个对应的解码器模型,它负责将生成的潜在表示映射回像素空间。这个解码器是生成过程的关键部分,因为它使模型能夠将压缩的视频数据转换回可视的、高质量的视频格式。
时空潜在patches
-
从压缩视频中提取时空patches序列:给定一个压缩后的输入视频,Sora模型从中提取出一系列时空patches,这些patches在模型中的作用类似于变换器(transformer)的标记(tokens)。这种方案同样适用于图像,因为图像可以被视为只有单帧的视频。这种基于patches的表示使得Sora能够处理不同分辨率、时长和宽高比的视频和图像。
-
利用patches控制生成视频的大小:在推理(inference)阶段,可以通过在一个适当大小的网格中排列随机初始化的patches来控制生成视频的大小。这意味着Sora能够灵活生成不同大小和格式的视频,为视频生成提供了更多的控制和自定义选项。
扩展Transformer并用于视频生成
-
Sora是一个扩散模型:如下图,它接收带有噪声的patches(以及诸如文本提示之类的条件信息)作为输入,被训练来预测原始的“干净”patches。

-
Sora是一个扩散transformer:Transformer在多个领域已展现出显著的扩展能力,包括语言建模、计算机视觉和图像生成。在这项研究中,发现扩散transformer同样有效地作为视频模型,具体细节参考 Scalable Diffusion Models with Transformers。报告中还展示了一个比较(见下面的3个视频,从上到下分别为基础计算量、4倍计算量、32倍计算量的效果),说明在训练过程中,使用固定种子和输入的视频样本质量随着训练计算量的增加而显著提高。



可设置视频时长、分辨率、宽高比
在图像和视频生成的传统方法中,通常将视频调整为标准尺寸,例如4秒长的256x256分辨率视频。然而,技术报告指出,在其原始尺寸上训练视频带来了多种好处。
-
采样的灵活性:Sora能够生成多种尺寸和比例的视频,如宽屏1920x1080p和竖屏1080x1920视频。这意味着Sora可以直接为不同设备生成符合其原生宽高比的内容,并且在全分辨率生成之前,以较低尺寸快速原型化内容,所有这些都可以通过同一个模型完成,分辨率对比视频可截图参见下图。

-
改善视频构图和取景:技术报告中提到,通过在视频的原生宽高比上进行训练,可以改进视频的构图和取景。报告比较了Sora和一个将所有训练视频裁剪为正方形的模型版本。结果显示,采用正方形裁剪的模型有时会生成主题只部分在视野内的视频。而Sora生成的视频则在构图上表现得更好。

语言理解
-
语言理解在视频生成中的应用:训练文本到视频的生成系统需要大量带有对应文字说明的视频。技术报告中提到,他们采用了在DALL·E 3中引入的重新标注技术应用于视频。首先训练一个高度描述性的字幕模型,然后用它为训练集中的所有视频生成文字说明。研究发现,使用高度描述性的视频字幕进行训练可以提高文本的保真度以及视频的整体质量。
-
利用GPT生成详细字幕:类似于DALL·E 3,报告中也提到了利用GPT将简短的用户提示转换成更长、更详细的字幕,然后发送给视频模型。这使得Sora能够生成高质量的视频,这些视频能够精准地遵循用户的提示。这表明Sora在处理文本和视频内容的融合方面具有高度的灵活性和准确性。
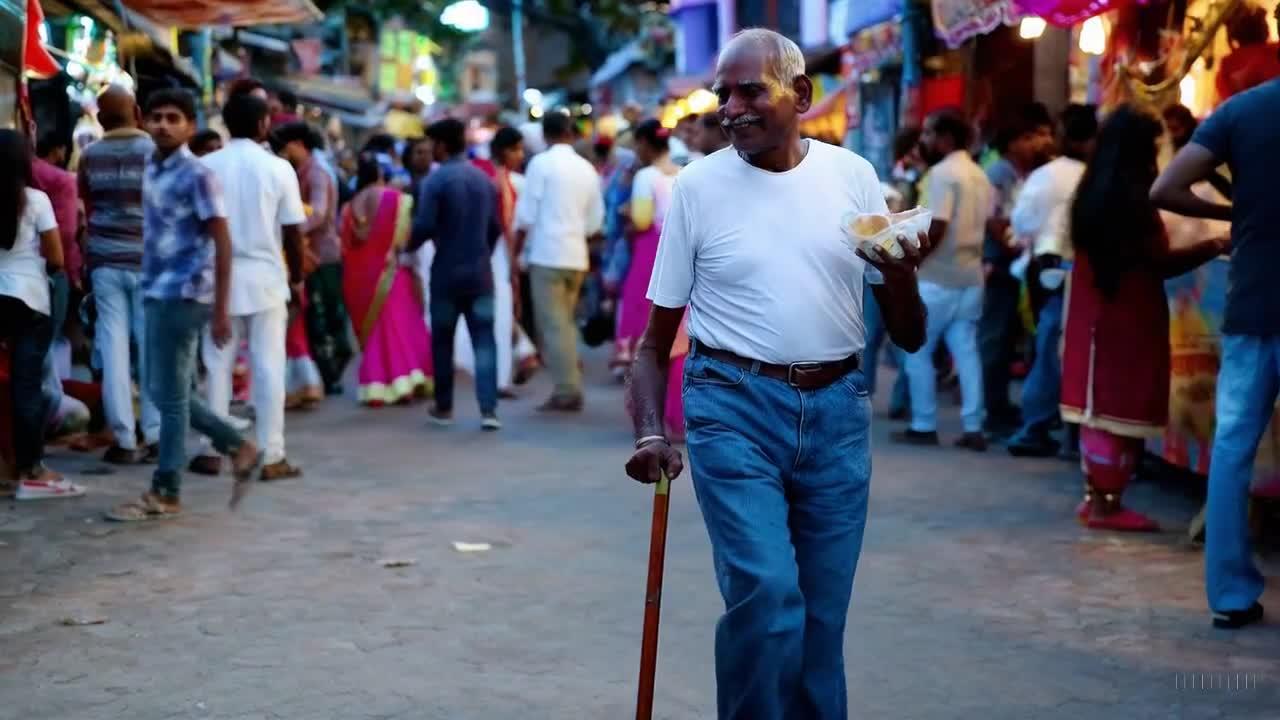
上面视频提示词:在印度孟买的一个多彩节日中,一个穿着蓝色牛仔裤和白色T恤的老人在愉快地散步

上面视频的提示词为:一个可爱的袋鼠穿着蓝色牛仔裤和白色T恤,在南非约翰内斯堡的冬季风暴期间愉快地散步
训练流程
根据上面官方给出的技术细节,我猜测Sora的训练流程如下:
-
收集视频数据与标注信息:Sora的过程开始于大量的视频数据收集。这些数据中,一部分视频已经有了标注信息,而另一部分则没有。
-
训练图片描述模型:对于那些没有标注的视频,Sora通过训练一个专门的图片描述模型来生成视频的描述。这个模型能够观察视频画面并自动生成描述文字,补充缺失的标注信息。
-
使用GPT-4丰富视频描述:为了使视频描述更加详细和丰富,Sora还利用了GPT-4。GPT-4在这里发挥作用,通过扩展和深化这些自动生成的描述以及已经标注的描述,使之更为完整和细致。
-
切分成视频Patches:处理好的视频数据随后被切分成小块,称为“视频Patches”。这使Sora能够专注于视频的每一个细节部分,有助于后续更精确的学习和生成。
-
应用视频压缩网络:切分后的视频Patches接着被送入视频压缩网络。这一过程将视频数据转换并压缩到一个高效的潜在空间中,便于后续的处理和学习。
-
潜在空间的视频数据:在潜在空间中,Sora拥有了用于生成新视频的压缩视频数据。
-
应用扩散模型进行视频生成:Sora使用Transformer结构的扩散模型在潜在视频的空间上进行训练,训练过程的输入是之前标注的文本描述,输出是视频的潜在空间中的压缩数据。
-
强大的硬件支持:整个过程依赖于强大的计算资源和硬件支持,这为处理大规模的数据和运行复杂的模型提供了必要的计算能力。
使用图像和视频进行提示
报告中提到的所有结果,以及其登陆页面上展示的样本,都是文本到视频的示例,部分视频我在博客中也做了复制和截图。但Sora也可以通过其他输入进行提示,例如预先存在的图像或视频。这一能力使Sora能够执行广泛的图像和视频编辑任务,如创建完美循环的视频、为静态图像添加动画、将视频向前或向后延伸等。
为DALL·E图像添加动画
Sora具备了基于图像和提示输入生成视频的能力。接下来展示了一些例子,这些视频是基于DALL·E 2和DALL·E 3生成的图像。这表明Sora不仅能够处理纯文本提示,还能将现有的静态图像转化为动态视频,增加了视觉内容的动态表现和互动性。具体实例如下面几个视频:

提示图片:视频封面;提示词:戴贝雷帽和黑色高领衫的柴犬狗。

提示图片:视频封面;提示词:扁平设计风格的怪物插图,包括毛茸茸的棕色怪物、带触角的黑色怪物、有斑点的绿色怪物和一个带小圆点的小怪物,它们在一个欢乐的环境中互动。

上传视频封面
好的标题可以获得更多的推荐及关注者
提示图片:视频封面;提示词:一张写着“SORA”的真实云朵图片。

上传视频封面
好的标题可以获得更多的推荐及关注者
提示图片:视频封面;提示词:在一座华丽的历史大厅中,一股巨大的潮汐浪尖峰并开始破碎。两名冲浪者抓住机会,熟练地驾驭着浪潮的表面。
扩展生成视频的时间轴
Sora具有向前或向后延伸视频时间的能力。接下来展示了3个视频(我这里截取了三帧做对比),这些视频都是从一个生成的视频片段开始向后延伸的。因此,虽然这三个视频的起始点各不相同,但它们最终都会汇聚到同一个结尾。这显示了Sora在视频时间编辑方面的高度灵活性和创造力,能够为现有视频内容增添新的维度和视角。

三个视频起始点不同

三个视频中间不同

三个视频结束点相同
同样,可以使用这种方法将视频向前和向后延伸,以产生一个无缝的无限循环。由于博客平台的文件数量限制,这里不在复制官网视频。
视频到视频编辑
扩散模型已经促进了许多通过文本提示编辑图像和视频的方法的发展。报告中提到了将其中一种方法,即SDEdit,应用到Sora上。这项技术使得Sora能够零次射击(zero-shot)地转换输入视频的风格和环境。这意味着Sora能够在没有先前样本或额外训练的情况下,直接对视频进行风格和环境上的变化,展示了在视频编辑领域的强大灵活性和创新能力。

用视频编辑视频效果截图
拼接视频
Sora还可以用来逐渐插值两个输入视频之间,创造出完全不同主题和场景构成的视频之间的无缝过渡。在下面的例子中,中间的视频是左右两边对应视频之间的插值结果。这表明Sora不仅能够生成或编辑单一视频,还能够将不同的视频内容巧妙地融合在一起,创造出全新的、流畅的视觉叙事体验。

中间的视频是左右两边对应视频之间的插值结果,此处是截图
图像生成能力
Sora同样具备生成图像的能力。这是通过在具有一个时间帧的空间网格中排列高斯噪声的patches来实现的。该模型能够生成不同尺寸的图像,分辨率最高可达2048x2048。这说明Sora不仅在视频生成领域表现出色,也能在静态图像生成上展现其强大的能力,尤其是在处理高分辨率图像时。

不同提示词下生成效果展示
新兴的模拟能力
在大规模训练时,视频模型展现出一些有趣的新兴能力。这些能力使Sora能够模拟现实世界中的人、动物和环境的某些方面。这些特性并非因为对三维、对象等的明确归纳偏见而产生,它们纯粹是规模效应的现象。
-
3D一致性:Sora能够生成具有动态摄像机移动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中保持一致性地移动。

这里是张截图,原视频的左侧为随着人物移动而跟拍,右侧则展示了高空旋转的镜头。
-
长期连贯性和对象永久性:视频生成系统的一个重大挑战一直是在采样长视频时保持时间上的连贯性。研究发现Sora通常能够有效地模拟短期和长期依赖关系。例如,模型可以在人物、动物或对象被遮挡或离开画面时仍然保持其存在。同样,它可以在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。

这里是张截图,原左侧视频显示行人不断遮挡着狗和窗户,但视频仍然保持一致。右侧视频展示了机器人在多个场景中变换,但其外观始终保持一致。
-
与世界互动:Sora有时能够模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下随时间持久的新笔触,或者一个人吃汉堡时留下咬痕。

这里是张截图,原左侧视频展示了画家可以在画布上留下随时间持久的新笔触,右侧视频则呈现了一个人吃汉堡时留下的咬痕。
-
模拟数字世界:Sora还能模拟人造过程——例如视频游戏。Sora可以在同时控制《Minecraft》中的玩家并以高保真度渲染世界及其动态。这些能力可以通过提及“Minecraft”等字样的提示词零次射击(zero-shot)地激发出来。

模拟了两个游戏的场景(个人不了解这个游戏)
这些能力表明,持续扩大视频模型的规模是朝着开发高能力的物理和数字世界模拟器以及其中的对象、动物和人类的有希望的途径。
讨论
-
Sora的局限性:尽管Sora展现了许多作为模拟器的潜力,但它目前仍存在一些限制。例如,Sora并不能准确地模拟许多基本互动的物理效应,如玻璃破碎。其他互动,比如吃食物,也不总是能够正确地反映对象状态的变化。报告中还列举了模型的其他常见失败模式,例如在长时间样本中出现的不连贯性或物体的突然出现,这些都在他们的登陆页面中有详细描述。

原视频是玻璃杯碎的过程,视频中玻璃杯没碎,但液体先流了出来,和现实不符合
-
Sora的未来发展方向:尽管如此,研究团队相信Sora目前所具备的能力表明,继续扩大视频模型的规模是发展能够模拟物理和数字世界及其中的对象、动物和人类的有力途径。这表示,尽管当前存在局限性,但Sora在未来的发展和提升仍有巨大潜力,特别是在进一步提高模拟真实世界复杂互动和动态环境方面。
读后感
模型效果与训练数据
-
模型的效果令人印象深刻,展现了OpenAI在这一领域的快速发展。关于训练数据,虽然细节未公开,但似乎包含了大量的网络视频和游戏引擎数据,以及YouTube等平台的素材。
视频数据标注技术
-
利用GPT将用户提示转换成详细字幕的方法使得Sora能够生成高质量的视频,精准地遵循用户的提示。这体现了Sora在融合文本和视频内容方面的高度灵活性和准确性。
技术创新与挑战
-
Sora的技术基础包括transformer、视频patches和diffusions等,这些技术之前已经具备了,结合了更强大的算力和丰富的训练数据。这些因素共同推动了其在视频领域的创新应用。
其他公司的跟进可能性
-
OpenAI在算力、资金和技术方面的先发优势,特别是利用GPT-4生成大量视频标注数据的能力,为其在视频生成领域的领先地位奠定了基础。这些优势构成了其他公司难以快速跨越的门槛。
深入Sora
-
了解Sora的更多细节可以看我的另一篇博客:深入剖析Sora原理:细节解读与技术洞见
-
了解Sora的核心工作可以看我的博客:DiT: Scalable Diffusion Models with Transformers 全文解读
更多相关工作
-
imporoved-deffusion: Improved Denoising Diffusion Probabilistic Models
-
Guided-diffusion: Diffusion Models Beat GANs on Image Synthesis
-
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion
-
DALL-E2: Hierarchical Text-Conditional Image Generation with CLIP Latents
-
CLIP:Learning Transferable Visual Models From Natural Language Supervision
-
ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
-
Stable diffusion: High-Resolution Image Synthesis with Latent Diffusion Models Robin
-
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
-
Sora的核心工作DiT: Scalable Diffusion Models with Transformers 全文解读
在这篇AI探索之旅尾声,感谢每一位读者的陪伴,如果大家有疑问、见解,欢迎留言、讨论。您的点赞和关注是我持续分享的动力。APlayBoy,期待与您一起在AI的世界里不断成长!

