
- 1大专生如何进大厂?_专科毕业怎么进大厂
- 2三分钟教你Mac下安装VmWare虚拟机_mac虚拟机
- 3python编译成c语言-cython编译Python为c语言
- 4如何在ubuntu18.04下安装Firefox中国版解决Ubuntu与Windows下Firefox账号同步问题(已解决)_ubuntu 1804下载火绒
- 5Linux:超级管理员(root用户)创建用户、用户组_linux创建管理员用户root
- 6Python 测试框架之 pytest框架详解_python test框架
- 7UCAS - AI学院 - 自然语言处理专项课 - 第10讲 - 课程笔记_xinshuai dong ucas
- 8讲真,一位8 年 Java 经验大牛的面试总结,你照猫画虎还怕收不到offer?_8年java经验面试都问啥
- 9数据结构和算法学习之路——堆排序(C++)_用筛选法将该序列构建小顶堆,并将最小元素输出后的剩余元素调整为堆,以完全二叉树
- 10大智能:大数据+大模型+大算力_大算力大数据大模型
大数据分析模型--批处理和流处理_大数据批处理
赞
踩
1.摘要
大数据和大数据分析的独特性引发了前所未有的研究呼吁。对于研究人员和从业人员来说,在正确的信息和大数据分析工具方面存在巨大的知识差距。该文对大数据分析模型工具批处理、流处理进行了全面调查。
大数据分析已开始在当今的工业活动中获得广泛关注,并迅速改变对商业理念的看法。组织业务的成功取决于数据,这些数据被提取、处理,其结果价值被转化为信息。大数据本质上跨越了教育、医疗保健、石油和天然气行业、金融、国家安全等各个领域的广度等。此外,大数据分析还为提升行业绩效带来了主动性、创新性和实践性。此外,随着最近向工业4.0的转变,结合传感器、物联网(IoT)和智能数据分析来改变工业产出,大数据分析方法发挥了关键作用。
2.Hadoop生态系统
Hadoop是一种用于大数据处理和管理的重要软件分发方法。Hadoop生态系统为在不同环境中生成的数据的存储和大规模处理提供支持。Hadoop生态系统的标准架构如图1所示,由基于Java的框架和异构开源程序组成,唯一地址用于企业大数据的操作系统(OS)。此外,异构行业和组织产生的数据是广泛而通用的,因此,创建Hadoop是为了处理、存储和管理大量的数据。此外,Hadoop是一个开源和分布式处理框架,用于组织和存储在集群系统中运行的大数据,它涉及包含Hadoop分布式文件系统(HDFS)和MapReduce计算范式的简单编程。
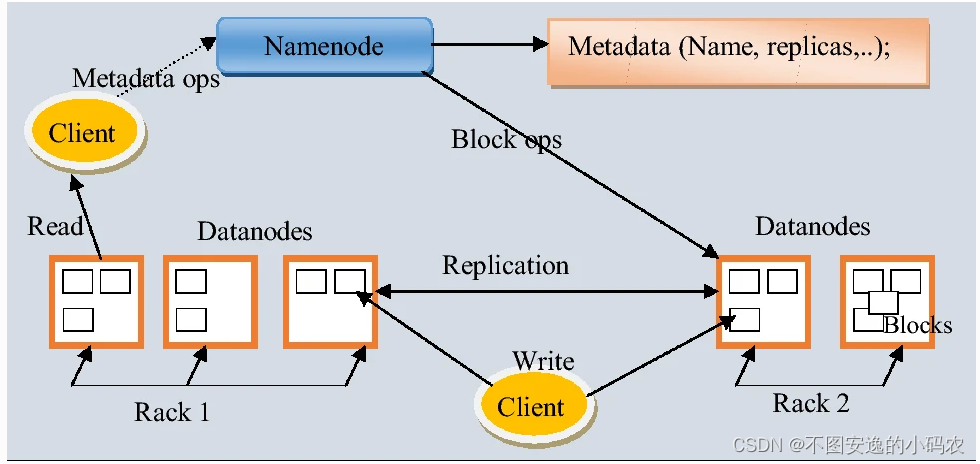
图1 Hadoop通用架构
Hadoop生态系统支持的各种数据技术包括数据挖掘、预测分析和机器学习应用程序,它们是大数据生态系统的核心技术。此外,Hadoop生态系统高效灵活,用户可以收集、分析和处理从数据仓库和关系数据库链接的数据,从而防止数据丢失。此外,Hadoop具有HDFS支持的数据复制和主从功能。Hadoop生态系统的其他特性包括高功率计算、低成本框架、灵活性与可扩展性、容错能力。
Hadoop生态系统由多个功能部分组成,即:NameNode、DataNode和Clients。NameNode和DataNode都是设计用于在安装了GNU/Linux操作系统的商品机器上运行的软件。Hadoop生态系统分为三个组件,即HDFS、HadoopYARN、HadoopCommon——提供文件系统和操作系统级别抽象的Java库和实用程序,以及Hadoop启动所需的其他脚本。
2.1Hadoop分布式文件系统(HDFS)
HDFS是一种数据存储系统,具有对应用程序的高吞吐量访问。此外,友好、可靠且经济高效地提供支持集群中多达100个节点的能力和特性。HDFS具有出色的存储结构化、半结构化和非结构化数据的能力,并且可以存储高达TB或更多的文件。尽管如此,HDFS并不构成多用途文件系统,因为其核心设计是处理四个基本目标,高延迟操作批处理、故障检测和恢复、庞大的数据集和数据硬件。因此,不提供文件中的快速记录查找,HDFS的优势在于其跨异构软件和硬件平台兼容性的可移植性。此外,HDFS提供了一种机制,通过将计算移动到数据存储附近来提高系统性能,从而最大限度地减少网络拥塞。
最新数据驱动行业的大数据分析实施的其他大数据存储和处理平台包括:
- HBase是分布式和非关系型数据库,它基于面向列的值数据模型提供可扩展且高效的大数据存储。此外,HBase在Hadoop和HDFS之上利用类似于BigTable的能力存储和处理大数据的随机、实时读/写访问。
- MongoDB是一个用C++构建的跨平台和开源项目。此外,它是一个面向文档的数据库,提供基于JSON文档并由BSON提供服务的数据模型,具有高性能、高可用性和易于扩展的特点。
- GoogleBigTable的创建是为了支持需要大规模可扩展性和不断迭代的应用程序。数据存储因其众所周知的处理分布式、面向列的数据存储和大量非结构化数据的能力而受欢迎。因此,GoogleBigTable对于处理Google的互联网搜索和网络服务操作非常重要。
- Cassandra是分布式数据库管理系统和开源的基于列的NoSQL数据库之一,用于存储数据。它提供了分布商用服务器的垂直面向的表,从而确保高持续的数据访问,没有单点故障。
- CouchDB是为存储JSON文档而开发的大数据存储和处理平台之一。适用于必须随时间存储和更改的许多不同的数据类型和结构。例如,当一个新的数量被设置为校准时,它可以从某个时间开始存储,而无需更改现有的文档。
2.2 HadoopYARN
YARN是管理资源和集群的作业调度的Hadoop生态系统组件。它旨在在低成本硬件上运行。与MapReduce进行数据处理相比,YARN更通用。因此,YARN被构建为一个集中的资源管理器,其中的节点管理器负责个人计算节点,向中央资源管理器报告专门针对单个集群的节点。
- YARN具动态地向每个客户端报告应用程序,其中包含应用程序状态的详细信息。
- YARN是在HDFS之上实现的,可以跨应用程序并行执行多个分布式数据。YARN对于处理大数据的批处理和实时交互处理至关重要。
- YARN与MapReduce的应用程序编程接口(API)兼容,并提供了重新编译MapReduce作业以在YARN上执行它们的简单方法。
- YARN增强了大数据处理和管理中的多租户、集群利用率、可扩展性和兼容性。
2.3 HadoopCommon
HadoopCommon是Hadoop生态系统组件之一,由支持其他Hadoop模块的通用实用程序和程序组成。因此,它提供了Hadoop启动大数据处理和管理所需的文件系统和操作系统级别的抽象和其他脚本。此外,HadoopCommon对于自动处理硬件故障、数据压缩、用户身份验证、服务授权以及重要的错误识别和纠正非常重要。
3.流行的大数据分析工具
面向数据驱动行业大数据分析方法大致分为三种;即批处理模型、流处理模型和融合模型。这些处理模型和典型分析工具的详细信息如图2所示
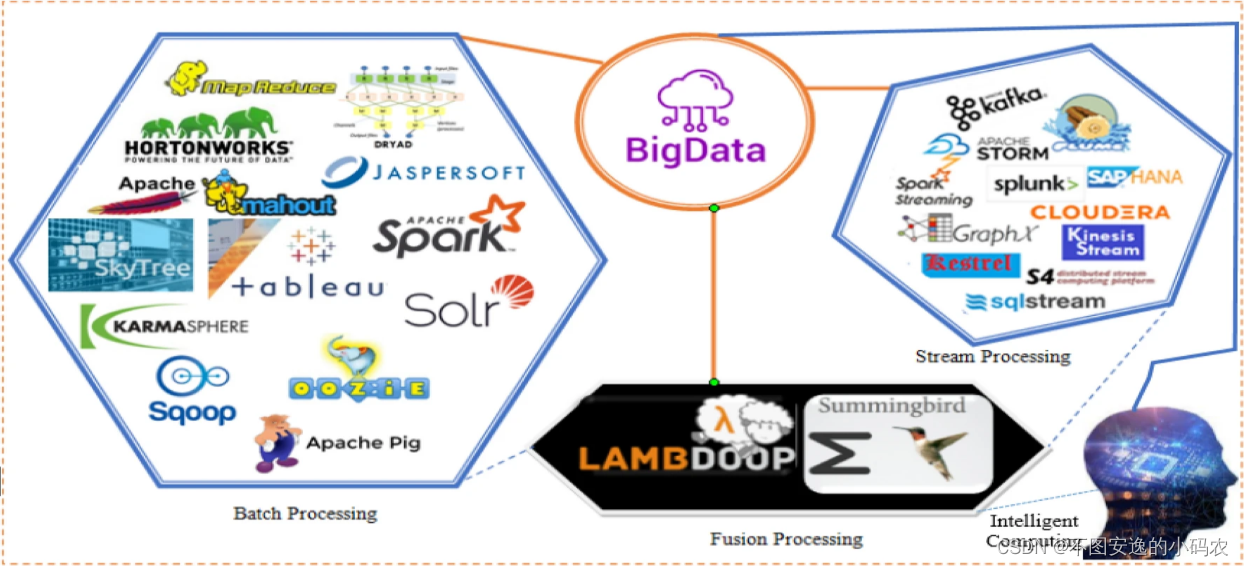
图2:大数据分析工具分类
3.1批处理
这是一种系统化的处理范式,其中随着时间的推移收集一组数据或一组工业数据,例如运营数据、商业智能、社交数据、历史和档案数据以及服务数据,并将收集到的数据输入分析人机交互较少的处理系统。因此,数据的加载以一定的时间间隔分批完成,生成报告,用户访问报告,直到下一次数据加载发生。
1)MapReduce
MapReduce是一个用于分布式计算的可编程框架(编程、模型和实现),它利用分而治之的方法进行大数据处理。该编程框架由Google创建,用于处理各种应用程序中生成的大数据,例如搜索引擎优化、互联网服务和广告增强。MapReduce是一种提供数据拆分为分布式格式、数据映射、打乱和分类以减少文档搜索的技术机制。具体来说,MapReduce平台是为通过批处理引擎进行离线数据处理而设计的。MapReduce中的数据处理分两个步骤:Reduce、Map。MapReduce可以执行多个reduce任务,以确保数据的并行化和聚合。
2)ApacheSpark
ApacheSpark是一个多用途的开源引擎,可快速用于大规模数据处理。Spark技术是一种分布式计算框架,兼容Hadoop、YARN集群管理器、JavaVM,可以从Hadoop或其他架构中读取任何现有数据。因此,ApacheSpark提供了一个用于流数据处理和分析的替代平台,能够以快速的响应时间处理内存中的大量数据集。
3)ApachePig
ApachePig是批处理框架之一,旨在最大限度地减少大数据分析中固有的问题,同时在Hadoop框架上并行执行数据流。因此,ApachePig是Hadoop生态系统的基本组成部分。Pig目前被Yahoo、Twitter、LinkedIn、Amazon等各行业采用,在大数据分析中提供类SQL查询和机器学习任务。此外,ApachePig使MapReduce中的脚本编程语言平台能够从Java等一些广泛使用的语言转换为高级符号。此外,Pig支持通过UDF以Java、JavaScript、JRuby、Python编码的用户定义函数(UDF),然后转换为MapReduce作业。
4)ApacheSolr
ApacheSolr是一个基于大数据的批处理工具,用于分布式数据索引、复制、负载平衡查询、自动故障转移和数据恢复。此外,该平台还为批处理提供集中配置、可靠、可扩展、容错和高效的机制。此外,ApacheSolr是基于ApacheLucene构建的,用于数据库搜索。此外,ApacheSolr是一个独立的企业搜索服务器,具有类似RESTful API,用于实现动态集群、实时索引、富文档处理、地理空间数据搜索、数据库集成、全文搜索等。
5)Oozie
Oozie是一个基于大数据的批处理平台,用于服务器端工作流调度系统。它是为管理和运行复杂的Hadoop作业而开发的。因此,服务器是一个可靠、可扩展和可扩展的管理系统,它执行大量工作流以及控制具有控制流和节点的非循环图。此外,工作流是基于XML的文档,支持不同MapReduce作业的连接和数据流。
6)Mahout
Mahout是为大数据分析提供可扩展、易用和可扩展库的MLlib和框架之一。Mahout支持各种编程平台,例如Scala、Python和Java编程语言,用于在Hadoop生态系统中构建分布式学习算法。最近,一个名为Samara的新版本被开发出来,使用数学环境来处理线性代数、统计运算和数据结构等大数据分析任务。
7)Dryad
Dryad表示用于开发和执行并行和分布式程序的批处理编程模型。Dryad可以将数据处理从非常小的集群扩展到基于数据流图处理的大型集群。此外,Dryad的特点是功能众多,包括生成作业图、在可用机器上调度进程、处理集群中的瞬时故障、收集性能指标、作业可视化、调用用户定义的策略以及动态更新响应政策决定的工作图。这是在不了解顶点语义的情况下实现的。Dryad中还有Map/Reduce和关系代数等其他计算框架,但在一定程度上具有复杂的数据处理。
8)SkytreeServer
SkytreeServer是一种大数据处理工具,可以部署以有效地高速处理海量数据集。Skytree服务器简单易用,并提供了一个简单的命令行来工作。此外,SkytreeServer在聚类、预测分析、推荐系统、市场细分和异常识别等领域为大数据处理提供各种算法和技术。
9)JaspersoftBI
JaspersoftBI套件是TIBCOJaspersoft推出的专为快速数据可视化而设计的大数据批处理工具之一。它在流行的存储平台上运行,包括MongoDB、Cassandra、Redis、Riak和CouchDB。有一个通过JasperReports连接到HBase的Hive连接器。此外,该工具与所有领先的大数据平台集成。Jaspersoft的独特属性基于无需提取、转换和加载(ETL)即可快速探索大数据。此外,在没有ETL要求的情况下,Jaspersoft可以交互式地直接从大数据存储中构建强大的HTML5报告和仪表板。此外,报告可以与用户组织内部或外部的任何人共享,以实现高效的性能可用性。
10)Sqoop
Sqoop提供用于将大数据移入和移出RDBMS的支持工具。Sqoop名称是从SQL中用Hadoop一词创造出来的,它确保了RDBMS和HDFS之间数据导出和导入的标准化。此外,它同时使用JDBC和命令行界面来实现跨Hadoop集群的数据并行化。Sqoop使用基于连接器的架构确保在指定源和目标目的地之间高效传输结构化大数据。
3.2流处理
流处理工具包括ApacheFlume、ApacheKafka、ApacheStrom、SparkStreaming、ApacheFlink、AmazonKinesis、Storm、Cloudera、S4和GraphX等。
1)ApacheFlume
ApacheFlume是一个基于代理的平台,它支持来自不同来源的分布式、可靠和可访问的Web服务,以有效地收集、聚合和移动大量事件数据到集中定义的数据存储。ApacheFlume提供了基于流数据流的简单灵活的架构,具有健壮、容错、可靠、故障转移和恢复机制,以确保高效的大数据处理和管理。此外,ApacheFlume代理是托管组件的Java虚拟机(JVM)进程,事件通过这些组件从外部源流向下一个目的地。图3描述了Flume的代理组件其中包括用于分发的启用Web服务、源(数据源)、用于事件存储的接收器、用于被动存储的通道和用于外部存储的HDFS。

图3 ApacheFlume平台
2)Kafka
Kafka是LinkedIn早在2010年开发的实时数据处理和开源分布式流项目。开发ApacheKafka是为了克服批处理方法的限制并解决数据丢失问题。Kafka提供了高效数据分析的功能,包括持久性、可伸缩性、容错和公共订阅消息系统。它专为实时和速度而设计,特别适用于日志数据收集。Kafka采用Scala和Java编程语言构建。Kafka是一个大数据项目工具,旨在通过内存分析技术处理流和操作数据以进行实时决策。
3)ApacheStorm
ApacheStorm是一个开源大数据流处理项目,旨在实时处理大型结构化和非结构化数据。ApacheStorm以容错性、可扩展性和轻松实现专用于实时数据分析、迭代计算、机器学习和顺序数据处理的框架而闻名。相比之下,storm集群总是类似于Hadoop集群。因此Storm集群用户为不同的Storm任务运行不同的拓扑,而Hadoop平台为相应的应用程序实现MapReduce作业。
4)SparkStreaming
SparkStreaming是Hadoop项目的一个组件,纯粹为自动并行化而设计。它是核心Spark API的扩展,允许对实时数据流进行高吞吐量、容错流处理。
5)ApacheS4
ApacheS4是为处理连续无界数据流的通用、分布式、可扩展、容错、可插拔计算平台而开发的大数据流处理工具之一。ApacheS4于2010年由Yahoo用于大数据流处理。
6)GraphX
GraphX是ApacheSpark的API,用于在并行计算中操作和执行图。它将提取、转换和加载(ETL)操作、探索性数据分析和迭代图计算统一在一个系统中。与SparkStreaming和SparkSQL类似,GraphX扩展了SparkRDDAPI的特性。因此,用户可以创建具有附加到每个顶点和边的任意属性的有向图。此外,GraphX提供了不同的运算符来支持使用图算法(例如,PageRank和三角形计数)的图操作
原文信息
[1]Ikegwu, A.C., Nweke, H.F., Anikwe, C.V. et al. Big data analytics for data-driven industry: a review of data sources, tools, challenges, solutions, and research directions. Cluster Comput (2022). https://doi.org/10.1007/s10586-022-03568-5

