
- 1stm32 SPI的从机中断接收_stm32f1 spi slave 中断接收 hal_nvic
- 2(18章)Python Flask 全流程全栈项目实战
- 3鸿蒙HarmonyOS-SDK管理使用指南_鸿蒙查看sdk
- 4【MySQL】学习如何通过DML更新数据库的数据
- 5.sh文件作用_.sh是什么脚本
- 6Docker 面试知识点_面试 docker
- 7python(django-vue3)项目win-win迁移_windows之间迁移python
- 8【RocketMQ】客户端报大量warn日志:No topic route info in name server for the topic:RMQ_SYS_TRACE_TOPIC、TBW102
- 9Ubuntu Linux 下安装和卸载cmake 3.28.2版本_cmake linux 卸载
- 10python实战项目电影推荐_7个Python实战项目代码,让你感受下大神是如何起飞的!...
安卓机上 4G 内存跑 Alpaca,欢迎试用轻量级 LLM 模型推理框架 InferLLM
赞
踩
从 LLM 火爆以来,社区已经出现了非常多优秀的模型,当然他们最大的特点就是体积大。最近为了让大模型可以在更低端的设备上运行,社区做了非常多的工作, gptq 实现了将模型进行低比特量化,因此降低了运行大模型对 CPU 内存、GPU 显存的要求,llama.cpp 实现了在本地 CPU/GPU 上就可以运行大模型,并且步骤非常简单,replit-code-v1-3b 用更小的模型实现了更智能的 code 生成。可以看到模型的小型化和轻量部署也是一个大模型的发展方向。
鉴于此,MegEngine 团队开发了 InferLLM 工程,主要目的有两个:
提供一个比 llama.cpp 更简单、更容易上手的本地部署框架,供大家学习和讨论
让 LLM 模型在本地或者端上部署成为可能,未来可以用在一些实际的生产环境中
相比 llama.cpp 工程,InferLLM 结构更简单,对一些通用组件进行了重构,避免将所有逻辑代码和 Kernel 代码放在一个文件中,避免在 Kernel 中引入过多的宏影响代码阅读和开发,llama.cpp 对于学习和二次开发不是很友好,InferLLM 也是主要借鉴 llama.cpp,如:使用 llama.cpp 的模型格式,以及 copy 了一些计算的 code,同时 InferLLM 对其进行了重构,使得代码更简单直接,非常容易上手,框架代码和 Kernel 代码分开,其实在大模型推理中,真正需要优化的 Kernel 是远远小于 CNN 的 Kernel 的。
另外 InferLLM 也可以用在生产中,因为它可以将 LLM 量化的模型在一个性能一般的手机上流畅的运行,可以流畅的进行人机对话,目前在手机上运行一个 llama 7b 4bit 的模型,只需要 4G 左右内存,这个内存是现在大多数手机都能满足的。相信在不久之后会出现很多大模型中的轻量化模型,可以直接在端上进行部署和推理,毕竟目前手机是大家最容易获得的计算资源,没有理由浪费如此庞大的计算集群。
下面是在xiaomi9,Qualcomm SM8150 Snapdragon 855 上使用 4 线程运行中文 alpaca 7b 4bit 量化模型的情况:
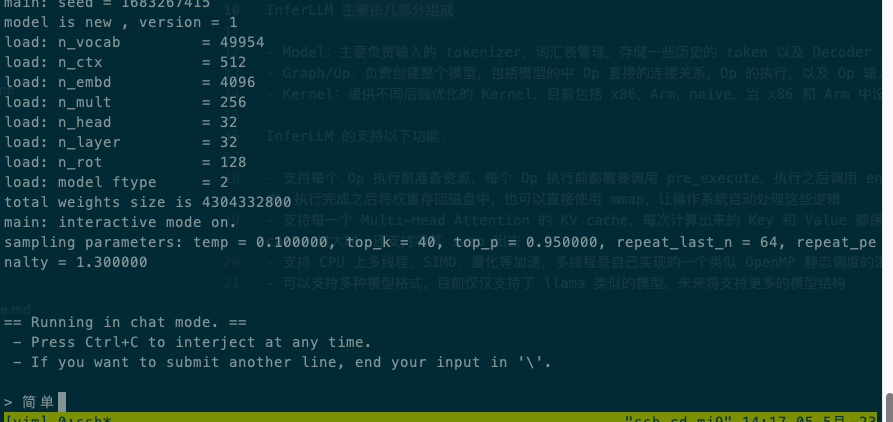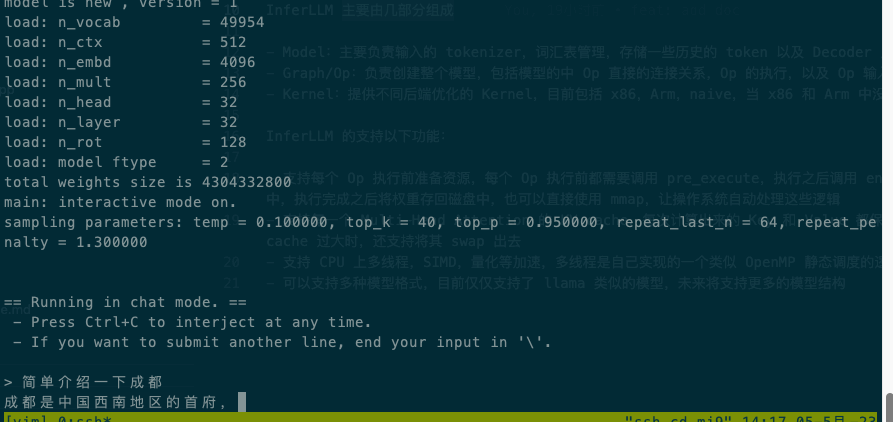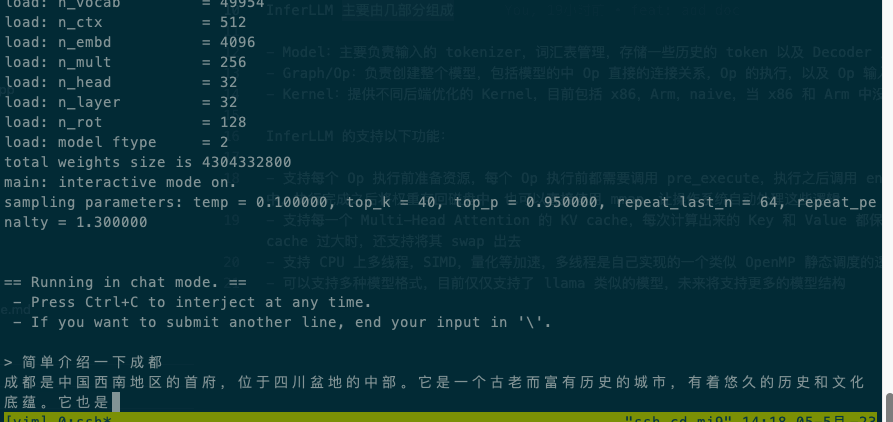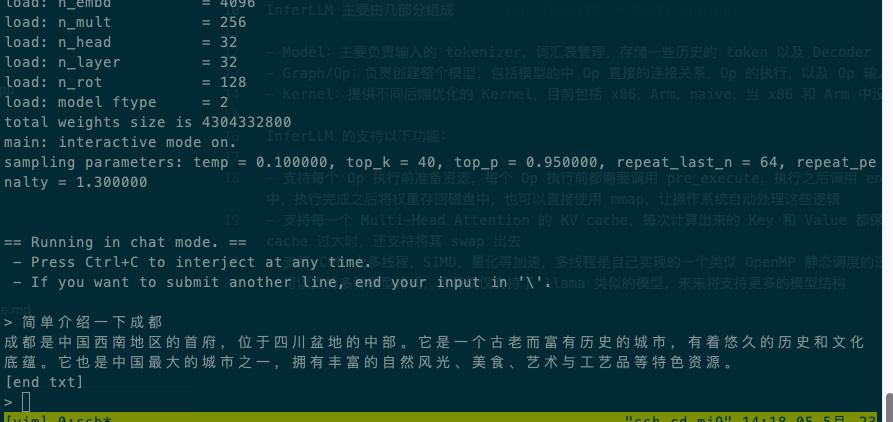
InferLLM 主要由几部分组成:
Model:主要负责输入的 tokenizer,词汇表管理,存储一些历史的 token 以及 Decoder 之后的采样等;
Graph/Op:负责创建整个模型,包括模型的中 Op 直接的连接关系,Op 的执行,以及 Op 输入输出等内存资源的管理;
Kernel:提供不同后端优化的 Kernel,目前包括 x86,Arm,naive,当 x86 和 Arm 中没有优化的 Kernel,会直接 fallback 到 naive 中进行运行。
InferLLM 主要支持以下功能:
支持每个 Op 执行前准备资源,每个 Op 执行前都需要调用 pre_execute,执行之后调用 end_execute。这样可以方便在内存不足的设备上,在执行前从磁盘中间权重读取到 RAM 中,执行完成之后将权重存回磁盘中,也可以直接使用 mmap,让操作系统自动处理这些逻辑;
支持每一个 Multi-Head Attention 的 KV cache,每次计算出来的 Key 和 Value 都保存在 KVStorage 中,KVStorage 支持通过 token 的 id 索引,另外如果 KV 的 cache 过大时,还支持将其 swap 出去;
支持 CPU 上多线程,SIMD,量化,float16 计算等加速方式,多线程是通过自己实现的一个类似 OpenMP 静态调度的逻辑,使用无锁的线程池来进行多线程之间的同步;
可以兼容多种模型格式,目前仅仅支持了 llama 类似的模型,未来将支持更多的模型结构。
欢迎大家试用 InferLLM:https://github.com/MegEngine/InferLLM
附:更多 MegEngine 信息获取,您可以:查看文档和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705。欢迎参与 MegEngine 社区贡献,成为 Awesome MegEngineer,荣誉证书、定制礼品享不停。


