
- 1Python 打包配置文件 setup.py 详解_python 中setup.py在哪
- 2【云原生 | 从零开始学istio】二、Istio核心特性与架构
- 3unity karting导入时的编译问题_all compiler errors have to be
- 4小程序实现无限级树形菜单_小程序 树菜单
- 5“IT小百科”之“Windows自带的服务和系统进程详解”_windows服务 打开exef进程
- 6DRF学习之权限验证(十五)_permission_classes=[isauthenticated]
- 7分布式事务概念及理论
- 8#每日一题# 25. K 个一组翻转链表 - 20191021_给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。 k 是一个正整数,
- 9开源大型语言模型概览:多语种支持与中文专注
- 10Unity pc端内嵌网页插件Embedded Browser基本使用流程(转载)
SHAP 和 LIME 解释模型_shap事后解释器
赞
踩
1、SHAP 解释器
1.1 案例:用于预测患者肺癌
该案例使用肺癌数据集,使用随机森林分类器训练模型,并预测测试集标签。最后使用SHAP解释器解释模型预测的依据,如哪些特征对预测影响较大,此外也可以添加其他指标评估模型质量。
1.2 案例中使用的shap解释器
- SHAP基于 shapely 值理论,它源于博弈论,用于衡量个体特征对模型预测结果的贡献。
- 对于每一个样本,SHAP通过计算该样本所有可能子集中,特征存在与不存在时模型输出的差异。
- 这些边际贡献根据公式计算出代表该特征对该实例预测结果贡献的shapley值。
- 由于shapley值具有加性性质,可以计算出每一个特征在该实例中的绝对影响程度。
- SHAP解释器会对每一次预测计算所有特征的shapley值。
- 这些shapley值既可以用来解释单个预测,也可以汇总 stationed 的 shapley值对所有样本进行可视化。
- 例如平均按特征 shapley值排序可以看出影响程度最大的特征。
- SHAP值也可以利用依赖图等方式展示特征间相互影响。
1.3 SHAP工作原理
假设我们有一个分类模型,输入有3个特征A,B,C,输出一个标签0或1。
现在有一个样本,其特征值为:
- A = 1
- B = 0
- C = 1
模型给出的预测标签是1
1、SHAP解释器会计算:
- 当只有A时,模型预测值。
- 当只有B时,模型预测值。
- 当只有C时,模型预测值。
- 当A,B共存时,模型预测值。
- 当A,C共存时,模型预测值。
- 当B,C共存时,模型预测值。
- 当A,B,C全存在时,模型预测值。
2、它通过对比不同子集中模型输出的差异,来计算每个特征的边际效应。
3、然后根据shapley值公式,得到每个特征A,B,C对预测结果的独立贡献,也就是它们的SHAP值。
4、通过这样的分析,我们就可以看到每个特征对预测结果的影响程度,这就是SHAP解释器工作的基本套路。
SHAP解释器计算每个特征的边际效应是基于下面这个思路:
对于样本X上的模型预测f(X),它有m个特征。
对于每个特征xi, SHAP会考虑该特征在所有可能的子集S中的取值:
- 当xi在S中时,模型输出为f(X|S)
- 当xi不在S中时,模型输出为f(X|-xi)
那么这个特征xi在子集S中的边际效应定义为: 边际效应 = f(X|S) - f(X|-xi)
也就是说,这个特征加入或去除子集S时,模型输出的变化。
5、SHAP会计算样本X上每个可能的子集S,然后对每个特征xi统计他在所有子集S中的边际效应。
6、最后根据shapley值的定义,通过加权平均计算出特征xi对整体模型输出f(X)的贡献大小。
这个贡献量就是我们常说的这个特征的SHAP值,就代表了它对预测结果的独立影响程度。
所以通过不断采样不同子集,SHAP可以详细解剖每个特征的边际影响,从而给出它们对结果的解释。
1.4 举例说明
小明,小军,小强,组队参加王者农药大赛,大赛设定哪个队先拿100个人头可获得一万元奖金。终于在他们三个的通力配合下,赢得了比赛获得一万元奖金,但分钱阶段出现了分歧,因为三个人的水平、角色不一,小强个人实力最强善用高输出角色,光是他自己就拿了大半的人头;但若是按照人头数分,也不合适,因为前期小强有几次差点挂掉,多亏队友及时治疗,另外有好多人头也是靠攻速抢到的。如何分配这一万元最公平?
这个问题,我们可以从贡献出发:
- 小强自己可以干掉35个人,小军可以干掉15个人,小明可以干掉10个人,显然,他们每个人都无法独立完成目标。
- 小强和小军联手可以干掉70个人,小强和小明可以干掉60个人,小军和小明联手可以干掉40个人,同样,无法完成任务。
- 而只有当三个人联手时候,才可以干掉100个人,达成目标。
考虑先后顺序,他们三个人一共有6种组队方式。
我们定义边际贡献:假定初始组合为小强一个人,贡献35,加入小军后,他们俩的组合贡献为70,则小军的边际贡献就是70-35=35,再加入小明,三个人的组合贡献为100,则小明的边际贡献为100-70=30;
根据组合次序计算全部的组合及组合中每个人的边际贡献,如表格所示,则可以求得每个人的贡献度。
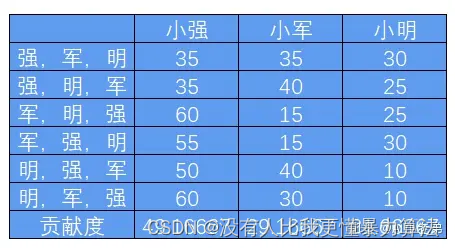
因此,最合理的分配方案就是小强小军小明分别获得4916、2917、2167。
【举例参考原文:https://zhuanlan.zhihu.com/p/106320452】
2、LIME 解释器
2.1 案例:判断法律案件胜诉可能性
该案例加载法律案件数据,训练RF分类模型预测胜诉可能性,并使用LIME解释单例预测依据,可以辅助法律工作。
2.2 LIME解释器工作原理
LIME(Local Interpretable Model-agnostic Explanations) 的工作原理:
- 对预测的每个样本,LIME都会训练一个"本地解释模型"来近似实际模型在这个样本附近的行为。
- 本地解释模型一般使用线性模型或者决策树这类易解释模型。
- LIME通过对样本附近数据点进行扰动,并询问实际模型得到这些点的预测,来训练本地模型。
- 本地模型可以解释实际模型对这个样本的预测是如何受不同特征值影响的。
所以LIME可以解释模型预测一个单独样本的原因,指出影响程度最大的特征,这对法律工作很有意义。它的优点是模型无关,仍适用于黑箱模型,这就是LIME受到欢迎的原因。
2.3 本地解释模型的训练过程
LIME训练本地解释模型的过程包括以下步骤:
- LIME周围采样许多实例,如更改、删除单个词等。这构成了一个新数据集。
- 对新数据集每个实例,询问原始模型给出的预测结果。这为新数据集加入预测标签。
- LIME对新数据集中的每个实例计算其相对于原始实例的距离作为新特征。
- LIME利用新数据集训练一个线性回归模型,取各个特征项的系数作为“影响程度”。
- 被训练的线性模型直接优化的是对原始模型在周围实例表现的模拟goodness。
- 其中的特征系数量化了不同特征值改变对原始模型输出影响的程度。
- 系数值越大,表示该特征对原始模型输出贡献越大,可以视为关键影响特征。
通过这一训练过程,LIME得到的线性模型仅在原始样本附近有效,但能反映原始模型在这里的线性表现,从而提供本地解释。
2.4 举例说明1:新闻分类
假设我们有一个文本分类模型,用于判断新闻文章是否为政治类。
给定一个测试样本:
文本内容: “政府宣布将提高税率。”
模型预测: 政治类
LIME会做如下工作:
- 创建样本的变异实例,如删改单个单词:
- “政府宣布税率。”
- “将提高税率。”
- “政府将提高。”
-
询问原模型这些实例的预测结果。
-
求每个实例与原样本的距离,做为新特征。
-
用这些新数据训练线性模型fitting原模型表现。
-
得到的线性模型公式为:
y = 1.0*“政府” + 0.8*“税率” + 0.1*“将提高”
所以关键词为"政府"和"税率",它们最大影响预测结果。
通过这个例子可以清楚看到LIME是如何在本地近似原始模型,并解释单个预测结果的。它利用了简单且易解释的线性模型。
2.4 举例说明2:电影评论判断
假设我们有一个模型来判断是否是正面评论,输入是一个短评文本:
评论文本: “电影很好看,主演演技饱满”
模型预测: 正面评论
LIME会做以下工作:
- 根据输入文本生成多种扰动样本,如删除个别单词
- 检查样本:“电影很演技饱满”
模型预测:负面评论 - 样本:“主演演技饱满”
模型预测:中性评论 - 将样本和预测作为新数据集训练线性模型
- 得到线性模型:
正面=1.0*“电影很好看”+0.6*“主演演技饱满” - 所以"电影很好看"对正面判断贡献最大
通过对原始样本进行简单删除操作,LIME找到主要影响项"电影很好看",表明它是模型判断的关键依据。
————————————————
原文链接:https://blog.csdn.net/weixin_71458119/article/details/132460672

