
- 12024年腾讯Java高级面试题及答案,【Spring注解驱动开发_java高级工程师面试题和答案2024
- 2淘宝技术这十年_淘宝 xtao社区 轻电商
- 3【Vue】关于ESLint自动修复配置显示---类型不正确,预期为“string“问题如何解决_source.fixall": true类型不正确
- 4AIGC大模型面经汇总,太全了!_aigc面经
- 5C#的String.Split方法_c# string split
- 6StringUtils工具类的使用_stringutils.tocodepoints
- 7Jmeter使用接口传递数据过程图解
- 8【小笔记】streamlit使用笔记_在phcht中运行 streamlit 应用程序 - 知乎
- 9苹果浏览器无法边下边播MP4(谷歌浏览器可以)_safari浏览器不支持video标签
- 10关于post请求的三种参数【params,data,json】_post请求的params
2024检索增强生成RAG最新综述
赞
踩
论文地址:https://arxiv.org/abs/2402.19473
项目存储库:https://github.com/hymie122/RAG-Survey
摘要—人工智能生成内容(AIGC)的发展得益于模型算法的进步、基础模型规模的增加以及大量高质量数据集的可用性。虽然AIGC取得了显著的性能,但仍面临一些挑战,如难以保持最新和长尾知识、数据泄露的风险以及与训练和推理相关的高成本。检索增强生成(RAG)最近出现作为一种范式来解决这些挑战。具体而言,RAG引入信息检索过程,通过从可用数据存储中检索相关对象来增强生成过程,从而提高准确性和鲁棒性。本文全面审查了将RAG技术整合到AIGC场景中的现有努力。我们首先根据检索器如何增强生成器对RAG基础进行分类,梳理各种检索器和生成器的增强方法的基本抽象。这种统一的视角涵盖了所有RAG场景,阐明了有助于潜在未来进展的进步和关键技术。我们还总结了RAG的其他增强方法,促进了RAG系统的有效工程和实施。然后,从另一个角度,我们调查了RAG在不同模态和任务中的实际应用,为研究人员和从业者提供了有价值的参考。此外,我们介绍了RAG的基准,讨论了当前RAG系统的局限性,并提出了未来研究的潜在方向。
关键词—检索增强生成,人工智能生成内容,生成模型,信息检索。
引言
背景
近年来,人工智能生成内容(AIGC)引起了广泛关注。各种内容生成工具被精心设计,以在各种模态下产生多样化的输出,例如大型语言模型(LLM),包括GPT系列[1]–[3]和LLAMA系列[4]–[6]用于文本和代码,DALL-E[7]–[9]和Stable Diffusion[10]用于图像,以及Sora[11]用于视频。术语“AIGC”强调这些内容是由先进的生成模型而不是人类或基于规则的方法产生的。这些生成模型由于采用了新颖的模型算法、庞大的基础模型规模和大量高质量数据集而取得了显著的性能。具体而言,序列到序列任务已经从使用长短期记忆(LSTM)网络[12]转变为基于Transformer模型[13],图像生成任务也已从生成对抗网络(GANs)[14]转变为潜在扩散模型(LDMs)[10]。值得注意的是,基础模型的架构,最初由数百万参数构成,现在已经增长到数十亿甚至数万亿的参数。这些进展进一步得到了丰富高质量数据集的支持,这些数据集提供了丰富的训练样本,以充分优化模型参数。
信息检索是计算机科学领域的另一个关键应用。与生成不同,检索旨在从大量资源中定位相关的现有对象。检索最常见的应用在于网络搜索引擎,主要关注文档检索任务。在当前时代,高效的信息检索系统可以处理数十亿级别的文档集合。除了文档,检索还被应用于许多其他模态。
尽管先进的生成模型取得了显著进展,AIGC仍然面临一些众所周知的挑战,包括难以保持最新知识、无法整合长尾知识和泄露私人训练数据的风险。检索增强生成(RAG)被提出来缓解,如果不是完全解决,上述挑战,通过其可适应的数据存储库。存储的知识可以被构想为非参数化记忆。这种形式的记忆易于修改,能够容纳广泛的长尾知识,并且还能够编码机密数据。此外,检索还可以用于降低生成成本。例如,RAG可以减小大型生成模型的大小,为长上下文提供支持,并消除某些生成步骤。
典型的RAG过程如图1所示。给定一个输入查询,检索器定位并查找相关数据源,然后检索结果与生成器互动以增强整个生成过程。检索结果可以以不同方式与生成过程互动:它们可以作为生成器的增强输入;它们可以在生成的中间阶段作为潜在表示加入;它们可以以logits的形式对最终生成结果做出贡献;它们甚至可以影响或省略某些生成步骤。此外,在典型的基础RAG过程基础上,还提出了许多增强方法来提高整体质量。这些增强方法涵盖了特定组件的方法以及针对整个流程的优化。
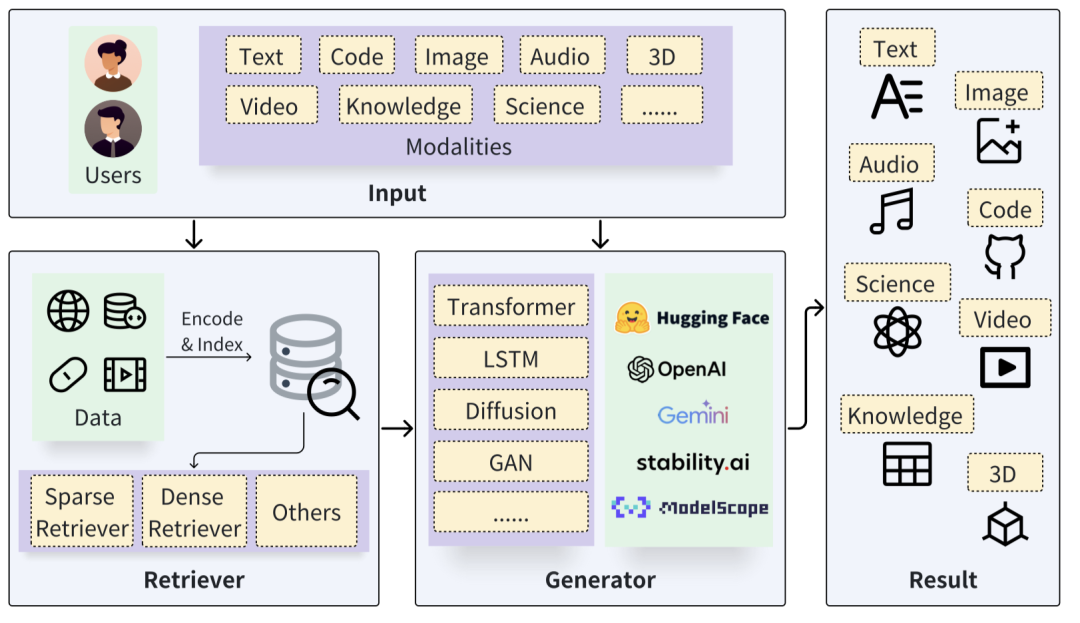
图1. 通用的RAG架构。用户的查询,可能是不同的模态,作为检索器和生成器的输入。检索器在存储中搜索相关数据源,而生成器与检索结果互动,最终产生各种模态的结果。
此外,尽管RAG的概念最初出现在文本到文本生成中,但它也已经适应到各个领域,包括代码、音频、图像、视频、3D、知识和科学人工智能。特别是,RAG的基本思想和过程在各种模态下基本一致。然而,它需要在增强技术上进行特定的微调,并且检索器和生成器的选择因特定模态和/或应用而异。
尽管最近对RAG的研究迅速增长,但缺乏涵盖所有基础、增强和应用的系统性审查。对RAG基础缺乏讨论显著削弱了该领域研究的实际价值,使RAG的潜力没有得到充分探索。尽管大多数研究兴趣,特别是在LLM研究人员中,集中在基于查询的文本生成任务上,但必须承认,其他RAG基础范式也是有效的技术,具有重要的用途和进一步发展的潜力。对RAG应用缺乏概述导致研究人员和从业者忽视了RAG在多个模态中的进展,并且不了解如何有效应用RAG。尽管文本生成通常被认为是RAG的主要应用,但我们强调RAG在其他模态中的发展也在早期阶段开始,并取得了令人期待的进展。某些模态与检索技术有着丰富的历史联系,为RAG注入了独特的特征。尽管已经提出了一些关于RAG的调查,但它们主要集中在部分方面,如特定方法和任务。在本文中,我们的目标是提供一项全面的调查,以系统概述RAG。
贡献
本调查全面概述了RAG,涵盖了基础、增强、应用、基准、局限性和潜在未来方向。虽然检索器和生成器在不同模态和任务中存在差异,但我们从这些基础中提炼了RAG基础的基本抽象,考虑到应用是从这些抽象中衍生出来的。我们旨在为研究人员和从业者提供参考和指导,为推进RAG方法和相关应用提供有价值的见解。总之,我们列出我们的贡献如下:
- 我们对 RAG 进行了全面的回顾,并提炼了适用于各种检索器和生成器的 RAG 基础抽象。
- 我们总结了对现有 RAG 流程的增强,详细阐述了用于实现更有效 RAG 系统的技术。
- 对于各种模态和任务,我们调查了融合了 RAG 技术的现有 AIGC 方法,展示了 RAG 如何对当前的生成模型做出贡献。
- 我们讨论了 RAG 的局限性和有前途的研究方向,揭示了其潜在的未来发展。
相关工作
随着对 RAG 的研究不断深入,提出了几篇关注 RAG 的综述论文。Li 等人 [56] 对文本生成的 RAG 进行了调查。由于该综述覆盖了截至 2022 年的论文,许多新的 AIGC 中 RAG 的进展并未包含在内。Asai 等人 [57] 提供了关于基于检索的语言模型的教程,介绍了架构和训练范式。Gao 等人 [58] 对 LLMs 中的 RAG 进行了调查,特别是研究了基于查询的 RAG 的增强。上述调查主要考虑了由 LLMs 支持的文本相关任务中的 RAG,将其他模态作为潜在扩展。然而,RAG 的概念在早期阶段就涉及到所有模态,使其更适合在整个 AIGC 的更广泛背景下讨论。Zhao 等人 [59] 提出了一项关于多种模态的 RAG 应用的调查,但忽略了对 RAG 基础的讨论。这些调查要么专注于单一的 RAG 基础范式,要么仅对有限情景下的 RAG 增强方法论进行简要概述。因此,虽然现有研究已经探讨了 RAG 的各个方面,但仍然需要全面概述系统地涵盖 RAG 的基础、增强以及其在不同领域中的适用性。在本文中,我们旨在提供一份系统性的 RAG 概述,以填补这些空白。
路线图
本文的其余部分组织如下。第 II 节详细介绍了 RAG 的基础知识,介绍了检索器和生成器。第 III 节介绍了 RAG 的基础知识以及对 RAG 的进一步增强。第 IV 节回顾了在各种应用中对 RAG 的现有研究。第 V 节调查了 RAG 的基准框架。第 VI 节讨论了 RAG 目前的局限性和未来的潜在方向。最后,第 VII 节总结了本文。
初步
在本节中,我们首先概述了一般 RAG 架构。随后,我们深入探讨了当今基于 RAG 的 AIGC 中所使用的生成器和检索器的细节。
概述
如图 1 所示,整个 RAG 系统由两个核心模块组成:检索器和生成器。检索器负责从构建的数据存储中搜索相关信息,生成器负责生成内容。RAG 过程如下展开:首先,检索器接收输入查询并搜索相关信息;然后,原始查询和检索结果通过特定的增强方法论传递给生成器;最后,生成器产生所需的结果。在第 III-A 节中,我们将介绍 RAG 的基础知识。在第 III-B 节中,我们将介绍基于构建的 RAG 系统的进一步增强方法。
生成器
生成 AI 在各种任务中表现出色,开启了 AIGC 时代。由其强大的生成模块驱动,生成 AI 在效率方面甚至超越了原始专家系统。在整个 RAG 系统中,生成模块具有重要意义。不同的生成模型根据不同的场景进行选择。例如:文本到文本任务选择 transformer 模型,图像到文本任务选择 VisualGPT [60],文本到图像任务选择 Stable Diffusion [10],文本到代码任务选择 Codex [2]。
根据模型结构,我们将生成器分为 4 大类:transformer 模型、LSTM、diffusion 模型和 GAN。我们将在接下来的章节中对每个类别进行详细介绍。
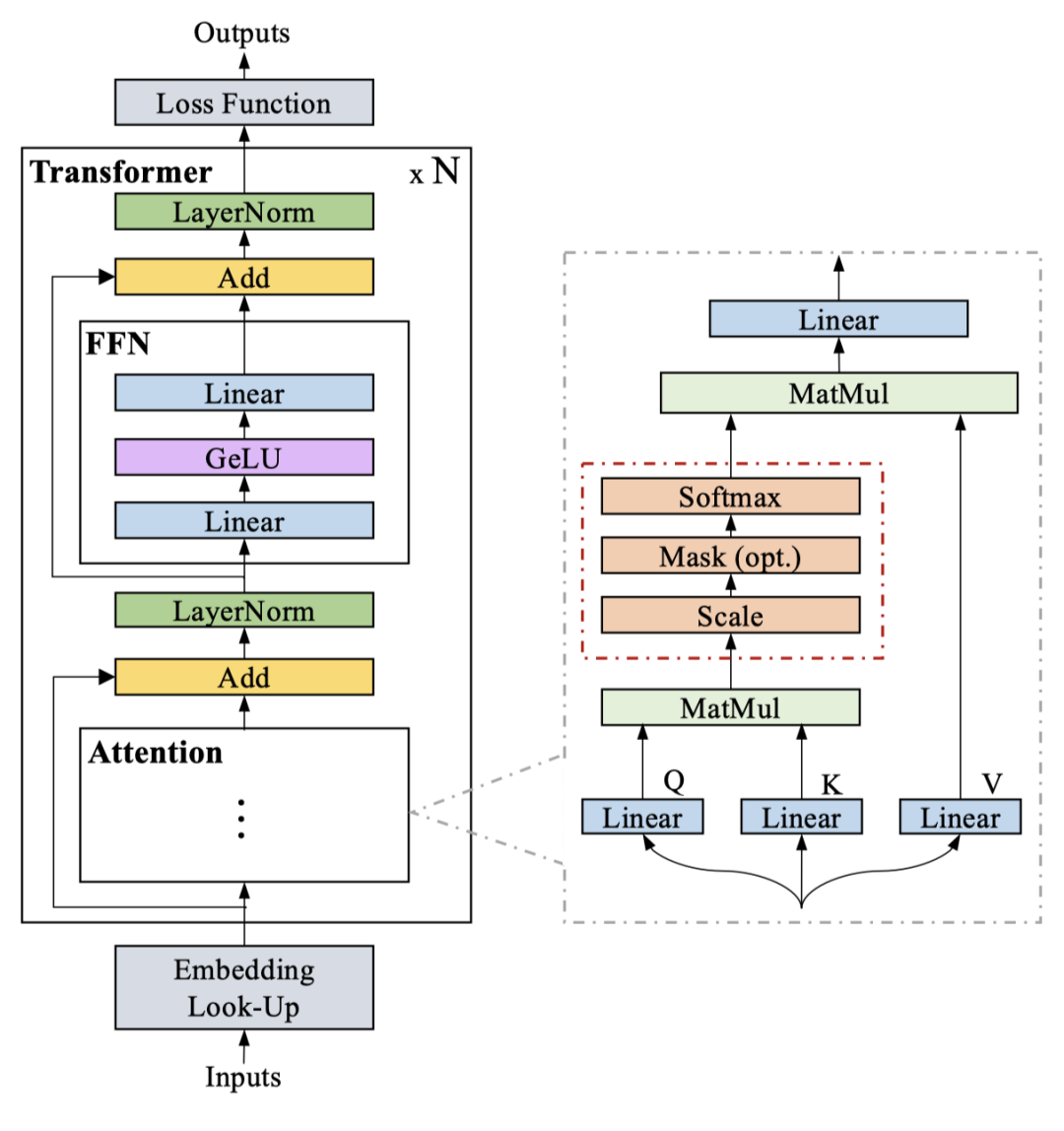
图 2. 传统 transformer 模型的架构。
Transformer 模型
最初的 transformer 设计用于解决神经语言处理领域的问题,包括自注意力机制、前馈网络、层归一化模块和残差网络 [61]。
如图 2 所示,transformer 的输入经过标记化处理和嵌入模型后,被映射为形状为 (b, s, h) 的张量 x_(in),其中 b 代表批处理大小,s 代表序列长度,h 代表隐藏维度。接下来,位置编码将与此张量一起发送到自注意力层。输入 x_(in) 和自注意力模块的输出 x_(out) 将通过残差网络和层归一化模块连接。最后,“Add & Norm” 模块的输出 x_(out) 将发送到前馈网络。整个过程可以定义如下:
需要注意的是 是形状为 的可学习张量; 是形状为 的可学习张量。
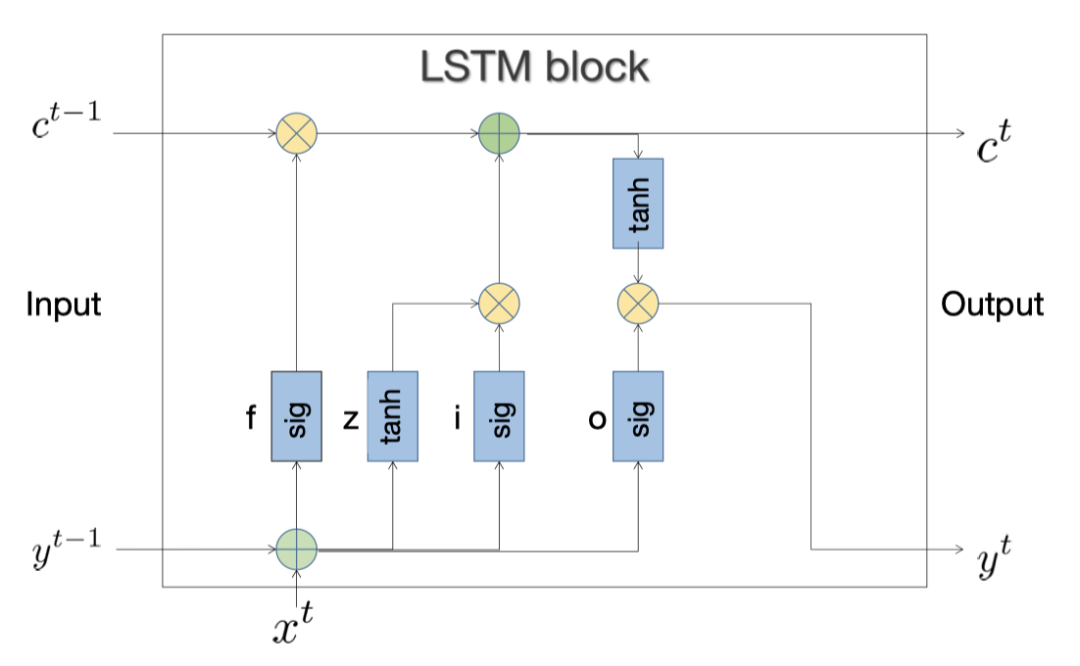
图 3. 具有遗忘门的典型 LSTM 模块的架构。
LSTM
长短期记忆(LSTM)[62] 是一种特殊的循环神经网络(RNN)模型,通过引入细胞状态和门机制,克服了 RNN 处理长期依赖信息时的梯度消失/爆炸问题。LSTM 模型由三个门组成:输入门、遗忘门和输出门。这些门通过控制信息流来更新细胞状态,使模型能够记住长期依赖信息。细胞状态是 LSTM 模型的核心模块,可以记忆和保持信息。输入门决定应该将哪些输入数据保留在细胞状态中。遗忘门确定应该丢弃哪些细胞状态信息,以避免过度记忆。输出门确定细胞状态中的信息如何影响当前输出。数据流和各组件之间的协作工作流程如图 3 所示。整个过程可以定义如下:
Diffusion 模型
扩散模型 [63] 是一类能够生成真实且多样化数据样本的深度生成模型,例如图像、文本、视频和分子等。如图 4 所示,扩散模型通过逐渐向数据添加噪声,直到变得随机,然后通过反向过程从噪声生成新数据。这一过程基于概率建模和神经网络。扩散模型主要有三种等效形式:去噪扩散概率模型、基于分数的生成模型和随机微分方程,其中包括 DDIM、Rectified Flow、Consistency Model 和 RPG-DiffusionMaster 等改进。

图 4. 扩散模型通过向数据添加噪声平滑扰动数据,然后通过反向过程从噪声生成新数据。反向过程中的每个去噪步骤通常需要估计得分函数(见右侧说明性图),该函数是指向具有更高可能性和更少噪声的数据方向的梯度,参见 [63]。
特别地,设 是遵循数据分布 的随机变量, 是在时间步 添加噪声后遵循分布 的随机变量。那么,DDPM 可以被表述如下:
-
正向过程 正向过程通过一系列高斯噪声注入扰动数据,将数据分布 转换为简单的先验分布 。每个时间步的转移核心如下所示:
-
逆向过程 逆向过程通过一个可学习的马尔可夫链反转前向过程生成新的数据样本。先验分布为 ,转移核为
,其中 和由深度神经网络参数化。逆向过程从开始采样,然后迭代地从中采样 。
-
模型训练 对于每个样本 x₀ ∼ q(x₀),模型训练的目标是最大化数据 x₀ 的变分下界(VLB)。简化形式 给出为
通过简化和重参数化技巧,整体目标 可以简化为最终形式
其中 是一个正权重函数, 是集合 上的均匀分布, 是一个深度神经网络,参数为 ,用于预测给定 和 的噪声向量 。需要注意的是,整体目标也等价于通过最小化它们之间的 KL 散度,将逆向过程 的联合分布匹配到前向过程 。
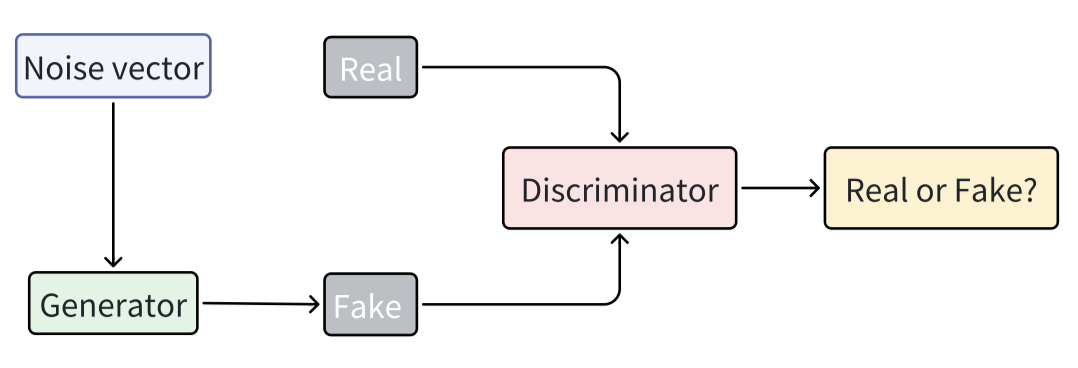
图 5. 典型生成对抗网络(GAN)的架构。
GAN
生成对抗网络(GANs)[96] 是备受期待的深度学习模型,具有惊人的能力,可以模拟和生成逼真的图像、音频和其他数据。由于其出色的性能,GANs 在各个领域取得了重大成就[97]。GANs 的设计灵感来自博弈论中的零和博弈。
如图 5 所示,典型的 GAN 包括两个主要组件:生成器和判别器。这两部分通过对抗学习相互竞争,使生成器不断改进生成逼真样本的能力,而判别器则不断改进区分真假样本的能力。
检索器
检索是识别和获取与信息需求相关的信息系统资源。具体来说,考虑将信息资源概念化为一个键-值存储 ,其中每个键 对应一个值 (通常情况下, 和 相同)。给定一个查询 ,目标是使用相似性函数 搜索前 个最相似的键,并获取配对的值。根据不同的相似性函数,现有的检索方法可分为稀疏检索、密集检索和其他方法。对于广泛使用的稀疏和密集检索,整个过程可以分为两个明确的阶段:在第一阶段,将每个对象编码为特定表示;在第二阶段,构建索引以组织数据源以进行高效搜索。
稀疏检索
稀疏检索方法广泛应用于文档检索,其中键实际上是要搜索的文档(在这种情况下,值是相同的文档)。这些方法利用诸如 TF-IDF [98]、查询似然性 [99] 和 BM25 [19] 等术语匹配度量,分析文本中的词统计信息,并构建倒排索引以进行高效搜索。其中,BM25 在工业规模的网络搜索中是一个难以超越的基准。对于包含关键词 的查询 ,文档 的 BM25 分数为:
其中 是逆文档频率权重, 是词 在文档 中出现的次数, 是 的长度,avgdl 是语料库中的平均文档长度, 和 是可调参数。 计算为:
其中 是文档数, 是包含 的文档数。IDF 分数也用于 TF-IDF。为了实现高效搜索,稀疏检索通常利用倒排索引来组织文档。具体来说,查询中的每个术语执行查找以获取候选文档列表,然后根据它们的统计分数对其进行排名。
密集检索
与稀疏检索不同,密集检索方法使用密集嵌入向量表示查询和键,并构建近似最近邻(ANN)索引以加速搜索。这种范式可应用于所有模态。对于文本数据,最近的预训练模型(包括 BERT [15] 和 RoBERTa [100])被用作编码器分别对查询和键进行编码[20],[101]–[104]。类似于文本,已经提出了用于编码代码数据[25]、[105]、[106]、音频数据[26]、[107]、图像数据[24]、[108]和视频数据[109]、[110]的模型。密集表示之间的相似性分数可以使用余弦、内积、L2 距离等方法计算。
在训练过程中,密集检索通常遵循对比学习范式,使正样本更相似,负样本更不相似。已经提出了几种硬负样本技术[101]、[111],以进一步提高模型质量。在推断过程中,应用近似最近邻(ANN)方法进行高效搜索。已经开发了各种索引来服务于 ANN 搜索,例如树[112]、[113]、局部敏感哈希[114]、邻居图索引(例如 HNSW[115]、DiskANN[116]、HMANN[117])、图索引和倒排索引的组合(例如 SPANN[118])。
其他方法
除了稀疏检索和密集检索,还有用于检索相关对象的替代方法。一些研究工作直接使用自然语言文本[119]或代码片段的抽象语法树(AST)之间的编辑距离,而不是计算表示。对于知识图,实体与关系相连,可以视为检索搜索的预建索引。因此,涉及知识图的 RAG 方法可以使用 k-hop 邻居搜索作为检索过程[122]、[123]。命名实体识别(NER)[124]、[125]是另一种检索方式,其中输入是查询,实体是键。
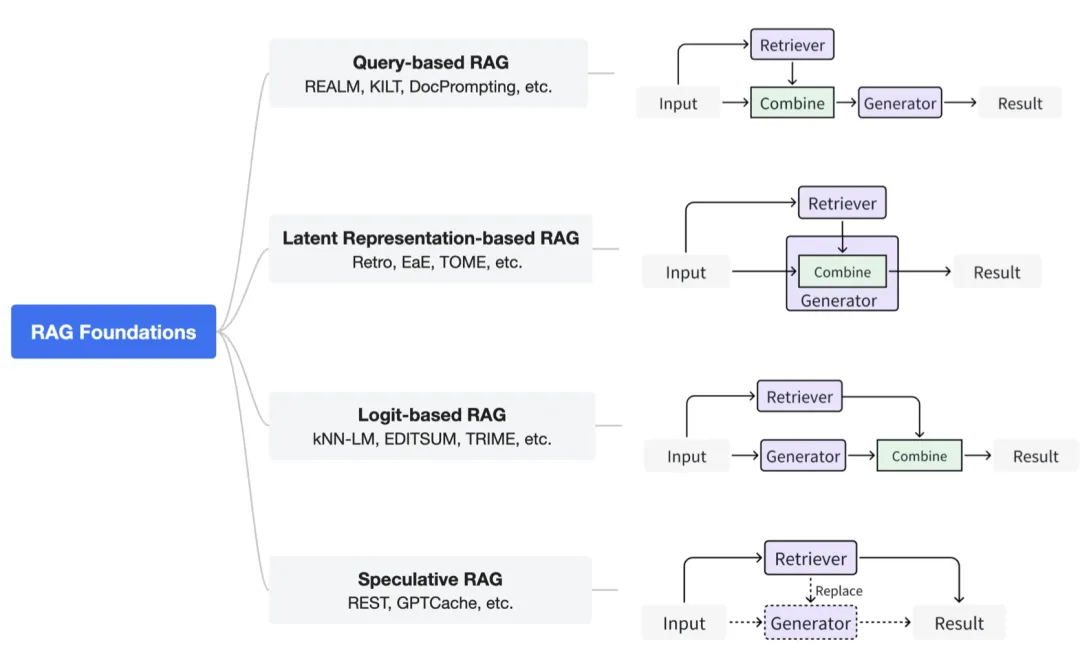
图 6. RAG 基础的分类。
方法
在本节中,我们首先介绍了在 AIGC 上下文中的 RAG 基础。随后,我们概述了进一步提高 RAG 效果的增强方法。
RAG 基础
根据检索器如何增强生成器,我们将 RAG 基础范式分类为 4 个不同类别,如图 6 所示。
基于查询的 RAG(Query-based RAG)
基于查询的 RAG 也称为提示增强。它将用户的查询与检索过程中获取的文档见解直接整合到语言模型输入的初始阶段。这种范式是 RAG 应用中广泛采用的方法。一旦检索到文档,它们的内容就会与原始用户查询合并,以创建一个复合输入序列。然后将这个增强的序列馈送到预训练语言模型中生成响应。最近,一些方法提出了在不修改语言模型架构的情况下实现 RAG 的方法,这对于通过 API 访问语言模型的场景特别合适。REPLUG [128] 通过将语言模型视为“黑匣子”,利用 Contriever 无缝地将相关外部文档整合到查询中,阐述了这一方法。具有 LM-Supervised Retrieval 的变体 REPLUG LSR 进一步优化了这一过程,通过优化检索,减少困惑度分数,并通过丰富其上下文理解来提高模型性能。In-Context RALM [129] 使用 BM25 算法进行文档检索和预测性重新排序,以选择与输入整合相关的文档。
在当代多模态应用研究中,将检索内容整合到输入中已被证明在增强各种任务性能方面非常有效。这种策略适用于几个关键领域,包括代码生成、音频生成和知识库问答(KBQA)。
对于文本转代码任务,APICoder [130] 和 DocPrompting [41] 展示了将检索信息有效整合到语言模型中如何提高生成代码的准确性和相关性。在自动程序修复任务中,CEDAR [131] 和 InferFix [132] 利用检索到的代码片段来辅助修复过程,通过将其与原始输入结合,增强模型的理解和应用修复策略。对于代码补全任务,ReACC [133] 使用提示机制,利用检索到的代码片段作为新输入的一部分,以提高代码补全的准确性和效率。
在音频生成领域,MakeAnAudio [43] 利用检索来构建无语言文本的字幕,以缓解文本到音频训练中的数据稀疏性。
最近在 KBQA 领域的研究显示了结合检索和语言模型的显著效果。Uni-Parser [134]、RNG-KBQA [122] 和 ECBRF [135] 通过将查询和检索信息合并到提示中,有效提高了问答系统的性能和准确性。BLLM augmentation [136] 是对使用黑盒大型语言模型进行零样本 KBQA 的创新尝试。这种方法直接将检索到的信息整合到模型输入中,无需额外的样本训练,展示了结合检索和语言模型以增强模型在理解和回答未见问题方面的泛化能力的巨大潜力。
在 RAG 技术的科学领域中,Chat-Orthopedist [137] 旨在为患特发性脊柱侧凸症的青少年提供共享决策支持。这种方法通过将检索信息整合到模型的提示中,增强了大型语言模型的应用效果和信息准确性。
在图像生成任务中,RetrieveGAN [44] 通过将检索信息(包括选定的图像片段及其对应的边界框)整合到生成器的输入阶段,提高了生成图像的相关性和准确性。IC-GAN [138] 通过将噪声向量与实例特征串联,调节生成图像的特定条件和细节。
在 3D 生成领域,RetDream [49] 最初利用 CLIP 检索相关的 3D 资产,在输入阶段有效地将检索内容与用户输入合并。
基于潜在表示的 RAG*(Latent Representation-based RAG)*
在基于潜在表示的 RAG 框架中,生成模型与检索对象的潜在表示进行交互,从而增强模型的理解能力和生成内容的质量。
FiD [34] 技术利用 BM25 和 DPR 来获取支持性段落。它将每个检索到的段落及其标题与查询连接起来,通过编码器分别处理它们。FiD 通过在解码器中融合来自多个检索段落的信息,而不是在编码器中处理每个段落,从而降低了计算复杂性,高效利用相关信息来生成答案。在文本内容处理领域,Fusion-in-Decoder 方法的应用超越了文本内容处理的范畴,展示了在处理代码、结构化知识和多模态数据集方面的巨大潜力和适应性。特别是在与代码相关的领域,诸如 EDITSUM [139]、BASH-EXPLAINER [140] 和 RetrieveNEdit [141] 等技术采用了 FiD 方法,通过编码器处理融合来促进整合。Re2Com [142]、RACE [143] 等方法还设计了多个编码器来处理不同类型的输入。在知识库问答(KBQA)领域,FiD 方法被广泛采用,展示了显著的有效性。UniK-QA [144]、DE-CAF [145]、SKP [146]、KD-CoT [147] 和 ReSKGC [148] 通过 Fusion-in-Decoder 技术有效提升了问答系统的性能。这表明通过将 RAG 用于 KBQA,可以显著提高问答系统的效率和准确性。在科学领域,RetMol [54] 采用 Fusion-in-Decoder 策略,在解码阶段整合信息,以增强生成的分子结构的相关性和质量。
Retro [35] 首创了通过“分块交叉注意力”整合检索文本的方法,这是一种将输入序列分段的新颖机制。每个块独立执行交叉注意力操作,从而减轻了计算负担。这种技术使模型能够有选择地检索和吸收不同文档用于不同序列段,促进了生成过程中的动态检索。这提升了模型的适应性,丰富了生成内容的上下文背景。在图像生成领域,交叉注意力机制在 RAG 框架中被广泛采用。诸如 Re-imagen [149]、KNN-Diffusion [150]、RDM [151] 和 LAION-RDM & ImageNet-RDM [152] 等方法利用交叉注意力来整合多个检索结果,有效提升模型的整体性能。另外,Li [153] 引入了 ACM,即文本-图像仿射组合模块,明显不采用任何形式的注意力机制。
与以往的知识方法不同,EaE [154] 赋予语言模型内化显式实体知识的能力。EaE 引入了一个特定于实体的参数化,通过在 transformer 架构中嵌入实体记忆层,优化推理效果。该层直接从文本数据中获取实体表示,利用稀疏检索策略根据它们的嵌入检索最近的实体,通过计算实体特定信息的聚合来完善模型的理解。与之不同,TOME [155] 将焦点转向全面的提及编码,优先考虑提及的细节而不仅仅是实体表示。它为维基百科中的每个实体提及精心生成编码,填充了一个包含大约 1.5 亿条目的存储库。这个存储库包括关键和值编码以及实体 ID,增强了检索更精细信息的能力。TOME 首先使用一个 transformer 块处理输入文本,然后使用具有记忆注意力层的 TOME 块,促进多方面信息源的综合,增强推理能力,即使对于未遇到的实体也是如此。Memorizing Transformers [30] 通过在 Transformer 层内部集成了 kNN 增强注意力机制,彻底改变了长文档处理。这种创新在输入序列处理中触发了 kNN 搜索,根据序列与存储的键-值对之间的相似性获取数据,从而提高性能而无需完全重新训练。这种方法不仅增强了处理效率,还扩展了模型的记忆跨度,使其能够从生成的输出中进行自检索,并进行广泛知识库或代码库的微调。Unlimiformer [156] 通过在预训练的编码器-解码器 transformer 框架中嵌入 k-nearest neighbors(kNN)索引,开创了处理长度不确定输入的先河。将输入标记的隐藏状态存储在 kNN 索引中,允许在解码过程中高效检索高度相关的标记。这种创新扩展了模型处理长序列的能力。在视频字幕领域,R-ConvED [47] 采用了卷积编码器-解码器网络架构,借助注意力机制处理检索到的视频-句子对,生成隐藏状态,随后生成字幕。CARE [159] 引入了概念检测器作为解码器的输入,并将概念表示嵌入混合注意力机制中。EgoInstructor [48] 利用门控交叉注意力将这些文本输入与编码视频特征整合,增强生成的针对自心视角视频内容的字幕的相关性和连贯性。
基于对数几率的 RAG(Logit-based RAG)
在基于对数几率的 RAG 中,生成模型在解码过程中通过对数几率结合检索信息。通常,对数几率通过模型求和或组合,以生成逐步生成的概率。
kNN-LM [36] 模型将预训练的神经语言模型与 k 最近邻搜索相结合。它利用预训练模型生成候选词列表及其概率分布,同时从数据存储库中检索,根据当前上下文找到最相关的 k 个邻居,从而增强原始语言模型的输出。该模型的核心创新在于其能够动态从广泛的文本语料库中检索信息,显著提高了其预测的准确性和相关性,特别是在处理罕见模式和适应各种领域方面。He [37] 提出了一个新框架,该框架基于仅在必要时执行检索操作,旨在通过自适应检索增强 kNN-LM 模型的推理效率。该框架通过训练一个检索适配器加速模型的推理速度,该适配器能够自动识别并消除某些情况下不必要的检索操作。这种方法允许模型根据当前上下文动态决定检索的必要性,从而在性能和效率之间取得平衡,显著提高推理速度同时保持模型性能。
与先前仅在测试时合并记忆的方法不同,TRIME [160] 在训练和测试阶段均实现了记忆合并,将批内示例视为可访问的记忆。TRIME 利用新的数据批处理和记忆构建技术有效利用外部记忆。TRIME 利用 BM25 分数将具有高词汇重叠的段落打包到同一批中,构建训练记忆以进一步优化模型性能。NPM [161] 是一个由编码器和参考语料库组成的非参数掩码语言模型。与传统模型在有限词汇上应用 softmax 不同,NPM 在语料库上建模非参数分布。编码器的作用是将语料库中的短语映射到固定大小的向量,通过检索填充 [MASK],找到与掩码位置最相似的短语。
除了文本领域,其他模态如代码和图像也利用了将检索内容与语言模型在最终输出阶段整合的方法。
对于代码到文本转换任务,Rencos [120] 并行生成多个从检索代码中提取的摘要候选项。然后使用编辑距离对这些候选项进行规范化,并计算最终概率以选择最符合原始代码的摘要输出。在代码摘要任务中,EDITSUM [139] 通过在概率级别集成原型摘要来提高摘要生成的质量。对于文本到代码任务,kNN-TRANX [162] 模型利用置信网络和元知识结合检索的代码片段。它利用 seq2tree 结构生成与输入查询紧密匹配的目标代码,从而提高代码生成的准确性和相关性。
在图像字幕任务中,MA [163] 结合了基于注意力的编码器-解码器,利用图像编码器提取视觉特征构建语义部分,并逐字解码与检索信息。
推测性 RAG(Speculative RAG)
推测性 RAG 寻找使用检索而非生成来节省资源并加快响应速度的机会。REST [31] 在推测性解码中用检索替换小模型,以生成草稿。GPTCache [38] 通过构建语义缓存来解决使用大型语言模型 API 时的高延迟问题。COG [165] 将文本生成过程分解为一系列复制粘贴操作,从检索文档中检索单词或短语而非生成。Cao 等人 [166] 提出了一种新范式,消除了最终结果对第一阶段检索内容数量和质量的依赖,通过直接检索短语级内容替换生成。
RAG 增强
在本节中,我们将介绍增强 RAG 性能的方法。我们根据增强目标将现有方法分为5个不同组别:输入、检索器、生成器、结果和整个流程。
输入增强
输入指用户的查询,最初输入到检索器中。输入的质量显著影响检索阶段的最终结果。因此,增强输入至关重要。在本节中,我们介绍两种方法:查询转换和数据增强。
- 查询转换: 查询转换可以通过修改输入查询来增强检索结果。Query2doc [167] 和 HyDE [168] 首先使用查询生成伪文档,然后将该文档用作检索的关键。这样做的优势在于伪文档将包含更丰富的相关信息,有助于检索更准确的结果。TOC [169] 利用递归检索增强模糊问题的澄清,构建澄清的问题树,从而生成这些模糊问题的全面答案。在构建这种树结构的过程中,TOC 利用自验证修剪方法确保每个节点的事实相关性。
- 数据增强: 数据增强指在检索之前提前改进数据,如删除不相关信息、消除歧义、更新过时文档、合成新数据等,可以有效提高最终 RAG 系统的性能。MakeAnAudio [43] 使用字幕和音频文本检索为无语言音频生成字幕以减轻数据稀疏性,并添加随机概念音频以改善原始音频。LESS [170] 通过分析梯度信息策略性地选择用于下游任务的最佳数据集,旨在最大化数据集对模型在应对指示性提示时微调性能的影响。
检索器增强
在 RAG 系统中,检索过程至关重要。通常情况下,内容质量越好,就越容易激发 LLMs 在上下文学习以及其他生成器和范式的能力。内容质量越差,就越容易导致模型幻觉。因此,在本节中,我们将讨论如何有效提高检索过程的效果。
- 递归检索: 递归检索是在检索之前将查询拆分,并执行多次搜索以检索更多且质量更高的内容的过程。Jagerman 等人 [171]、RAT [172] 和 ReACT [173] 都使用思维链 (COT) [174] 让模型逐渐分解查询并提供更丰富的相关知识。LLMCS [175] 将此技术应用于会话系统,并通过重写对话记录获得更好的检索结果。ACTIVERAG [176] 利用认知中枢机制巧妙地将检索到的知识与语言模型固有的认知系统相融合,从而优化 COT 过程并有效辅助生成答案。RATP [177] 利用蒙特卡洛树搜索技术进行多阶段决策,其中每个节点代表一个思维。系统根据这些思维的评分模型反馈指导动作选择。在节点扩展中,它通过提示将检索文档和思维合并到语言模型中以生成新的思维。Kuratov 等人 [178] 将 Transformer 与 RNN 结合,利用模型的中间结果作为检索内容。这个过程在 Transformer 的每一层都执行,从而显著扩展了文本窗口的长度,并有效地缓解了“中间丢失”的问题。
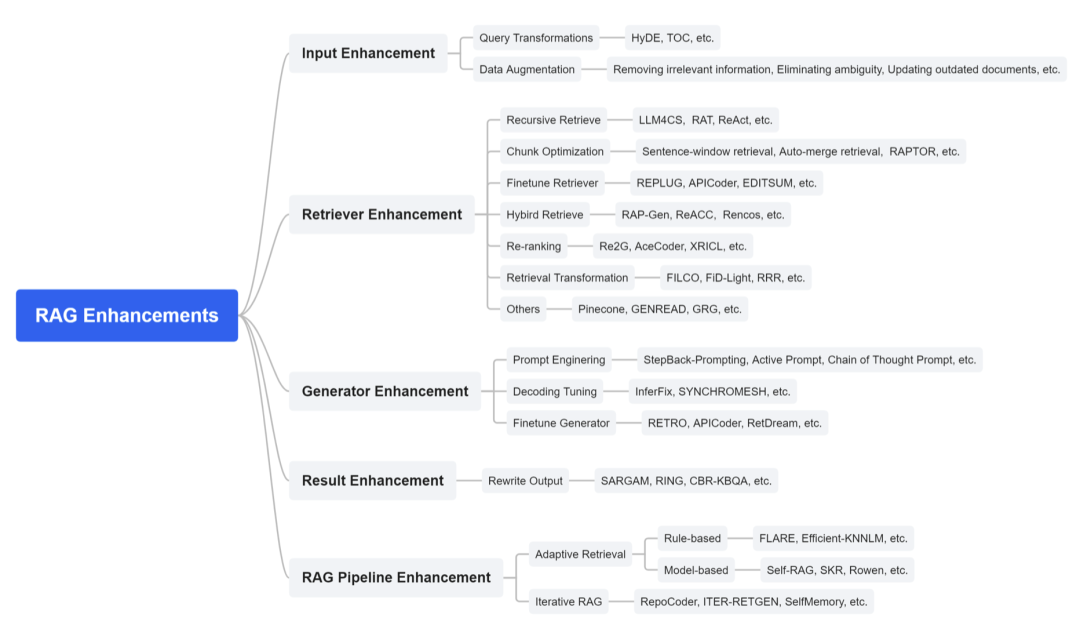
图7. RAG增强分类。
-
微调检索器:作为RAG系统的核心组件,检索器在整个系统操作过程中起着至关重要的作用。一个良好的嵌入模型可以使语义上相似的内容在向量空间中更加接近。检索器的能力越强,就能为后续的生成器提供更多有用的信息,从而提高RAG系统的有效性。因此,嵌入模型的能力对于RAG系统的整体有效性至关重要。
此外,对于已经具有良好表达能力的嵌入模型,我们仍然可以使用高质量的领域数据或任务相关数据对其进行微调,以提高其在特定领域或任务中的性能。REPLUG将LM视为黑匣子,并根据最终结果更新检索器模型。APICoder使用Python文件和API名称、签名、描述对检索器进行微调。EDITSUM微调检索器以减少检索后摘要之间的Jaccard距离。SYNCHROMESH在损失中添加AST的树距离,并使用目标相似性调整来微调检索器。R-ConvED使用与生成器相同的数据对检索器进行微调。Kulkarni等人应用infoNCE损失来微调检索器。
-
混合检索:混合检索表示同时使用多种检索方法或从多个不同来源提取信息。RAP-Gen和ReACC同时使用稠密检索器和稀疏检索器来提高检索质量。Rencos使用稀疏检索器在句法级别检索相似代码片段,并使用稠密检索器在语义级别检索相似代码片段。BASHEXPLAINER首先使用稠密检索器捕获语义信息,然后使用稀疏检索器获取词汇信息。RetDream先用文本检索,然后用图像嵌入进行检索。CRAG设计了一个检索评估器,评估检索文档与输入查询的相关性,根据不同的置信水平触发三种检索操作:如果被认为是正确的,则直接将检索结果用于知识完善;如果不正确,则转而进行网络搜索;如果模糊不清,则结合两种方法。为了提高问答任务的性能,Huang等人在检索阶段引入了两个指标,DKS(Dense Knowledge Similarity)和RAC(Retriever as Answer Classifier)。这些指标考虑了答案的相关性和基础知识的适用性。UniMS-RAG引入了一种新型的标记,称为“操作标记”,用于确定从哪里检索信息。
-
重新排序:重新排序技术指的是重新排列检索到的内容,以实现更大的多样性和更好的结果。Re2G在传统检索器之后应用一个重新排序模型。重新排序模型的作用是重新排列检索到的文档,其目的是减少由于将文本压缩为向量而导致的信息丢失对检索质量的影响。AceCoder使用选择器重新排序检索到的程序。引入选择器的目的是减少冗余程序并获得多样化的检索程序。XRICL在检索后使用基于蒸馏的范例重新排序器。Rangan利用量化影响度量,评估查询和参考之间的统计偏差,以评估数据子集的相似性,并使用此评估重新排序检索结果。UDAPDR利用大型语言模型以低成本大规模生成合成查询,使用这些合成查询集来训练特定领域的重新排序器。这些重新排序器充当多个教师,并通过多教师知识蒸馏技术创建单个检索器。LLM-R迭代地训练检索器,利用来自冻结LLM的反馈来对候选文档进行排名并训练奖励模型。检索器还基于知识蒸馏进行进一步训练。每次训练迭代都建立在前一个周期训练的检索器基础上,促进后续轮次的迭代优化。
-
检索转换:FILCO有效地过滤掉检索到的文本块中的无关内容,仅保留精确的支持内容。这个过程简化了生成器的任务,使其更容易预测正确答案。FiD-Light最初使用编码器将检索到的内容转换为向量,然后对其进行压缩,大大减少了延迟时间。RRR通过模板将当前查询与每一轮中的前k个文档集成,然后通过预训练的LLMs(如GPT-3.5-Turbo等)重构它。
-
其他:除了上述优化方法外,还有一些其他优化方法可用于检索过程。例如,元数据过滤是一种利用元数据(如时间、目的等)来过滤检索文档以获得更好结果的方法。GENREAD和GRG引入了一种新颖的方法,通过提示LLM根据给定问题生成文档来替代或改进检索过程。
生成器增强
在RAG系统中,生成器的质量往往决定了最终输出结果的质量。因此,生成器的能力决定了整个RAG系统有效性的上限。
- 提示工程:专注于改善LLM输出质量的提示工程技术,如提示压缩、Stepback Prompt、Active Prompt、Chain of Thought Prompt等,都适用于RAG系统中的LLM生成器。LLM-Lingua应用一个小型模型来压缩查询的总长度,以加快模型推断速度,减轻无关信息对模型的负面影响,并缓解“中间迷失”的现象。ReMoDiffuse通过使用ChatGPT将复杂描述分解为解剖文本脚本。ASAP在提示中添加范例元组以获得更好的结果。范例元组由输入代码、函数定义、分析该定义的结果及其相关评论组成。CEDAR使用设计的提示模板将代码演示、查询和自然语言说明组织到一个提示中。XRICL利用COT技术在跨语言语义解析和推理的中间步骤中添加翻译对。MakeAnAudio能够使用其他形式的输入,为后续处理提供更丰富的信息。
- 解码调优:解码调优指在生成器处理过程中添加额外的控制,可以通过调整超参数以实现更大的多样性,以某种形式限制输出词汇表等方式实现。InferFix通过调整解码器中的温度来平衡结果的多样性和质量。SYNCHROMESH通过实现一个完成引擎限制解码器的输出词汇表,以消除实现错误。
- 微调生成器:生成器的微调可以增强模型具有更精确的领域知识或更好地与检索器匹配的能力。RETRO固定检索器的参数,并在生成器中使用分块交叉注意机制来结合查询和检索器的内容。APICoder使用一个新的混合API信息和代码块的文件对生成器CODEGEN-MONO 350M进行微调。CARE首先使用图像数据、音频数据和视频文本对编码器进行训练,然后微调解码器(生成器)以减少标题损失和概念检测损失,期间编码器和检索器被冻结。Animate-A-Story优化视频生成器使用图像数据,然后微调一个LoRA适配器来捕获给定角色的外观细节。Ret-Dream使用渲染图像微调一个LoRA适配器。
结果增强
在许多场景中,RAG的最终结果可能未达到预期效果,一些结果增强技术可以帮助缓解这一问题。
RAG管道增强:
- 自适应检索: 一些关于RAG的研究和实践表明,检索并不总是有利于最终生成的结果。当模型本身的参数化知识足以回答相关问题时,过度的检索会导致资源浪费,并可能增加模型的混乱。因此,在本章中,我们将讨论两种确定是否检索的方法,分别称为基于规则和基于模型的方法。
- 基于规则: FLARE [214] 通过生成过程中的概率主动决定是否以及何时进行搜索。Efficient-KNNLM [37] 结合了KNN-LM [36] 和NPM [161] 的生成概率,并使用超参数 λ 来确定生成和检索的比例。Mallen等人 [215] 在生成答案之前对问题进行统计分析,允许模型直接回答高频问题,并引入RAG来回答低频问题。Jiang等人 [216] 研究了模型不确定性、输入不确定性和输入统计,全面评估模型的置信水平。最终,基于模型的置信水平,决定是否进行检索。Kandpal等人 [217] 通过研究训练数据集中相关文档数量与模型掌握相关知识程度之间的关系,帮助确定是否需要检索。
- 基于模型: Self-RAG [127] 使用训练好的生成器根据不同指令确定是否执行检索,并通过自反思标记评估检索文本的相关性和支持程度。最终,根据评论标记评估最终输出结果的质量。Ren等人 [218] 使用“判断提示”来确定LLMs是否能够回答相关问题以及它们的答案是否正确,从而帮助确定是否需要检索。SKR [219] 利用LLMs自身的判断能力事先判断是否能够回答问题,如果能够回答,则不进行检索。Rowen [220] 将模型作为一个复杂的多语言检测系统,评估对跨多种语言提出的相同问题的答案的语义连贯性。在检测到不一致性时,决定检索外部信息,从而增强推理过程并纠正不准确之处。相反,当回答一致时,系统维持最初生成的答案,该答案源自内部推理。AdaptiveRAG [221] 根据一个较小的LM对查询复杂性动态决定是否进行检索。
- 迭代RAG: RepoCoder [222] 将迭代检索-生成管道应用于代码补全任务,以更好地利用散布在不同文件中的有用信息。在第i次迭代期间,它通过先前生成的代码增强检索查询,并获得更好的结果。ITER-RETGEN [223] 以迭代方式协同检索和生成。生成器的当前输出在一定程度上反映了它仍然缺乏的知识,而检索可以检索缺失信息作为下一轮的上下文信息,有助于提高下一轮生成内容的质量。SelfMemory [224] 以迭代方式使用检索增强生成器创建一个无限的记忆池。随后,使用记忆选择器选择一个输出,然后作为后续生成轮的记忆。
应用
在本章中,我们将介绍不同领域中流行的RAG应用。
文本RAG
在本节中,我们将介绍使用RAG方法进行文本生成的一些热门工作。
问答
问答涉及从广泛而全面的文本来源中提供对提出问题的回答的过程。FID [34] 和REALM [32] 根据查询识别出最相关的k个文章片段,并将每个片段连同问题转发给LLMs生成k个响应。然后将这些响应合成为最终答案。Toutanova等人 [225] 将REALM中的文本语料库替换为知识图中的子图,取得了令人印象深刻的结果。Atlas [29] 展示了利用RAG来辅助LLMs在开放域问答任务中显著增强少样本学习能力。如图9所示,RETRO [35] 使用注意机制将问题与模型内相关的检索文档整合,生成最终答案。SKR [219] 发现使用RAG并不总是有利于问答,因此探索引导模型评估其对相关知识的掌握程度,随后调整其对外部资源的使用以增强检索。TOG [226] 引入了一种创新的知识图增强LLM框架,通过促进LLMs与知识图之间的互动,并通过波束搜索扩展推理路径空间来取得优异表现。NPM [161] 首创使用非参数数据分布代替softmax层,使参数更少的模型能够有效执行。Self-RAG [127] 通过学习辨别何时进行检索、评估检索内容的相关性以及使用四种反思标记评估最终生成的结果来提高答案质量。CL-ReLKT [227] 使用语言通用编码器弥合跨语言的问题-文档对之间的差距,从而更好地利用多语言数据。CORE [228] 通过引入一种新颖的密集段落检索算法和多语言自回归生成模型,缓解了语言资源差异,最后,EAE [154] 通过检索查询实体的实体嵌入并将其与隐藏状态集成以进一步处理,提高答案质量。UR-QA [229] 发现,当遇到未见过的问题时,检索QA对有更好的最终效果;当遇到以前未见过的问题时,检索文本块表现更好。因此,建议同时检索QA对和文本块,并通过比较校准的置信度选择最终答案。ARM-RAG [230] 通过检索过去成功推理步骤在解决基础数学问题方面表现出色。DISC-LawLLM [231] 通过法律三段论提示策略构建了一个监督微调数据集,使模型能够获得最新法律信息的支持。RAG-end2end [232] 对检索器(DPR)和生成器(BART)进行同时训练,以优化端到端问答任务的性能并促进领域适应。MultiHop-RAG [233] 旨在从各种不同文档中提取相关信息,将这些知识汇总,为生成器提供必要的上下文,以生成对查询的明确答案。
事实验证
事实验证涉及评估信息的真实性,这在自然语言处理(NLP)、信息检索和数据挖掘等学科中是一个关键功能。在当今数字化时代,特别是在社交媒体和在线新闻平台上,数据呈指数级增长,未经核实的信息迅速传播。事实验证在对抗虚假新闻、欺骗性内容和谣言传播方面发挥着重要作用,从而维护信息领域的完整性,确保公众获取准确的知识。因此,自动化事实验证系统具有巨大重要性,具有广泛的应用和重要的实际价值。
CONCRETE [234] 利用跨语言检索机制,利用丰富的多语言证据,有效弥合事实核查数据集中语言资源不足的差距。Hagstro¨m等人 [235] 在LLaMA [236] 和Atlas [29] 上证明,搜索增强对解决不一致问题比增加模型大小更有益。
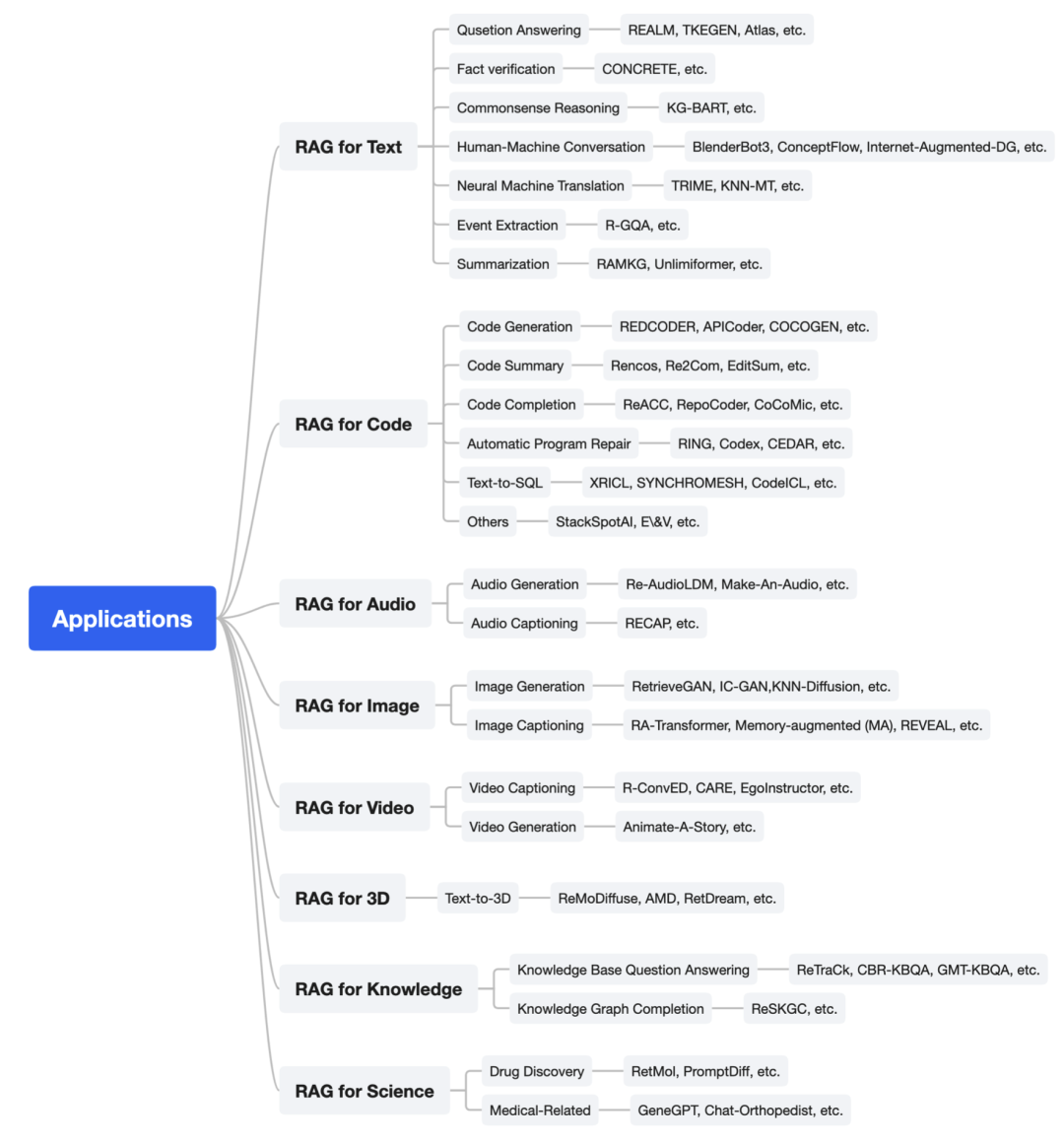
Fig. 8. 多模态多应用分类法。
常识推理
常识推理涉及机器以类似人类的方式推断或决策问题或任务的能力,借助其获得的外部知识及其应用。然而,广泛的常识知识范围和推理过程的复杂性使得常识推理成为自然语言处理领域中一个长期具有挑战性和突出的研究领域。
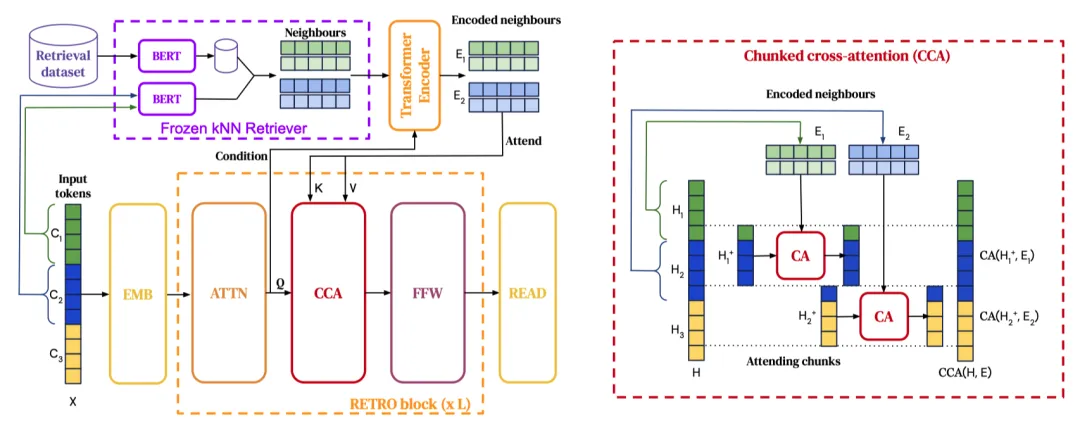
Fig. 9. RETRO [35] 模型架构。
人机对话:
人机对话涵盖了机器理解自然语言并熟练运用这一技能与人类进行无缝交流的能力。这种能力在人工智能和自然语言处理领域代表着重大挑战,并提供了广泛的实际应用。因此,人机对话一直是许多学者研究的焦点。
ConceptFlow [239] 利用常识知识图来构建对话,根据注意力分数引导对话流程,推动对话向前发展。即使模型参数大幅减少,这种方法也取得了可观的成果。蔡等人 [240] 将文本生成任务重新构想为填空测试,通过检索和提炼过去对话历史的精髓,取得了显著的成果。Komeili 等人 [241] 通过利用先进的搜索引擎技术从互联网获取相关内容,提升了对话生成的质量。BlenderBot3 [242] 扩大了搜索范围,不仅挖掘相关的互联网内容,还包括本地对话历史,并采用实体提取等技术来提炼生成对话的质量。Kim 等人 [243]、PARC [244] 和 CREA-ICL [245] 通过整合跨语言知识来改进非英语对话的质量,有效解决非英语数据集的稀缺问题,并提升生成对话的质量。CEG [246] 通过后处理机制解决了幻觉问题,通过检索验证LLM生成的答案。如果答案正确,检索到的文档将作为参考添加到原始答案中;如果答案缺乏可靠的参考资料,它将引导LLM重新回答问题。
神经机器翻译
神经机器翻译(NMT)是将文本从源语言自动翻译为目标语言的过程。这是自然语言处理领域中的一个关键任务,也是人工智能追求的一个重要目标,具有相当大的科学和实际意义。
蔡等人 [247] 提出了一种创新方法,利用单语语料库和多语言学习技术,挑战了神经机器翻译对双语语料库的传统依赖。这种方法确保检索系统提供充分信息的同时,同时优化检索机制和翻译模型,最终取得了令人瞩目的性能。KNN-MT [248] 通过计算向量空间距离在标记级别执行翻译任务。TRIME [160] 通过联合训练检索系统和生成模型有效地减小了训练和推理阶段之间的差异,从而提高了翻译的准确性。
事件抽取
事件抽取是自然语言处理(NLP)中的一项专门任务,专注于从非结构化文本数据中准确定位和提取特定事件类型的实例。事件通常以中心动作或谓词以及相关实体为特征,这些实体可以包括参与者、时间指示器、地点和其他相关属性。事件抽取的目标是将文本中嵌入的细微细节转换为结构化格式,从而促进高级分析、高效信息检索和实际的下游应用。
R-GQA [249] 采用基于检索的方法来增强给定问题的上下文,通过识别和利用存储库中与当前查询处理相关的最接近的问答对,丰富了用于处理当前查询的信息。
摘要
在自然语言处理领域,摘要是一项旨在从冗长文本中提炼基本信息并生成简洁连贯摘要的任务,概括了主要主题。摘要使用户能够快速把握文本的要点,从而节省阅读大量材料所需的时间。摘要有两种主要方法:抽取式和生成式。
抽取式摘要涉及从源文本直接自动选择和编制关键短语。关键短语简洁地捕捉了文本的主题、内容或观点,通常由一个或几个词组成。生成关键短语对于理解、分类、检索和组织文本信息至关重要。它广泛应用于搜索引擎优化、学术研究、文本摘要等领域。这种技术避免了创建新句子,而是重新利用原始文本中的片段。另一方面,生成式摘要涉及理解原始文本的含义,并将其重新组织成新句子。这种方法可以更流畅地传达源文的意图,但由于其复杂性,在实施方面存在更大的挑战。
RAMKG [250] 有效利用全面的英语语料库来增强非英语环境中关键短语生成的性能。它通过增强从不同语言的文本中提取的共享相似主题的关键字的对齐来实现。Unlimiformer [156] 通过检索和利用前k个最相关的隐藏状态来解决基于transformer模型的输入长度限制问题,从而扩展模型处理更长输入的能力。
RPRR [251] 采用检索-规划-检索-阅读方法来克服LLM面临的有限上下文窗口限制,利用检索信息生成新兴事件的高质量维基百科文档。RIGHT [252] 选择在不同数据集中使用不同类型的检索器来增强生成器,从而有效提高简单部署中自动生成标签的质量。
用于代码的RAG
历史上在与代码相关的任务中通常采用分离的检索和生成方法。对于检索,可以使用抽象语法树或文本编辑距离来识别相似的代码片段,而自然语言可以通过稀疏或密集检索来检索。对于生成,序列到序列模型(如LSTM和Transformers)被用于在顺序数据形式中生成代码或自然语言。最近的RAG研究结合了检索和生成技术,以提高整体性能。
代码生成
代码生成的目标是将自然语言描述转换为代码实现,可以看作是文本到代码的过程。因此,LSTM和transformer模型被广泛用于生成器。是否使用特定于代码的检索还是基于文本的检索取决于要搜索的内容。检索结果也可以在生成过程中应用。RECODE [119] 使用编辑距离检索相似的自然语言描述,然后从检索到的句子对应的目标代码抽象语法树中提取 n-gram 动作子树。在基于 LSTM 的生成过程中,处理过的子树模式被利用来增加每个解码步骤的相应单词概率。kNN-TRANX [162] 使用 seq2tree 模型 BertranX [265] 将自然语言转换为代码抽象语法树。它为每个代码前缀和自然语言对构建一个数据存储;即对于每个自然语言-代码对,第 i 个上下文的上下文表示是通过 seq2tree 模型对自然语言和代码的第 i 个前缀进行编码获得的。在生成过程中,在每个解码步骤中,隐藏表示在数据存储中搜索以形成新的概率,然后使用置信网络将其与 seq2tree 模型的输出结合起来。
ToolCoder [266] 执行正常的代码生成,并在遇到特殊 ¡API¿ 令牌时进行在线搜索或离线检索。这种范式使模型学会利用 API 工具。
代码摘要
代码摘要的目标是将代码转换为自然语言描述,这是一个代码到文本的过程。与代码生成相同,许多序列到序列模型被应用作为生成器。
在许多研究中,检索结果被额外的编码器处理。Re2Com [142] 和 EditSum [139] 都使用稀疏检索 BM25 检索相似代码,并使用 LSTM 生成摘要。如图 10 所示,它们分别对输入、检索到的代码和相应摘要进行编码,然后在解码器中组合中间表示或概率。HGNN [267] 使用代码编辑距离进行检索,并用混合 GNN 替换代码的编码器,应用于它们的代码属性图 (CPG) [268]。RACE [143] 旨在为代码差异生成提交消息。它利用密集检索获取相似示例,并使用变压器模型进行生成。它还为输入、检索到的代码差异和相应提交消息使用三个编码器,然后在输入解码器之前将结果组合。BASHEXPLAINER [140] 采用类似的思路。其密集检索模块基于 CodeBert [25],对于生成,直接融合了来自 CodeBert 的输入和相似代码的输出表示以供基于变压器的解码器使用。READSUM [269] 使用 Levenshtein 距离检索相似代码,对检索到的对进行代码编码和摘要编码,然后使用融合网络的解码器生成摘要。
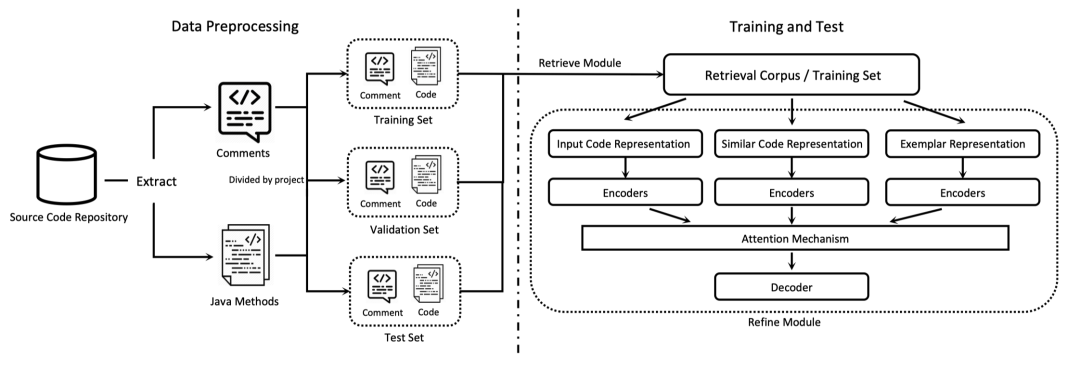
图 10. Re2Com [142] 模型的架构。
RAG 用于上下文学习,检索相似示例并构建生成提示,也适用于代码摘要。REDCODER [39] 既适用于代码生成又适用于摘要,并将检索器替换为 GraphCode- Bert [105] 用于代码摘要任务。ASAP [208] 使用 BM25 检索相似代码,并使用 GPT 模型生成摘要。与上述范式类似,关于伪代码生成的研究 [270] 将检索到的代码作为生成的输入,然后将结果替换为原始输入。SCCLLM [271] 通过语义、句法和基于词汇的检索检索相关代码片段,然后通过 LLM 为智能合同注释生成形成上下文提示。UniLog [272] 检索相似代码片段及其日志语句,用于日志语句生成的上下文学习。
基于 Logit 的 RAG 也在代码摘要中盛行。Rencos [120] 利用两种不同方法检索相似代码片段,即抽象语法树 (AST) 之间的句法相似性和密集表示之间的余弦相似性。对于生成器,它采用基于注意力的 LSTM。对于代码输入和两个检索结果,分别有三个编码器-解码器模型,然后将概率组合用于最终生成。CoRec [273] 生成给定代码差异和检索到的相似代码差异的提交消息。多个 LSTM 生成器处理输入代码差异和检索到的代码差异,然后将概率相加以进行最终生成。kNN- Transformer [274] 通过将代码输入编码到编码器-解码器生成器中获得上下文向量,然后获得三部分 logits:第一部分来自向量搜索,第二部分来自普通 Transformer,第三部分是从输入中保留稀有标记的复制机制。Tram [275] 在令牌级和句子级都涉及检索。它将源代码和相应的 AST 编码为隐藏状态表示;对于令牌级别,它在数据库中检索相似表示以形成下一个令牌预测 logits;对于句子级别,它使用相似代码进行自回归生成 logits;还将原始自回归生成 logits 添加进去。CMR-Sum [276] 使用编码器-解码器模型生成摘要。它在检索到的摘要表示和生成的摘要之间进行交叉注意力,并将 logits 添加到原始变压器 logits 中以进行最终分布。
代码完成
代码完成可以被视为“下一个句子预测”任务的编码等效。早期关于函数完成的尝试 [277] 使用 DPR 检索相关的模板函数,使用函数文档字符串将信息连接为代码生成器 BART 的输入。ReACC [133] 检索相似代码以构建生成提示。对于检索,它使用混合检索器,结合稀疏和密集检索;对于生成,它使用 CodeGPT-adapted [278]。RepoCoder [222] 进一步执行迭代检索和生成,以弥合检索上下文和预期完成目标之间的差距。在每次迭代中,对于检索,代码查询会与先前生成的代码相结合;对于生成,提示由最新检索到的代码与代码查询组合形成。除了在提示中组合检索结果外,检索和编辑框架 [141] 首先使用密集检索检索相似的训练示例,然后分别对输入和检索结果进行编码,最后通过注意力将它们组合用于后续 LSTM 解码器。CoCoMic [279] 为整个代码项目构建项目上下文图,并检索输入源代码的前 k 个邻居。它生成源代码和检索到的上下文的表示,然后联合处理嵌入以完成代码。RepoFusion [280] 遵循 Fusion-in-Decoder 的思想;它使用多个编码器将检索到的存储库上下文和未完成的代码输入,然后通过解码器融合它们并生成结果。KNM- LM [281] 使用相同的模型进行检索编码和生成,然后使用贝叶斯推断组合 logits。EDITAS [282] 旨在生成断言。它检索相似查询及其断言,编码编辑序列(从检索到的查询到原始查询)和检索到的断言,然后将信息融合用于解码器生成。De-Hallucinator [283] 首先生成代码片段而不进行检索,然后在生成内容时检索相关的 API 引用。在第二次传递中,检索到的 API 引用与提示结合以进行更好的生成。REPOFUSE [284] 使用理由上下文和检索到的相似代码构建提示。为了适应输入长度限制,它保留与查询最相关的上下文。
文本到SQL和基于代码的语义解析
语义解析是将自然语言话语转换为明确的结构化含义表示的任务,通常会利用编程语言来增强这一过程。SQL不仅是一种编程语言,还可以被视为一种结构化表示,因此我们将文本到SQL(代码生成的特例)放在本小节中。相关研究都应用了基于查询的RAG。XRICL [194] 关注将非英语话语翻译为SQL查询的问题。它通过密集检索搜索和重新排列英语话语,然后利用Codex生成SQL查询的提示。SYNCHROMESH [121] 提出了受限语义解码,以在生成SQL或其他语言时强制执行丰富的句法和语义约束。它利用抽象语法树(AST)之间的相似性来微调密集检索器S-Bert。在推理过程中,检索类似的自然语言和SQL以形成GPT-3的提示。CodeICL [286] 使用Python进行语义解析,并通过结构化领域描述增强了GPT生成的提示。在少样本学习设置中,它利用BM25稀疏检索找到类似的训练示例。RESDSQL [287] 使用交叉编码器对模式进行排名,然后将排名的模式包含到提示中以生成SQL骨架和SQL查询。ReFSQL [288] 检索相关问题和相应的SQL以增强文本到SQL的生成。它涉及结构增强的检索器与模式链接,以及马氏距离对比学习以提高检索性能。ODIS [289] 使用BM25检索域内和域外演示,然后将它们包含在上下文学习中以生成SQL。另一项工作 [290] 检索相似和多样的演示,然后构建用于上下文学习生成SQL的提示。MURRE [291] 进行多跳检索-重写,通过密集检索检索相关表,然后重写以生成新的表格化问题。最后,一个排名模块整合检索结果并选择顶部表格用于文本到SQL模块。CodeS [292] 以粗到精的方式从表数据库中检索相关信息,然后将检索到的值包含在提示中,用于微调和推理。
其他
还有一些其他与代码相关的任务采用了RAG范式。在数值推理任务中,Chain-of-Thought被替换为程序作为中间推理步骤,并在下游LLMs的提示中增加了基于密集检索的类似示例。De-fine [294] 试图使用程序解决复杂任务。它遵循SKCODER中的范式,检索相关的查询和代码对,然后为真实程序生成草图模板。生成后,它结合反馈以改进相同生成器的答案。被视为最佳结果的改进程序被添加回代码库以供后续服务。E&V [295] 利用基于LLM的代理进行程序静态分析。该代理使用源代码检索、伪代码执行、执行规范验证等工具形成中间结果。检索是通过AST模式匹配实现的。Code4UIE [296] 利用代码表示进行信息提取任务。它通过密集检索检索相关示例,并使用检索到的查询及其相应代码构建上下文学习提示。StackSpotAI [297] 构建了一个AI编码助手,涵盖许多与代码相关的任务。它实现了一个RAG组件,识别最相关的信息片段,作为GPT生成的上下文。InputBlaster [298] 旨在生成可能导致移动应用崩溃的异常文本输入。它将检索到的相关错误文本与有效输入结合起来,形成生成的提示。
用于音频的RAG
音频生成
音频生成的目标是通过自然语言输入生成音频。ReAudioLDM [158] 采用密集检索器CLAP [26],给定输入提示检索相似的字幕-音频对。如图 11 所示,生成器、潜在扩散模型和基于VAE的解码器将输入文本和检索到的对的表示作为输入,并生成输出音频。Make-An-Audio [43] 使用密集检索器CLAP [26] 来增强数据,根据自然语言文本检索相关音频。然后为基于扩散的文本到音频模型训练构建伪提示。
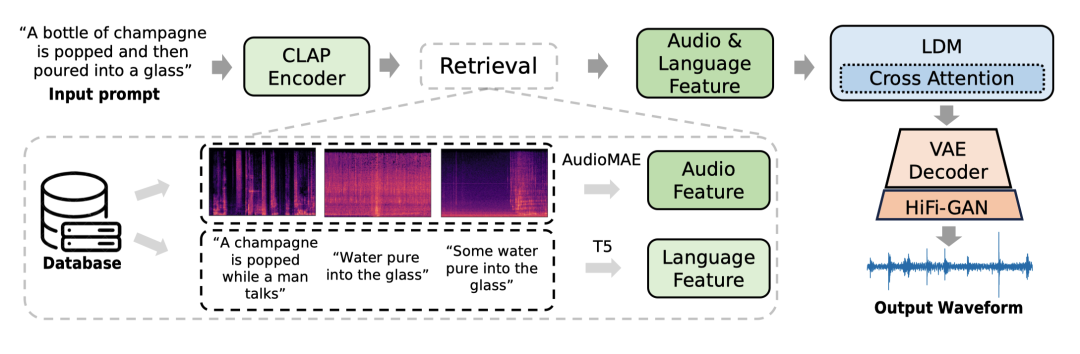
图11. Re-AudioLDM [158] 模型架构。
音频字幕
音频字幕的目标是生成与音频数据相关的自然语言数据,基本上是一个序列到序列的任务。RECAP [299] 利用CLAP [26] 检索给定音频数据的相关字幕。检索到的字幕随后包含在GPT-2模型的提示输入中,该模型通过交叉注意力与音频嵌入进行交互。在 [42] 中,采用密集检索器VGGish [107] 生成音频数据的密集嵌入,采用GPT-2生成与类似音频配对的检索到的字幕的表示。在获取音频和字幕的表示后,额外的多头注意力块和线性层融合所有信息并生成输出。一些研究将音频模态转换为文本,以利用LLMs的进展。它们利用深度检索模型,将模态对齐到相同的潜在空间,用于下游文本生成。
用于图像的RAG
图像生成
检索过程不仅有助于产生高质量的图像,即使对于罕见或未见主题,而且还减少了参数数量和计算开销。对于基于GAN的模型,RetrieveGAN [44] 使用可微分检索过程选择与生成兼容的图像块,采用Gumbel-softmax技巧和端到端训练。IC-GAN [138] 将数据建模为围绕每个训练实例的条件分布的混合,同时在生成器和鉴别器上对这些实例进行条件化,可以通过交换类标签或条件实例来控制语义和风格。最近,扩散模型在图像生成上击败了GANs。KNN-Diffusion [150] 在没有文本数据的情况下训练文本到图像扩散模型,通过将模型条件化为来自图像数据库的CLIP联合嵌入的实例和k个最近邻居。这些k-NN嵌入桥接了文本-图像分布差距,并允许通过交换数据库来自不同领域的图像生成。类似地,RDM [151] 将扩散或自回归模型条件化为外部图像数据库的CLIP嵌入。它实现了对类标签、文本提示和零样式化的事后条件化。除了仅检索图像外,Re-imagen [149] 对文本提示和检索到的图像-文本对进行条件化,用于文本到图像生成。还提出了交替的无分类器指导,以平衡文本提示和检索条件之间的对齐。为了避免CLIP嵌入的信息丢失并访问所有视觉条件,Retrieve&Fuse [303] 在U-Net的每个注意力块之前将检索到的条件图像和噪声图像连接起来,通过自注意力进行交互。RPG [78] 检索代表性图像以构建信息丰富的上下文示例(即图像-区域对),并利用多模态Chain-of-Thought推理规划出互补的子区域,用于组合文本到图像扩散。
图像字幕
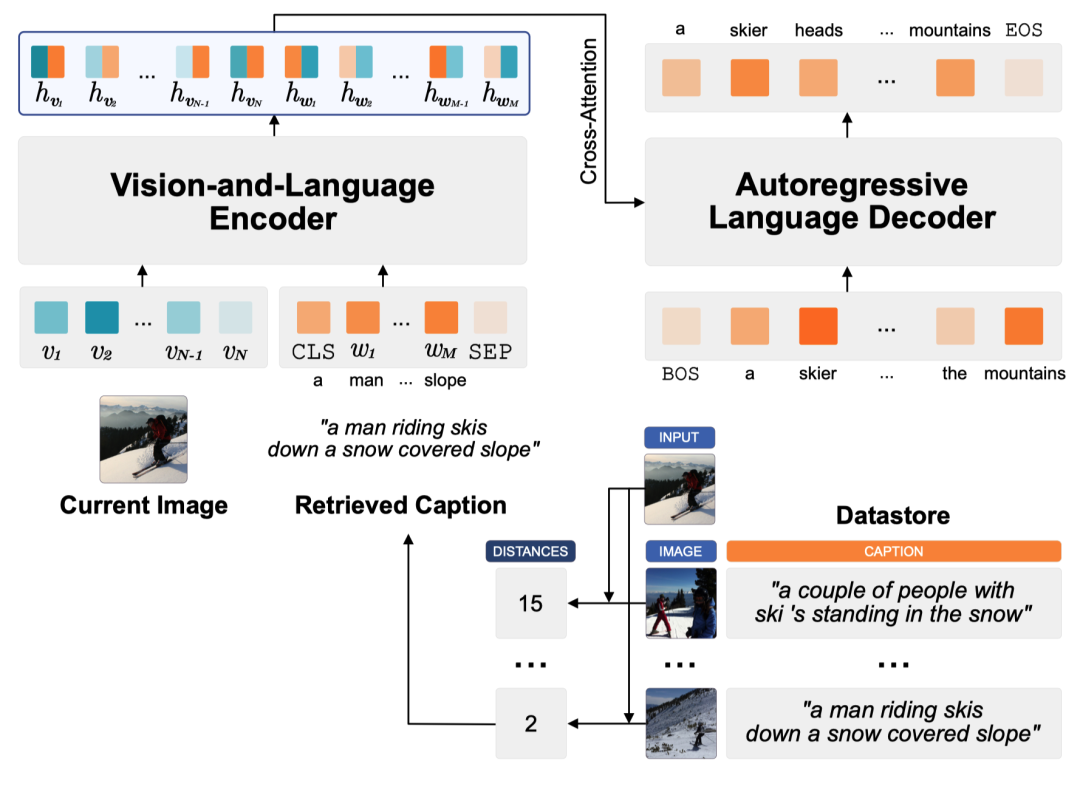
图 12. EXTRA 模型的架构 [307]。
其他
对于其他与图像相关的任务,也存在许多利用检索增强的工作。在视觉问答(VQA)方面,PICa [310] 利用 GPT-3 的隐式知识检索和推理能力,将图像转换为文本描述,然后提示 GPT-3 基于这些描述和问题预测答案。RA-VQA [311] 发现了以往工作中检索训练与答案生成分开的局限性,并提出了一种集成可微检索和答案生成的联合训练方案,实现端到端训练。对于基于视觉的对话,基于KNN的信息提取(KIF)[312]增强了用于对话建模的生成式Transformer。每个KIF模块学习读操作以访问固定的外部知识。Maria [313],一个神经对话代理,通过利用从大规模图像索引中检索的视觉经验作为额外上下文,增强了对话生成。对于多模态机器翻译,旨在利用多模态信息改进NMT,[314]在短语级别上整合视觉信息以解决句子-图像配对的稀疏性,利用条件VAE从句子-图像数据集中过滤出冗余的视觉信息。
视频相关的RAG
视频字幕生成
视频字幕生成是用描述性话语描述视觉内容。R-ConvED [47] 引入了检索增强机制以促进单词预测。它使用双编码 [109] 进行视频文本检索,并提出了一个卷积编码器-解码器网络进行生成。对于给定的输入视频,R-ConvED首先从训练集中检索出前k个相关句子及其对应的视频,然后将这些句子对和输入视频分别输入生成器。通过类似注意力的读操作组合获得的解码器隐藏状态,从而可以使用最终表示来预测目标单词。CARE [159] 利用视觉编码器、音频编码器和文本编码器分别处理帧、音频和检索到的文本。它使用CLIP作为检索器,变压器解码器作为生成器。三种模态的嵌入被结合起来增强解码器,产生全局语义指导,关注输入嵌入,以及局部语义指导,关注注意力层。EgoInstructor [48] 为第一人称视角视频生成字幕。它通过密集检索检索相关的外中心视频和相应的文本,然后通过基于CLIP的视觉编码器和基于变压器解码器的瓶颈模块对输入的自我中心视频和检索到的外中心视频进行编码。然后通过基于解码器的LLM生成字幕,该解码器以检索到的文本作为输入,并在门控交叉注意力层中与编码视频交互。
视频生成
文本到视频生成是根据自然语言描述生成视频。如图 13 所示,Animate-A-Story [210] 开发了一个框架,可以基于文本生成高质量的叙事视频。它首先将文本分解为单独的情节,并使用LLM装饰描述。然后通过密集检索器 [110] 为每个情节检索相关视频。它通过一个潜在扩散模型生成视频,包括两个分支:一个文本编码器CLIP,以及一个结构编码器,该编码器以估计的检索视频深度作为结构控制。
其他
对于其他与视频相关的任务,也存在许多利用检索增强的工作。对于视频问答(VideoQA),MA-DRNN [315] 利用带有外部存储器的可微分神经计算机(DNC)来存储和检索问题和视频中的有用信息,并建模长期的视觉-文本依赖关系。给定视频输入,R2A [316] 通过多模态模型(例如CLIP)检索语义上相似的文本,并用问题和检索到的文本查询LLM。对于视频基础对话,[317] 提出了TVQA+数据集,该数据集能够检索相关时刻和视觉概念以回答关于视频的问题,并提出了利用它的基于空间-时间答案者与基于证据的STAGE。VGNMN [318] 也从视频中提取视觉线索,而检索是使用在先前对话中实体和动作参数化的神经模块网络进行的。VidIL [319] 利用图像语言模型将视频内容转换为具有少量示例的时间感知提示,用于各种视频语言任务,包括视频字幕生成、视频问答、视频字幕检索和视频未来事件预测。值得注意的是,对于可信的自动驾驶,RAG-Driver [320] 将MLLM基于存储在内存数据库中的相关专家演示,以生成驾驶行为解释、理由和控制信号预测。
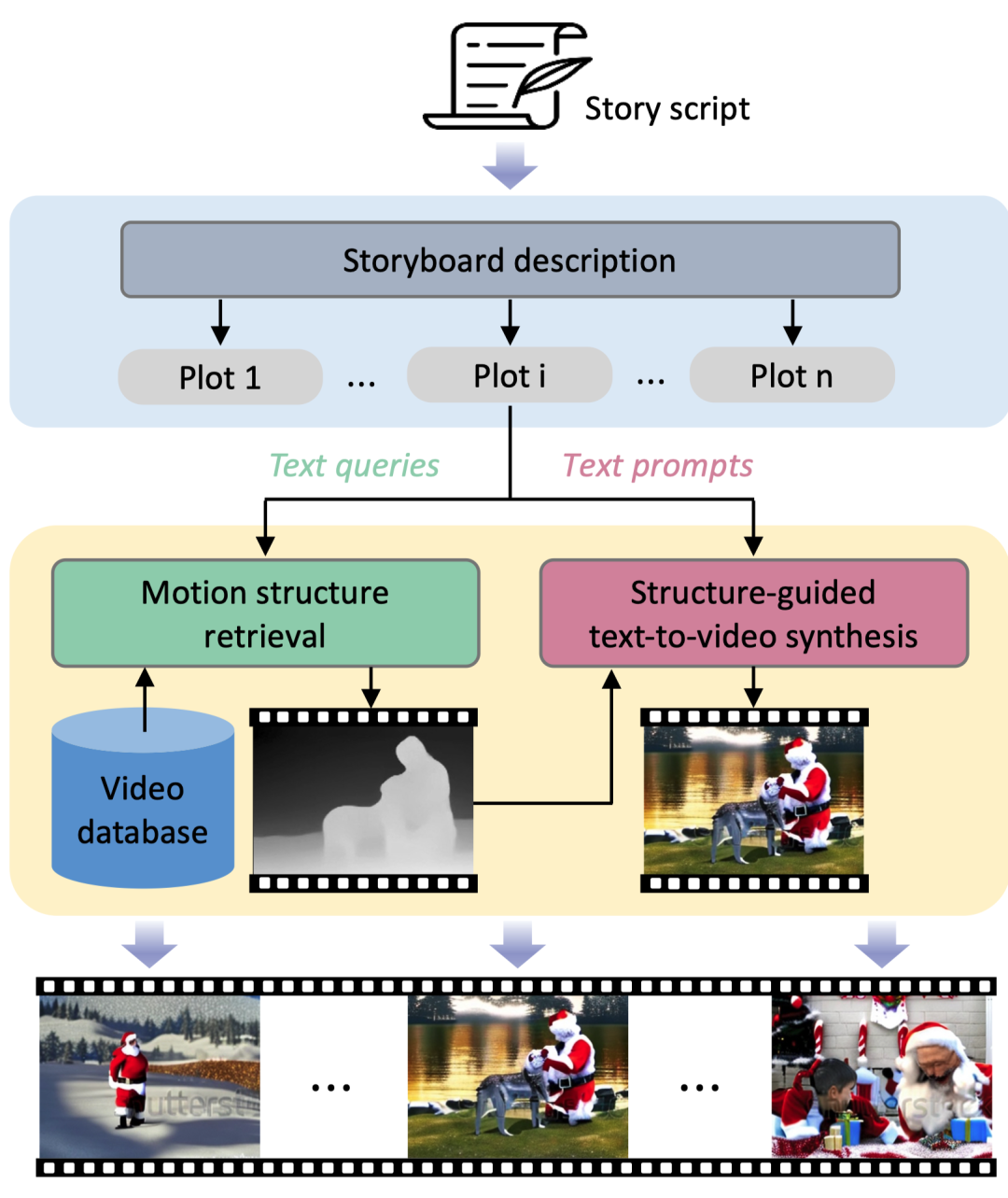
图 13. Animate-A-Story [210] 模型的架构。
用于3D的RAG*
文本到3D
检索可以应用于增强3D内容的生成。ReMoDiffuse [50] 旨在使用扩散模型生成动作。它首先通过CLIP给定文本输入检索相关的动作实体,然后通过语义调制注意力层利用文本和检索到的实体的信息。AMD [157] 为保真度和多样性设计了两个分支的运动扩散。如图 14 所示,第一个分支将原始提示文本输入进行扩散;第二个分支将输入文本分解为解剖脚本,并检索类似的参考动作进行扩散。进一步应用基于变压器的融合模块来自适应平衡两个分支的结果。RetDream [49] 旨在进行通用的3D生成,利用检索到的3D资产来增强从2D扩散模型中进行变分分数蒸馏的过程。给定一个查询输入,它通过CLIP检索相关的3D资产,然后利用检索到的资产提供几何先验和适应的2D先验。具体来说,检索到的资产不仅为粒子的分布初始化增加额外速度,还通过低秩适应帮助优化2D扩散模型。
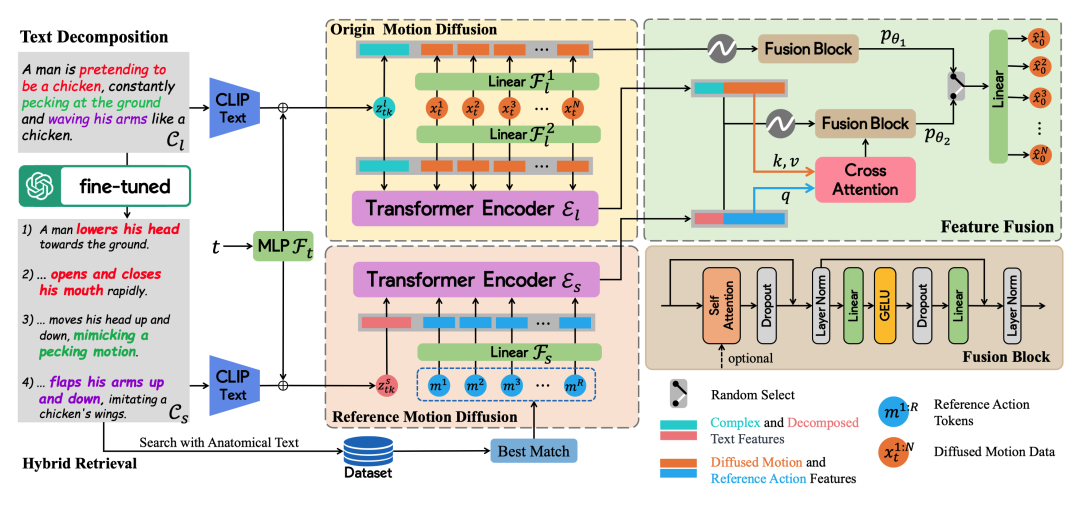
图 14. AMD [157] 模型的架构。
用于知识的RAG
结构化知识,包括知识图和表格,在与语言相关的任务中被广泛使用。它通常作为检索源用于增强生成。除了常规的稀疏检索和密集检索外,还应用了NER(命名实体识别)技术来识别查询中的特定实体,并利用图感知邻居检索来提取相关实体和关系。
知识库问答
知识库问答(KBQA)通常利用知识库来识别问题的正确答案。许多语义解析方法被提出,给定一个问题生成逻辑形式(例如SPARQL)。潜在表示为基础的 RAG 在知识库问答中也被广泛应用。ReTraCk [332] 使用提及检测链接实体,并使用密集检索器 Bert 检索模式项。然后通过 LSTM 生成逻辑形式,通过特定于知识的规则整合检索到的项。SKP [146] 将三元组与查询连接起来,并在推理中使用融合解码器技术。它在三元组上添加了一个预训练阶段,使用基于知识的 MLM 损失和与检索到的项相关的知识对比损失。DECAF [145] 将资源描述格式知识库三元组转换为句子,然后将具有相同头实体的句子连接成文档。它使用 BM25 稀疏检索或 Bert 密集检索检索相关文档,然后利用融合解码器技术生成逻辑形式和直接答案,以每个(查询,文档)对作为输入。它将输出组合以获得最终答案。KD-CoT [147] 使用与 DECAF 相同的密集检索器和融合解码器生成器。它遵循一种“思维链”范式,迭代地执行检索、生成和验证,直到“思维链”完成。
增强型知识开放领域问答
结构化知识经常被利用于开放领域问答以实现出色的性能。
潜在表示为基础的 RAG 的使用,特别是融合解码器技术,在增强型知识开放领域问答中非常普遍。UniK-QA [144] 将三元组中组件的文本形式连接起来,并构建文档池进行检索。对于给定的问题,它利用密集检索器检索相关文档,然后执行融合解码器技术以整合信息进行答案生成。KG-FiD [333] 进行检索和生成,如同普通的 FiD。它通过两种方式添加了重新排序:第一种是在由检索文档形成的图上使用图注意力网络;第二种是使用生成器中的隐藏状态。OREOLM [334] 使用知识推理路径增强了 LLM。具体来说,它使用实体链接确定初始状态,然后在知识图上进行上下文随机游走以获取推理路径,这些路径的实体值记忆被合并到 LLM 的隐藏状态中以获得更好的生成。GRAPE [335] 为每对问题和检索到的段落构建二部图,然后为融合知识构建实体的二部图。它将 FiD 作为骨干模型并生成答案。SKURG [336] 使用文本和图像数据构建知识图,然后更新每个源的表示与它们的相关源。然后使用特别设计的解码器迭代地检索和生成。它与所有源进行交叉注意力,然后检索得分最高的源并连接到原始输入嵌入;如果门控得分未超过阈值,则开始生成真实答案,否则重新开始检索阶段。
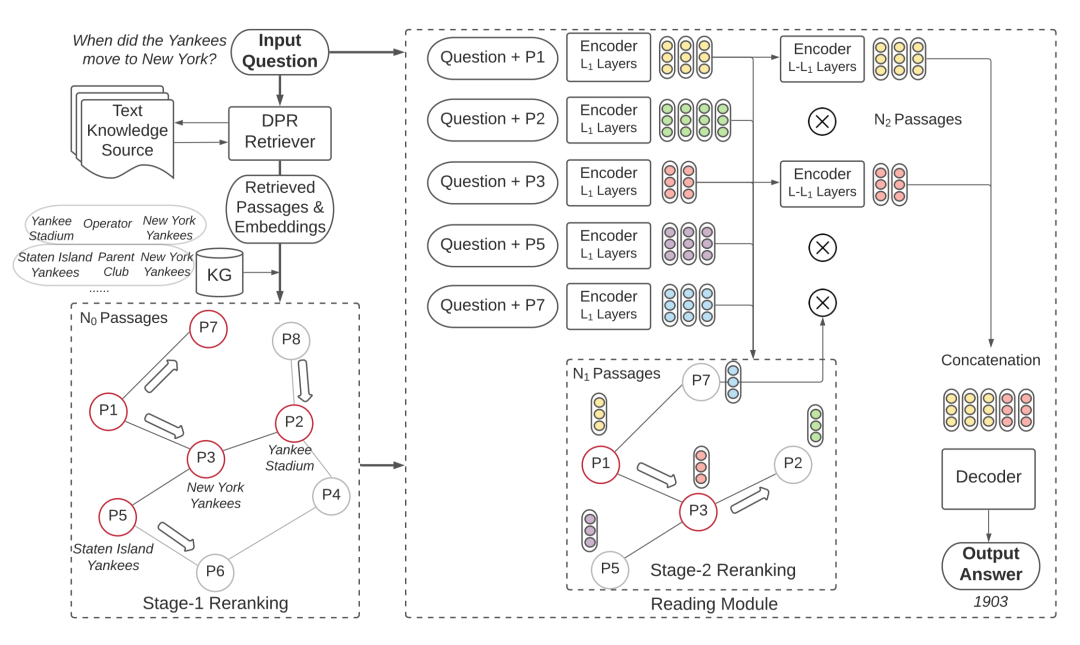
图 15. KG-FiD [333] 模型架构。
随着大语言模型的快速发展,基于查询的 RAG 正成为一种新的标准。DIVKNOWQA [337] 开发了一个检索增强工具,包括结构化知识上的稀疏检索、文本上的密集检索和知识库上的 sparql 生成。通过基于 CoT 的 LLM,在每一步中检索和重新排序,并生成最终答案。
KnowledGPT [338] 使用生成的代码从公共和个人知识库中检索,以构建 LLm 问答的提示。EFSUM [339] 使用检索到的相关事实生成以证据为中心的摘要,然后优化摘要以将 QA 特定偏好与另一个生成器和有用性和忠实度的过滤器对齐。GenTKGQA [340] 通过关系排序和时间挖掘进行子图检索,然后使用 GNN 将结构和时间信息合并到虚拟标记表示中,以进行后续 LLM 生成。KnowledgeNavigator [341] 分析复杂问题,并通过对核心实体相关的关系进行迭代过滤,在知识图上执行检索,以获取相关三元组。然后将三元组包含在提示中进行生成。
问答表格
表格作为另一种结构化知识形式,也有助于问答。
融合解码器风格的 RAG 经常用于表格问答。在 NeurIPS 2020 的 EfficientQA 竞赛中提出了许多检索-阅读器系统。这些系统从文本或表格中检索,然后利用抽取式或生成式模型作为阅读器。Dual Reader-Parser [343] 使用 BM25 检索相关的文本和表格信息,然后使用交叉编码器 Bert 进行重新排序。它利用融合解码器结合检索结果并生成最终答案。Convinse [344] 首先进行问题理解,然后通过实体链接和稀疏检索从异构资源(包括知识库、表格和文本)中检索相关信息。最后使用融合解码器整合检索到的证据并生成答案。CORE [345] 通过密集表示检索相关表格和段落,然后使用来自 T0 linker 的查询生成分数对检索结果进行重新排序。它在最终生成中使用 FiD。RINK [346] 遵循检索-重新排序-阅读器范式进行表格增强型问答。它设计了一个集合级别的继承式重新排序器来获取块(表格段)的相关性分数。TAG-QA [347] 从表格和文本中检索:对于表格,它将表格转换为图,然后执行 GNN 选择相关内容;对于文本,它使用 BM25 进行检索。然后利用 FiD 进行答案生成。
表格可以并入提示用于基于查询的 RAG。T-RAG [348] 给定用户查询检索相关表格,然后将查询与表格连接作为提示通过 BART 生成答案。OmniTab [349] 进行多任务训练以提高表格问答模型的性能。给定查询,它检索相关表格,然后将它们连接以进行掩码标记预训练。CARP [350] 使用实体链接检索相关表格和段落,然后提取检索到的知识的混合链,稍后用于构建生成的提示。StructGPT [325] 从知识图、表格或数据库中提取相关信息,以形成提示,并通过 LLM 生成答案。cTBLS [351] 通过密集检索检索相关表格,然后对于每个查询,使用排名表格形成提示进行答案生成。最近的一项工作 [352] 首先使用表格到文本技术将表格数据整合到语料库中,然后在微调和 RAG 上进行实验进行问答。
其他
Prototype-KRG [353] 检索知识事实和对话原型,然后通过隐藏状态和对数将它们整合到基于 GRU 的生成器中。SURGE [354] 使用密集检索检索相关子图,然后将它们添加到生成器的输入中进行对话生成。RHO [355] 在开放领域对话生成过程中,将相关实体和关系的知识图嵌入融合到文本嵌入中。K-LaMP [356] 检索历史查询中的实体以构建查询建议的提示。ReSKGC [148] 将所有训练三元组线性化为文本,然后使用 BM25 检索相关三元组,并使用融合解码器的 T5 生成完整的三元组。G-Retriever [357] 从基于图的数据中检索相关节点和边,然后构建子图并根据文本图进行问题回答的图提示调整。
科学领域的 RAG
RAG 也已经成为许多跨学科应用的一个有前景的研究方向,例如加强分子生成、指导医学任务和推进计算研究。
药物发现
药物发现的目标是生成同时满足多种属性的分子。RetMol [54] 将轻量级检索机制整合到预训练的编码器-解码器生成模型中。如图 16 所示,该方法采用 SMILES 字符串 [358] 表示分子,以及 Chem-Former 模型 [359],涉及将示例分子与输入分子进行检索和融合。PromptDiff [360] 提出了一种创新的基于交互的检索增强 3D 分子扩散模型,以促进面向目标的分子生成。PromptDiff 检索一组经过策划的配体参考,即那些具有高结合亲和力等所需属性的配体,以引导扩散模型合成满足设计标准的配体。
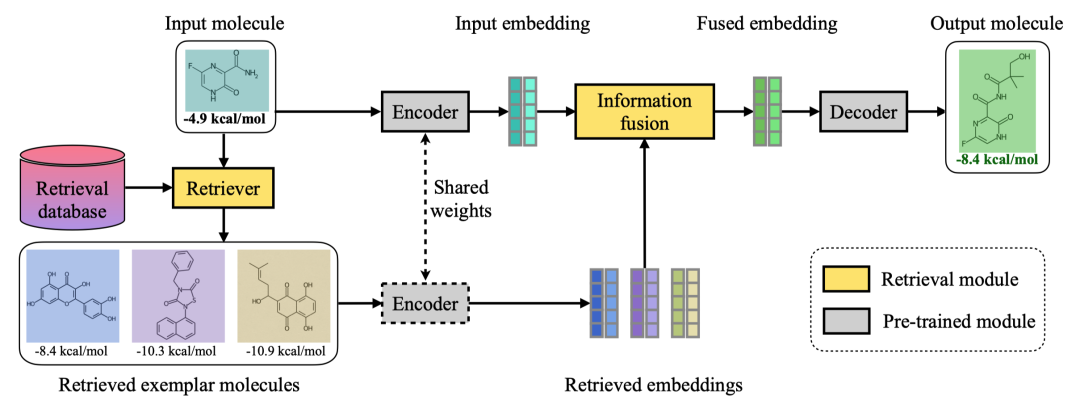
图 16. RetMol [54] 模型架构。
生物医学信息学增强
数学应用
检索增强生成技术在数学领域简化了问题解决过程,促进了研究创新,并完善了教育策略。LeanDojo [365] 利用其 ReProver 模型增强了定理证明,采用检索增强技术从庞大的数学库中高效选择相关前提,从而提高了自动化和定理泛化。RAG-for-math-QA [366] 利用检索增强生成技术增强数学问答,将高质量数学教材内容整合到一起,旨在提高用于中学代数和几何问题的 LLM 生成响应的质量和教育相关性。
基准
Chen 等人 [367] 提出了一个 RAG 基准,从四个方面评估了 RAG:噪声鲁棒性、负面拒绝、信息整合和反事实鲁棒性。噪声鲁棒性评估了 LLM 是否能够从包含嘈杂信息的文档中提取必要信息。这些嘈杂信息与输入查询相关,但对回答查询无用。负面拒绝衡量了当检索到的内容不足时,LLM 是否会拒绝回答查询。信息整合评估了 LLM 是否能够通过整合多个检索到的内容获取知识并做出响应。反事实鲁棒性指的是 LLM 辨别检索到的内容中反事实错误的能力。
另外三个基准,RAGAS [368]、ARES [369] 和 TruLens [370],分别考虑了三个不同方面:忠实度、答案相关性和上下文相关性。忠实度关注结果中的事实错误,当正确答案可以从检索到的内容中推断出时。答案相关性衡量生成的结果是否实际解决了问题(即查询)或不是。上下文相关性判断检索到的内容是否包含尽可能多的知识来回答查询,并尽可能少地包含无关信息。
CRUD-RAG [371] 将所有 RAG 任务分为四个类别,分别是创建、读取、更新和删除,并使用文本延续、单文档和多文档问答、幻觉修改以及开放域多文档摘要来评估每个类别。MIRAGE [372] 是一个旨在评估 RAG 在医学领域应用的基准,重点是比较和优化医学问答系统的性能。
讨论
限制
尽管 RAG 在各种应用中被广泛采用,但在效率和有效性方面确实存在一些限制。在本文中,我们总结了 RAG 的限制并进行了深入讨论。
检索结果中的噪声
信息检索无法产生完美的结果,因为编码器模型生成的表示中存在信息丢失。此外,ANN 搜索也可能提供近似结果而非精确结果。因此,在检索结果中出现一定程度的噪声是不可避免的,表现为无关对象或误导性信息,这可能导致 RAG 系统的失败点 [373]。尽管普遍认为提高检索的准确性将有助于提高 RAG 的有效性,但最近的研究令人惊讶地表明,嘈杂的检索结果可能反而有助于提高生成质量 [374]。一个可能的解释是,多样性的检索结果对于快速构建也是必要的 [[375](#_bookmark374]]。因此,检索结果中的噪声对于生成质量的影响仍不确定,导致对于应该使用哪种度量衡来进行检索以及如何促进检索器和生成器之间的交互存在困惑。预计后续研究将揭示这种困惑。
额外开销
尽管在某些情况下检索可以帮助减少生成的成本 [29]–[31],但有时引入检索会带来不可忽视的额外开销。考虑到 RAG 主要用于改进现有生成模型的性能,增加额外的检索和交互过程会导致延迟增加。更糟糕的是,当与复杂的增强方法结合使用时,例如递归检索 [171] 和迭代 RAG [222],额外开销将变得更加显著。此外,随着检索规模的扩大,与数据源相关的存储和访问复杂性也会增加。因此,RAG 系统在成本和收益之间存在权衡。展望未来,我们期待进一步优化以减轻相关开销。
检索和生成的交互
实现检索和生成组件之间的无缝集成需要精心设计和优化。鉴于检索器和生成器的目标不一致,并且这两个模型可能不共享相同的潜在空间,设计和优化这两个组件之间的交互会遇到挑战。正如在第 III 节中介绍的,已经提出了许多方法来实现有效的 RAG,这些方法要么解耦检索和生成过程,要么在中间阶段集成它们。虽然前者更模块化,但后者可能受益于联合训练。迄今为止,还缺乏对不同交互方式在各种场景中的充分比较。
调整 RAG 系统也具有挑战性。关于提示增强式 RAG 中归因和流畅性之间的权衡的最新研究表明,对于生成,使用前 k 个检索结果可以提高归因,但在流畅性方面会受到影响 [376]。RAG 中不同方面的相互作用的相互影响尚未被探索。因此,需要进一步改进 RAG 系统,无论是在算法还是部署方面,以充分释放其潜力。
长上下文生成
早期阶段 RAG 的主要挑战之一是生成器固有的上下文长度限制。关于提示压缩 [207] 和长上下文支持 [377] 的研究进展部分缓解了这一挑战,尽管在准确性或成本方面存在轻微的权衡。鉴于这一挑战,最近出现了一个观点,即“像 Gemini 1.5 这样的长上下文模型将取代 RAG”。然而,这种说法并不成立 — RAG 在管理动态信息方面表现出更大的灵活性,涵盖了最新和长尾知识 [378]。我们相信未来的 RAG 将利用长上下文生成来实现更好的性能,而不仅仅是被淘汰。
潜在未来方向
最后但同样重要的是,我们希望确定一系列可能的未来研究和应用方向。
对 RAG 方法论、增强和应用进行更深入研究
一个直接的研究方向是开发更先进的 RAG 方法论、增强和应用。
正如在第 III-A 节中介绍的,现有作品已经探索了检索器和生成器之间的各种交互模式。然而,由于这两个组件的优化目标不同,实际的增强过程对最终生成结果有很大影响。对于增强的更先进基础的研究具有充分释放 RAG 潜力的希望。
基于构建的 RAG 系统,增强有助于改进某些组件或整个流程的有效性。鉴于系统的固有复杂性,RAG 有很大的改进潜力,需要适当的调整和谨慎的工程。我们期待进一步的实验分析和深入探索,这将有助于开发更有效和更健壮的 RAG 系统。
正如在第 IV 节中介绍的,RAG 是一种通用技术,已应用于各种模态和任务。然而,大多数现有作品直接将外部知识与特定生成任务整合,而没有充分考虑目标领域的关键特征。因此,对于没有充分利用 RAG 力量的生成任务,我们有信心设计适当的 RAG 系统将是有益的。
高效部署和处理
目前,已经提出了几种针对 LLM 的基于查询的 RAG 部署解决方案,例如 LangChain [379]、LLAMA-Index [180] 和 PipeRAG [380]。然而,对于其他类型的 RAG 和生成任务,缺乏即插即用的解决方案。此外,考虑到检索引入的额外开销,以及检索器和生成器的复杂性将继续增长,实现 RAG 中的高效处理仍然是一个挑战,需要有针对性的系统优化。
整合长尾和实时知识:
总的来说,RAG 与其他旨在提高 AIGC 效果的技术是正交的,包括微调、强化学习、思维链、基于代理的生成以及其他潜在的优化方法。然而,同时应用这些技术的探索仍处于早期阶段,需要进一步研究算法设计,充分发挥它们的潜力。
结论
本文针对与 AIGC 相关的场景中的 RAG 进行了彻底全面的调查,特别关注增强基础、增强和实际应用。我们首先系统地组织和总结了 RAG 中的基础范式,深入探讨了检索器和生成器之间的互动。基于构建的 RAG 系统,我们审查了进一步提高 RAG 效果的增强措施,包括对输入、检索器、生成器和结果的增强。为了促进跨领域研究人员,我们展示了 RAG 在各种形式和任务中的实际应用。最后,我们还介绍了现有的 RAG 基准,讨论了当前的限制,并展望了未来的发展方向。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

