
- 1前端如何使用微信支付_前端微信支付
- 2机器学习系列15-半监督学习_low density separation assumption
- 3解析BroadcastReceiver的注册、发送与接收过程_enqueueing broadcast: replacepending=false
- 4JPA-主键生成策略_strategy = generationtype.identity
- 5【AIGC调研系列】浙大&蚂蚁OneKE大模型知识抽取框架是什么_oneke 知识图谱
- 6HDLBits(九)学习笔记——verilog实现移位寄存器、More Circuits(三输入查找表)_8位移位寄存器verilog代码
- 7RabbitMQ下载安装
- 8Android 14 变更及适配攻略_android14适配
- 9【AI视野·今日CV 计算机视觉论文速览 第244期】Fri, 15 Apr 2022_interpretable vertebral fracture quantification vi
- 10JimuReport 积木报表 v1.6.4 稳定版本正式发布 — 开源免费的低代码报表_積木報表哪個版本的更穩定csdn
Android 性能优化系列:启动优化进阶_android cpu影响应用启动时间
赞
踩
启动速度优化的本质因素
应用的速度优化是我们使用最频繁,也是应用最重要的优化之一,它包括启动速度优化、页面打开速度优化、功能或业务执行速度优化等等,能够直接提升应用的用户体验。
大部分人谈到速度优化,只能想到一些零碎的优化点,比如使用多线程、预加载等等,没有一个较为体系的优化方案。
那么我们要怎么体系化的学习启动优化呢?能从哪些方面入手?
从底层来看,CPU、缓存、任务调度是决定应用速度最本质的因素,CPU 和缓存都属于硬件层,任务调度机制则属于操作系统层。速度优化我们将围绕这三个因素详细说明优化方案。
CPU 层面进行速度优化
所有的程序最终会被编译成机器码指令,然后交给 CPU 执行,CPU 以流水线的形式一条条执行程序的机器码指令。当我们想要提升某些场景(如启动、打开页面、滑动)等的速度时,本质上就是降低 CPU 执行完这些场景指令的时间,这个时间简称为 CPU 时间。程序所消耗 CPU 时间的计算公式:CPU 时间 = 程序的指令数 x 时钟周期时间 x 每条指令的平均时钟周期数。
-
程序的指令数:就是程序编译成机器码指令后的指令数量
-
时钟周期时间:每一次时钟周期内,CPU 仅完成一次执行,所以时钟周期时间越短,CPU 执行得越快。对时钟周期时间这个概念可能不熟悉,但是它的倒数也就是 CPU 时钟周期频率肯定听说过,1ns 的时钟周期时间就是 1GHz 的时钟周期频率。这个指标也是衡量 CPU 性能最重要的一个指标
- 每条指令的平均时间周期:是指令执行完毕所消耗的平均时间周期,指令不同所需的机器周期数也不同
从 CPU 来看,当我们想要提升程序的速度时,优化这三项因子中的任何一项都可以达到目的。那基于这三项因子有哪些通用方案可以借鉴呢?
减少程序的指令数
通过减少程序的指令数来提升速度是我们最常用也是优化方案最多的方式。下面这些方案都是通过减少指令数来提升速度的。
-
利用手机多核:从程序角度讲其实就是多线程并发,将要提速的场景的程序指令交给多个 CPU 同时执行,对于单个 CPU 来说,需要执行的指令数就变少了,CPU 时间自然就降低了
-
更简洁的代码逻辑和更优的算法:同样的功能用更简洁或更优的代码来实现,指令数也会减少,指令数少了程序的速度自然也就快了。可以用抓 trace 或者在函数前后统计耗时方式去分析,将耗时的方法用更优的方式实现
-
减少 CPU 闲置:通过在 CPU 闲置的时候,执行预创建 View、预准备数据等预加载逻辑,在我们需要加速场景的指令数量由于预加载之行了一部分而变少了,自然也就快了
降低时钟周期时间
想要降低手机的时钟周期,一般只能通过升级 CPU 做到,每次新出一款 CPU,相比上一代不仅在时钟周期时间上有优化,每个周期内可执行的指令也都会有优化,时钟频率周期越大处理速度越快。
虽然我们没法降低设备的时钟周期,但是应该避免设备提高时钟周期时间,也就是降频现象,当手机发热发烫时,CPU 往往都会通过降频来减少设备的发热现象,具体的方式就是通过合理的线程使用或者代码逻辑优化,来减少程序长时间超负荷的使用 CPU。
降低每条指令的平均时间周期
在降低每条指令的平均时间周期上,我们能做的其实也不多,因为它和 CPU 性能有很大的关系;除了 CPU 性能,以下几个方面也会影响到指令的时间周期:
-
编程语言:Java 翻译成机器码后有更多的间接调用,所以比 C++ 代码编译成的机器码指令的平均时间周期更长
-
编译程序:一个好的编译程序可以通过优化指令来降低指令的平均时间周期
-
降低 IO 等待:严格来说,IO 等待的时间并不能算到指令执行的耗时中,因为 CPU 在等待 IO 时会休眠或者去执行其他任务,但等待 IO 会使执行完指令的时间变长
缓存层面进行速度优化
程序的指令并不是直接就能被 CPU 执行的,CPU 在读取指令时会经过寄存器、高速缓存、主存,逐级将指令进行缓存,层级越靠上执行速度越快;当然一个程序也不可能全是 CPU 计算逻辑,必然也会涉及到比如磁盘 IO 的操作或等待。所以缓存也是决定应用速度的关键因素之一。
缓存对程序速度的影响主要体现在两方面:
-
缓存的读写速度
-
缓存的命中率
缓存的读写速度
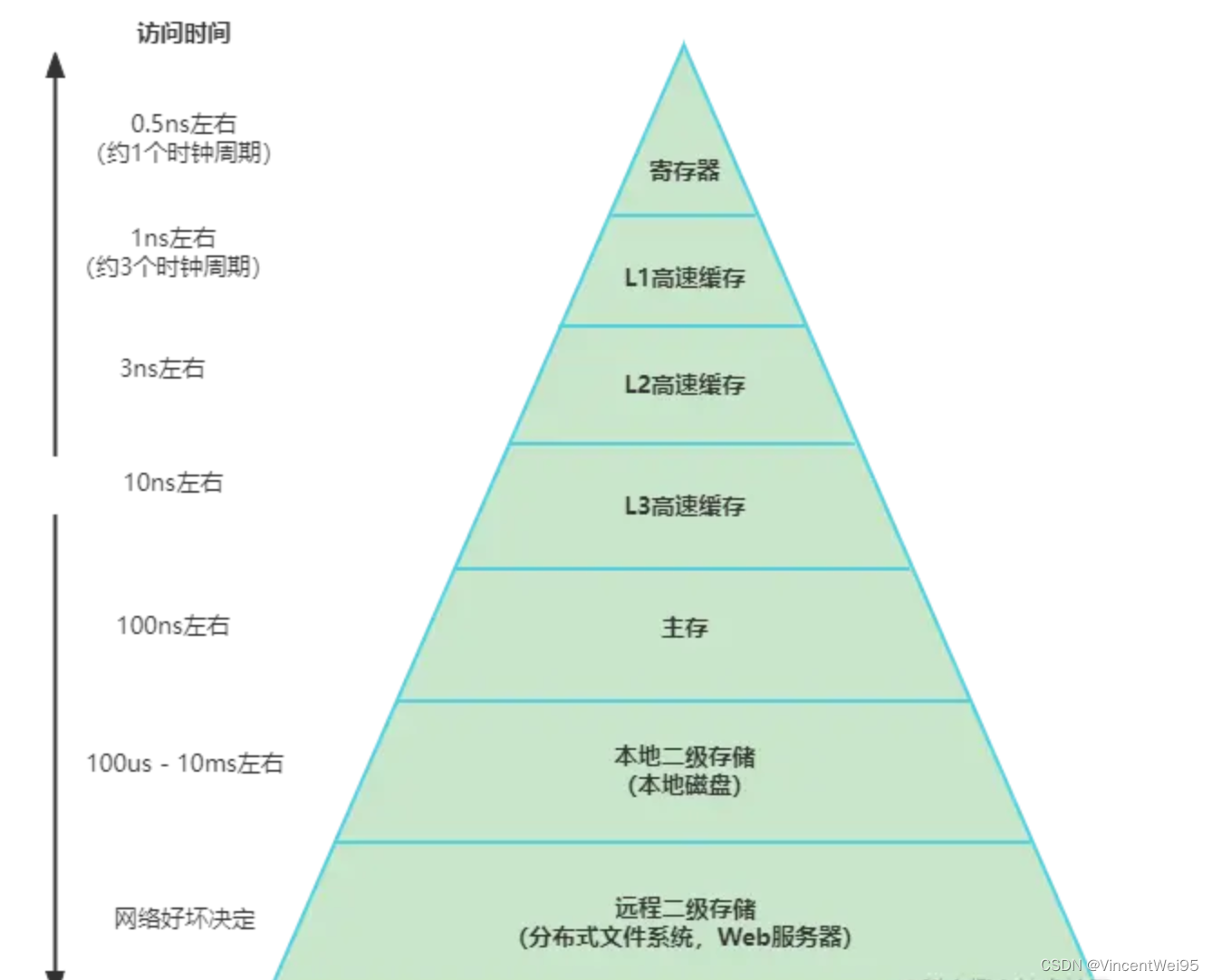
手机或电脑的存储设备都被组织成了一个存储器层次结构,在这个层次结构中,从上至下设备的访问速度越来越慢,但容量也越来越大,并且每字节的造价也越来越便宜。
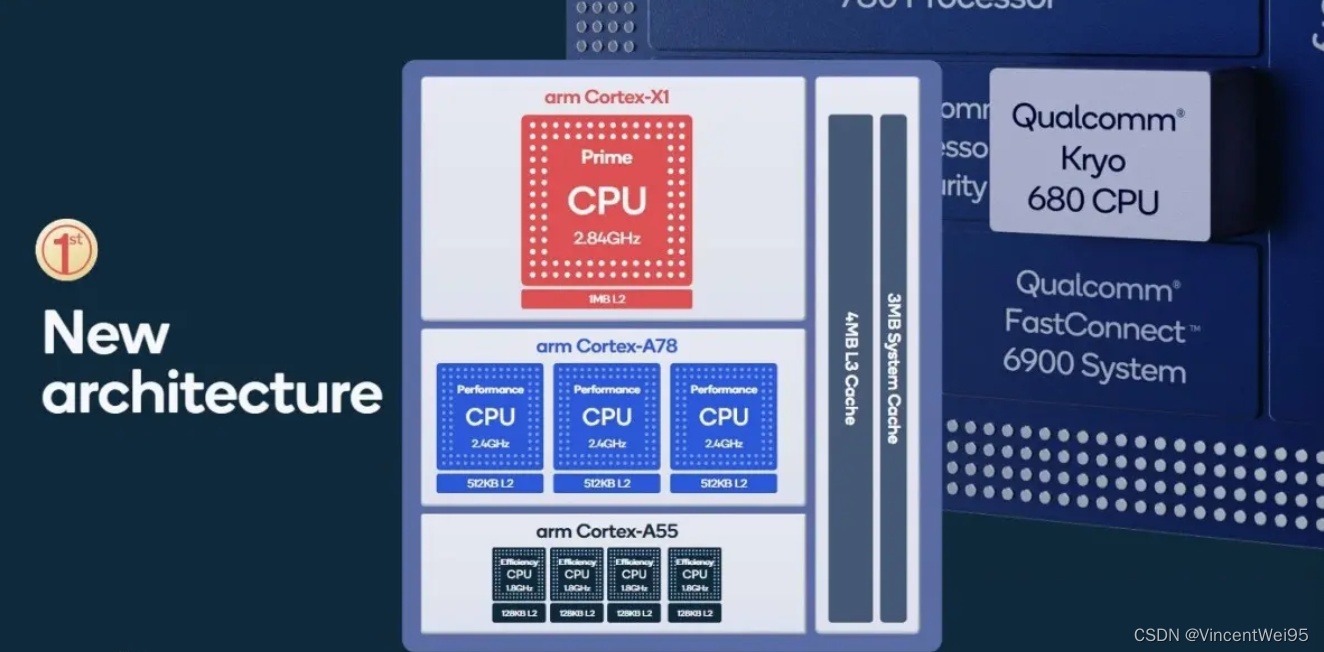
高速缓存是属于 CPU 的组成部分,并且实际有几层高速缓存也是由 CPU 决定的。以下图高通骁龙 888 的芯片为例,它是 8 块核组成的 CPU,从架构图可以看到,它的 L2 是 1M 大小,L3 是 3M 大小,并且所有核共享。
不同层之间的读写速度差距是很大的,所以为了能提高场景的速度,我们需要将和核心场景相关的资源(代码、数据等)尽量存储在靠上层的存储器中。基于这一原理,便能衍生出非常多的优化方案,比如 OkHttp、Fresco 等框架都会想尽办法将数据缓存在内存中,其次是磁盘,以此来提高速度。
缓存的命中率
在讲解缓存读取速度时有提及,缓存层级越靠上虽然访问越快,但是容量越少,我们只能将有限的数据存放在缓存中,在这样的制约下,提升缓存命中率往往是一件非常难的事情。
从系统层面,一个好的编译器可以提升寄存器的命中率,一个好的操作系统可以提升高速缓存的命中率;从应用层面,好的优化方案可以提升主存和硬盘的命中率,比如 LruCache;应用可以提升高速缓存的命中率,比如使用 redex 对应用的 dex 中 class 文件重排来提升高速缓存读取类文件时的命中率。
想要提高缓存命中率,一般都是利用局部性原理(局部性原理即数据被访问,不久之后该数据或附近的存储单元可能再次被访问,将可能被再次访问的数据提前加载)分析大概率事件等多种原理来提高缓存命中率。
任务调度层面进行速度优化
为了能同时运行多个程序,所以诞生了虚拟内存技术,但只有虚拟内存技术是不够的,还需要任务调度机制,我们的程序才能获得 CPU 的资源正常跑起来,所以 任务调度也是影响程序速度的本质因素之一。
在 Linux 系统中,任务调度的维度是进程,Java 线程也属于轻量级的进程,所以线程也是遵循 Linux 系统的任务调度规则。Linux 系统将进程分为了实时进程和普通进程这两类。
为了熟悉任务调度机制,我们需要熟悉调度机制的原理,以及进程的生命周期。
通过实时进程和普通进程了解任务调度机制原理
1、实时进程
Linux 系统对实时进程的调度策略有两种:先进先出(SCHED_FIFO)和循环(SCHED_RR),Android 只使用了 SCHED_FIFO 策略调度实时进程,我们主要介绍这个。
如果某个进程占有 CPU 时间片,此时没有更高优先级的实时进程抢占 CPU 或该进程主动让出,那么该进程就始终保持使用 CPU 状态。这种策略会提高进程运行的持续时间,减少被打断或切换的次数,所以响应更及时。Android 中 Audio、SurfaceFlinger、Zygote 等系统核心进程都是实时进程。
2、普通进程
Linux 系统对普通进程采用了一种完全公平调度算法来实现对进程的切换调度,算法细节我们不需要了解。
完全公平调度算法简单理解就是,调度器根据进程的运行时间来进行任务调度,进程运行时间并不是真实的物理运行时间,而是通过 nice 值作为权值系数计算的虚拟时间。在同样的物理时间内,nice 值越低进程的运行时间越少,运行时间少更容易被调度器所选择。
所以修改进程优先级 nice 值,nice 值越低代表优先级越大,实际上就是 nice 值越低越容易被调度器选择。
实时进程和普通进程的任务调度机制的结合就是系统任务调度机制的原理。
进程生命周期
了解了进程的调度原理,再来了解下进程的生命周期。
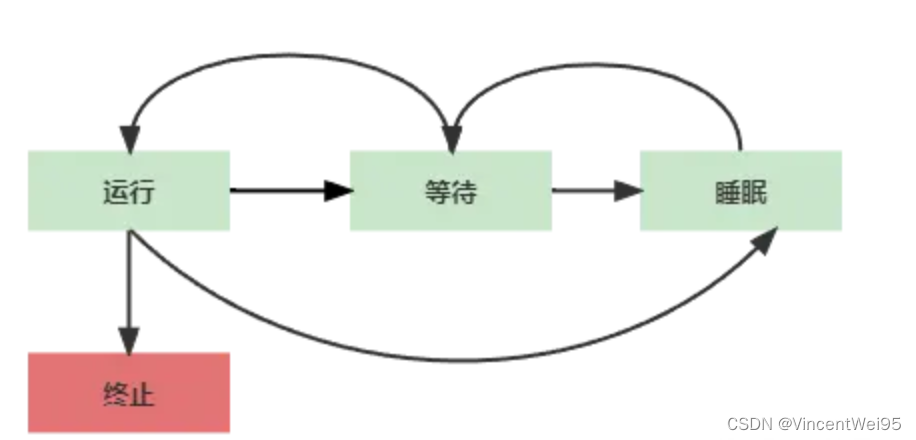
线程实际上就是轻量级的进程,有以下几种状态:
-
运行:该进程此刻正在运行
-
等待:进程能够运行,但 CPU 分配给另一个进程,调度器可以在下一次任务切换时选择该进程
-
睡眠:进程正在睡眠无法运行,因为它在等待一个外部事件,调度器无法在下一次任务切换时选择该进程
-
终止:进程终止
遵循以上的调度原理和规则,任务调度层面优化应用场景的速度实际上就是线程的优化。主要可以从以下两方面优化:
-
提高线程优先级:关键线程选择提高线程优先级,还可以将关键线程绑定 CPU 大核的方式提高线程的执行效率
-
减少线程创建或者状态切换的耗时:简单理解就是合理使用线程池,根据场景合理设置线程池的常驻线程数量、线程存活时间等参数减少线程频繁创建和切换
CPU 优化
合理使用线程池提升 CPU 利用率
在 Java 中创建子线程是使用 Thread,但是我们一般都不会直接使用它们,而是通过 线程池 的方式创建线程统一管理。Java 同样提供了Executors 线程池管理工具帮助我们管理线程,但一般我们不会直接使用 Executors 提供的线程池,而是会自定义线程池,更好的管理线程。
合理使用线程应该符合这几个条件:
-
线程不能太多也不能太少:线程太多会浪费 CPU 资源用于任务调度上,并且会减少核心线程在单位时间内所能消耗的 CPU 资源;线程太少则发挥不出 CPU 的性能,浪费了 CPU 资源
-
减少线程创建及状态切换导致的 CPU 损耗:线程频繁的创建、销毁、状态切换(如休眠切换到运行状态或运行状态切换到休眠),都是对 CPU 资源的损耗
如何在使用线程的时候符合上面讲的两个条件呢?可以尽量做到两点:
-
收敛线程:排查野线程和各个业务的自定义线程池
-
使用线程池:线程都从线程池创建,并且正确使用线程池
线程池类型
要正确使用线程池,针对不同的场景主要可以分为 CPU 密集型场景和 IO 密集型场景即 CPU 线程池和 IO 线程池。
-
CPU 线程池:用来处理 CPU 类型任务,如计算、逻辑操作、UI 渲染等
-
IO 线程池:用来处理 IO 类型任务,如拉取网络数据、往磁盘读写数据等
线程池配置主要考虑四个参数:
-
corePoolSize:核心线程数量,或者叫常驻线程数量
-
maximumPoolSize:最大线程数量
-
keepAliveTime:非核心线程存活时间
-
workQueue:任务队列
还有 threadFactory 线程工厂和 RejectedExecutionHandler 异常处理兜底参数。
不同的场景使用不同的线程池配置。那么具体该怎么配置上面四个参数呢?
CPU 线程池配置
1、corePoolSize
一般设置为 CPU 的核心数,理想情况下等于核心数的线程数量性能是最高的,因为既能充分发挥 CPU 的性能,还减少了频繁调度导致的 CPU 损耗。不过实际运行过程中无法达到理想情况,所以将 核心线程数设置为 CPU 核心数可能不是最优的,但绝对是最稳妥且相对较优的方案。
2、maximumPoolSize
对于 CPU 线程池来说,最大线程数就是核心线程数,因为 CPU 的最大利用率就是每个核都满载,想要达到满载只需要核心数个并发线程就行了,能够完全发挥出 CPU 资源,再多的线程只会增加 CPU 调度的损耗。
3、keepAliveTime
因为最大线程数就是核心线程数,keepAliveTime 是设置的非核心线程的存活时间可以是 0。
4、workQueue
CPU 线程池中统一使用 LinkBlockingQueue,这是一个可以设置容量并支持并发的队列。当线程较多核心线程数处理不来时,任务会到队列中等待,所以队列不能太小避免新来的任务进入到错误兜底的处理逻辑中。我们可以将队列设置成无限大,但如果想要追求更好的程序稳定性则不建议这样做了。
如果需要对创建的线程重命名或对线程栈大小做限制,可以在 threadFactory 线程工厂自定义处理。
假设队列设置有限数量例如 64 个,如果线程池使用出现异常时导致进入异常兜底 RejectedExecutionHandler,可以在这里设置监控及时发现异常。
以上配置逻辑实际上就是 Executors 工具类提供的 newFixedThreadPool 线程池,其实它就是 CPU 线程池:
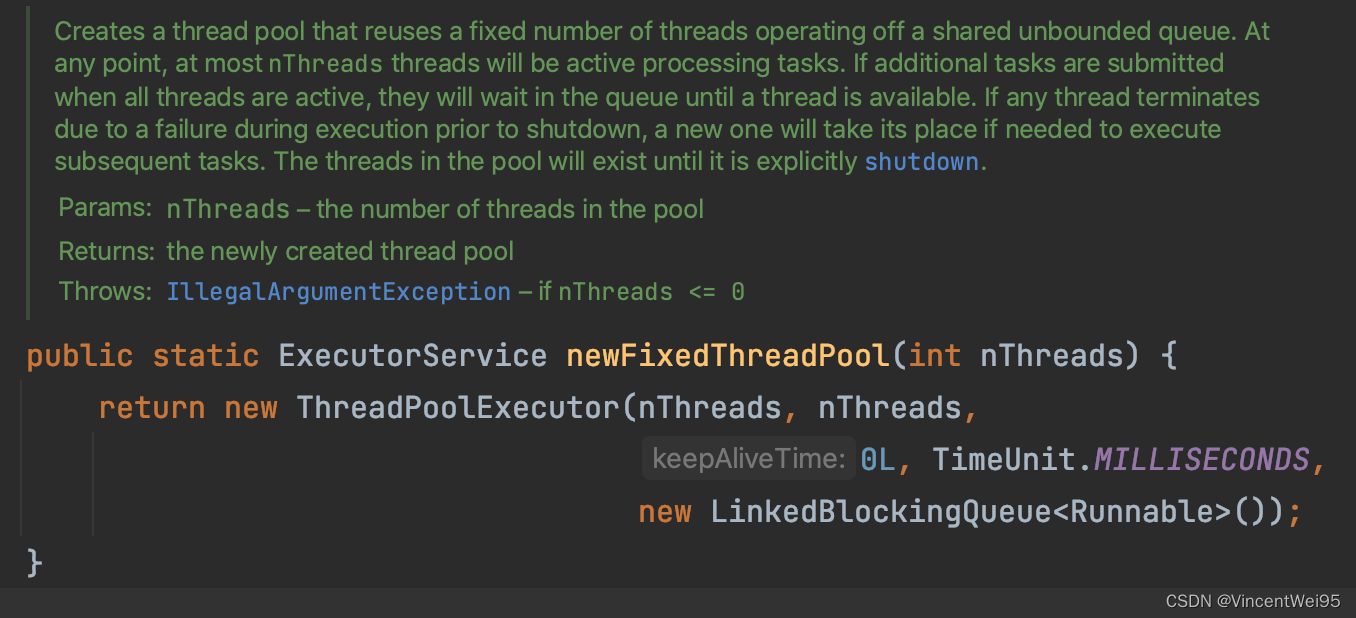
IO 线程池配置
IO 任务消耗 CPU 资源是非常少的,当我们处理 IO 数据时会交给 DMA(直接存储器访问)芯片去做,此时调度器就会把 CPU 资源切换给其他的线程去使用。因为 IO 任务对 CPU 资源消耗少,所以每来一个 IO 任务就直接启动一个线程去执行它就行了,不需要放入队列中,即使此时执行了非常多的 IO 任务,也都是 DMA 芯片在处理,和 CPU 无关。了解了这一特性,我们再来看看 IO 线程池如何配置。
1、corePoolSize
核心线程数量没有具体规定,要根据 app 的类型对应场景配置数量。比如 IO 任务比较多的新闻咨询类应用或者大型应用,可以设置多一些比如十几个,太少了会因为 IO 线程创建和销毁频繁产生损耗。如果应用 IO 任务较少,可以直接设置为 0 个。
2、maximumPoolSize
最大线程数量可以多设置一些,确保每个 IO 任务都能有线程执行,毕竟 IO 任务对 CPU 消耗不高。一般来说,中小型应用设置 60 个就足够,大型应用可以设置 100 个以上,但不建议设置特别大,防止程序出现异常创建大量 IO 线程,线程的创建和销毁是消耗 CPU 资源的。
3、keepAliveTime
非核心线程闲置存活时间一般设置 60s,这个时间即能让闲置线程复用效率较高,也能保证不会频繁销毁线程后又重新创建消耗系统资源。
4、workQueue
因为 IO 任务的特性是来一个任务处理一个,所以 对于 IO 线程池而言是不需要等待队列的,可以传入 SynchronousQueue,它是一个容量为 0 的队列。
以上配置逻辑实际上就是 Executors 工具类提供的 newCacheThreadPool 线程池,其实它就是 IO 线程池:
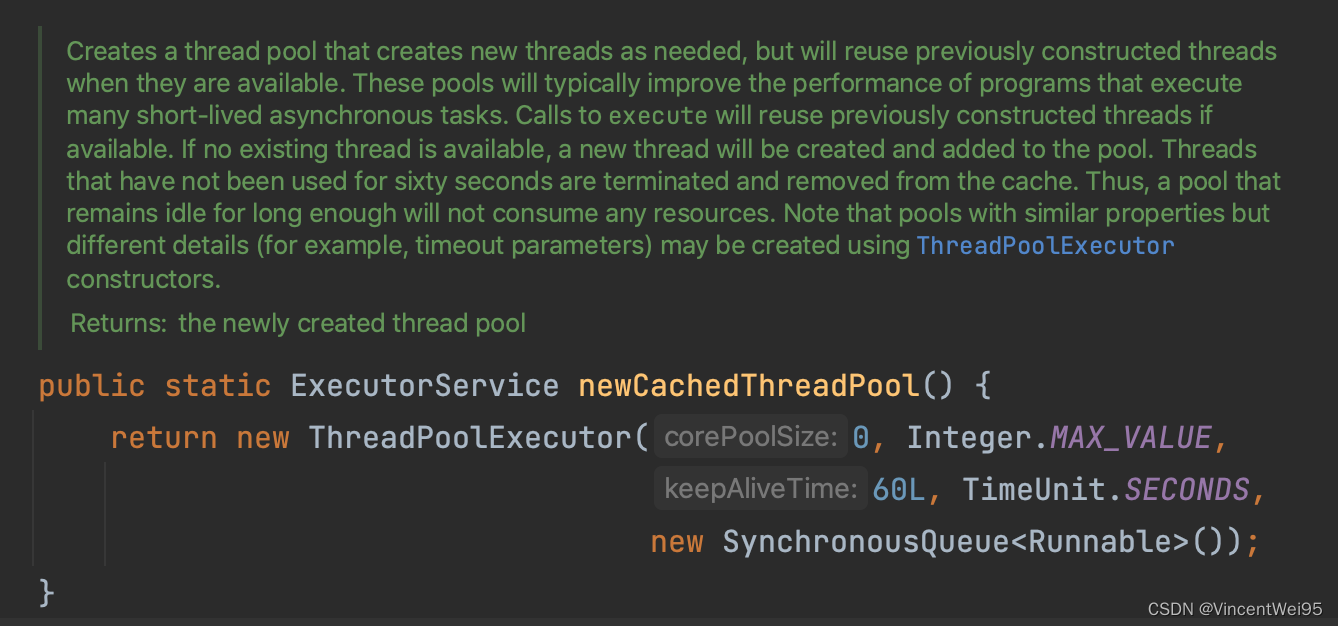
不过 newCacheThreadPool 设置的最大线程数是无限大,这里建议还是自己创建 IO 线程池,并且在设置 IO 线程池的线程优先级时,需要比 CPU 线程池的线程优先级高一些,因为 IO 线程的任务不怎么消耗 CPU 资源,优先级高一些可以避免得不到调度的情况出现。
确认任务属于哪种类型
那么怎么确认任务是要放在 CPU 线程池执行还是 IO 线程池执行呢?
我们可以通过插桩(AspectJ、ASM、Javaassit 等)将 Runnable 的 run() 执行时间以及对应的线程池、线程名称打印出来,如果任务耗时较久,还是在 CPU 线程池执行的,那就要考虑该任务是否需要放在 IO 线程池去执行了。
减少 CPU 闲置提升利用率
除了游戏类食品类应用,很少有应用会持续以较高的状态消耗 CPU,大部分情况下 CPU 都可能处于闲置状态。我们可以把核心场景运行时需要执行的任务或者数据放在闲置时提前预加载,能充分利用 CPU 闲置时刻又不会抢占核心场景 CPU 资源,减少其他场景 CPU 执行的指令数,提升速度。
我们可以启动一个定时任务定时比如每 5s 检测 CPU 是否已经闲置,如果已经闲置就通知各个业务预加载执行任务。那么怎么知道 CPU 处于闲置?
检测 CPU 闲置有两种方案:
-
读取 proc 文件节点下的 CPU 数据判断 CPU 是否闲置
-
times 函数判断 CPU 是否闲置
考虑性能及准确率,在这里推荐使用 native 的 times 函数判断 CPU 是否闲置。不过两种方式都会讲解下。
读取 proc 文件判断 CPU 闲置
在 Linux 系统上,设备和应用的大部分信息和数据都会记录在 proc 目录下的某个文件中,CPU 数据同样可以在 proc 目录下的文件获取。主要会涉及两个文件:/proc/stat 和 /proc/pid/stat,字段意义具体可以查看 Linux proc 文档,CPU 使用率计算。
读取 /proc/stat 获取 CPU 总运行时间
首先看下 /proc/stat 节点文件:
$ adb shell cat /proc/stat
cpu 17742 2886 22371 1720255 577 0 295 0 0 0
cpu0 4786 582 6057 428486 101 0 254 0 0 0
cpu1 3375 466 5224 432181 183 0 10 0 0 0
cpu2 4447 916 5970 429892 166 0 15 0 0 0
cpu3 5133 920 5119 429695 125 0 15 0 0 0
intr 4076330 0 0 0 952094 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 23 2979 12779 1 19744 1 18 1 0 119018 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 541
ctxt 9551253
btime 1688788408
processes 17971
procs_running 1
procs_blocked 0
softirq 1297436 43240 320646 10 4133 0 0 202342 344748 0 382317
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面的字段我们只需要关注标有 cpu 的即可,后面的数字是,从系统启动到当前时刻,不同维度累计下的 CPU 时间:
| 1.CPU 名称 | 2.user | 2.nice | 4.system | 5.idle | 6.iowait | 7.irq | 8.soft_irq | 9. steal、guest、guest_nice |
|---|---|---|---|---|---|---|---|---|
| 用户态累积消耗的 CPU 时间 | nice 值为负的进程所累积消耗的 CPU 时间 | 内核态累积消耗的 CPU 时间 | 除 IO 等待时间以外的其他等待时间 | 累积 IO 等待时间(这个时间是不准确的,因为需要 IO 等待时,调度器会将 CPU 切换给其他任务使用 | 累计的硬中断时间 | 累计的软中断时间 | 保留字段 | |
| cpu(所有核累加) | 17742 | 2886 | 22371 | 1720255 | 577 | 0 | 295 | 0 0 0 |
| cpu0(第一个核) | … | … | … | … | … | … | … | … |
| … | … | … | … | … | … | … | … | … |
| cpu3(第四个核) | … | … | … | … | … | … | … | … |
有了上面的数据后,我们只需要 将表格中第一行 CPU 数据中的 2 到 8 列数据累加起来,就是 CPU 的总运行时间了,CPU 总运行时间 = user + system + nice + idle + iowait + irq + soft_irq。
读取 /proc/pid/stat 获取进程 CPU 消耗时间
获取了 CPU 总运行时间,接下来获取应用的 CPU 消耗时间。
首先是获取应用的 pid:
adb shell ps -l // 假设应用 com.example.demo 的 pid 查询结果为 22419
- 1
查看 /proc/pid/stat :
adb shell cat /proc/22419/stat
- 1

上面数据也是比较多,我们只需要关注从左到右算第 14 项 utime 加上 第 15 项 stime,就是这个进程的 CPU 消耗时间,进程 CPU 消耗时间 = utime + stime。
通过 CPU 总运行时间和进程 CPU 消耗时间计算进程 CPU 使用率
有了 CPU 的总运行时间和进程的 CPU 消耗时间,就可以计算 CPU 使用率了。
CPU 使用率的计算限定在一定时间范围内,比如在 5-60s 之间(时间不宜太长)如果 CPU 使用率低,就说明应用没怎么用 CPU 处于闲置。
如果我们预加载任务比较多,时间可以缩短一些,比如 5s 检测一次,这 5s 内如果 CPU 是闲置的,就执行预加载任务。但需要注意预加载任务需要打散,也就是每个闲置周期不能执行太多的预加载任务,避免所有预加载任务都一次执行而导致 CPU 过载。
计算进程 CPU 占用率经过以下三个步骤:
-
读取
/proc/stat节点获取 CPU 总运行时间 -
读取
/proc/pid/stat文件获取进程的 CPU 消耗时间 -
计算 CPU 占用率 = 应用的 CPU 消耗时间 / CPU 总运行时间。
需要注意的是,CPU 占用率还要依据 CPU 核数设定阀值,因为假设 8 核 CPU 极限 CPU 占用率可以接近 800%,4 核 CPU 极限 CPU 占用率可以接近 400%。CPU 占用率低于 30% 阀值就可以认为已经闲置,性能差的设备阀值可以设置低一点,但都要基于 CPU 核数为基础设置。
Timer().also { it.schedule(object : TimerTask() { override fun run() { val cpuUsage = getCpuUsage() Log.v("@@@", "cpuUsage = $cpuUsage") } }, 0, 5000) } private val cpuCount = Runtime.getRuntime().availableProcessors() private var procStatFile: RandomAccessFile? = null private var appStatFile: RandomAccessFile? = null private var lastTotalCpuTime: Double = 0.0 private var lastAppCpuTime: Double = 0.0 private fun getCpuUsage(): Double { val totalCpuTime = getTotalCpuTime() val appCpuTime = getAppCpuTime() Log.v("@@@", "totalCpuTime = $totalCpuTime, appCpuTime = $appCpuTime, cpuCount = $cpuCount") // CPU 使用率百分比 return (100 * (appCpuTime / totalCpuTime)) * cpuCount } private fun getTotalCpuTime(): Double { if (procStatFile == null) { procStatFile = RandomAccessFile("/proc/stat", "r") } else { procStatFile!!.seek(0) } val procStat = procStatFile!!.readLine() val procStats = procStat.split(" ") var curCpuTime = 0.0 val curIdleTime = procStats[5].toDouble() // 2-8 项数据累加就是 CPU 总运行时间 // CPU 总运行时间 = user + system + nice + idle + iowait + irq + soft_irq for (i in 2..8) { curCpuTime += procStats[i].toDouble() } if (lastTotalCpuTime == 0.0) { lastTotalCpuTime = curCpuTime return 0.0 } val total = curCpuTime - lastTotalCpuTime lastTotalCpuTime = curCpuTime return total } private fun getAppCpuTime(): Double { if (appStatFile == null) { appStatFile = RandomAccessFile("/proc/${android.os.Process.myPid()}/stat", "r") } else { appStatFile!!.seek(0) } val appStat = appStatFile!!.readLine() val appStats = appStat.split(" ") // 14-17 项数据累加就是该进程 CPU 消耗时间 // 14-15 项数据累加就是该进程单一线程 CPU 消耗时间 // 进程 CPU 消耗时间 = utime + stime + cutime + cstime // 单一线程 CPU 消耗时间 = utime + stime var appCpuTime = 0.0 for (i in 14..17) { appCpuTime += appStats[i].toDouble() } if (lastAppCpuTime == 0.0) { lastAppCpuTime = appCpuTime return 0.0 } val result = appCpuTime - lastAppCpuTime lastAppCpuTime = appCpuTime return result }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
计算结果可以通过 adb shell top 查看对应 CPU 使用率是否正确。
计算的 cpuUsage 如果小于我们设置的阈值,就可以通知任务队列或者各个业务执行预加载任务了。
但该方案有一定缺陷并不通用,主要原因有以下两个:
-
间隔通过文件读写的方式对性能有一定损耗
-
在 Android API 26(Android 8.0)开始不再支持第三方应用读取
/proc/stat,否则会抛出异常
基于存在以上问题,接下来会讲解第二种推荐的方案判断 CPU 是否闲置:times 函数。
times 函数判断 CPU 是否闲置
times 函数可以直接返回用户的 CPU 时间和系统时间,因为是系统函数会直接从内核拿数据,所以不需要解析文件性能较高。
先看下 times 函数提供了什么字段:
times.h struct tms { __kernel_clock_t tms_utime; // 用户 cpu 时间 __kernel_clock_t tms_stime; // 系统 cpu 时间 __kernel_clock_t tms_cutime; // 已终止子进程的用户 cpu 时间 __kernel_clock_t tms_cstime; // 已终止子进程的用户系统时间 }; #include <jni.h> #include <string> #include <sys/times.h> extern "C" JNIEXPORT jfloat JNICALL Java_com_example_native_1demo_MainActivity_getCpuTime(JNIEnv *env, jobject thiz) { struct tms currentTms; times(¤tTms); return currentTms.tms_utime + currentTms.tms_stime; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
可以看到 times 函数只能读取到应用消耗的 CPU 时间,没法获取到总的 CPU 时间,那么该怎么计算 CPU 使用率判断 CPU 是否处于闲置呢?实际上我们还可以通过应用的 CPU 速率来判断 CPU 是否已经闲置,CPU 速率 = 单位时间内进程消耗的 CPU 时间 / 单位时间。
MainActivity.java private lateinit var timer: Timer private var beforeCpuTime = 0f private val random = Random() private var num: Int = 0 private val handler = object : Handler(Looper.getMainLooper()) { // 模拟 cpu 计算消耗 override fun handleMessage(msg: Message) { for (i in 0 until 100_0000) { num += i } sendEmptyMessageDelayed(0, random.nextInt(5000).toLong()) } } override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) handler.sendEmptyMessageDelayed(0, random.nextInt(5000).toLong()) timer = Timer() timer.schedule(object: TimerTask() { override fun run() { val cpuTime = getCpuTime() // 计算单位时间内的 CPU 速率 val cpuSpeed = (cpuTime - beforeCpuTime) / 5f Log.v("@@@", "cpuSpeed = $cpuSpeed") if (cpuSpeed <= 0.1) { Log.v("@@@", "cpu is idle") } beforeCpuTime = cpuTime } }, 0, 5 * 1000) } override fun onDestroy() { super.onDestroy() timer.cancel() handler.removeCallbacksAndMessages(null) } private external fun getCpuTime(): Float companion object { // Used to load the 'native_demo' library on application startup. init { System.loadLibrary("native_demo") } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
当应用处于闲置状态时,CPU 速率一定在 0.1 以下,我们可以根据应用的特性,设置一个阀值判断 CPU 是否处于闲置状态。当 CPU 闲置时我们可以预执行的事情很多,比如预创建页面的 View、预拉取数据、预创建次级页面的关键对象等等。
减少 CPU 等待
从底层分析 CPU 实际上是没有等待这种状态,CPU 要么是运行,要么是闲置,所谓的 CPU 等待其实是某个线程或进程拿到 CPU 时间片在当前指令段停下来,长时间无法接着执行后面代码指令的情况,也就是代码可能出现空循环导致 CPU 空转、CPU 被切走去执行其他线程。
两种情况经常导致 CPU 等待,一是等待锁,二是等待 IO。
锁优化
在 Java 并发编程时通常用 synchronized 加锁保证并发任务的准确,但某个线程拿到锁,其他线程可能就得等待锁。
那么为什么锁 synchronized 会影响 CPU?请求 synchronized 流程如下:
-
判断锁是否被其他线程持有,如果有则通过多次循环判断锁是否释放,这个过程会导致 CPU 空转
-
多次 CPU 空转还是无法获得,请求锁的线程会陷入休眠加入等待队列,待锁释放后被唤醒
无论是 CPU 空转还是休眠都会导致当前线程无法获得 CPU 资源,如果是核心线程比如主线程或渲染线程,就会导致体验速度变慢。
所以我们要合理的使用锁,可以遵循以下原则:
-
无锁比有锁好:这里指的是该加锁的地方才加,可以不需要的就不加锁;除了不加锁,还有线程本地存储、偏向锁等方案,都属于无锁优化
-
合理处理锁的粒度、数量:相比整个方法都是 synchronized,更推荐在存在线程安全的代码合理用 synchronized 代码块针对处理,细化锁的粒度提高性能;当然在某些场景应该粗化锁的粒度,比如 StringBuffer.append() 时,虚拟机会将每个 append() 内部的锁粗化共用一把锁
IO 任务分离
在前面已经分析过 IO 读写实际上是 DMA 在执行和 CPU 无关,此时就会出现两种情况:
-
其他线程要执行 CPU 任务,任务调度器会将 CPU 切换给其他线程
-
没有 CPU 相关任务,CPU 一直等待直到 DMA 读写数据完成,再接着执行后面的代码逻辑
以上两种情况对于线程来说,执行完所有指令的时间变长了,也就是指令所消耗的平均时钟周期时间变长了。如果线程是主线程或者渲染线程,会导致体验速度变慢。
为了减少等待 IO 导致的 CPU 使用率下降,我们 可以将 IO 任务分离即将 IO 任务从主线程或主流程分离出来,单独用 IO 线程池处理;对于主线程必须要先拿到 IO 任务结果才执行后面逻辑的场景,可以默认用静态数据展示,等待 IO 任务拿到数据后再更新界面,就能做到主线程缩短了等待 IO 的时间了。
IO 任务分离并不是说不等待 IO,而是要求将主流程的任务拆分得足够细,先执行一些不需要等待 IO 的处理,IO 完成后再刷新处理。
缓存优化:局部性原理与 dex 类文件重排序
缓存对提升速度来说至关重要,但缓存始终受着容量的制约,所以 我们做缓存时,始终要考虑在有限的容量内需要缓存哪些数据,以及如何提升缓存的命中率。当命中率较低时,业务的速度就会变慢,此时我们就需要想办法提升命中率了。
空间换时间:局部性原理
程序运行是 CPU 不断读取程序指令并执行的过程:CPU 在读取指令时,会先从寄存器读,寄存器没有再从高速缓存读,最后才从主存读取,读取到指令后,也会先从主存加载到高速缓存,再从高速缓存加载到寄存器。
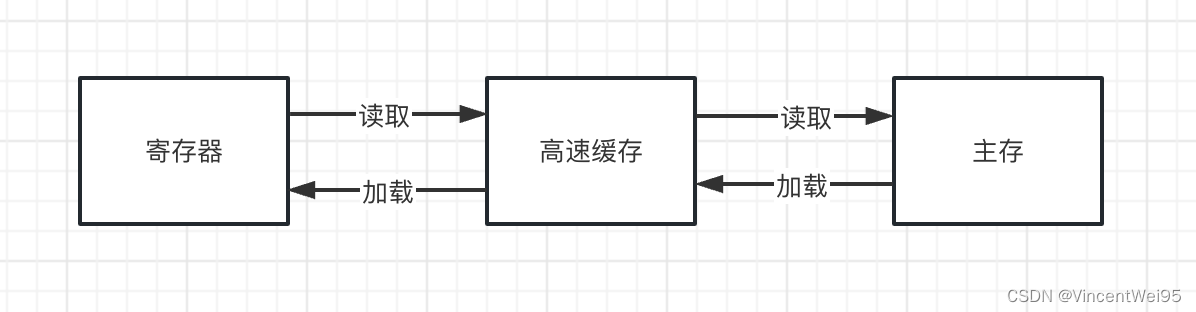
高速缓存从主存读取的数据量大小是有限的,这个大小为 cache line 个字节,在 Linux 也被称为页,一页的大小和 CPU 型号有关,主流是 64 个字节大小。
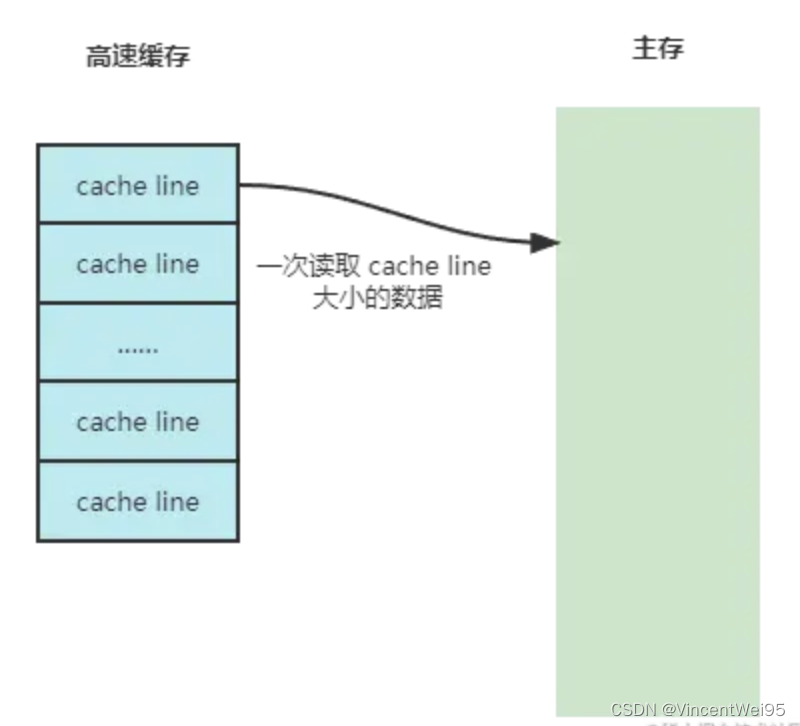
高速缓存读取数据时会一次读满一页,即使 CPU 需要的数据只有 4 个字节,高速缓存也会读满 64 个字节的数据,以此降低高速缓存读主存的次数,提升高速缓存的命中率,让 CPU 更快执行指令。该操作就涉及到了局部性原理。
局部性是一个很重要的概念,计算机硬件中用到了大量的局部性原理来提升命中率。局部性通常有两种不同的形式:时间局部性和空间局部性。
时间局部性表示被使用过一次的数据很可能在后面还会再被多次使用。
空间局部性表示如果一个数据被使用了一次,那么接下里这个数据附近的数据也很很可能被使用。
高速缓存读取数据就是按照空间局部性来读的,也就是读取当前需要被使用的数据,以及在内存上紧挨着的数据,总共凑齐一页大小的数据后再加载进高速缓存中。
了解了高速缓存读取数据的原理后,我们就能利用这个规则来优化程序的速度了。在程序执行过程中,假设需要读取一个对象的数据,高速缓存不仅仅读取这一个对象的数据,还会读取这个对象后面紧挨的一些对象,直到数据量达到一页(一般是 64 个字节)。如果这个对象在内存上紧挨着的对象就是接下来马上被用到的,高速缓存就不需要多次读取数据了,CPU 也减少了等待数据读取的时间,能更快的执行程序指令,程序运行得更快。
Redex:dex 类文件重排序提升缓存命中率
根据上面讲述的局部性原理,也可以应用到 dex 文件的读取。
当我们的项目被编译成 apk 包,所有的 class 文件会整合后放在一个个 dex 文件中。这个时候,dex 文件中 class 文件的顺序并不是按照程序执行顺序存放的,因为我们也不知道 class 文件的执行顺序。
如果我们能提前将程序运行一遍,把 dex 中的 class 对象的使用顺序收集下来,再按照这个顺序重新调整 dex 文件中类文件的顺序,把互相引用的类尽量放在同个 dex,增加类的 pre-verify,将所有启动相关的类文件,都放在主 dex 文件中,启动当然就会更快了。
上面的流程实现起来还是很复杂的,幸运的是这一套流程也有成熟的开源框架可以直接使用,Facebook 提供了 Redex,其中的 InterDexPass 方案就是使用的局部性原理达到启动优化的目的。
官方文档已经将 Redex 的环境配置和优化项配置讲解得很详细,这里不再赘述。
需要注意的是,如果项目中有使用到热修复等方案将会与 InterDexPass 有冲突会导致优化失效,想要二者兼得需要选择其他补丁方案。
任务调度优化:线程 + CPU 提升任务调度优先级
任务调度优化主要有两个方向:
-
提高任务的优先级
-
减少任务调度的耗时
在前面已经讲过减少任务调度耗时的处理方式,所以这里主要讲下如何提高任务优先级。
提高任务优先级有两种方案:
-
提升核心线程的优先级
-
核心线程绑定 CPU 大核
提升核心线程优先级
上面我们有讲解到,在 Linux 中的进程分为实时进程和普通进程两类。实时进程一般通过 RTPRI(RealTimePriority)值来描述优先级,取值范围是 0 到 99;普通进程一般使用 nice 值描述进程优先级,取值范围是 -20 到 19。为了架构设计统一,Linux 系统会将 nice 值对齐成 prio 值。因为线程在 Linux 系统层面其实也是一个轻量级的进程,所以以上优先级的处理在线程也适用。
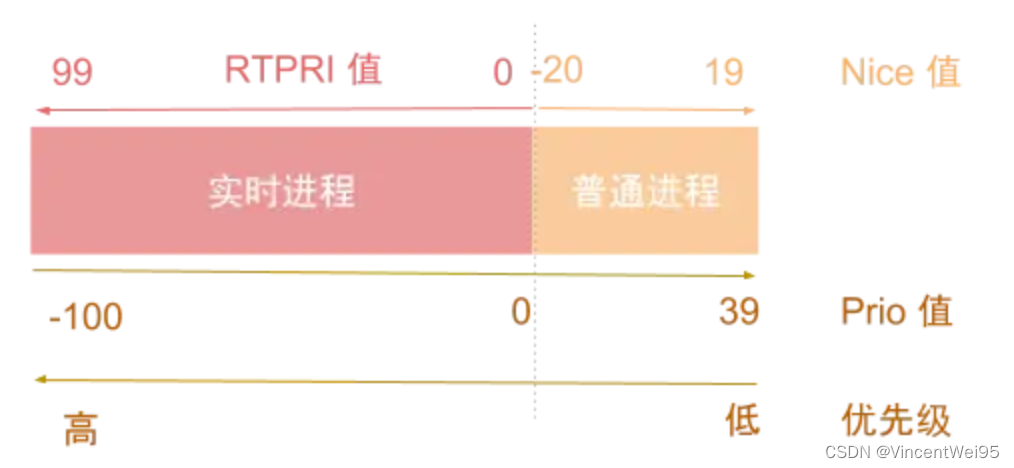
在 Android 中只有部分底层核心进程才是实时进程,如 SurfaceFlinger、Audio 等进程,大部分的进程都是普通进程。应用中的所有线程都属于普通进程的级别,所以我们可以通过修改 nice 值调整线程优先级。
调整线程优先级的方式
调整线程优先级 nice 值有两个 API:
-
Process.setThreadPriority(int priority) / Process.setThreadPriority(int pid, int priority) -
Thread.setPriority(int priority)
第一种方式是 Android 系统提供的 API,如果不传 pid 默认就是当前线程,priority 可以传 -20 到 19 之间的任何一个值,不过还是建议直接使用 Android 提供的 priority 值定义的常量,代码可读性更强。
| 系统常量 | nice 值 | 使用场景 |
|---|---|---|
| Process.THREAD_PRIORITY_DEFAULT | 0 | 默认优先级 |
| Process.THREAD_PRIORITY_LOWEST | 19 | 最低优先级 |
| Process.THREAD_PRIORITY_BACKGROUND | 10 | 后台线程建议优先级 |
| Process.THREAD_PRIORITY_LESS_FAVORABLE | 1 | 比默认略低 |
| Process.THREAD_PRIORITY_MORE_FAVORABLE | -1 | 比默认略高 |
| Process.THREAD_PRIORITY_FOREGROUND | -2 | 前台线程优先级 |
| Process.THREAD_PRIORITY_DISPLAY | -4 | 显示线程建议优先级 |
| Process.THREAD_PRIORITY_URGENT_DISPLAY | -8 | 显示线程的最高优先级 |
| Process.THREAD_PRIORITY_AUDIO | -16 | 音频线程建议优先级 |
| Process.THREAD_PRIORITY_URGENT_AUDIO | -19 | 音频线程最高优先级 |
我们的主线程 nice 值默认为 0,渲染线程默认 nice 值为 -4,音频线程建议是最高级别优先级,因为音频线程优先级太低,就会出现音频播放卡顿的情况。
第二种方式是 Java 提供的 API,Java 有自己对线程优先级的定义和规则,但最后都会转为对应的 nice 值。
| 常量值 | nice 值 | Android 对应 nice 值 | |
|---|---|---|---|
| Thread.MAX_PRIORITY | 10 | -8 | Process.THREAD_PRIORITY_URGENT_DISPLAY |
| Thread.MIN_PRIORITY | 0 | 19 | Process.THREAD_PRIORITY_LOWEST |
| Thread.NORM_PRIORITY | 5 | 0 | Process.THREAD_PRIORITY_DEFAULT |
第二种方式能设置的优先级较少,不太灵活,并且因为系统的一个时许问题 bug,在设置子线程优先级时,可能因为子线程没创建成功而设置成了主线程的,会导致优先级设置异常,所以建议使用 Process.setThreadPriority() 来设置线程的优先级,避免使用 Thread.setPriority()。
调整主线程和渲染线程(RenderThread)优先级
在 Android 我们可以调整主线程和渲染线程,因为这两个线程对任何应用来说都非常重要。从 Android 5 开始,主线程只负责布局文件的 measure 和 layout,渲染工作放到了渲染线程,两个线程配合工作界面才能在应用正常显示出来。所以通过提升这两个线程优先级,便能让这两个线程获得更多的 CPU 时间,页面显示速度自然也就更快了。
调整主线程优先级
主线程的优先级调整很简单,直接在 Application 的 attachBaseContext() 调用 Process.setThreadPriority(-19),将主线程设置为最高级别优先级即可。
调整渲染线程优先级
渲染线程又该怎么调整呢?API 需要提供 pid,如果我们能找到渲染线程的 id 就可以调整了。
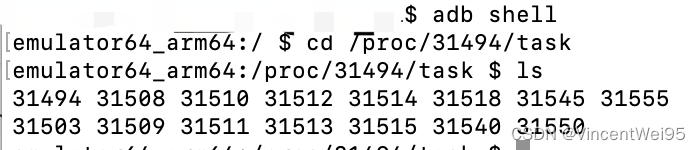
应用中线程的信息记录在 /proc/pid/task 中,我们可以通过遍历这个目录下的文件查找渲染线程:
1、先查看设备所有的进程,找到应用的 pid
adb shell ps // 先查看设备所有的进程,通过包名找到应用的 pid
- 1

假设我们要查看的进程是 com.example.demo,pid 是 31494。
2、查看应用的所有线程信息
adb shell
cd /proc/31494/task // 查看 com.example.demo 进程的所有线程信息
- 1
- 2
3、接着查看目录线程的 stat 节点,就能具体查看线程的详细信息了,比如 tid、name 等
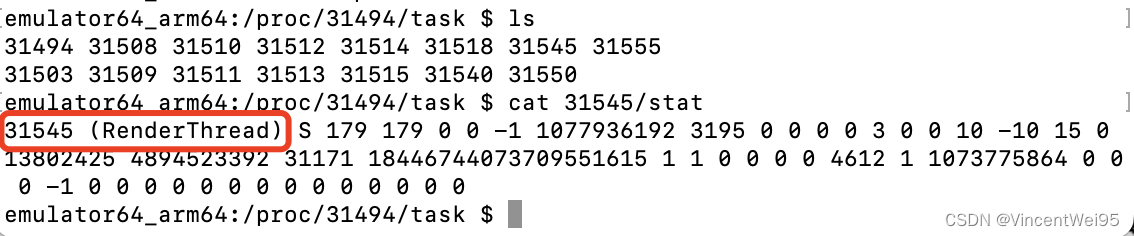
所以我们要找到渲染线程的 pid,只需要遍历 /proc/pid/task 目录下的所有目录,查看 pid/stat 文件,如果有名称为 (RenderThread),第一个信息就是渲染线程 pid 了。拿到 pid 也就能调整线程优先级:
private fun getRenderThreadTid(): Int { val appAllThreadMsgDir = File("/proc/${android.os.Process.myPid()}/task/") if (!appAllThreadMsgDir.isDirectory) return -1 val files = appAllThreadMsgDir.listFiles() ?: arrayOf() var result = -1 files.forEach { file -> val br = BufferedReader(FileReader("${file.path}/stat"), 100) val cpuRate = br.use { return@use br.readLine() } if (!cpuRate.isNullOrEmpty()) { val param = cpuRate.split(" ") if (param.size >= 2) { val threadName = param[1] if (threadName == "(RenderThread)") { result = param[0].toInt() return@forEach } } } } return result } val pid = getRenderThreadTid() if (pid != -1) { Process.setThreadPriority(pid, -19) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
当然,我们要提高的优先级线程并非只有这两个,我们可以根据业务需要,来提高核心线程的优先级,同时降低其他非核心线程的优先级,该操作可以在线程池中通过线程工厂来统一调整。提高核心线程优先级,降低非核心线程优先级,两者配合使用,才能更高效地提升应用的速度。
核心线程绑定 CPU 大核
核心线程绑定 CPU 大核的方案虽然和任务调度关系不大,但也属于一种提升线程优先级的方案,其实就是将核心线程运行在性能更好的 CPU 上以提高运行速度,比如将主线程和渲染线程绑定在大核,提高页面显示速度。
线程绑核并不是很复杂的事情,因为 Linux 系统有提供相应的 API 接口,系统提供了 pthread_setaffinity_np 和 sched_setaffinity 两个函数,都能实现线程绑核。不过 Android 系统限制了 pthread_setaffinity_np 函数的使用,所以只能通过 sched_setaffinity 函数进行绑核操作。

sched_setaffinity 函数需要传入三个参数:
-
pid:线程 pid,如果 pid 的值为 0 则表示指定的是主线程
-
cpusetsize:mask 所指定的数的长度
-
mask:需要绑定的 cpu 序列的掩码
#include <jni.h>
#include <sched.h>
extern "C"
JNIEXPORT jint JNICALL
Java_com_example_demo_MainActivity_bindMaxFreqCore(JNIEnv *env, jobject thiz,
jint max_freq_cpu_index, jint pid) {
cpu_set_t mask;
// 将 mask 置空
CPU_ZERO(&mask);
// 将需要绑定的 CPU 核设置给 mask,核为序列 0、1、2、3...
CPU_SET(max_freq_cpu_index, &mask);
// 线程绑核
return sched_setaffinity(pid, sizeof(mask), &mask);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
线程绑定大核我们需要两个参数:CPU 大核的序列位置、绑定大核的线程 pid。
获取 CPU 大核的序列位置,其实就是要知道哪个 CPU 的时钟频率是最高的。那么怎么知道是哪个 CPU 核的时钟频率是最高的?
获取大核序列位置
可以通过 /sys/devices/system/cpu/ 目录下的文件查看当前设备有几个 CPU,可以看到如下设备是有 8 个 CPU:

我们进入其中一个 cpu 目录的 cpu{x}/cpufreq/ 目录的 /cpuinfo_max_freq 可以查看该 cpu 的时钟周期频率,这里我们进入 cpu0 查看它的时钟周期频率:

这里也将该设备所有的 CPU 时钟周期频率列出来:
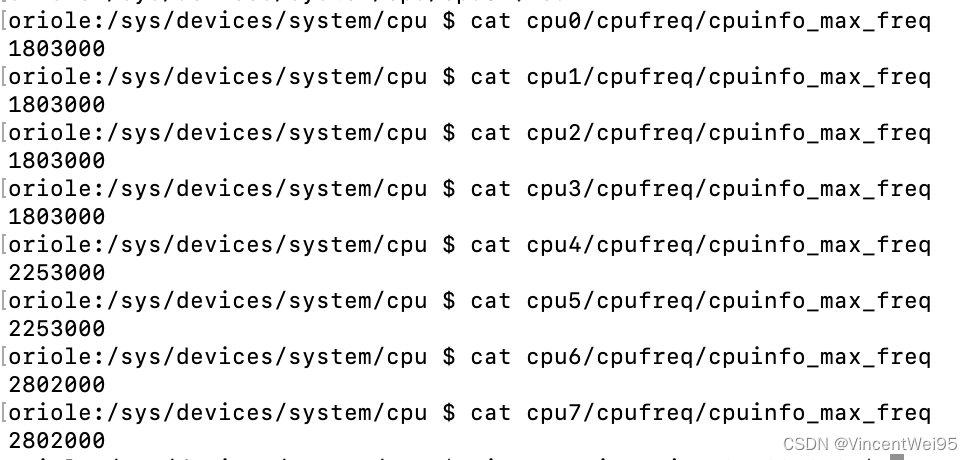
可以看到这台设备的 cpu6 和 cpu7 就是我们要找的大核。
所以获取 CPU 时钟频率最高的核序列操作如下:
-
访问
/sys/devices/system/cpu/目录遍历文件,记录设备的 CPU 数量 -
根据 CPU 数量遍历访问
/sys/devices/system/cpu/cpu{x}/cpufreq/cpuinfo_max_freq获取最大的 CPU 时钟周期频率,同时也能知道大核的 CPU 序列位置
// 获取 CPU 数量 private fun getNumberOfCpuCores(): Int { val files = File("/sys/devices/system/cpu/").listFiles() var size = 0 files?.forEach { file -> val path = file.name if (path.startsWith("cpu")) { val chars = path.toCharArray() for (i in 3 until path.length) { if (chars[i] in '0'..'9') { size++ } } } } return size } // 获取 CPU 大核序列位置 private fun getMaxFreqCPUIndex(): Int { val cores = getNumberOfCpuCores() if (cores == 0) return -1 var maxFreq = -1 var maxFreqCPUIndex = 0 for (i in 0 until cores) { val filename = "/sys/devices/system/cpu/cpu$i/cpufreq/cpuinfo_max_freq" val cpuInfoMaxFreqFile = File(filename) if (!cpuInfoMaxFreqFile.exists()) continue val buffer = ByteArray(128) FileInputStream(cpuInfoMaxFreqFile).use { stream -> stream.read(buffer) var endIndex = 0 while (buffer[endIndex].toInt().toChar() in '0'..'9') endIndex++ val freqBound = String(buffer, 0, endIndex).toInt() if (freqBound > maxFreq) { maxFreq = freqBound maxFreqCPUIndex = i } } } return maxFreqCPUIndex }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
线程绑定大核步骤
线程绑定大核操作步骤如下:
-
获取时钟频率最高(即性能最好)的 CPU 核序列
-
获取需要绑定的线程 pid
-
调用 shced_setaffinity 函数将线程绑定到大核
下面以渲染线程绑定 CPU 大核为例:
class MainActivity : AppCompatActivity() { override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) // 获取渲染线程 pid val renderThreadTid = getRenderThreadTid() Log.v("@@@", "renderThreadTid = $renderThreadTid") // 获取 CPU 大核序列位置 val maxFreqCPUIndex = getMaxFreqCPUIndex() Log.v("@@@", "maxFreqCPUIndex = $maxFreqCPUIndex") // 线程绑定大核,返回 0 表示成功,否则失败 val result = bindMaxFreqCore(maxFreqCPUIndex, renderThreadTid) Log.v("@@@", "result = $result") } private fun getNumberOfCpuCores(): Int { val files = File("/sys/devices/system/cpu/").listFiles() var size = 0 files?.forEach { file -> val path = file.name if (path.startsWith("cpu")) { val chars = path.toCharArray() for (i in 3 until path.length) { if (chars[i] in '0'..'9') { size++ } } } } return size } private fun getMaxFreqCPUIndex(): Int { val cores = getNumberOfCpuCores() if (cores == 0) return -1 var maxFreq = -1 var maxFreqCPUIndex = 0 for (i in 0 until cores) { val filename = "/sys/devices/system/cpu/cpu$i/cpufreq/cpuinfo_max_freq" val cpuInfoMaxFreqFile = File(filename) if (!cpuInfoMaxFreqFile.exists()) continue val buffer = ByteArray(128) FileInputStream(cpuInfoMaxFreqFile).use { stream -> stream.read(buffer) var endIndex = 0 while (buffer[endIndex].toInt().toChar() in '0'..'9') endIndex++ val freqBound = String(buffer, 0, endIndex).toInt() if (freqBound > maxFreq) { maxFreq = freqBound maxFreqCPUIndex = i } } } return maxFreqCPUIndex } private fun getRenderThreadTid(): Int { val appAllThreadMsgDir = File("/proc/${android.os.Process.myPid()}/task/") if (!appAllThreadMsgDir.isDirectory) return -1 val files = appAllThreadMsgDir.listFiles() ?: arrayOf() var result = -1 files.forEach { file -> val br = BufferedReader(FileReader("${file.path}/stat"), 100) val cpuRate = br.use { return@use br.readLine() } if (!cpuRate.isNullOrEmpty()) { val param = cpuRate.split(" ") if (param.size >= 2) { val threadName = param[1] if (threadName == "(RenderThread)") { result = param[0].toInt() return@forEach } } } } return result } private external fun bindMaxFreqCore(maxFreqCpuIndex: Int, pid: Int): Int companion object { // Used to load the 'demo' library on application startup. init { System.loadLibrary("demo") } } } native-lib.cpp #include <jni.h> #include <sched.h> extern "C" JNIEXPORT jint JNICALL Java_com_example_demo_MainActivity_bindMaxFreqCore(JNIEnv *env, jobject thiz, jint max_freq_cpu_index, jint pid) { cpu_set_t mask; // 将 mask 置空 CPU_ZERO(&mask); // 将需要绑定的 CPU 核设置给 mask,核为序列 0、1、2、3... CPU_SET(max_freq_cpu_index, &mask); return sched_setaffinity(pid, sizeof(mask), &mask); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115

