
- 1Nginx网站使用CDN之后禁止用户真实IP访问的方法
- 2PyQt(Python+Qt)学习随笔:model/view架构中的两个标准模型QStandardItemModel和QFileSystemModel_qstandarditemmodel qfilesystemmodel
- 3音频变速python版_语音 语速语调 调节 python
- 4mac python3 轻松安装教程
- 5热力图_c++ opencv 热力图
- 6Streamlit+Echarts画出的图表,真的是太精湛了!!_streamlit echarts
- 7成为有钱人的终极秘诀:做到这7步,你也可以成为富人!_成为富人秘诀
- 8【SpringBoot Web框架实战教程(开源)】02 SpringBoot 返回 JSON
- 9【粉丝福利社】《AI高效工作一本通》(文末送书-完结)
- 10【全网唯一】触摸精灵iOS版纯离线本地文字识别插件_tomatoocr文字识别工具,纯本地离线识别
02|无需任何机器学习,如何利用大语言模型做情感分析?_大语言模型 情感分析
赞
踩
上一讲我们看到了,大型语言模型的接口其实非常简单。像 OpenAI 就只提供了 Complete 和 Embedding 两个接口,其中,Complete 可以让模型根据你的输入进行自动续写,Embedding 可以将你输入的文本转化成向量。
不过到这里,你的疑问可能就来了。不是说现在的大语言模型很厉害吗?传统的自然语言处理问题都可以通过大模型解决。可是用这么简单的两个 API,能够完成原来需要通过各种 NLP 技术解决的问题吗?比如情感分析、文本分类、文章聚类、摘要撰写、搜索,这一系列问题怎么通过这两个接口解决呢?
别急,在接下来的几讲里,会告诉你,怎么利用大语言模型提供的这两个简单的 API 来解决传统的自然语言处理问题。这一讲我们就先从一个最常见的自然语言处理问题——“情感分析”开始,来看看我们怎么把大语言模型用起来。
传统的二分类方法:朴素贝叶斯与逻辑回归
“情感分析”问题,是指我们根据一段文字,去判断它的态度是正面的还是负面的。在传统的互联网产品里,经常会被用来分析用户对产品、服务的评价。比如大众点评里面,你对餐馆的评论,在京东买个东西,你对商品的评论,都会被平台拿去分析,给商家或者餐馆的评分做参考。也有些品牌,会专门抓取社交网络里用户对自己产品的评价,来进行情感分析,判断消费者对自己的产品评价是正面还是负面的,并且会根据这些评价来改进自己的产品。
对于“情感分析”类型的问题,传统的解决方案就是把它当成是一个分类问题,也就是先拿一部分评论数据,人工标注一下这些评论是正面还是负面的。如果有个用户说“这家餐馆真好吃”,那么就标注成“正面情感”。如果有个用户说“这个手机质量不好”,那么就把对应的评论标注成负面的。
我们把标注好的数据,喂给一个机器学习模型,训练出一组参数。然后把剩下的没有人工标注过的数据也拿给训练好的模型计算一下。模型就会给你一个分数或者概率,告诉你这一段评论的感情是正面的,还是负面的。
可以用来做情感分析的模型有很多,这些算法背后都是基于某一个数学模型。比如,很多教科书里,就会教你用朴素贝叶斯算法来进行垃圾邮件分类。朴素贝叶斯的模型,就是简单地统计每个单词和好评差评之间的条件概率。一般来说,如果一个词语在差评里出现的概率比好评里高得多,那这个词语所在的评论,就更有可能是一个差评。
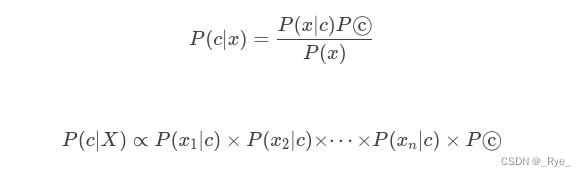
假设我们有一个训练集包含 4 封邮件,其中 2 封是垃圾邮件,2 封是非垃圾邮件。训练集里的邮件包含这些单词。
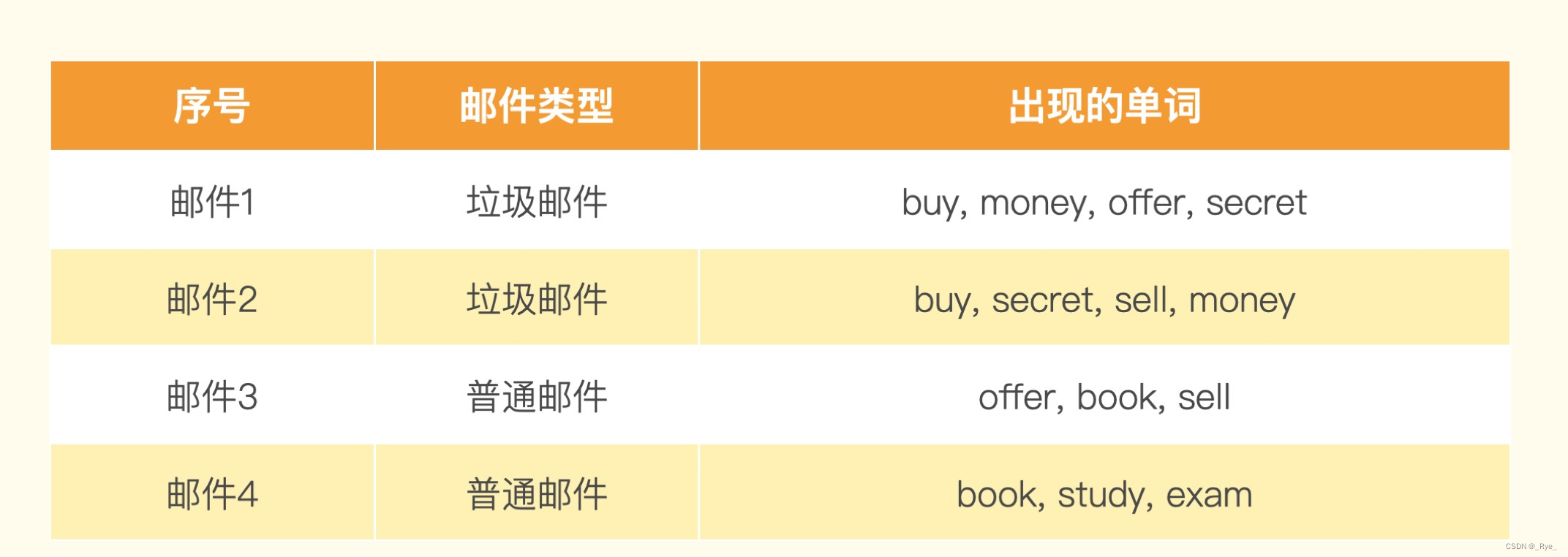
然后来了一封新邮件,里面的单词是:buy、money、sell。
通过这些单词出现的概率,我们很容易就可以预先算出这封邮件是垃圾邮件还是普通邮件。

然后我们把这封邮件里所有词语的条件概率用全概率公式乘起来,就得到了这封邮件是垃圾邮件还有普通邮件的概率。
P(垃圾∣X)∝P(buy∣垃圾)×P(money∣垃圾)×P(sell∣垃圾)×P(垃圾)=1×1×0.5×0.5=0.25
P(普通∣X)∝P(buy∣普通)×P(money∣普通)×P(sell∣普通)×P(普通)=0×0×0.5×0.5=0
在这里,我们发现 P(垃圾∣X)>P(普通∣X),而且 P(普通∣X) 其实等于 0。那如果用朴素贝叶斯算法,我们就会认为这封邮件 100% 是垃圾邮件。如果你觉得自己数学不太好,这个例子没有看明白也没有关系,因为我们接下来的 AI 应用开发都不需要预先掌握这些数学知识,所以不要有心理负担。
类似的,像逻辑回归、随机森林等机器学习算法都可以拿来做分类。你在网上,特别是 Kaggle 这个机器学习比赛的网站里,可以搜索到很多其他人使用这些传统方法来设计情感分析的解决方案。这些方案都以 Jupyter Notebook 的形式出现,在这里放个链接,有兴趣的话也可以去研究一下。
传统方法的挑战:特征工程与模型调参
但这些传统的机器学习算法,想要取得好的效果,还是颇有门槛的。除了要知道有哪些算法可以用,还有两方面的工作非常依赖经验。
特征工程
第一个是特征工程。对于很多自然语言问题,如果我们只是拿一段话里面是否出现了特定的词语来计算概率,不一定是最合适的。比如“这家餐馆太糟糕了,一点都不好吃”和 “这家餐馆太好吃了,一点都不糟糕”这样两句话,从意思上是完全相反的。但是里面出现的词语其实是相同的。在传统的自然语言处理中,我们会通过一些特征工程的方法来解决这个问题。
比如,我们不只是采用单个词语出现的概率,还增加前后两个或者三个相连词语的组合,也就是通过所谓的 2-Gram(Bigram 双字节词组)和 3-Gram(Trigram 三字节词组)也来计算概率。在上面这个例子里,第一句差评,就会有“太”和“糟糕”组合在一起的“太糟糕”,以及“不”和“好吃”组合在一起的“不好吃”。而后面一句里就有“太好吃”和“不糟糕”两个组合。有了这样的 2-Gram 的组合,我们判断用户好评差评的判断能力就比光用单个词语是否出现要好多了。
这样的特征工程的方式有很多,比如去除停用词,也就是“的地得”这样的词语,去掉过于低频的词语,比如一些偶尔出现的专有名词。或者对于有些词语特征采用 TF-IDF(词频 - 逆文档频率)这样的统计特征,还有在英语里面对不同时态的单词统一换成现在时。
不同的特征工程方式,在不同的问题上效果不一样,比如我们做情感分析,可能就需要保留标点符号,因为像“!”这样的符号往往蕴含着强烈的情感特征。但是,这些种种细微的技巧,让我们在想要解决一个简单的情感分析问题时,也需要撰写大量文本处理的代码,还要了解针对当前特定场景的技巧,这非常依赖工程师的经验。
机器学习相关经验
第二个就是你需要有相对丰富的机器学习经验。除了通过特征工程设计更多的特征之外,我们还需要了解很多机器学习领域里常用的知识和技巧。比如,我们需要将数据集切分成训练(Training)、验证(Validation)、测试(Test)三组数据,然后通过 AUC 或者混淆矩阵(Confusion Matrix)来衡量效果。如果数据量不够多,为了训练效果的稳定性,可能需要采用 K-Fold 的方式来进行训练。
如果没有接触过机器学习,看到这里,可能已经看懵了。没关系,上面的大部分知识你未来可能都不需要了解了,因为我们有了大语言模型,可以通过它提供的 Completion 和 Embedding 这两个 API,用不到 10 行代码就能完成情感分析,并且能获得非常好的效果。
大语言模型:20 行代码的情感分析解决方案
通过大语言模型来进行情感分析,最简单的方式就是利用它提供的 Embedding 这个 API。这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
我们需要提前计算“好评”和“差评”这两个字的 Embedding。而对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。那么,我们把这段文本的 Embedding 和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。
下面我们就用这个方法分析一下两条在京东上购买了 iPhone 用户的评论。
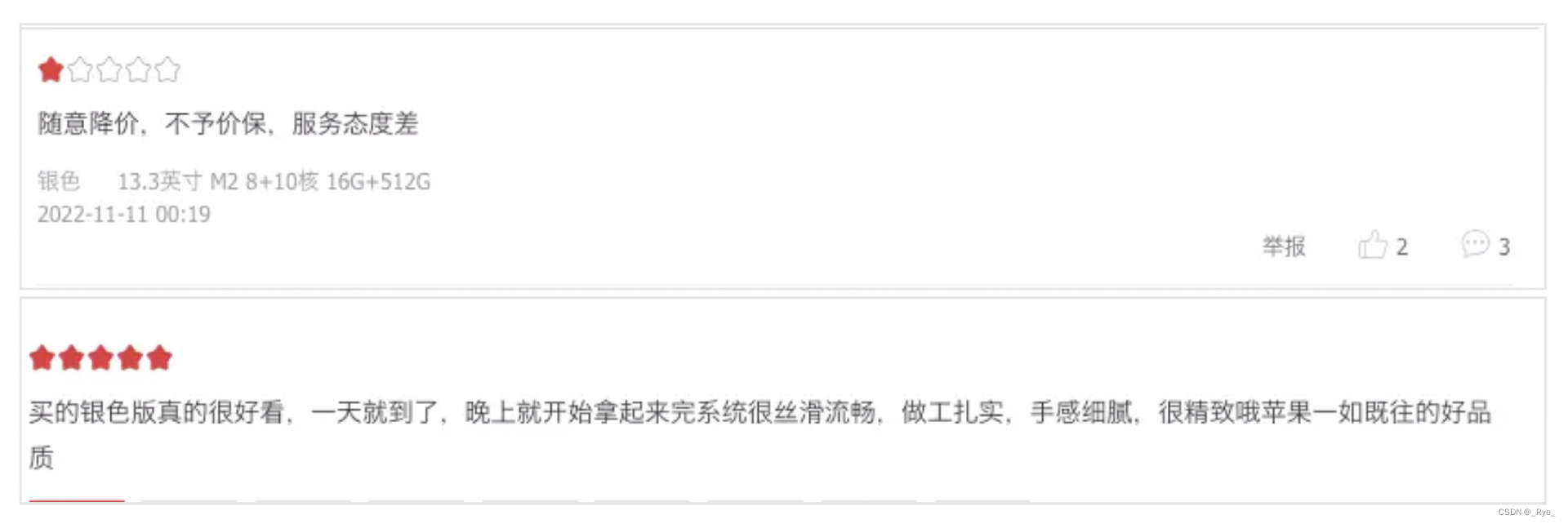
这个使用大模型的方法一共不到 40 行代码,我们看看它能否帮助我们快速对这两条评论进行情感分析。
- from openai import OpenAI
- import numpy as np
- import os
-
- client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
-
- EMBEDDING_MODEL = "text-embedding-ada-002"
-
- def get_embedding(text, model=EMBEDDING_MODEL):
- text = text.replace("\n", " ")
- return client.embeddings.create(input = [text], model=model).data[0].embedding
-
- def cosine_similarity(vector_a, vector_b):
- dot_product = np.dot(vector_a, vector_b)
- norm_a = np.linalg.norm(vector_a)
- norm_b = np.linalg.norm(vector_b)
- epsilon = 1e-10
- cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
- return cosine_similarity
-
- positive_review = get_embedding("好评")
- negative_review = get_embedding("差评")
-
- positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
- negative_example = get_embedding("随意降价,不予价保,服务态度差")
-
- def get_score(sample_embedding):
- return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
-
- positive_score = get_score(positive_example)
- negative_score = get_score(negative_example)
-
- print("好评例子的评分 : %f" % (positive_score))
- print("差评例子的评分 : %f" % (negative_score))

输出结果:
- 好评例子的评分 : 0.070963
- 差评例子的评分 : -0.081472
正如我们所料,京东上的好评通过 Embedding 相似度计算得到的分数是大于 0 的,京东上面的差评,这个分数是小于 0 的。
这样的方法,是不是特别简单?我们再拿刚才的例子试一下,看看这个方法是不是对所有词语都管用,只是出现的位置不同但含义截然相反的评论,能得到什么样的结果。
- good_restraurant = get_embedding("这家餐馆太好吃了,一点都不糟糕")
- bad_restraurant = get_embedding("这家餐馆太糟糕了,一点都不好吃")
-
- good_score = get_score(good_restraurant)
- bad_score = get_score(bad_restraurant)
- print("好评餐馆的评分 : %f" % (good_score))
- print("差评餐馆的评分 : %f" % (bad_score))
输出结果:
- 好评餐馆的评分 : 0.062719
- 差评餐馆的评分 : -0.074591
可以看到,虽然两句话分别是“太好吃”“不糟糕”和“太糟糕”“不好吃”,其实词语都一样,但是大语言模型一样能够帮助我们判断出来他们的含义是不同的,一个更接近好评,一个更接近差评。
更大的数据集上的真实案例
在这里,我们只举了几个例子,看起来效果还不错。这会不会只是我们运气好呢?我们再来拿一个真实的数据集验证一下,利用这种方法进行情感分析的准确率能够到多少。
下面这段代码,是来自 OpenAI Cookbook 里面的一个例子。它是用同样的方法,来判断亚马逊提供的用户对一些食物的评价,这个评价数据里面,不只有用户给出的评论内容,还有用户给这些食物打了几颗星。这些几颗星的信息,正好可以拿来验证我们这个方法有多准。对于用户打出 1~2 星的,我们认为是差评,对于 4~5 星的,我们认为是好评。
我们可以通过 Pandas,将这个 CSV 数据读取到内存里面。为了避免重新调用 OpenAI 的 API 浪费钱,这个数据集里,已经将获取到的 Embedding 信息保存下来了,不需要再重新计算。
- import pandas as pd
- import numpy as np
-
- from sklearn.metrics import classification_report
-
- datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
-
- df = pd.read_csv(datafile_path)
- df["embedding"] = df.embedding.apply(eval).apply(np.array)
-
- # convert 5-star rating to binary sentiment
- df = df[df.Score != 3]
- df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
每一条评论都用我们上面的方法,和一个预先设定好的好评和差评的文本去做对比,然后看它离哪个近一些。这里的好评和差评,我们写得稍微长了一点,分别是 “An Amazon review with a negative sentiment.” 和 “An Amazon review with a positive sentiment.”。
在计算完结果之后,我们利用 Scikit-learn 这个机器学习的库,将我们的预测值和实际用户打出的星数做个对比,然后输出对比结果。需要的代码,也就不到 20 行。
- from sklearn.metrics import PrecisionRecallDisplay
-
- def evaluate_embeddings_approach(
- labels = ['negative', 'positive'],
- model = EMBEDDING_MODEL,
- ):
- label_embeddings = [get_embedding(label, engine=model) for label in labels]
-
- def label_score(review_embedding, label_embeddings):
- return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
-
- probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
- preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
-
- report = classification_report(df.sentiment, preds)
- print(report)
-
- display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
- _ = display.ax_.set_title("2-class Precision-Recall curve")
-
- evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
输出结果:
- precision recall f1-score support
- negative 0.98 0.73 0.84 136
- positive 0.96 1.00 0.98 789
- accuracy 0.96 925
- macro avg 0.97 0.86 0.91 925
- weighted avg 0.96 0.96 0.96 925
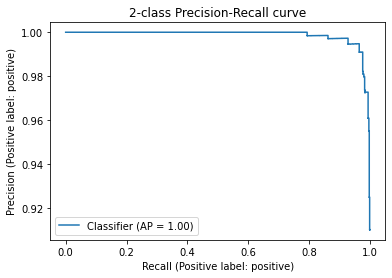
在结果里面可以看到,我们这个简单方法判定的好评差评的精度,也就是 precision 在 negative 和 positive 里,分别是 0.98 和 0.96,也就是在 95% 以上。
而召回率,也就是图里的 recall,在差评里稍微欠缺一点,只有 73%,这说明还是有不少差评被误判为了好评。不过在好评里,召回率则是 100%,也就是 100% 的好评都被模型找到了。这样综合考虑下来的整体准确率,高达 96%。而要达到这么好的效果,我们不需要进行任何机器学习训练,只需要几行代码调用一下大模型的接口,计算一下几个向量的相似度就好了。
小结
这一讲,我们利用不同文本在大语言模型里 Embedding 之间的距离,来进行情感分析。这种使用大语言模型的技巧,一般被称做零样本分类(Zero-Shot Classification)。
所谓零样本分类,也就是我们不需要任何新的样本来训练机器学习的模型,就能进行分类。我们认为,之前经过预训练的大语言模型里面,已经蕴含了情感分析的知识。我们只需要简单利用大语言模型里面知道的“好评”和“差评”的概念信息,就能判断出它从未见过的评论到底是好评还是差评。
这个方法,在一些经典的数据集上,轻易就达到了 95% 以上的准确度。同时,也让一些原本需要机器学习研发经验才能完成的任务变得更加容易,从而大大降低了门槛。
如果你所在的公司今天想要做一个文本分类的应用,通过 OpenAI 的 API 用几分钟时间就能得到想要的结果。
课后练习
利用大模型来解决问题,不是一个理论问题,而是一个实战问题。请你尝试将这个方法运用在别的数据集上,看看是否也会有很好的效果?比如,你可以试着用 Kaggle 提供的亚马逊耳机类商品的评论数据,看看结果是怎样的?这个数据集比较大,你可以挑几条数据试一下。因为 OpenIA 会对你的调用限速,免费的 Token 数量也比较有限。对于限速情况下的大批量数据的处理,我们会在第 04 讲讲解。
数据集链接:https://www.kaggle.com/datasets/shitalkat/amazonearphonesreviews

