- 1必备iOS设备解锁工具:iToolab UnlockGo for Mac(4.1.4中文)_appletools4.1
- 2拆分xlsx与csv(python实现)_pathon len(sheetnames)
- 3K-Means聚类和层次聚类_层次聚类和kmeans聚类
- 4將IP地址改成自動獲取的詳細步驟
- 5Eureka介绍与使用
- 6MySQL 数据库设计_部门表数据库设计
- 7Day 30:100346. 使二进制数组全部等于1的最小操作次数Ⅱ
- 8Logistic回归与牛顿迭代法_newton 迭代算法的 logistic 回归模型
- 9css基础-盒子(div)模型、背景属性、边框线的设置、padding、margin、网站的设置思想(float),图片代替列表符号_div边框线怎么设置
- 10基于pyqt5实现一款简单的界面软件(radioButton、comboBox、pushButton、图片显示)_python的qt做简单界面
Redis创建集群_redis7 创建集群
赞
踩
主要内容
搭建redis集群
能力目标
搭建redis集群
一 应用场景
为什么需要redis集群?
当主备复制场景,无法满足主机的单点故障时,需要引入集群配置。
一般数据库要处理的读请求远大于写请求 ,针对这种情况,我们优化数据库可以采用读写分离的策略。我们可以部 署一台主服务器主要用来处理写请求,部署多台从服务器 ,处理读请求。
二 基本原理
哨兵选举机制,如果有半数节点发现某个异常节点,共同决定改异常节点的状态,如果该节点是主节点,对应的备节点自动顶替为主节点。Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
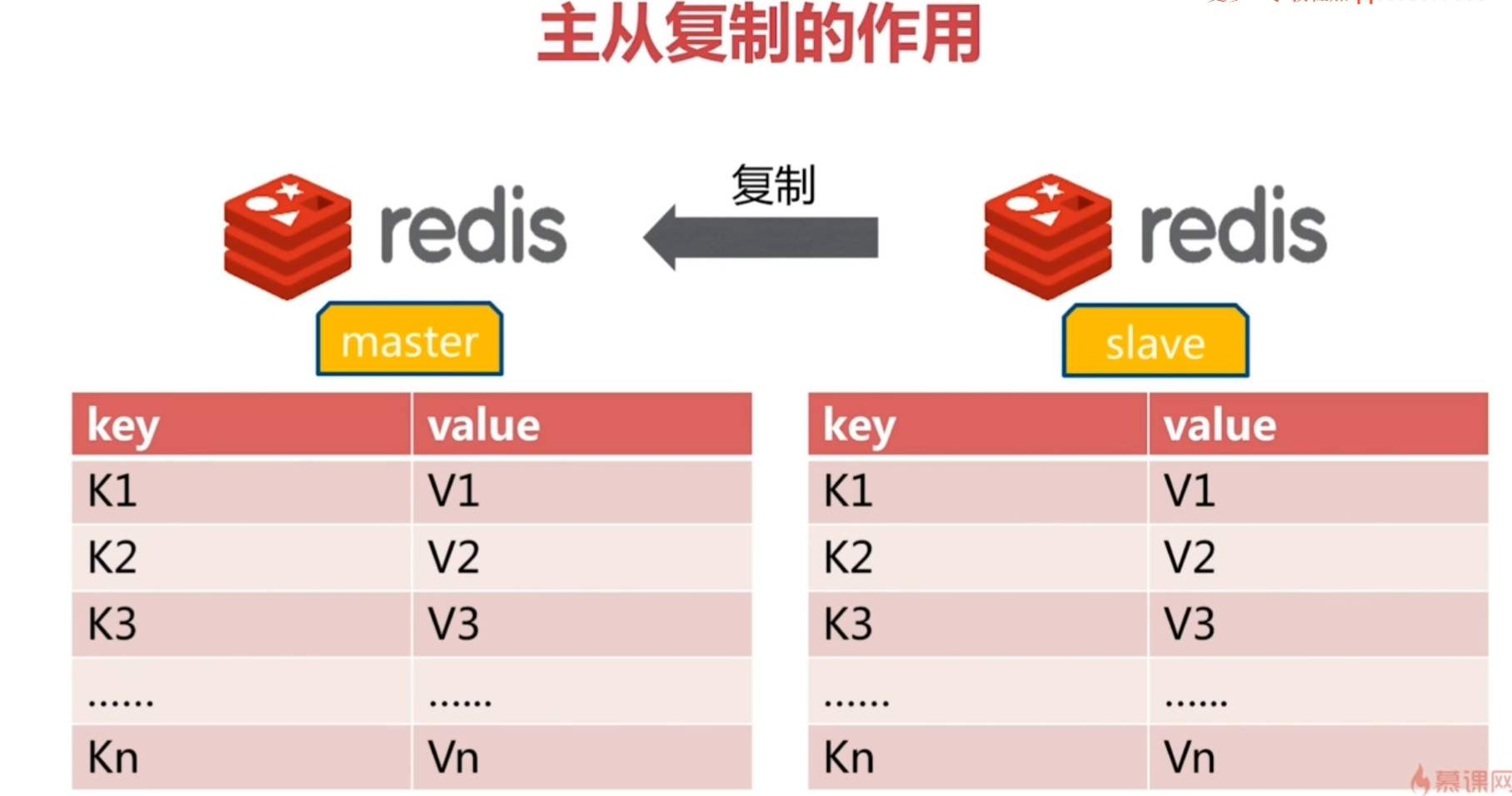
主从复制的作用
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4、读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量。
5、高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
配置集群所需的环境
Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里是一样的。
1,规划网络。
用一台虚拟机模拟6个节点,一台机器6个节点,创建出3 master、3 salve 环境。虚拟机是 CentOS7 ,ip地址192.168.159.34
2,创建 Redis 节点
首先在 192.168.159.34 机器上 /usr/java/目录下创建 redis_cluster 目录;
mkdir redis_cluster
3 创建目录
在 redis_cluster 目录下,创建名为7001、7002,7003、7004、7005,7006的目录
mkdir 7001 7002 7003 7004 7005 7006

4 将 redis.conf 拷贝到这六个目录中,
echo ./7002 ./7003 ./7004 ./7005 ./7006 | xargs -n 1 cp -v /usr/java/redis_cluster/7001/redis.conf

5 配置redis7001.conf
- include /usr/java/redis_cluster/redis.conf
- port 7001
- pidfile "/var/run/redis_7001.pid"
- dbfilename "dump_7001.rdb"
- dir "/usr/java/redis_cluster/7001"
- logfile "/usr/java/redis_cluster/7001/redis_err_7001.log"
- cluster-enabled yes
- cluster-config-file nodes-7001.conf
- cluster-node-timeout 15000
后台启动
6 启动这6个redis
- root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_cluster/7001/redis.conf
- [root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_cluster/7002/redis.conf
- [root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_cluster/7003/redis.conf
- [root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_cluster/7004/redis.conf
- [root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_cluster/7005/redis.conf
- [root@localhost redis_cluster]# /usr/java/redis/bin/redis-server /usr/java/redis_
7 创建redis的集群
/usr/redis/bin/redis-cli --cluster create 192.168.159.34:7001 192.168.159.34:7002 192.168.159.34:7003 192.168.159.34:7004 192.168.159.34:7005 192.168.159.34:7006 --cluster-replicas 1
cluster-replicas 1
1其实代表的是一个比例,就是主节点数/从节点数的比例。那么想一想,在创建集群的时候,哪些节点是主节点呢?哪些节点是从节点呢?答案是将按照命令中IP:PORT的顺序,先是3个主节点,然后是3个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
![]()
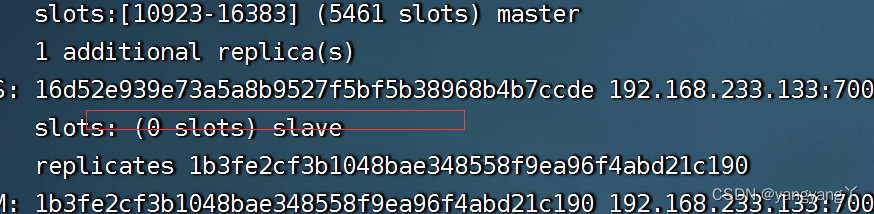
8 使用cli连接redis集群
使用客户端链接集群 必须使用 -c 连接
/usr/java/redis/bin/redis-cli -c -h 192.168.159.34 -p 7002
查看集群的节点的信息 :cluster nodes


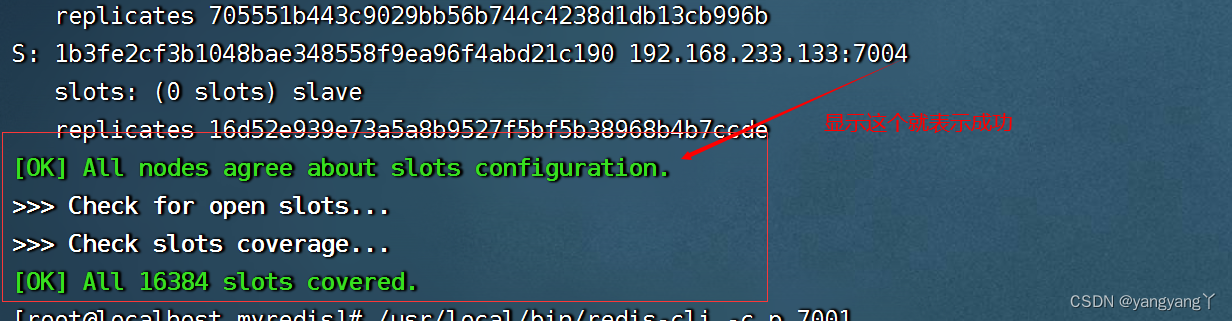
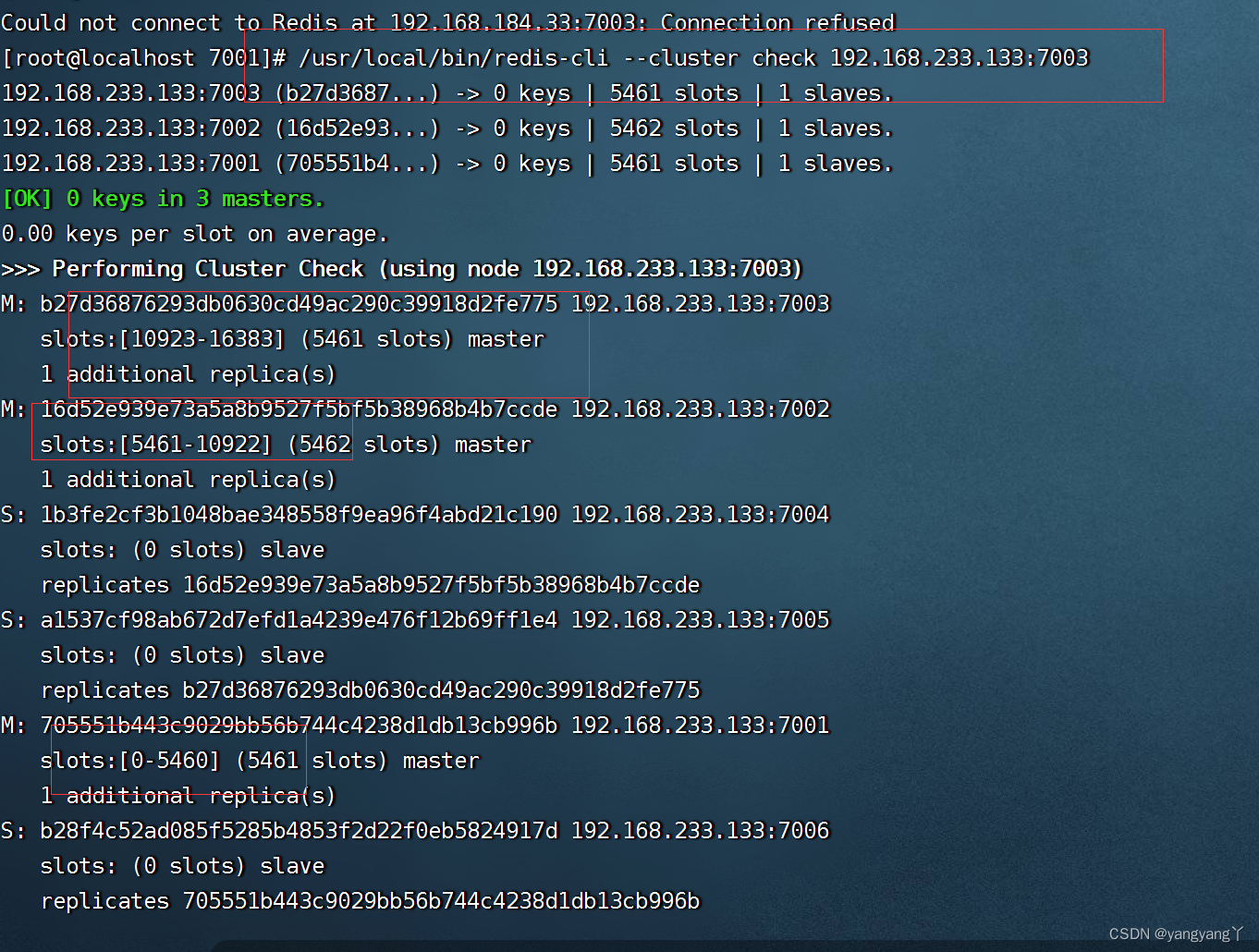
9 检查集群的状态
/usr/java/redis/bin/redis-cli --cluster check 192.168.159.34:7002
10 添加主节点
配置文件 7007 /redis.conf
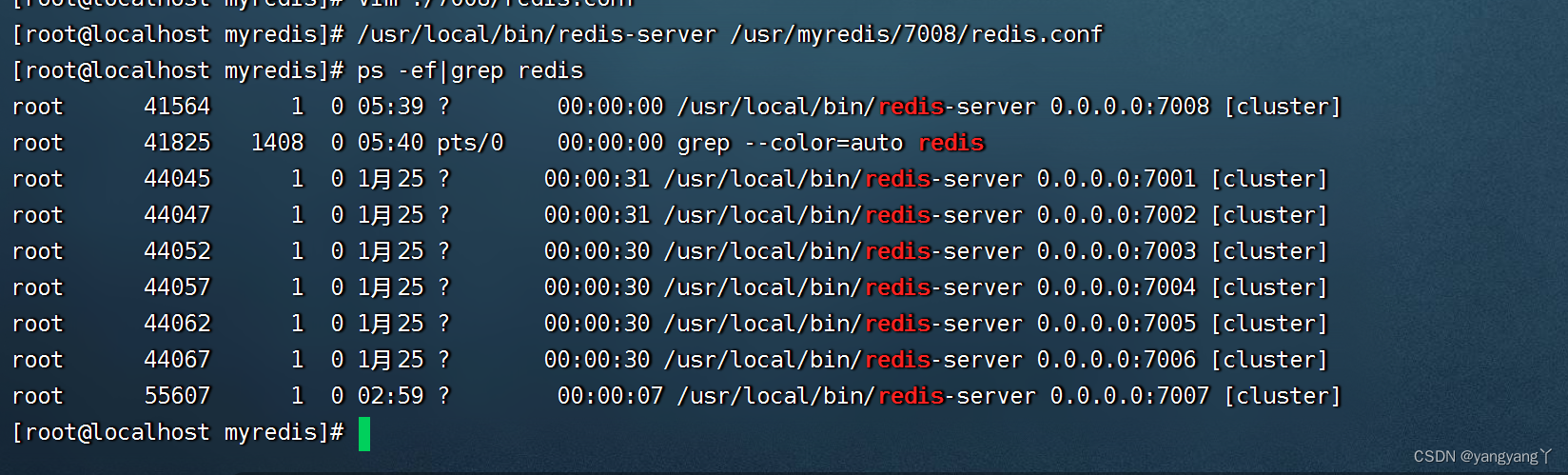
启动
在添加之前首先要像7001-6一样,修改配置文件,启动7007 服务
/usr/java/redis/bin/redis-cli --cluster add-node 192.168.159.34:7007 192.168.159.34:7002
前面的IP加端口号是要添加的redis节点,后面的IP和端口号是集群中的任意一个节点。
检查节点的信息
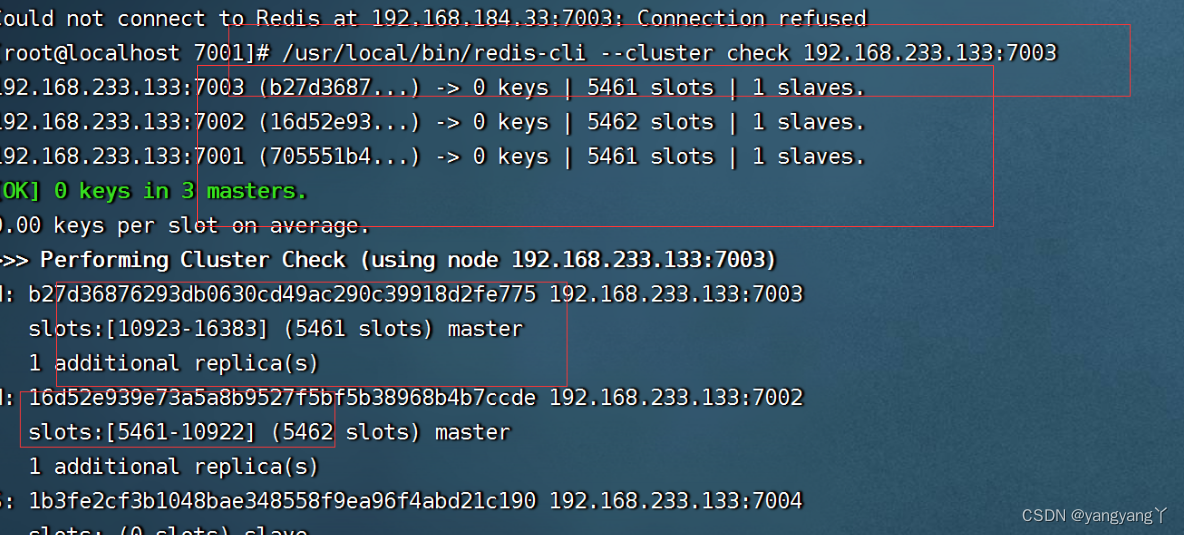
redis-cli --cluster add-node 新节点 集群中的节点
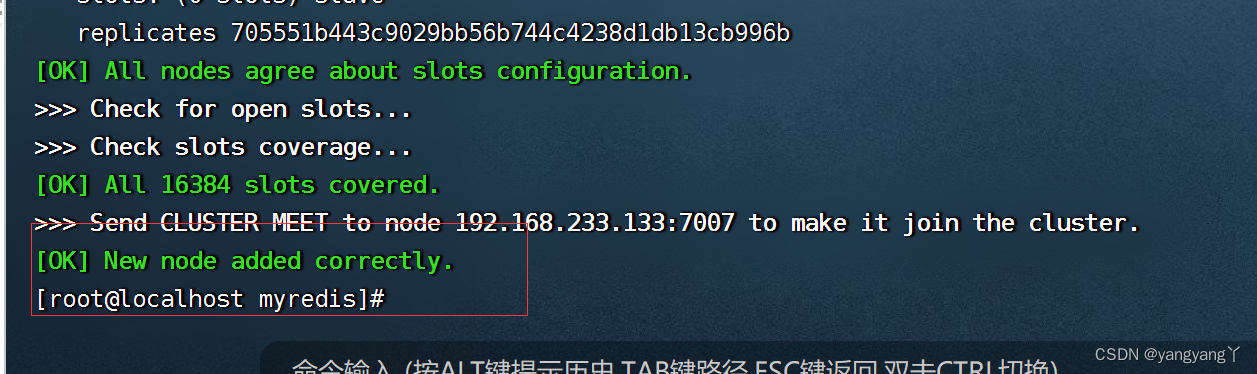

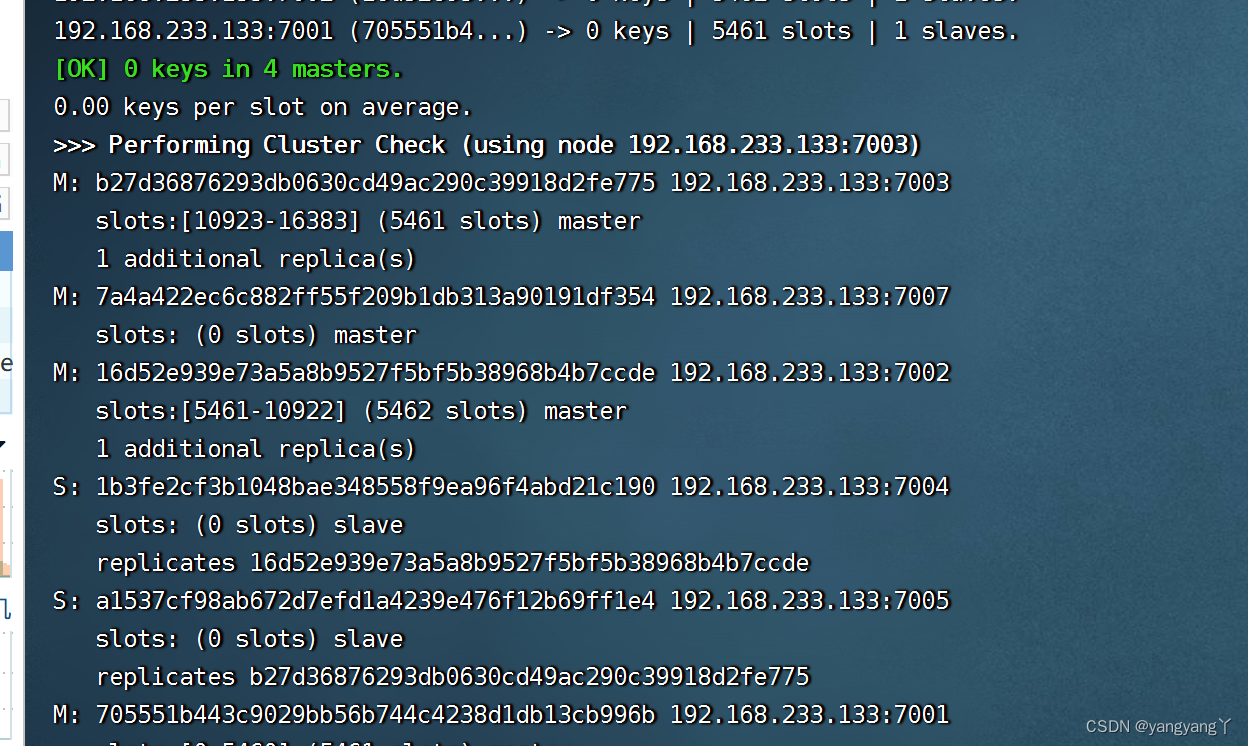
刚才添加的主节点还没有分配槽,所以无法使用
添加从节点之前需要设置从节点并启动节点
--cluster-master-id 为从节点对应主节点的id
/usr/java/redis/bin/redis-cli --cluster add-node 192.168.159.34:7008 192.168.159.34:7002 --cluster-slave --cluster-master-id 67211a02cffe48ee7197092ca48e9e7294dc5961
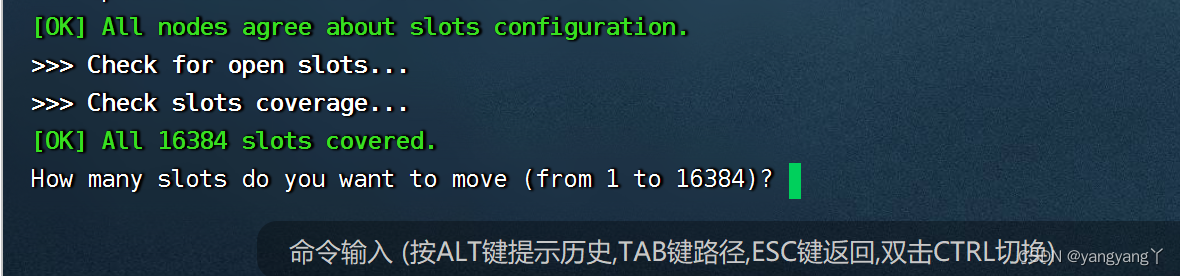
可以随意分配数量
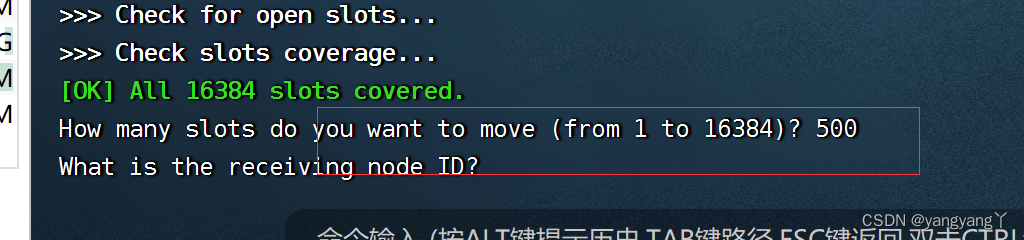


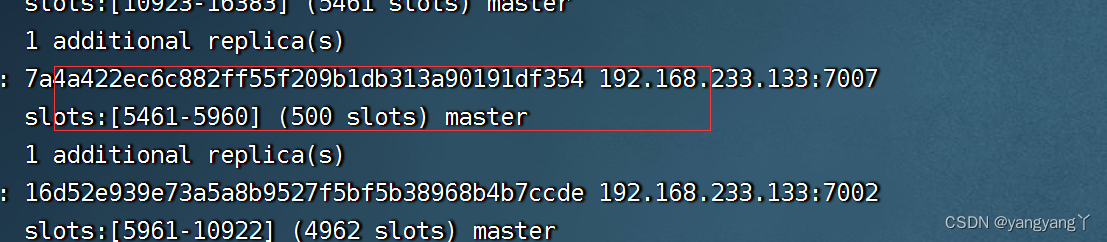
显示上图卡槽分配成功
批量添加
集群中进行批量添加
不允许
想添加
分组
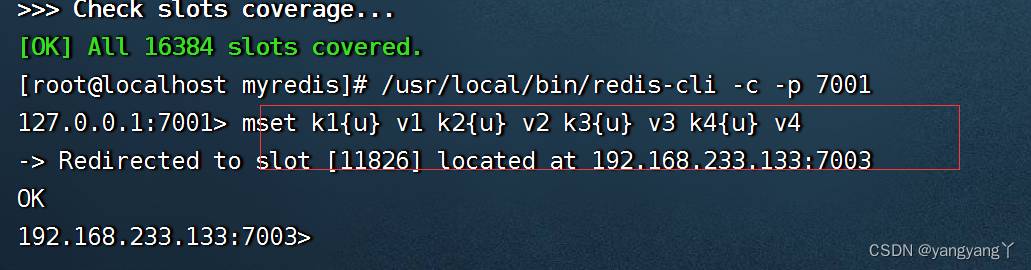
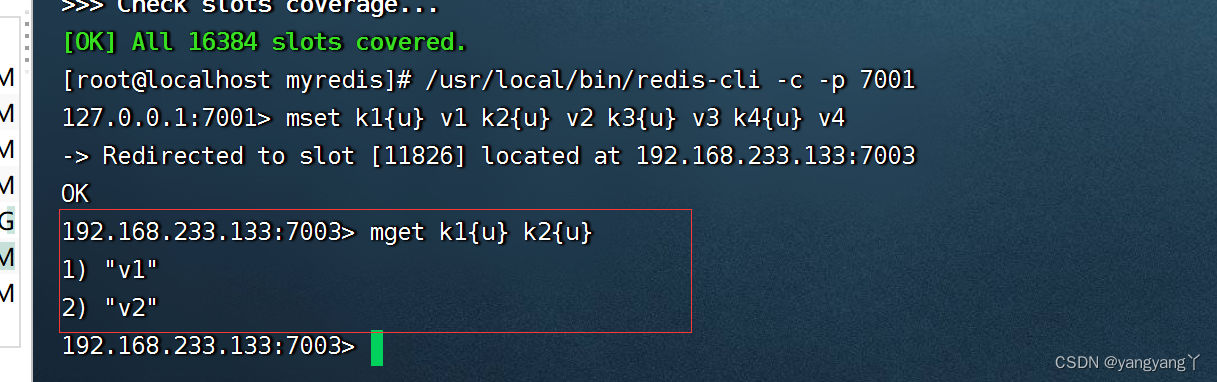
{名字}
Mset k{u} 当设置了组名的时候分配槽的时候是根据组的名字分配的槽
删除从节点

删除主节点



测试集群
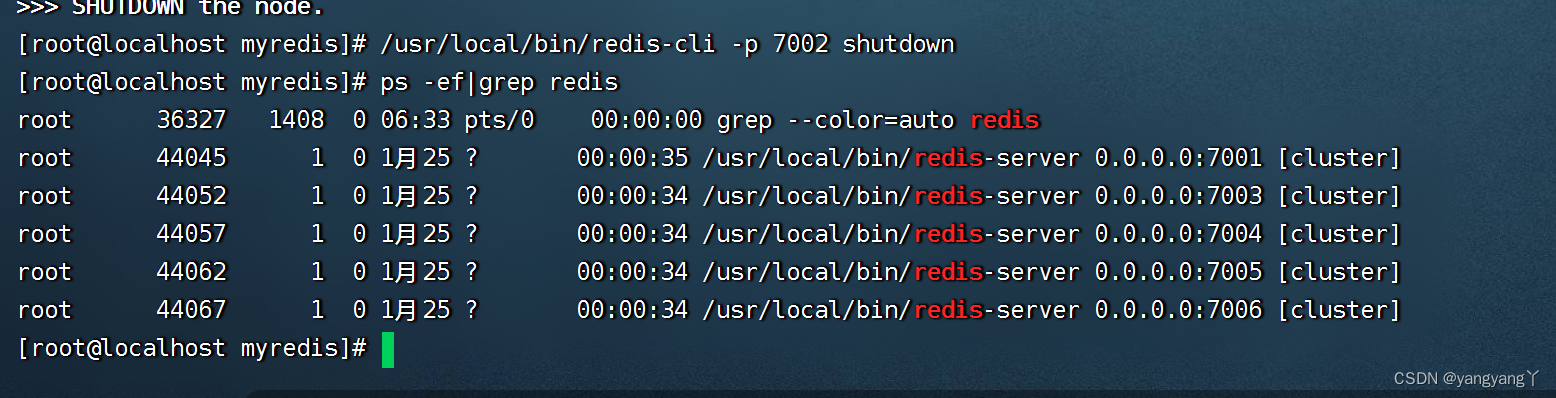
关闭7002
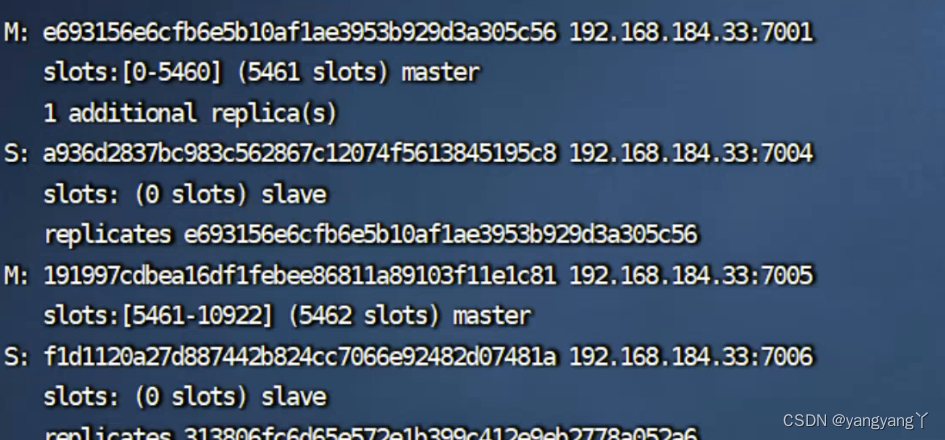
重启7002

重启之后变为从节点