
- 1基于一体化有序信息和事件关系的脚本事件预测_事件关系脚本学习
- 2idea git 合并多个commit_idea git合并多个commit
- 3关于def __init__(self)_def --init--
- 4字节跳动的真实工作体验_字节跳动稳定吗
- 5华为HCIP-Datacom认证题库(H12-821)_mqc与pbr一样,只能在设备的三层接口下调用
- 60.1## 梯度下降的优化算法,SGD中的momentum冲量的理解_sgd momentum如何取值
- 7将本地项目上传到GitHub_添加本地git代码到sourcetree
- 8基于Python+Django+Vue+Mysql前后端分离的图书管理系统_djangovue前后端分离图书馆
- 9基于JSP的图书销售管理系统_jsp 图书信息管理 博客
- 10Linux系统Docker部署DbGate并结合内网穿透实现公网管理本地数据库_docker安装基于web的数据库管理工具_dbgate docker
面向小白的最全Python数据分析指南,超全的!
赞
踩
因工作需求经常会面试一些数据分析师,一些 coding 能力很强的小伙伴,当被问及数据分析方法论时一脸懵逼的,或者理所当然的认为就是写代码啊,在文章开头先来解释一下数据分析。
数据分析是通过明确分析目的,梳理并确定分析逻辑,针对性的收集、整理数据,并采用统计、挖掘技术分析,提取有用信息和展示结论的过程,是数据科学领域的核心技能。

今天在本文中,我将从数据分析常用逻辑框架及技术方法出发,结合 Python 项目实战全面解读数据分析,可以系统掌握数据分析的框架套路,快速上手数据分析。
【注】资料、技术交流学习,文末获取
一、 数据分析的逻辑 --构建系统的分析维度及指标

1.1 PEST分析法
PEST分析是指宏观环境的分析,宏观环境是指影响一切行业或企业的各种宏观力量。P是政治(Politics),E是经济(Economy),S是社会(Society),T是技术(Technology)。通常是战略咨询顾问用来帮助企业检阅其外部宏观环境的一种方法,以吉利收购沃尔沃为例:

1.2 5W2H分析法
5W2H分析法又称七何分析法,包括:Why、What、Where、When、Who、How、How much 。主要用于用户行为分析、业务问题专题分析、营销活动等,是一个方便又实用的工具。

1.3 逻辑树分析法

逻辑树是分析问题最常用的工具之一,它是将问题的所有子问题分层罗列,从最高层开始,并逐步向下扩展。使用逻辑树分析的主要优点是保证解决问题的过程的完整性,且方便将工作细分为便于操作的任务,确定各部分的优先顺序,明确地把责任落实到个人。

1.4 4P营销理论
4P即产品(Product)、价格(Price)、渠道(Place)、促销(Promotion),在营销领域,这种以市场为导向的营销组合理论,被企业应用最普遍。通过将四者的结合、协调发展,从而提高企业的市场份额,达到最终获利的目的。
4P营销理论适用于分析企业的经营状况,可视为企业内部环境,PEST分析的是企业在外部面对的环境。

1.5 SCQA分析法
SCQA分析是一个“结构化表达”工具,即S(Situation)情景、C(Complication)冲突、Q(Question)疑问、A(Answer)回答。

整个结构是通过描述当事者的现实状态,然后带出冲突和核心问题,通过结构化分析以提供更为明智的解决方案。以校园招聘SCQA分析为例:

1.6 SMART分析法
SMART法是一种目标管理方法,即对目标的S(Specific)明确性,M(Measurable)可衡量性,A(Attainable)可实现性,R(Relevant)相关性,T(Time-based)时限性。

1.7 SWOT分析法
SWOT分析法也叫态势分析法,S (Strengths)是优势、W (Weaknesses)是劣势,O (Opportunities)是机会、T (Threats)是威胁或风险。常用来确定企业自身的内部优势、劣势和外部的机会和威胁等,从而将公司的战略与公司内部与外部环境有机地结合起来。以HUAWEI 的SWOT分析为例:

二、 数据分析的技术方法
数据分析的技术方法是指提取出关键指标信息的具体方法,如对比分析、交叉分析、回归预测分析等方法。

2.1 对比分析法
对比分析法是将两个或两个以上的数据进行比较,分析差异,揭示发展变化情况和规律。
- 静态比较:时间一致的前提下选取不同指标,如部门、城市、门店等,也叫横向比较。
- 动态比较:指标一致的前提下,针对不同时期的数据比较,也叫纵向比较。
举例:各车企销售表现

2.2 分组分析法
- 先经过数据加工,对数据进行数据分组,然后对分组的数据进行分析。
- 分组的目的是为了便于对比,把总体中具有不同性质的对象区分开,把性质相同的对象合并在一起,保持各组内对象属性的一致性、组与组之间属性的差异性,以便进一步运用各种数据分析方法来解释内在的数量关系。
举例:新书在各销售渠道的销量

2.3 结构分析法
- 结构分析法又称比重分析法,是在分组分析法的基础上,计算总体内各组成部分占总体的比重,进而分析总体数据的内部特征。
举例:市场占有率是典型的结构分析。

2.4 平均分析法(标准参数分析法)
- 运用计算平均数的方法来反映总体在一定的时间、地点条件下某一数量特征的一般水平。
- 平均指标可用于同一现象在不同地区、不同部门或单位间的对比,还可用于同一现象在不同时间的对比。
举例:季节性分析和价格分析时常会用到index指标

2.5 交叉分析法
- 通常用于分析两个变量之间的关系,即同时将两个有一定联系的变量及其值交叉排列在一张表格内,使各变量值成为不同变量的交叉节点,形成交叉表。
举例:常见的气泡图数据表格

2.6 漏斗图分析法
- 漏斗图可以很好的反映网站各步奏转化率,利用对比法对同一环节优化前后的效果进行对比分析来反映某个步奏转化率的好坏。
举例:商品流转率表现图

三、 数据分析的图表展示
图表展示可以帮助我们更好、更直观地看懂数据信息。
图表的选择,不只是关注图表的样式,而关键在于关注数据情况及图表展示的功能。可以通过数据展示的功能(构成、比较、趋势、分布及联系)进行图表选择,如下所示:

四、 项目实战 (python)
4.1 数据内容
数据来源于kesci天猫真实成交订单,主要是行为类数据。
a. 订单编号:订单编号
b. 总金额:订单总金额
c. 买家实际支付金额:总金额 - 退款金额(在已付款的情况下);未付款的支付金额为0
d. 收货地址:全国各个省份
e. 订单创建时间:下单时间
f. 订单付款时间:付款时间(如果未付款,显示NaN)
g. 退款金额:付款后申请退款的金额。未付款的退款金额为0
4.2 天猫订单分析过程
4.2.1 背景及分析目的
以天猫一个月内的订单数据,观察这个月的订单量以及销售额, 分析下单日期、收货地址等因素对订单量的影响以及订单转换情况,旨在提升用户下单量和订单转换率,进而提高用户实际支付额。
4.2.2 分析逻辑
本文结合订单流程以逻辑树方法分析订单数目的影响因素,从以下几个维度展开:

4.2.3 数据读取及处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
# 读取数据
df = pd.read_csv('tmall_order_report.csv')
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

# 利用pandas_profiling一健生成数据情况(EDA)报告:数据描述、缺失、相关性等情况
import pandas_profiling as pp
report = pp.ProfileReport(df)
report
- 1
- 2
- 3
- 4

#规范字段名称
df.columns
- 1
- 2
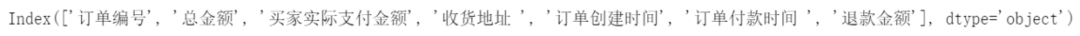
df=df.rename(columns={'收货地址 ':'收货地址','订单付款时间 ':'订单付款时间'})
df.columns
- 1
- 2

#查看数据基本信息
df.info()
- 1
- 2

# 数据类型转换
df['订单创建时间']=pd.to_datetime(df.订单创建时间)
df['订单付款时间']=pd.to_datetime(df.订单付款时间)
df.info()
- 1
- 2
- 3
- 4

# 数据重复值
df.duplicated().sum()
- 1
- 2
无
#数据缺失值
df.isnull().sum()
- 1
- 2

#数据集描述性信息
df.describe()
- 1
- 2
- 3

#筛选数据集
df_payed=df[df['订单付款时间'].notnull()]#支付订单数据集
df_trans=df_payed[df_payed['买家实际支付金额']!=0]#到款订单数据集
df_trans_full=df_payed[df_payed['退款金额']==0]#全额到款订单数据集
- 1
- 2
- 3
- 4
- 5
4.2.4 总体运营指标分析
分析2月份成交订单数的变化趋势
import pyecharts.options as opts #将订单创建时间设为index df_trans=df_trans.set_index('订单创建时间') #按天重新采样 se_trans_month = df_trans.resample('D')['订单编号'].count() from pyecharts.charts import Line #做出标有具体数值的变化图 name = '成交订单数' ( Line() .add_xaxis(xaxis_data = list(se_trans_month.index.day.map(str))) .add_yaxis( series_name= name, y_axis= se_trans_month, ) .set_global_opts( yaxis_opts = opts.AxisOpts( splitline_opts = opts.SplitLineOpts(is_show = True) ) ) .render_notebook() )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

小结 1 :2月上半月,多数企业未复工,快递也停运,暂时无法发货,订单数很少;2月下半月,随着企业复工逐渐增多,订单数开始上涨。
se_trans_map=df_trans.groupby('收货地址')['收货地址'].count().sort_values(ascending=False) # 为了保持收货地址和下面的地理分布图使用的省份名称一致,定义一个处理自治区的函数 def strip_region(iterable): result = [] for i in iterable: if i.endswith('自治区'): if i == '内蒙古自治区': i = i[:3] result.append(i) else: result.append(i[:2]) else: result.append(i) return result # 处理自治区 se_trans_map.index = strip_region(se_trans_map.index) # 去掉末位‘省’字 se_trans_map.index = se_trans_map.index.str.strip('省') import pyecharts.options as opts from pyecharts.charts import Map # 展示地理分布图 name = '订单数' ( Map() .add( series_name = name, data_pair= [list(i) for i in se_trans_map.items()]) .set_global_opts(visualmap_opts=opts.VisualMapOpts( max_=max(se_trans_map)*0.6 ) ) .render_notebook() )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
用直观的地图来观察成交订单数的分布情况

小结 2 :地区对订单数量影响较大,一般较发达地区订单数较大,边远地区较小。这里可能需要具体分析每个地区的商品种类、消费群体以及优惠政策,快递等原因。可以根据原因进一步提高其他地区的订单数量和销售金额。
4.2.5 销售转化指标
订单数以及订单转化率的呈现
dict_convs=dict() #字典 dict_convs['总订单数']=len(df) df_payed dict_convs['订单付款数']=len(df_payed.notnull()) df_trans=df[df['买家实际支付金额']!=0] dict_convs['到款订单数']=len(df_trans) dict_convs['全额到款订单数']=len(df_trans_full) #字典转为dataframe df_convs = pd.Series(dict_convs,name = '订单数').to_frame() df_convs #求总体转换率,依次比上总订单数 total_convs=df_convs['订单数']/df_convs.loc['总订单数','订单数']*100 df_convs['总体转化率']=total_convs.apply(lambda x:round(x,0)) df_convs #求单一转换率 single_convs=df_convs.订单数/(df_convs.订单数.shift())*100 single_convs=single_convs.fillna(100) df_convs['单一转化率']=single_convs.apply(lambda x:round(x,0)) df_convs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

画转换率漏斗图,直观呈现订单转化情况
from pyecharts.charts import Funnel from pyecharts import options as opts name = '总体转化率' funnel = Funnel().add( series_name = name, data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ], is_selected = True, label_opts = opts.LabelOpts(position = 'inside') ) funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%')) funnel.set_global_opts( title_opts = opts.TitleOpts(title = name), # tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'), ) funnel.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

name = '单一转化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

小结 3:从单一转化率来看,支付订单数-到款订单数转换率为79%,后续可以从退款率着手分析退款原因,提高转换率。
关于Python学习指南
数据分析在当今信息时代中扮演着至关重要的角色。无论是企业决策还是学术研究,Python已经成为最受欢迎的数据分析工具之一。但要学会 Python 还是要有一个学习规划,最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等学习教程。带你从零基础系统性的学好Python!
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

