- 1测试开发 | 词嵌入(Word Embeddings):赋予语言以向量的魔力_词嵌入是将词汇表中的每个词映射到
- 2OpenMV:21控制多个舵机(需要模块PCA9685)_openmv控制双舵机
- 3AIGC内容分享(五十五):AIGC周刊
- 4在NVIDIA Orin中编译Apollo 9_apollo 9.0 orin
- 5大数据项目在线实习_数据测试员实习项目
- 6Elasticsearch 未授权访问_elasticsearch未授权访问
- 7【推荐系统】DeepFM模型分析
- 8跟着我,在PS里成功装上SD插件(终极教程!附基本操作步骤)_ps sd插件
- 9stm32+cubemx+淘晶驰串口屏+收发通信并应用_stm32驱动陶晶驰x系列串口屏
- 10原生php开发学生信息管理系统源码_php学生信息管理系统源代码
垂类大模型 研发方向与具体方案调研_如何开发垂直大模型
赞
踩
垂类大模型 研发方向与具体方案调研
一、研发方向调研初步汇总
初步选定垂类大模型研发技术栈如下:
- LLM框架: LLaMA2 38k Star
- 向量数据库:Chroma 8k Star
- LLM应用程序构建:Langchain 58.4 Star
主要训练策略:通用大模型+向量知识库:领域知识库加上通用大模型,针对通用大模型见过的知识比较少的问题,利用向量数据库等方式根据问题在领域知识库中找到相关内容,再利用通用大模型强大的summarization和qa的能力生成回复,完成本次垂直大模型研发。
涉及方向确立的主要参考资料:
1、CLiB中文大模型能力评测榜单(持续更新)
2、主流向量数据库一览
3、一文了解:打造垂域的大模型应用ChatGPT
4、浅谈垂直领域大模型
5、垂直领域大模型的一些思考及开源模型汇总
6、如何将本地知识库接入大模型?
模型部署参考教程:
1、超详细Llama2部署教程——个人gpt体验攻略!
2、LLAMA2一键可运行整合包:Windows10+消费级显卡可用(Meta大语言模型)
二、垂类大模型研发背景与策略选择
1、垂类大模型研发背景
目前很多企业希望将大模型的能力应用到企业内部当中,但很多通用大模型只是一个预训练模型,其所能回答的知识主要来源于互联网上公开的通用知识库,对于部分垂直领域和企业内部的私有知识库的问答,给出的回答往往是大众性质的、普适化的,而非个性化的。面对有时无法让用户得到满意的答案。
2、垂类大模型研发策略选择
下面是目前垂直行业大模型的五种训练策略的简要介绍:
(1)重新训练:
使用通用数据和领域数据混合,from scratch(从头开始)训练了一个大模型,最典型的代表就是BloombergGPT。
(2)二次预训练:
在一个通用模型的基础上做continue pretraining(继续预训练,二次预训练),像LawGPT就是做了二次预训练的。有很多团队尝试过这个方案,但普遍反应效果一般(没有SFT来得直接)。
(3)基础大模型微调:
在一个通用模型的基础上做instruction tuning(sft),这也是现在开源社区最普遍的做法,有大量的工作比如Huatuo,ChatLaw等等。这种做法的优势是可以快速看到不错的结果,但会发现要提高上限比较困难。
(4)通用大模型+向量知识库:
领域知识库加上通用大模型,针对通用大模型见过的知识比较少的问题,利用向量数据库等方式根据问题在领域知识库中找到相关内容,再利用通用大模型强大的summarization和qa的能力生成回复。
(5)In context learning类似微调:
直接用in context learning的方法,通过构造和领域相关的prompt,由通用大模型直接生成回复。随着业界把context window越做越大,prompt中可以放下越来越多的领域知识,直接用通用大模型也可以对领域问题有很好的回复。
以上五种策略对硬件资源+数据 的消耗也是不同的:像【重新训练】一样几乎重新训练一遍模型,需要几百张卡。也可以像【基础大模型微调】一样用几百条数据做做sft,可能几张卡就够了。
综合目前的LLM技术发展前景,以及具体的资源消耗。目前很多垂类大模型的技术解决方案,以【基础大模型微调】+【向量知识库】为主。
三、垂类大模型实现流程
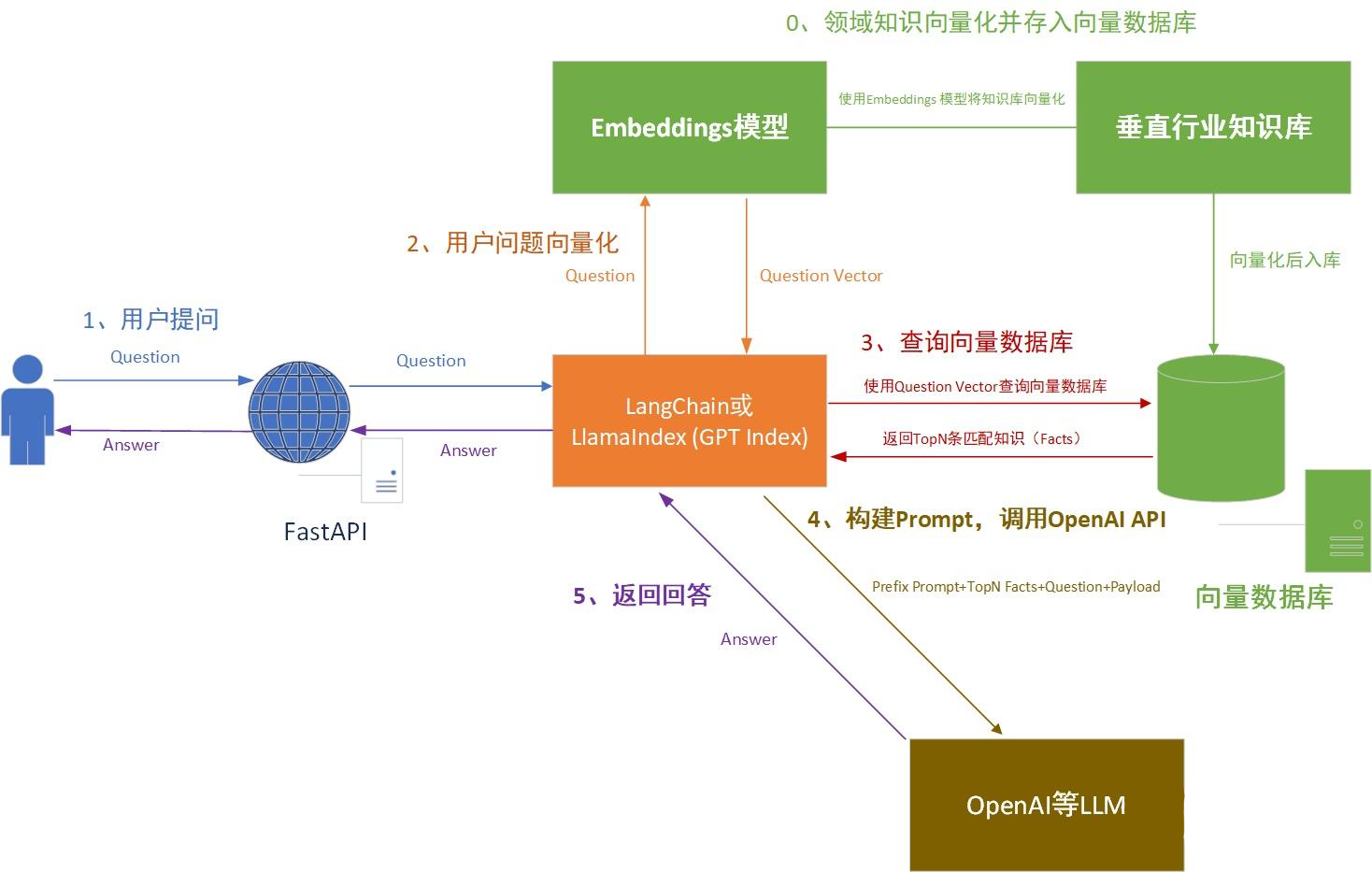
1、整体流程
1、大模型本地化部署:垂类大模型的效果与底座性能息息相关,研发垂类大模型第一步就是确定开源大模型解决方案。
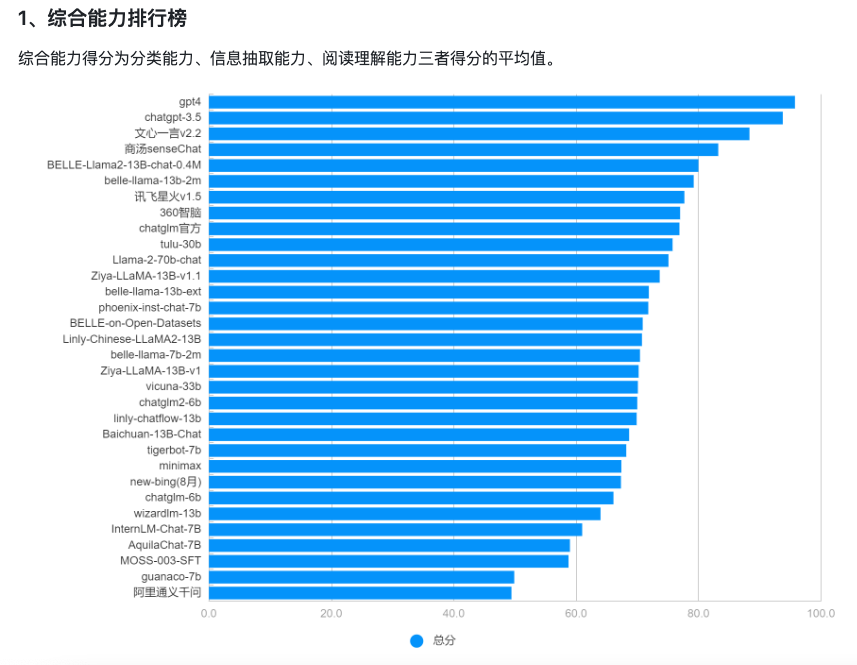
参考综合能力排行榜,我们主要选择llama2,做为我们研发的底座。
Github跳转地址:https://github.com/facebookresearch/llama
部署教程:超详细Llama2部署教程——个人gpt体验攻略!
2、本地垂类领域知识库的搭建:收集整理垂类相关的领域知识/企业知识/专业知识,将垂直行业领域的知识库文档进行Embedding向量化处理,并将处理后的语义向量Vectors存入向量数据库Vector Database中(这个步骤中还包括对非结构化数据先转化成文本数据,并对长文本进行Splitter分割处理)。
3、用户问题向量化:将用户的问题进行向量化Embedding处理,转化为Vector search
4、得到TopN条匹配知识:将用户问题Vector search 和向量数据库进行查询匹配,返回相似度最高的TopN条知识文本
5、构建Prompt,调用OpenAI API:将匹配出的文本和用户的问题上下文一起提交给 LLM,根据Prompt生成最终的回答