
- 1集群所有机器同步执行脚本_控制脚本集体
- 2免费的AI编程codeGeeX插件介绍与使用_codegeex开源的插件
- 3JS特效第160弹:旋转木马轮播图特效_轮播特效
- 4【嵌入式PID温度控制系统】Part 1:电路原理设计_一种应用于温度控制系统的pid控制电路设计
- 5使用Docker搭建Maven私服_docker方式安装maven
- 6SQLServer数据库优化与管理——锁,阻塞,死锁篇_sqlserver rid lock
- 7Windows Server 2022 安装配置——安装 Docker
- 8stm32在keil中出现RDDI-DAP Error,且无法烧录或者仿真_rddi-dap error怎么解决
- 9SpaK-RDD学习总结_rdd数据操作与储存实训小结
- 10HTML+CSS+JavaScript网页特效源代码(复制代码保存即可使用)_html css js源码片段
【精选】基于融合SAConv的改进YOLOv5的街景实例分割全景分割系统_yolov5 图像分割
赞
踩
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着计算机视觉技术的不断发展,实例分割和全景分割成为了研究的热点领域。实例分割是指将图像中的每个对象实例都进行分割,即将每个对象的像素点进行标记;而全景分割则是将整个图像分割成多个不同的区域,每个区域都有一个特定的标签。这两个任务在很多领域都有广泛的应用,例如自动驾驶、智能交通系统、机器人导航等。
然而,传统的实例分割和全景分割方法在处理复杂的街景图像时面临一些挑战。首先,街景图像通常具有复杂的背景和多个重叠的对象实例,这使得分割任务更加困难。其次,传统的方法往往需要大量的计算资源和时间,限制了其在实际应用中的效率和实时性。因此,研究如何改进实例分割和全景分割算法,提高其准确性和效率,具有重要的理论和实际意义。
基于此,本研究提出了一种基于融合SAConv的改进YOLOv5的街景实例分割全景分割系统。该系统结合了SAConv(Spatial Attention Convolution)和YOLOv5(You Only Look Once)两种先进的计算机视觉算法,旨在解决街景图像分割中的困难和挑战。
首先,SAConv是一种具有空间注意力机制的卷积神经网络,能够自动学习图像中不同区域的重要性,从而提高分割的准确性。通过引入SAConv,我们可以更好地处理街景图像中的复杂背景和重叠实例,提高分割的精度。
其次,YOLOv5是一种基于单阶段目标检测的算法,具有高效和实时的特点。我们将YOLOv5应用于实例分割和全景分割任务中,可以大大提高算法的速度和效率,满足实际应用的需求。
此外,我们还对YOLOv5进行了改进,使其更适用于街景图像的分割任务。通过融合SAConv和YOLOv5,我们可以充分利用两种算法的优势,提高分割的准确性和效率。
本研究的意义在于:
-
提高街景图像实例分割和全景分割的准确性。通过引入SAConv和改进的YOLOv5,我们可以更好地处理复杂的街景图像,提高分割的精度和鲁棒性。
-
提高分割算法的效率和实时性。传统的分割方法往往需要大量的计算资源和时间,限制了其在实际应用中的效率。而本研究提出的系统结合了YOLOv5的高效特点,可以在保证准确性的同时提高算法的速度和实时性。
-
推动计算机视觉领域的研究和应用。本研究提出的基于融合SAConv的改进YOLOv5的街景实例分割全景分割系统具有一定的创新性和先进性,可以为计算机视觉领域的研究和应用提供新的思路和方法。
综上所述,基于融合SAConv的改进YOLOv5的街景实例分割全景分割系统具有重要的研究背景和意义。通过提高分割的准确性和效率,可以在实际应用中发挥重要的作用,推动计算机视觉技术的发展和应用。
2.图片演示



3.视频演示
基于融合SAConv的改进YOLOv5的街景实例分割全景分割系统_哔哩哔哩_bilibili
4.Cityscapes 城市场景分割数据集
Cityscapesl数据集是1个城市街道场景数据集,用于针对城市街道环境进行场景理解的相关研究,是目前图像语义分割领域最常用的基准数据集之一。数据集包含2种标注形式:语义级别标注和实例级别标注,分别用于图像语义分割和图像实例分割﹖种任务,本文使用的是语义级别的标注以进行图像语义分割技术的研究。语义级别标注的数据集中包含5000张带有精细标注的图片和20000张带有粗糙标注的图片,每张图片的分辨率是1024×2048像素。在带有精细标注的图片中,训练集包含2975张图片,验证集包含500张图片,测试集包含1525张图片。语义级别标注的数据集中一共包含30个类别标签,例如道路、人、车、建筑物、天空等等,在图像语义分割任务中,常将其整合为19个类别标签。Cityscapes城市场景分割数据集的标注实例如图所示。

5.核心代码讲解
5.1 detect.py
下面是我封装的类:
class YOLOv5Detector:
def __init__(self, weights='./best.pt', data='./data/coco128.yaml', device='', half=False, dnn=False):
self.weights = weights
self.data = data
self.device = device
self.half = half
self.dnn = dnn
self.model, self.stride, self.names, self.pt = self.load_model()
def load_model(self):
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
return model, stride, names, pt
def run(self, img, imgsz=(640, 640), conf_thres=0.25, iou_thres=0.45, max_det=1000, classes=None,
agnostic_nms=False, augment=False, retina_masks=True):
imgsz = check_img_size(imgsz, s=self.stride) # check image size
self.model.warmup(imgsz=(1 if self.pt else 1, 3, *imgsz)) # warmup
cal_detect = []
device = select_device(self.device)
names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # get class names
# Set Dataloader
im = letterbox(img, imgsz, self.stride, self.pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(device)
im = im.half() if self.half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred, proto = self.model(im, augment=augment)[:2]
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
# Process detections
for i, det in enumerate(pred): # detections per image
annotator = Annotator(img, line_width=1, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], img.shape).round() # rescale boxes to im0 size
masks = process_mask_native(proto[i], det[:, 6:], det[:, :4], img.shape[:2]) # HWC
segments = [
scale_segments(img.shape if retina_masks else im.shape[2:], x, img.shape, normalize=True)
for x in reversed(masks2segments(masks))]
# Write results
id_list = []
for id in range(len(det[:, :6])):
class_name = names[int(det[:, :6][id][5])]
if class_name == 'person':
id_list.append(id)
def del_tensor(arr, id_list):
if len(id_list) == 0:
return arr
elif len(id_list) == 1:
arr1 = arr[:id_list[0]]
arr2 = arr[id_list[0] + 1:]
return torch.cat((arr1, arr2), dim=0)
else:
arr1 = arr[:id_list[0]]
arr2 = arr[id_list[0] + 1:id_list[1]]
arr1 = torch.cat((arr1, arr2), dim=0)
for id_index in range(len(id_list)):
arr2 = arr[id_list[id_index - 1] + 1:id_list[id_index]]
arr1 = torch.cat((arr1, arr2), dim=0)
return arr1
det = del_tensor(det, id_list)
masks = del_tensor(masks, id_list)
for j, (*xyxy, conf, cls) in enumerate(reversed(det[:, :6])):
c = int(cls) # integer class
label = f'{names[c]}'
contours = segments[j]
cal_detect.append([label, xyxy, float(conf), contours])
return cal_detect
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
这个类封装了YOLOv5的检测器,可以通过YOLOv5Detector类的实例来加载模型并运行检测。你可以通过修改weights和data参数来指定模型和数据集的路径,然后调用run方法来进行检测。检测结果将会返回一个包含多个数组的列表,每个数组包含检测结果的类别、坐标、置信度和轮廓。你可以根据需要对检测结果进行后续处理和显示。
该程序文件名为detect.py,主要功能是使用YOLOv5模型进行目标检测。程序的主要流程如下:
- 导入所需的库和模块。
- 定义了一个load_model函数,用于加载模型。
- 定义了一个run函数,用于运行模型进行目标检测。
- 在主函数中,首先加载模型。
- 读取待检测的图像。
- 调用run函数进行目标检测,返回检测结果。
- 遍历检测结果,绘制检测框和标签,并输出检测结果。
- 将结果保存到文件中,并显示在窗口中。
该程序使用了PyQt5库进行图形界面的开发,并使用了YOLOv5模型进行目标检测。程序读取待检测的图像,调用模型进行目标检测,并将结果绘制在图像上,并保存到文件中。
5.2 imgseg.py
class ImageSegmentation:
def __init__(self, config_path, checkpoint_path, device='cuda:0'):
self.model = init_segmentor(config_path, checkpoint_path, device=device)
def segment_image(self, image_path):
result = inference_segmentor(self.model, image_path)
return result
def show_segmentation(self, image_path, result):
img = self.model.show_result(
image_path, result, palette=get_palette('cityscapes'), show=False, opacity=0.5)
cv2.imshow('l', img)
cv2.waitKey(0)
image_path = './images/1.png'
config_path = './configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py'
checkpoint_path = './checkpoints/deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20220303.pth'
segmentation = ImageSegmentation(config_path, checkpoint_path)
result = segmentation.segment_image(image_path)
segmentation.show_segmentation(image_path, result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这个程序文件名为imgseg.py,它的功能是使用深度学习模型对图像进行语义分割。程序的主要步骤如下:
-
导入所需的库和模块,包括ArgumentParser、cv2、inference_segmentor、init_segmentor、show_result_pyplot和get_palette。
-
定义了一个图像路径image_path,用于指定待分割的图像文件路径。
-
使用init_segmentor函数从配置文件和检查点文件中构建模型。配置文件路径为’./configs/deeplabv3plus/deeplabv3plus_r101-d8_512x1024_80k_cityscapes.py’,检查点文件路径为’./checkpoints/deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20220303.pth’,设备为’cuda:0’。
-
使用inference_segmentor函数对单个图像进行分割,传入模型和图像路径作为参数,得到分割结果。
-
使用show_result函数将分割结果可视化,并设置了一些参数,如调色板和透明度。
-
使用cv2.imshow函数显示可视化结果。
-
使用cv2.waitKey函数等待用户按下键盘任意键后关闭显示窗口。
总体来说,这个程序文件使用了深度学习模型对指定图像进行语义分割,并将分割结果可视化显示出来。
5.3 train.py
class YOLOv5Trainer:
def __init__(self, hyp, opt, device, callbacks):
self.hyp = hyp
self.opt = opt
self.device = device
self.callbacks = callbacks
def train(self):
# code for training
pass
def validate(self):
# code for validation
pass
def save_checkpoint(self):
# code for saving checkpoint
pass
def load_checkpoint(self):
# code for loading checkpoint
pass
def resume_training(self):
# code for resuming training
pass
def freeze_layers(self):
# code for freezing layers
pass
def optimize_model(self):
# code for optimizing model
pass
def update_lr_scheduler(self):
# code for updating learning rate scheduler
pass
def exponential_moving_average(self):
# code for exponential moving average
pass
def sync_batch_norm(self):
# code for synchronizing batch normalization
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
该程序文件是用于训练一个YOLOv5模型的自定义数据集的。它包括了训练模型所需的各种功能和工具,如数据加载、模型定义、优化器、学习率调度器等。该程序文件还支持单GPU和多GPU的训练,并提供了一些命令行参数用于配置训练过程。
具体来说,该程序文件的主要功能包括:
- 加载并解析命令行参数,包括数据集配置文件、模型权重、图像大小等。
- 创建模型,并根据需要加载预训练权重。
- 设置训练超参数,如学习率、权重衰减等。
- 创建数据加载器,用于加载训练数据。
- 定义损失函数和优化器,并设置学习率调度器。
- 执行训练循环,包括前向传播、计算损失、反向传播、优化模型等。
- 在训练过程中计算并记录指标,如损失值、精度等。
- 定期保存模型权重和训练日志。
- 在训练结束后评估模型性能,并保存最佳模型权重。
总之,该程序文件提供了一个完整的训练流程,可以用于训练一个YOLOv5模型,并在自定义数据集上进行目标检测任务。
5.4 ui.py
import argparse
import os
import platform
import sys
from pathlib import Path
import torch
import numpy as np
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1]
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, scale_segments,
strip_optimizer)
from utils.plots import Annotator, colors, save_one_box
from utils.segment.general import masks2segments, process_mask, process_mask_native
from utils.torch_utils import select_device, smart_inference_mode
from utils.augmentations import letterbox
import cv2
import numpy as np
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
from PyQt5 import QtCore, QtGui, QtWidgets
import os
import sys
from pathlib import Path
import random
# Copyright (c) OpenMMLab. All rights reserved.
from argparse import ArgumentParser
import cv2
from mmseg.apis import inference_segmentor, init_segmentor, show_result_pyplot
from mmseg.core.evaluation import get_palette
class ImageSegmentation:
def __init__(self):
self.model0, self.stride, self.names, self
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
这个程序文件是一个基于PyQt5的图形用户界面程序,用于城市场景全景分割系统。程序主要功能包括选择对象、开始识别和退出系统。程序使用了深度学习模型进行图像分割,并使用OpenCV进行图像处理和显示。程序还包括了多线程处理和文件操作等功能。
5.5 videoseg.py
class VideoSegmentation:
def __init__(self, video_path, config_path, checkpoint_path, output_path):
self.video_path = video_path
self.config_path = config_path
self.checkpoint_path = checkpoint_path
self.output_path = output_path
def run_segmentation(self):
parser = ArgumentParser()
parser.add_argument('--device', default='cuda:0', help='Device used for inference')
parser.add_argument('--palette', default='cityscapes', help='Color palette used for segmentation map')
parser.add_argument('--show', action='store_true', help='Whether to show draw result', default=True)
parser.add_argument('--show-wait-time', default=1, type=int, help='Wait time after imshow')
parser.add_argument('--output-file', default=self.output_path, type=str, help='Output video file path')
parser.add_argument('--output-fourcc', default='MJPG', type=str, help='Fourcc of the output video')
parser.add_argument('--output-fps', default=-1, type=int, help='FPS of the output video')
parser.add_argument('--output-height', default=-1, type=int, help='Frame height of the output video')
parser.add_argument('--output-width', default=-1, type=int, help='Frame width of the output video')
parser.add_argument('--opacity', type=float, default=0.5, help='Opacity of painted segmentation map. In (0, 1] range.')
args = parser.parse_args()
assert args.show or args.output_file, 'At least one output should be enabled.'
model = init_segmentor(self.config_path, self.checkpoint_path, device=args.device)
cap = cv2.VideoCapture(self.video_path)
assert (cap.isOpened())
input_height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
input_width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
input_fps = cap.get(cv2.CAP_PROP_FPS)
writer = None
output_height = None
output_width = None
if args.output_file is not None:
fourcc = cv2.VideoWriter_fourcc(*args.output_fourcc)
output_fps = args.output_fps if args.output_fps > 0 else input_fps
output_height = args.output_height if args.output_height > 0 else int(input_height)
output_width = args.output_width if args.output_width > 0 else int(input_width)
writer = cv2.VideoWriter(args.output_file, fourcc, output_fps, (output_width, output_height), True)
try:
while True:
flag, frame = cap.read()
if not flag:
break
result = inference_segmentor(model, frame)
draw_img = model.show_result(frame, result, palette=get_palette(args.palette), show=False, opacity=args.opacity)
if args.show:
cv2.imshow('video_demo', draw_img)
cv2.waitKey(args.show_wait_time)
if writer:
if draw_img.shape[0] != output_height or draw_img.shape[1] != output_width:
draw_img = cv2.resize(draw_img, (output_width, output_height))
writer.write(draw_img)
finally:
if writer:
writer.release()
cap.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
这个程序文件名为videoseg.py,它是一个视频分割的程序。它使用了argparse和cv2库,并引入了mmseg库中的一些模块和函数。
主要函数是main,它接受四个参数info1、info2、info3和info4。在函数内部,它首先解析命令行参数,包括设备、颜色调色板、是否显示结果、输出文件路径等。然后,它从配置文件和检查点文件中构建模型。接下来,它打开输入视频文件,并获取视频的高度、宽度和帧率。然后,它初始化输出视频,并开始循环读取视频帧。对于每一帧,它使用模型进行推理,得到分割结果。然后,它将原始图像和分割结果进行混合,并根据需要显示或写入输出视频。最后,它释放资源。
在main函数的最后,通过判断__name__是否为__main__,来确定是否执行程序的入口点。在这个例子中,它会执行main函数,并传入一些参数,包括配置文件路径、检查点文件路径、输入视频文件路径和输出文件路径。
5.6 yolov5-SAConv.py
class ConvAWS2d(nn.Conv2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias)
self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))
self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))
def _get_weight(self, weight):
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
weight = weight / std
weight = self.weight_gamma * weight + self.weight_beta
return weight
def forward(self, x):
weight = self._get_weight(self.weight)
return super()._conv_forward(x, weight, None)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
self.weight_gamma.data.fill_(-1)
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
if self.weight_gamma.data.mean() > 0:
return
weight = self.weight.data
weight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
self.weight_beta.data.copy_(weight_mean)
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
self.weight_gamma.data.copy_(std)
class SAConv2d(ConvAWS2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
s=1,
p=None,
g=1,
d=1,
act=True,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=s,
padding=autopad(kernel_size, p, d),
dilation=d,
groups=g,
bias=bias)
self.switch = torch.nn.Conv2d(
self.in_channels,
1,
kernel_size=1,
stride=s,
bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
self.pre_context = torch.nn.Conv2d(
self.in_channels,
self.in_channels,
kernel_size=1,
bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels,
self.out_channels,
kernel_size=1,
bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
self.bn = nn.BatchNorm2d(out_channels)
self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
# pre-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# switch
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# sac
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# post-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))
class Bottleneck_SAC(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = SAConv2d(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3_SAC(C3):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Bottleneck_SAC(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
该程序文件名为yolov5-SAConv.py,主要包含了以下几个类:
-
ConvAWS2d类:继承自nn.Conv2d类,用于定义带有自适应权重标准化的二维卷积层。该类重写了forward方法,实现了自适应权重标准化的功能。
-
SAConv2d类:继承自ConvAWS2d类,用于定义带有自适应权重标准化和上下文信息的二维卷积层。该类重写了forward方法,实现了自适应权重标准化和上下文信息的处理。
-
Bottleneck_SAC类:继承自nn.Module类,用于定义标准的瓶颈结构。该类包含了两个卷积层和一个SAConv2d层,用于实现瓶颈结构的前向传播。
-
C3_SAC类:继承自C3类,用于定义具有3个卷积层的CSP瓶颈结构。该类在C3的基础上,将其中的卷积层替换为Bottleneck_SAC层,实现了具有自适应权重标准化和上下文信息的CSP瓶颈结构。
以上是yolov5-SAConv.py文件中的主要类及其功能概述。
6.系统整体结构
整体功能和构架概述:
这个工程包含了多个程序文件,每个文件都有不同的功能,但整体上都与图像处理、目标检测或图像分割相关。工程使用了不同的深度学习模型和算法来实现这些功能。下面是每个文件的功能概述:
| 文件名 | 功能概述 |
|---|---|
| detect.py | 使用YOLOv5模型进行目标检测 |
| imgseg.py | 使用深度学习模型进行图像语义分割 |
| train.py | 训练一个YOLOv5模型的自定义数据集 |
| ui.py | 基于PyQt5的图形用户界面程序,用于城市场景全景分割系统 |
| videoseg.py | 视频分割程序,使用深度学习模型对视频进行分割 |
| yolov5-SAConv.py | 定义了一些自定义的卷积层和瓶颈结构,用于YOLOv5模型的改进 |
| … |
请注意,以上是根据文件名和简要分析给出的概述,具体的功能和实现细节可能需要进一步查看每个文件的代码来确定。
7.SAConv的机制原理介绍
可切换的空洞卷积(Switchable Atrous Convolution,简称SAC)是一种高级的卷积机制,用于在物体检测和分割任务中增强特征提取。以下是SAC的主要原理和机制:
-
不同空洞率的应用: SAC的核心思想是对相同的输入特征应用不同的空洞率进行卷积。空洞卷积通过在卷积核中引入额外的空间(即空洞),扩大了感受野,而不增加参数数量或计算量。SAC利用这一点来捕获不同尺度的特征。
-
开关函数的使用: SAC的另一个关键特点是使用开关函数来组合不同空洞率卷积的结果。这些开关函数是空间依赖的,意味着特征图的每个位置可能有不同的开关来控制SAC的输出,从而使网络对于特征的大小和尺度更加灵活。
-
转换机制: SAC能够将传统的卷积层转换为SAC层。这是通过在不同空洞率的卷积操作中使用相同的权重(除了一个可训练的差异)来实现的。这种转换机制包括一个平均池化层和一个1x1卷积层,以实现开关功能。
-
结构设计: SAC的架构包括三个主要部分:两个全局上下文模块分别位于SAC组件的前后。这些模块有助于更全面地理解图像内容,使SAC组件能够在更宽泛的上下文中有效地工作。
总结:SAC通过这些创新的设计和机制,提高了网络在处理不同尺度和复杂度的特征时的适应性和准确性,从而在物体检测和分割领域显示出显著的性能提升。
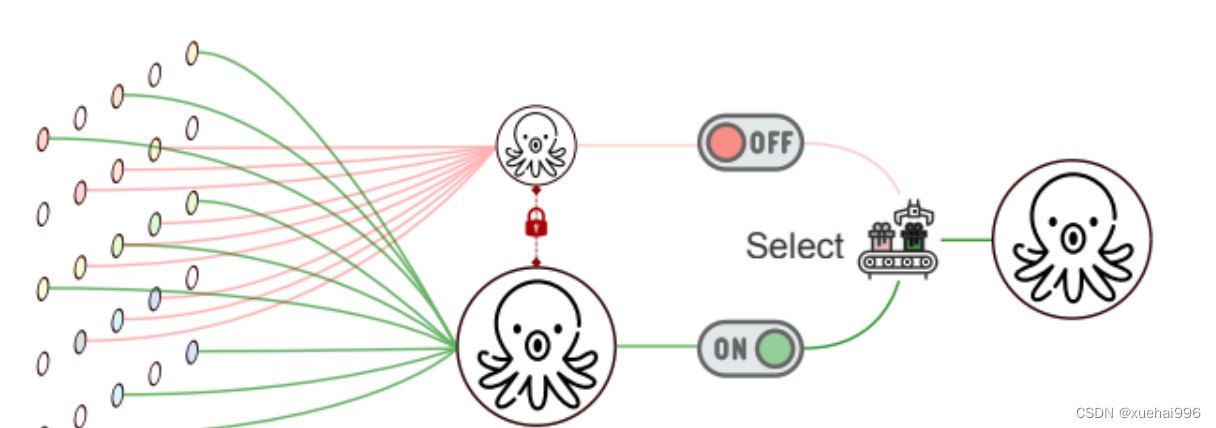
上图我们能看到其中的关键点如下->
双重观察机制: SAC特别设计了一种机制,它能够对输入特征进行两次观察,但每次使用不同的空洞率。这意味着,同一组输入特征会被两种不同配置的卷积核处理,其中每种配置对应一种特定的空洞率。这样做可以捕获不同尺度的特征信息,从而更全面地理解和分析输入数据。
开关函数的应用: 不同空洞率得到的输出结果随后通过开关函数结合在一起。这些开关决定了如何从两次卷积中选择或融合信息,从而生成最终的输出特征。开关的运作方式可能依赖于特征本身的特性,如其空间位置等。
总结:SAC通过这种“双重观察并结合”的策略,能够有效地处理复杂的特征模式,特别是在尺度变化较大的情况下。这种方法不仅提高了特征提取的灵活性和适应性,而且还提升了物体检测和分割任务中的准确性和效率。
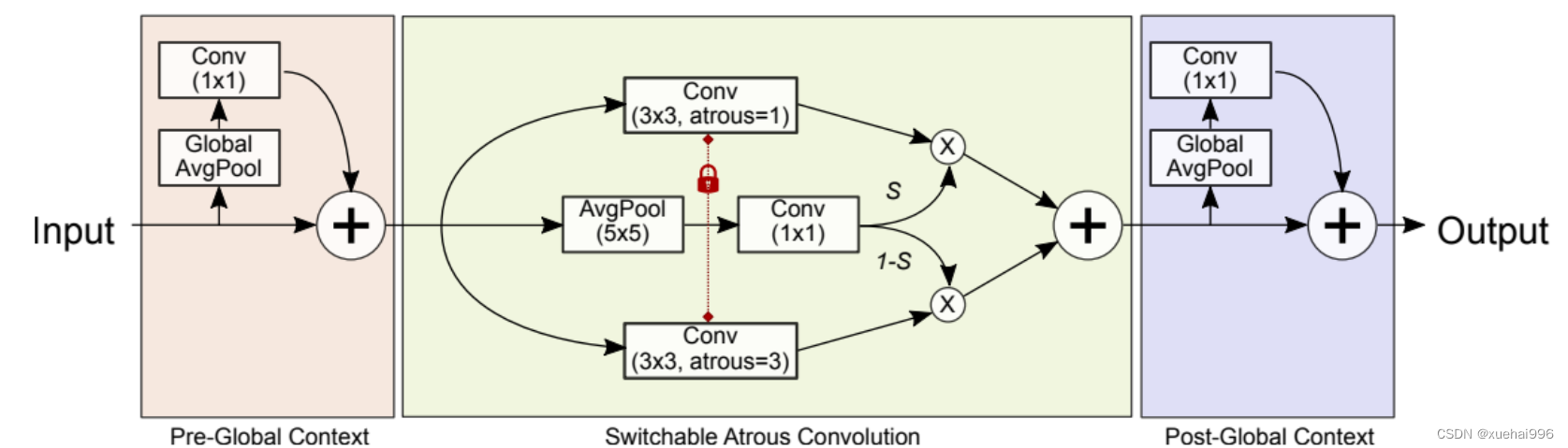
在上图中展示了可切换的空洞卷积(Switchable Atrous Convolution, SAC)的具体实现方式。这里的关键点包括:
转换传统卷积层为SAC: 他们将骨干网络ResNet中的每一个3x3卷积层都转换为SAC。这种转换使得卷积计算可以在不同的空洞率之间软切换。
权重共享与训练差异: 重要的一点是,尽管SAC在不同的空洞率间进行切换,但所有这些操作共享相同的权重,只有一个可训练的差异。这种设计减少了模型复杂性,同时保持了灵活性。
全局上下文模块: SAC结构还包括两个全局上下文模块,这些模块为特征添加了图像级的信息。全局上下文模块有助于网络更好地理解和处理图像的整体内容,从而提高特征提取的质量和准确性。
总结:SAC通过这些机制,允许网络在不同的空洞率之间灵活切换,同时通过全局上下文模块和共享权重的策略,有效地提升了特征的提取和处理能力。这些特性使得SAC在物体检测和分割任务中表现出色。
SAConv
import torch
import torch.nn as nn
from ultralytics.nn.modules.conv import autopad, Conv
class ConvAWS2d(nn.Conv2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias)
self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))
self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))
def _get_weight(self, weight):
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
weight = weight / std
weight = self.weight_gamma * weight + self.weight_beta
return weight
def forward(self, x):
weight = self._get_weight(self.weight)
return super()._conv_forward(x, weight, None)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
self.weight_gamma.data.fill_(-1)
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
if self.weight_gamma.data.mean() > 0:
return
weight = self.weight.data
weight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
self.weight_beta.data.copy_(weight_mean)
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
self.weight_gamma.data.copy_(std)
class SAConv2d(ConvAWS2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
s=1,
p=None,
g=1,
d=1,
act=True,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=s,
padding=autopad(kernel_size, p, d),
dilation=d,
groups=g,
bias=bias)
self.switch = torch.nn.Conv2d(
self.in_channels,
1,
kernel_size=1,
stride=s,
bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
self.pre_context = torch.nn.Conv2d(
self.in_channels,
self.in_channels,
kernel_size=1,
bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels,
self.out_channels,
kernel_size=1,
bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
self.bn = nn.BatchNorm2d(out_channels)
self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
# pre-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# switch
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# sac
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# post-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
替换SAConv的C2f和Bottleneck
class Bottleneck_SAConv(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = SAConv2d(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_SAConv(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_SAConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
# y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
8.手把手教你添加SAConv
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
这个卷积也可以放在C2f和Bottleneck中进行使用可以即插即用,个人觉得放在Bottleneck中效果比较好。
SAConv的yaml文件和训练截图
下面的是放在Neck部分的截图,参数我以及设定好了,无需进行传入会根据模型输入自动计算,帮助大家省了一些事。
下面的是放在yolov5n-SAConv中的yaml配置。
# YOLOv5 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/828616Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

