
热门标签
热门文章
- 1已解决:pycharm上传代码更新到GitHub的时候怎么更新到对应的 Releases 中_github 发布release
- 2【虚拟化】虚拟机xml文件解析_虚拟机xml文件配置
- 3Spring Cloud Zuul-“网关“灰度发布S_灰度发布如何处理新旧流量切换时未处理完的请求
- 4基于k8s实现算法训练系统(架构思路+落地方案)_算法训练管理
- 5postgresql【数据库管理】用户权限、更改密码、数据备份、启动、停止、重启动数据库_postgres本地账户和密码
- 6基于ChatGPT API的PC端软件开发过程遇到的问题的分析_chatgpt api 开发
- 7Scrapy 爬取旅游景点相关数据( 二 )
- 8使用香橙派Kunpeng Pro自建网站服务器_香橙派可以制作为服务器吗
- 9BadDet: Backdoor Attacks on Object Detection——面向目标检测的后门攻击_attack object detection
- 10从0到1搭建文档库——sphinx + git + read the docs_readthedocs搭建
当前位置: article > 正文
深度强化学习TD3策略在QuantConnect开源Lean框架上的实现_td3代码实现
作者:运维做开发 | 2024-07-17 13:31:04
赞
踩
td3代码实现
概要
深度强化学习TD3算法应用于量化交易应该是比较有前景的思路,相比人工交易,从理论上说深度强化学习算法可用自学习、自迭代,参与量化交易存在产生质变回报的可能。基于QuantConnect开源Lean框架搭建本地策略回测平台,构造自有随机数据源,开发深度强化学习TD3算法的Python策略,成功运行。
整体架构流程
三部曲
技术名词解释
略。
技术细节
完整策略由6个py文件构成,每个py文件包含详细注释。
- agent.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from network import Actor, Critic
import base64
from io import BytesIO
import json
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class TD3(object): # 定义DDPG算法
def __init__(self, algo, state_dim, action_dim, max_action, seed):
"""
初始化DQN代理.
参数:
algo: 使用的算法.
state_dim: 状态空间的维度.
action_dim: 动作空间的维度.
max_action: 动作的最大值.
seed: 随机种子.
"""
self.algo = algo # 使用的算法
self.actor = Actor(state_dim, action_dim, max_action,
seed).to(device) # 创建演员网络并移动到指定设备上
self.actor_target = Actor(state_dim, action_dim, max_action, seed).to(
device) # 创建目标演员网络并移动到指定设备上
self.actor_target.load_state_dict(
self.actor.state_dict()) # 初始化目标演员网络的参数为演员网络的参数
self.actor_optimizer = torch.optim.Adam(
self.actor.parameters(), lr=1e-3) # 创建演员网络的优化器
self.critic = Critic(state_dim, action_dim, seed).to(
device) # 创建评论家网络并移动到指定设备上
self.critic_target = Critic(state_dim, action_dim, seed).to(
device) # 创建目标评论家网络并移动到指定设备上
self.critic_target.load_state_dict(
self.critic.state_dict()) # 初始化目标评论家网络的参数为评论家网络的参数
self.critic_optimizer = torch.optim.Adam(
self.critic.parameters(), lr=1e-3) # 创建评论家网络的优化器
self.max_action = max_action # 动作的最大值
# np.random.seed(seed=seed) # 设置随机种子(注释掉的代码,按照要求不进行解释)
def select_action(self, state, noise=0.1):
"""
从代理的策略中选择一个合适的动作
参数:
state (array): 当前环境的状态
noise (float): 向动作中添加的噪声大小
返回值:
action (float): 被限制在动作范围内的动作
"""
# 将状态转换为张量并移动到指定的设备上
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
# 基于当前状态通过actor网络选择动作
action = self.actor(state).cpu().data.numpy().flatten()
# 如果设置了噪声,则向动作中添加噪声
if noise != 0:
action = (action + np.random.normal(0, noise, size=1))
# 限制动作的范围
return action.clip(-self.max_action, self.max_action)
def train(self, replay_buffer, iterations, batch_size=100, discount=0.99, tau=0.005, policy_noise=0.2, noise_clip=0.5, policy_freq=2):
"""
对智能体进行训练,使用DQN算法更新策略网络和价值网络。
参数:
- replay_buffer: 经验回放缓冲区,用于存储环境交互过程中的经验。
- iterations: 训练迭代次数。
- batch_size: 批量大小,每次从经验回放缓冲区中抽取的经验数量。
- discount: 折扣因子,用于计算目标Q值。
- tau: 目标网络参数更新的软更新系数。
- policy_noise: 策略噪声,用于探索。
- noise_clip: 噪声截断值,防止噪声过大。
- policy_freq: 策略更新频率,每隔多少次价值网络更新进行一次策略网络更新。
返回值:
无
"""
for it in range(iterations):
# 从经验回放缓冲区中采样
x, y, u, r, d = replay_buffer.sample(batch_size)
state = torch.FloatTensor(x).to(device)
action = torch.FloatTensor(u).to(device)
next_state = torch.FloatTensor(y).to(device)
done = torch.FloatTensor(1 - d).to(device)
reward = torch.FloatTensor(r).to(device)
# 生成策略噪声
noise = torch.FloatTensor(u).data.normal_(
0, policy_noise).to(device)
noise = noise.clamp(-noise_clip, noise_clip)
# 计算下一个动作和目标Q值
next_action = (self.actor_target(next_state) +
noise).clamp(-self.max_action, self.max_action)
target_Q1, target_Q2 = self.critic_target(next_state, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + (done * discount * target_Q).detach()
# 计算当前Q值并更新价值网络
current_Q1, current_Q2 = self.critic(state, action)
critic_loss = F.mse_loss(
current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 按照策略更新频率更新策略网络
if it % policy_freq == 0:
actor_loss = -self.critic.Q1(state, self.actor(state)).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 进行软更新,更新目标网络参数
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(
tau * param.data + (1 - tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(
tau * param.data + (1 - tau) * target_param.data)
def save(self, filename):
"""
保存模型的状态字典至指定文件。
参数:
- filename: 字符串,保存文件的基础文件名。
返回值:
- 无
"""
# 保存actor模型的状态字典
torch.save(self.actor.state_dict(), '%s_actor.pth' % (filename))
# 保存critic模型的状态字典
torch.save(self.critic.state_dict(), '%s_critic.pth' % (filename))
def load(self, filename):
"""
加载Actor和Critic的模型状态。
参数:
- filename: 字符串,指定加载模型状态的文件名前缀。
返回值:
- 无
"""
# 加载Actor模型的状态
self.actor.load_state_dict(torch.load('%s_actor.pth' % (filename)))
# 加载Critic模型的状态
self.critic.load_state_dict(torch.load('%s_critic.pth' % (filename)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- buffer.py
import numpy as np
import pickle
class ReplayBuffer(object): # 存储数据
def __init__(self, algo, max_size=1000000):
"""
初始化一个对象。
:param algo: 用于算法的实例或对象。
:param max_size: 储存空间的最大大小,默认为1000000。
:return: 无返回值。
"""
self.algo = algo # 存储传入的算法实例或对象
self.storage = [] # 初始化一个空列表用于存储
self.max_size = max_size # 设置存储空间的最大大小
self.ptr = 0 # 初始化指针指向存储列表的起始位置
def add(self, data):
"""
向存储结构中添加新数据。
如果存储结构已达到最大大小,则在循环存储中覆盖最旧的数据;
如果未达到最大大小,则直接添加数据到末尾。
参数:
- data: 需要添加到存储结构的数据。
返回值:
- 无
"""
if len(self.storage) == self.max_size:
# 当存储结构达到最大容量时,覆盖最旧的数据
self.storage[int(self.ptr)] = data
self.ptr = (self.ptr + 1) % self.max_size
else:
# 如果未达到最大容量,直接将数据添加到末尾
self.storage.append(data)
def save(self, name='ReplayBuff'):
"""
保存回放缓冲区到对象存储。
参数:
- name: 保存的文件名,默认为 'ReplayBuff'。
返回值:
- 无
"""
# 保存回放缓冲区到指定的对象存储
self.algo.ObjectStore.Save(name, str(self.storage))
# 记录保存回放缓冲区的时间和大小
self.algo.Log(
"{} - Saving Replay Buffer!: {}".format(self.algo.Time, len(self.storage)))
def load(self, name='ReplayBuff'):
"""
加载回放缓冲区(Replay Buffer)的数据。
参数:
- name: 回放缓冲区的名称,默认为'ReplayBuff'。
返回值:
- 无
"""
# 从算法的对象存储中读取回放缓冲区的数据并保存到self.storage中
self.storage = eval(self.algo.ObjectStore.ReadBytes("key"))
# 记录加载回放缓冲区的时间和数据量
self.algo.Log(
"{} - Loading Replay Buffer!: {}".format(self.algo.Time, len(self.storage)))
def sample(self, batch_size):
"""
从存储器中抽取指定批次大小的样本。
参数:
batch_size -- 抽取样本的大小
返回值:
states -- 抽取样本的状态数组
actions -- 抽取样本的动作数组
next_states -- 抽取样本的下一个状态数组
rewards -- 抽取样本的奖励数组
dones -- 抽取样本的完成标志数组
"""
# 生成随机索引,用于从存储器中选择样本
ind = np.random.randint(0, len(self.storage), size=batch_size)
states, actions, next_states, rewards, dones = [], [], [], [], []
# 遍历随机索引,收集样本数据
for i in ind:
s, a, s_, r, d = self.storage[i]
states.append(np.array(s, copy=False))
actions.append(np.array(a, copy=False))
next_states.append(np.array(s_, copy=False))
rewards.append(np.array(r, copy=False))
dones.append(np.array(d, copy=False))
# 将收集到的样本数据转换为numpy数组,并调整形状以便使用
return np.array(states), np.array(actions), np.array(next_states), np.array(rewards).reshape(-1, 1), np.array(dones).reshape(-1, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- env.py
import numpy as np
import pandas as pd
from collections import deque
import random
from gym import spaces
import math
from scipy.stats import linregress
import random
class TradingEnv(object): # 创建环境类
def __init__(self, obs_len=10, df=None):
"""
初始化函数
:param obs_len: 观察窗口的长度,默认为10
:param df: 输入的数据框,默认为None,如果为None,则使用虚拟数据
"""
self.window = obs_len # 设置观察窗口长度
self.data = df # 存储输入的数据框
# 如果没有提供数据框,则使用虚拟数据
if df is None:
self.data = self.dummy_data()
# 从数据框的列名中提取唯一符号列表
x = list(self.data.columns.get_level_values(0))
x = list(dict.fromkeys(x))
self.SymbolList = x # 存储符号列表
self.CountIter = -1 # 初始化迭代计数器
self.MaxCount = len(x) # 计算符号列表的长度
# 定义动作空间,使用Box空间,范围在-1到+1之间,数据类型为float32
self.action_space = spaces.Box(-1, +1, (1,), dtype=np.float32)
def dummy_data(self):
"""
生成一个包含虚拟股票数据的DataFrame。
该函数不接受任何参数。
返回值:
- df: 一个MultiIndex DataFrame,其中包含三个股票(symbol_1, symbol_2, symbol_3)的收盘价(close)和成交量(volume)数据。
"""
# 初始化收盘价和成交量数据字典
x1 = np.zeros(100) # 创建长度为100的全0数组
close = {'symbol_1': x1, 'symbol_2': x1, 'symbol_3': x1}
vol = {'symbol_1': x1, 'symbol_2': x1, 'symbol_3': x1}
# 将收盘价和成交量数据整合到一个字典中
y = {'close': close, 'volume': vol}
# 将字典中的数据转换为DataFrame
dict_of_df = {k: pd.DataFrame(v) for k, v in y.items()}
# 将DataFrame合并为一个宽格式的DataFrame
df = pd.concat(dict_of_df, axis=1)
# 为DataFrame的列设置多级分类索引
v = pd.Categorical(df.columns.get_level_values(0),
categories=['close', 'volume'],
ordered=True)
v2 = pd.Categorical(df.columns.get_level_values(1),
categories=['symbol_1', 'symbol_2', 'symbol_3'],
ordered=True)
df.columns = pd.MultiIndex.from_arrays([v2, v])
# 按照列的多级索引进行排序
return df.sort_index(axis=1, level=[0, 1])
def reset(self, randomIndex=False):
"""
重置函数,用于初始化或重新设置环境的状态。
参数:
- randomIndex: 布尔值,当设置为True时,会随机初始化环境的状态。
返回值:
- observations: 环境的当前观察值,用于后续的决策制定。
"""
# 如果randomIndex为True,随机设置CountIter的值
if randomIndex:
self.CountIter = random.randint(0, int(self.MaxCount))
# 当CountIter加1后大于等于MaxCount时,将CountIter重置为-1
if self.CountIter + 1 >= self.MaxCount:
self.CountIter = -1
self.CountIter += 1 # 更新CountIter的值
# 根据CountIter获取对应的symbol
self.sym = self.SymbolList[self.CountIter]
# 根据symbol从data中获取相应的数据
df = self.data[self.sym]
# 提取close、volume和returns数据
self.close = df['close'].values
self.volume = df['volume'].values
self.returns = df['close'].pct_change().values
# 初始化时间序列索引
self.ts_index = self.window + 1
# 调用on_data函数,获取c_window和v_window
c_window, v_window = self.on_data()
# 基于c_window和v_window,生成下一个观察值
observations = self.next_observation(
close_window=c_window, volume_window=v_window)
# 设置observation_space的形状和类型
self.observation_space = spaces.Box(-np.inf, np.inf,
shape=(len(observations),), dtype=np.float32)
# 初始化策略回报列表
self.strat_returns = []
return observations
def std(self, x):
"""
计算标准化值。
该方法接收一个数组x,计算其标准化值,并返回数组最后一个元素的标准化值。
标准化值是通过将原始值减去该变量的平均值,然后除以该变量的标准差来计算的。
参数:
- x: 输入的数组,其中包含了需要进行标准化处理的数值。
返回值:
- 返回数组x最后一个元素的标准化值。
"""
y = (x - x.mean()) / x.std() # 计算标准化值
return y[-1] # 返回最后一个标准化值
def exponential_regression(self, data):
"""
计算指数回归的拟合优度。
参数:
- data: 用于指数回归的数据集,预期为一个数组或列表。
返回值:
- 返回一个表示拟合优度的数值,该数值越大表示拟合效果越好。
"""
# 对数据取对数
log_c = np.log(data)
# 创建一个索引数组,长度与数据集相同
x = np.arange(len(log_c))
# 计算对数数据与索引之间的线性回归斜率和相关系数
slope, _, rvalue, _, _ = linregress(x, log_c)
# 计算并返回指数回归的拟合优度
return (1 + slope) * (rvalue ** 2)
def regression(self, data):
"""
计算回归分析的调整R平方值。
参数:
data: 一维数组,包含需要进行回归分析的数据点。
返回值:
返回调整后的R平方值,该值表示拟合优度。
"""
# 生成等间距的x值,范围与data一致
x = np.arange(len(data))
# 计算线性回归的斜率和决定系数rvalue
slope, _, rvalue, _, _ = linregress(x, data)
# 计算并返回调整后的R平方值
return (1 + slope) * (rvalue ** 2)
def next_observation(self, close_window, volume_window):
"""
生成下一个观察值,结合了价格和成交量的统计特征。
:param close_window: 一个包含收盘价的窗口,用于计算线性回归和标准差。
:param volume_window: 一个包含成交量的窗口,用于计算标准差。
:return: 返回一个包含三个特征的numpy数组:收盘价的标准差、线性回归值、成交量的标准差。
"""
# 计算收盘价窗口的线性回归
lin_reg = self.regression(close_window)
# 计算收盘价窗口的标准差
col = self.std(close_window)
# 计算成交量窗口的标准差
vol = self.std(volume_window)
# 将三个特征 concatenate 在一起形成观察值
obs = np.concatenate(([col], [lin_reg], [vol]), axis=0)
# 将观察值中的 NaN 值替换为 0
where_are_NaNs = np.isnan(obs)
obs[where_are_NaNs] = 0
return obs
def on_data(self):
"""
处理数据的函数。
该函数不接受任何参数。
返回:
close_window : list
返回一个包含最近 `window` 个收盘价的列表。
volume_window : list
返回一个包含最近 `window` 个成交量的列表。
"""
step = self.ts_index # 获取当前时间步
# 获取最近window个收盘价和成交量
close_window = self.close[step-self.window:step]
volume_window = self.volume[step-self.window:step]
return close_window, volume_window
def get_reward(self, trade=0):
"""
计算并获取当前时间步的奖励。
参数:
- trade: 交易标志,默认为0,表示没有进行交易。如果为非零值,则表示进行了交易。
返回值:
- reward: 计算得到的奖励值。如果计算结果不是有限数,则返回0。
"""
step = self.ts_index # 当前时间步
# 计算奖励,根据当前时间步的回报和是否进行交易来确定
reward = self.returns[step] * trade
self.strat_returns.append(reward) # 将计算得到的奖励添加到策略回报列表中
# 如果计算出的奖励是有限数,则返回该奖励;否则,返回0
return reward if np.isfinite(reward) else 0
def normalize(self, x):
"""
对输入的值进行标准化处理。
参数:
- self: 方法的对象引用。
- x: 需要进行标准化处理的值。
返回值:
- 标准化处理后的值,保留3位小数。
"""
return np.round((1/0.95*x)-0.05264, 3) # 计算标准化值,并四舍五入至小数点后三位
def step(self, action):
"""
执行一步交易操作。
参数:
action - 一个数组,表示执行的动作,其中第一个元素被使用来决定交易的大小。
返回值:
observations - 表示环境状态的观察值。
reward - 该步操作得到的奖励。
done - 表示这一步是否完成了整个交易过程。
self.ts_index - 当前时间序列的索引。
"""
done = False # 初始化交易未完成标志
action = float(action[0]) # 提取并转换动作的第一个元素为浮点数
# 根据动作的大小决定交易的大小,小于-0.05做空,大于等于0.05做多,否则不做交易
if action >= 0.05:
size = np.clip(self.normalize(abs(action)), 0, 1)
elif action <= -0.05:
size = -(np.clip(self.normalize(abs(action)), 0, 1))
else:
size = 0 # 如果动作在指定阈值内,则不做交易
# 检查是否到达交易序列的末尾
if self.ts_index + 2 >= len(self.close):
done = True # 标记交易完成
reward = self.get_reward(trade=size) # 计算并获取此步交易的奖励
c_window, v_window = self.on_data() # 获取当前的收盘价和成交量窗口
observations = self.next_observation(
close_window=c_window, volume_window=v_window) # 根据当前窗口生成下一个观察值
return observations, reward, done, self.ts_index # 返回观察值,奖励,完成标志和当前时间序列索引
# 如果未到达交易序列末尾,则继续进行下一步交易
reward = self.get_reward(trade=size) # 计算并获取此步交易的奖励
self.ts_index += 1 # 更新时间序列索引
c_window, v_window = self.on_data() # 获取更新后的收盘价和成交量窗口
observations = self.next_observation(
close_window=c_window, volume_window=v_window) # 根据更新后的窗口生成下一个观察值
return observations, reward, done, self.ts_index # 返回更新后的观察值,奖励,完成标志和当前时间序列索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- explore.py
from collections import deque
import pandas as pd
import numpy as np
import gym
import sys
from buffer import ReplayBuffer
from agent import TD3
class Runner: # 运行器
def __init__(self, algo, n_episodes=100, batch_size=32, gamma=0.99, tau=0.005, noise=0.2, noise_clip=0.5, explore_noise=0.1,
policy_frequency=2, sizes=None):
"""
初始化函数
:param algo: 使用的算法
:param n_episodes: 训练的回合数,默认为100
:param batch_size: 批量大小,默认为32
:param gamma: 折扣因子,默认为0.99
:param tau: 目标网络的更新参数,默认为0.005
:param noise: 探索噪声,默认为0.2
:param noise_clip: 噪声夹断值,默认为0.5
:param explore_noise: 探索时的噪声大小,默认为0.1
:param policy_frequency: 政策更新频率,默认为2
:param sizes: 状态维度、动作维度、最大动作值和随机种子的列表
"""
self.algo = algo # 算法
self.n_episodes = n_episodes # 训练回合数
self.batch_size = batch_size # 批量大小
self.gamma = gamma # 折扣因子
self.tau = tau # 目标网络更新参数
self.noise = noise # 探索噪声
self.noise_clip = noise_clip # 噪声夹断值
self.explore_noise = explore_noise # 探索时的噪声大小
self.policy_frequency = policy_frequency # 政策更新频率
self.replay_buffer = ReplayBuffer(algo) # 初始化回放缓冲区
self.agent = TD3(
self, state_dim=sizes[0], action_dim=sizes[1], max_action=sizes[2], seed=sizes[3]) # 初始化TD3代理
def evaluate_policy(self, TestEnv, eval_episodes=1):
"""
评估策略的性能。
参数:
- TestEnv: 测试环境,用于执行策略评估。
- eval_episodes: 评估的回合数,默认为1。
返回值:
- avg_reward: 在评估回合中的平均奖励。
"""
avg_reward = 0.
for i in range(eval_episodes):
obs = TestEnv.reset() # 重置环境,开始新的回合
done = False
while not done:
action = self.agent.select_action(
np.array(obs), noise=0) # 选择一个动作,无噪声
obs, reward, done, _ = TestEnv.step(
action) # 执行动作,获取新的观测、奖励和完成状态
avg_reward += reward # 累加奖励
if action <= -0.05: # 特定条件下的日志记录
self.algo.Log("Action {}.".format(action))
# 计算平均奖励
avg_reward /= eval_episodes
return avg_reward
def observe(self, TrainEnv, observation_steps):
"""
观察并填充回放缓冲区。
通过在给定的环境中执行随机动作,并将观察结果存储到回放缓冲区中,来填充缓冲区。
这个方法主要用于训练前让智能体探索环境,以便后续的强化学习。
参数:
TrainEnv: 训练环境,提供了一个接口来执行动作和获取环境状态。
observation_steps: 观察步数,决定了函数执行和填充缓冲区的次数。
返回值:
无
"""
time_steps = 0
obs = TrainEnv.reset() # 重置环境,并获取初始观察结果
done = False
while time_steps < observation_steps:
action = TrainEnv.action_space.sample() # 从动作空间中随机采样一个动作
new_obs, reward, done, _ = TrainEnv.step(
action) # 执行动作,并获取新的观察结果、奖励等
self.replay_buffer.add(
(obs, new_obs, action, reward, done)) # 将观察结果等信息添加到回放缓冲区
obs = new_obs # 更新当前观察结果为新的观察结果
time_steps += 1 # 增加时间步数
if done:
obs = TrainEnv.reset() # 如果当前环境已完成,则重置环境
done = False # 重置完成标志
# self.algo.Log("Populating Buffer {}/{}.".format(time_steps, observation_steps))
# sys.stdout.flush()
def train(self, TrainEnv, TestEnv):
"""
对智能体进行训练。
参数:
- TrainEnv: 训练环境,用于智能体的训练过程。
- TestEnv: 测试环境,用于评估智能体的性能。
无返回值。
"""
# 初始化分数列表及相关变量
scores = []
scores_avg = []
scores_window = deque(maxlen=25)
eval_reward_best = -1000 # 初始化最佳评估奖励
self.algo.Debug("{} | Training..".format(self.algo.Time)) # 记录开始训练的日志
# 初始评估
eval_reward = self.evaluate_policy(TestEnv, int(TestEnv.MaxCount))
# 如果当前评估分数更好,则保存为最佳模型
if eval_reward > eval_reward_best:
eval_reward_best = eval_reward
self.algo.Debug("Last Model Tested |"+str(eval_reward_best))
self.agent.save("best_avg")
# 开始训练循环
for i_episode in range(1, self.n_episodes+1):
# 重置训练环境,并初始化分数、完成标志和步数
obs = TrainEnv.reset()
score = 0
done = False
episode_timesteps = 0
# 在当前环境中执行动作,直到完成该回合
while not done:
# 选择动作,并执行于环境中
action = self.agent.select_action(
np.array(obs), noise=self.explore_noise)
new_obs, reward, done, _ = TrainEnv.step(action)
self.replay_buffer.add((obs, new_obs, action, reward, done))
obs = new_obs
score += reward
episode_timesteps += 1
# 更新分数相关统计
scores_window.append(score)
scores.append(score)
scores_avg.append(np.mean(scores_window))
# 基于回放缓冲区进行训练
self.agent.train(self.replay_buffer, episode_timesteps, self.batch_size,
self.gamma, self.tau, self.noise, self.noise_clip, self.policy_frequency)
# 每隔一定回合数进行一次评估,并记录最佳模型
if i_episode % 1 == 0:
eval_reward = self.evaluate_policy(
TestEnv, int(TestEnv.MaxCount))
# 如果当前评估分数为最佳,则保存模型
if eval_reward > eval_reward_best:
eval_reward_best = eval_reward
self.algo.Debug(
str(i_episode)+"| Best Model! |"+str(round(eval_reward_best, 3)))
self.agent.save("best_avg")
# self.algo.Log("{} {} {} {} {}".format(episode_timesteps, i_episode, score, eval_reward))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- main.py
from datetime import timedelta
from QuantConnect.Data.Custom.Tiingo import *
from AlgorithmImports import *
from env import TradingEnv
from explore import Runner
from agent import TD3
import pandas as pd
import numpy as np
import math
class TwinDelayedDDPG(QCAlgorithm): # 定义一个名为TwinDelayedDDPG的类
def Initialize(self):
"""
初始化函数,设置交易环境的基本参数,包括特征窗口大小、回看周期、测试周期等,并配置交易品种和基准指数。
该函数还负责创建和配置交易环境、设置模型参数,并初始化交易代理。
参数:
self: 表示实例自身的引用。
返回值:
无
"""
# 初始化一些基本参数
self.FeatureWindow = 10 # 特征窗口大小
self.LookBack = 100 * 2 # 回看周期
self.Test = 20 * 2 # 测试周期
self.LastDataNum = -1 # 最后一个数据的编号
live = False # 是否为实盘交易
# 设置交易开始和结束日期
self.SetStartDate(2019, 1, 1)
self.SetEndDate(2019, 1, 31)
# 初始化股票列表和安全列表
self.symbolDataBySymbol = {} # 通过符号存储数据的字典
self.SymbolList = ['STK000000',
'STK000001',
'STK000002'] # 股票符号列表
self.SecurityList = [] # 安全列表
# 为每个股票符号添加股票并初始化SymbolData
for symbol in self.SymbolList:
security = self.AddEquity(symbol, Resolution.Daily) # 添加股票
self.SecurityList.append(security.Symbol) # 添加符号到安全列表
self.symbolDataBySymbol[security.Symbol] = SymbolData(
self, security.Symbol, self.FeatureWindow, Resolution.Daily) # 初始化SymbolData
self.SetBenchmark("STK000000") # 设置基准指数
# 初始化交易环境
env = TradingEnv(self.FeatureWindow)
env.reset()
self.environment = env # 交易环境
# 初始化一些运行标志和模型训练标志
self.observationRun = False
self.modelIsTraining = False
# 根据环境设置模型的参数
state_size = env.observation_space.shape[0] # 状态空间大小
action_dim = env.action_space.shape[0] # 动作空间维度
max_action = float(env.action_space.high[0]) # 最大动作值
seed = 0 # 随机种子
sizes = (state_size, action_dim, max_action, seed) # 模型参数
# 初始化运行器和AI交易代理
self.runnerObj = Runner(self, n_episodes=170, batch_size=5, gamma=0.99, tau=0.005, noise=0.2,
noise_clip=0.5, explore_noise=0.1, policy_frequency=2, sizes=sizes)
self.AI_TradeAgent = TD3(
self, state_dim=state_size, action_dim=action_dim, max_action=max_action, seed=seed)
# 如果是实盘交易,则加载回放缓冲区
if live:
self.runnerObj.replay_buffer.load(name='ReplayBuff')
# 开始训练
self.Train(self.TrainingMethod)
# 定义每周日6点开始的训练计划
self.Train(self.DateRules.Every(DayOfWeek.Sunday),
self.TimeRules.At(6, 0), self.TrainingMethod)
def TrainTimeCheck(self):
"""
检查是否需要训练的时间。
该方法不接受参数。
返回值:
- True:如果上一次记录的数据月份与当前月份不同,且当前月份为偶数月,或上一次记录的月份数据未设置。
- False:如果上一次记录的数据月份与当前月份相同,且当前月份不是偶数月。
"""
today = self.Time # 获取当前时间
weekNum = today.strftime("%V") # 获取当前时间的星期数
dayNum = today.strftime("%e") # 获取当前时间的日数
monthNum = today.strftime("%m") # 获取当前时间的月份
# 判断是否需要更新训练,即判断当前月份与上一次记录的月份是否不同,且当前月份为偶数,或上一次月份未记录
if self.LastDataNum == -1:
self.LastDataNum = monthNum
return True
return False
def HistoricalData(self, lookBack=100):
"""
获取历史数据的函数,用于提取指定时间段内证券列表的每日收盘价和成交量数据。
参数:
lookBack: int, 默认值为100,表示要查看的过去的数据天数。
返回值:
pd.DataFrame, 包含证券列表中每个证券的收盘价和成交量数据的DataFrame,其中行表示时间,列表示证券和数据类型(收盘价或成交量)。
"""
# 从历史数据中获取指定时间段内的每日数据
historyData = self.History(
self.SecurityList, lookBack, Resolution.Daily)
historyData.dropna(inplace=True) # 删除缺失值
pricesX = {} # 存储证券收盘价的字典
volumeX = {} # 存储证券成交量的字典
# 遍历证券列表,提取每个证券的收盘价和成交量
for symbol in self.SecurityList:
if not historyData.empty:
pricesX[symbol.Value] = list(
historyData.loc[str(symbol.Value)]['close'])[:-1]
volumeX[symbol.Value] = list(
historyData.loc[str(symbol.Value)]['volume'])[:-1]
maxValue = len(pricesX[symbol.Value]) # 计算最长数据长度
dictOfDict = {'close': pricesX, 'volume': volumeX} # 将收盘价和成交量数据封装成字典
# 将字典中的数据转换为DataFrame
dictOfDf = {k: pd.DataFrame(v) for k, v in dictOfDict.items()}
df = pd.concat(dictOfDf, axis=1) # 按列合并DataFrame
# 重新设置DataFrame的列标签,以实现多级索引
temp1 = df.columns.get_level_values(0)
v1 = pd.Categorical(df.columns.get_level_values(0),
categories=['close', 'volume'],
ordered=True)
temp2 = df.columns.get_level_values(1)
v2 = pd.Categorical(df.columns.get_level_values(1),
categories=self.SymbolList,
ordered=True)
df.columns = pd.MultiIndex.from_arrays([v2, v1]) # 设置多级列索引
return df.sort_index(axis=1, level=[0, 1]) # 按索引的级别排序DataFrame的列,并返回
def TrainingMethod(self):
"""
训练方法:负责执行训练流程。
无参数和返回值。
"""
# 检查是否到达训练时间
train = self.TrainTimeCheck()
# 如果未到训练时间,则直接返回
if not train:
return
# 设置查看历史数据的长度
x = self.LookBack
# 获取历史数据
df = self.HistoricalData(x)
# 创建训练环境和测试环境
trainEnv = TradingEnv(obs_len=self.FeatureWindow,
df=df.iloc[:-self.Test])
testEnv = TradingEnv(obs_len=self.FeatureWindow,
df=df.iloc[-self.Test:])
# 如果还未执行过观察步骤,则对训练环境进行一次观察
if not self.observationRun:
self.runnerObj.observe(trainEnv, 1000)
self.observationRun = True
# 标记模型为训练中
self.modelIsTraining = True
# 进行模型训练
self.runnerObj.train(testEnv, testEnv)
# 更新模型训练状态为完成
self.modelIsTraining = False
def OnOrderEvent(self, orderEvent):
"""
处理订单事件的回调函数。
参数:
- self: 对象自身的引用。
- orderEvent: 订单事件对象,包含订单的详细信息。
返回值:
- 无。
"""
self.Debug("{} {}".format(self.Time, orderEvent.ToString()))
# 在调试模式下输出当前时间及订单事件信息
def OnEndOfAlgorithm(self):
"""
在算法结束时执行的操作。
无参数。
无返回值。
"""
# 保存重播缓冲区数据
self.runnerObj.replay_buffer.save(name='ReplayBuff')
# 记录当前总 portfolio 值
self.Log("{} - TotalPortfolioValue: {}".format(self.Time,
self.Portfolio.TotalPortfolioValue))
# 记录当前的现金账本
self.Log("{} - CashBook: {}".format(self.Time, self.Portfolio.CashBook))
class SymbolData: # 创建一个类,用于存储交易品种的数据
def __init__(self, algo, symbol, window, resolution):
"""
初始化函数
:param algo: 算法实例,用于交易和数据订阅管理
:param symbol: 交易品种的符号
:param window: 窗口大小,用于分析数据
:param resolution: 数据分辨率,如分钟、小时或日
"""
# 初始化类属性
self.algo = algo
self.symbol = symbol
self.window = window
self.resolution = resolution
# 设置交易日志合并器,以天为单位
self.timeConsolidator = TradeBarConsolidator(timedelta(days=1))
self.timeConsolidator.DataConsolidated += self.TimeConsolidator # 当数据合并时触发的事件处理函数
self.algo.SubscriptionManager.AddConsolidator(
symbol, self.timeConsolidator) # 向算法订阅管理器添加合并器
self.weight_temp = 0 # 临时权重变量
# 初始化历史数据列表
self.history_close = [] # 收盘价历史数据
self.history_volume = [] # 成交量历史数据
# 计算最大多头仓位比例,基于符号列表长度
self.max_pos = 1 / len(algo.SymbolList)
self.max_short_pos = 0.0 # 最大空头仓位比例初始化为0
def update(self, close, volume, symbol):
"""
更新价格和成交量历史数据。
参数:
close: float - 最新的收盘价。
volume: int - 最新的成交量。
symbol: str - 股票代码。
返回值:
无
"""
# 如果历史收盘价列表为空,则从algo中获取20天的历史数据
if len(self.history_close) == 0:
hist_df = self.algo.History(
[self.symbol], timedelta(days=20), self.resolution)
# 如果数据中没有'close'字段,则返回
if 'close' not in hist_df.columns:
return
# 数据处理:去除NaN值,重置索引,并设置'time'为索引
hist_df.dropna(inplace=True)
hist_df.reset_index(level=[0, 1], inplace=True)
hist_df.set_index('time', inplace=True)
hist_df.dropna(inplace=True)
# 保存最后window长度的历史收盘价和成交量
self.history_close = hist_df.close.values[-self.window:]
self.history_volume = hist_df.volume.values[-self.window:]
# 如果历史收盘价列表长度小于window,追加新的收盘价和成交量
if len(self.history_close) < self.window:
self.history_close = np.append(self.history_close, close)
self.history_volume = np.append(self.history_volume, volume)
# 如果历史收盘价列表长度大于等于window,移除第一个元素并追加新的收盘价和成交量
else:
self.history_close = np.append(self.history_close, close)[1:]
self.history_volume = np.append(self.history_volume, volume)[1:]
def TimeConsolidator(self, sender, bar):
'''
此函数用于整合时间周期内的交易数据,根据AI策略进行交易决策。
参数:
- sender: 发送数据的源对象。
- bar: 包含交易品种的收盘价、成交量等信息的数据对象。
返回值:
- 无
'''
# 如果模型正在训练,则不执行任何交易操作
if self.algo.modelIsTraining:
self.algo.Debug("Retun, model still training")
return
# 加载最优平均策略
self.algo.AI_TradeAgent.load("best_avg")
# 提取交易品种、收盘价、成交量信息
symbol = bar.Symbol
price = bar.Close
vol = bar.Volume
# 更新历史价格和成交量数据
self.update(price, vol, symbol)
# 如果已经投资于该证券
if self.algo.Securities[symbol].Invested:
# 计算当前持仓权重
currentweight = (
self.algo.Portfolio[symbol].Quantity * price) / self.algo.Portfolio.TotalPortfolioValue
else:
currentweight = 0.0
# 初始化交易权重
weight = currentweight
# 获取新的观测值
new_obs = self.algo.environment.next_observation(close_window=self.history_close,
volume_window=self.history_volume)
# 根据观测值选择行动
action = self.algo.AI_TradeAgent.select_action(
np.array(new_obs), noise=0)
# 如果行动指示买入
if action > 0.05:
# 调整权重以反映买入决策
weight += np.clip(self.algo.environment.normalize(abs(float(action))), 0, 1) * 0.3
weight = np.clip(round(weight, 4),
self.max_short_pos, self.max_pos)
# 如果新的权重大于之前的最大权重,则更新持仓
if weight > self.weight_temp:
self.algo.SetHoldings(symbol, weight, False)
self.weight_temp = weight
# 如果行动指示卖出
elif action < -0.05:
# 调整权重以反映卖出决策
weight += - \
(np.clip(self.algo.environment.normalize(
abs(float(action))), 0, 1)) * 0.3
weight = np.clip(round(weight, 4),
self.max_short_pos, self.max_pos)
# 如果新的权重小于之前的最大权重,则更新持仓
if weight < self.weight_temp:
self.algo.SetHoldings(symbol, weight, False)
self.weight_temp = weight
else:
pass
else:
# 如果行动指示保持现状,则不做任何操作
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- network.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
def hidden_init(layer):
"""
初始化隐藏层参数的函数。
参数:
- layer: 包含权重的层,用于计算初始值的范围。
返回:
- 一个元组,包含权重初始化的下界和上界。
"""
# 计算输入神经元的数量(fan_in)
fan_in = layer.weight.data.size()[0]
# 根据输入神经元数量计算权重初始化的界限
lim = 1. / np.sqrt(fan_in)
return (-lim, lim)
class Actor(nn.Module):
"""
Actor网络,用于生成动作。
"""
def __init__(self, state_dim, action_dim, max_action, seed):
"""
初始化Actor网络。
参数:
state_dim (int): 状态空间的维度。
action_dim (int): 动作空间的维度。
max_action (float): 动作的最大值,用于归一化动作。
seed (int): 随机种子,用于初始化模型参数,保证实验可复现性。
"""
# 使用父类的构造方法初始化
super(Actor, self).__init__()
# 设置随机种子
self.seed = torch.manual_seed(seed)
# 定义网络的三层线性结构
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
# 保存最大动作值,用于动作的归一化
self.max_action = max_action
def forward(self, x):
"""
实现前向传播过程
参数:
- x输入数据,待处理的特征向量或张量
返回值:
- x处理后的数据,经过多层神经网络结构变换后的结果
"""
# 通过第一层神经网络,并应用ReLU激活函数
x = F.relu(self.l1(x))
# 通过第二层神经网络,并应用ReLU激活函数
x = F.relu(self.l2(x))
# 通过第三层神经网络,应用tanh激活函数,并乘以最大动作值,用于输出规范化动作
x = self.max_action * torch.tanh(self.l3(x))
return x
class Critic(nn.Module):
"""
Critic网络类,用于估计状态-动作值函数Q(s, a)。
参数:
- state_dim (int): 状态空间的维度。
- action_dim (int): 动作空间的维度。
- seed (int): 随机种子,用于初始化模型参数,以确保可复现性。
"""
def __init__(self, state_dim, action_dim, seed):
super(Critic, self).__init__()
# 使用给定的种子设置随机数生成器
self.seed = torch.manual_seed(seed)
# 定义Q1网络的架构
self.l1 = nn.Linear(state_dim + action_dim, 400) # 第一层线性层
self.l2 = nn.Linear(400, 300) # 第二层线性层
self.l3 = nn.Linear(300, 1) # 输出层,估计Q1值
# 定义Q2网络的架构,与Q1相似
self.l4 = nn.Linear(state_dim + action_dim, 400) # 第一层线性层
self.l5 = nn.Linear(400, 300) # 第二层线性层
self.l6 = nn.Linear(300, 1) # 输出层,估计Q2值
def forward(self, x, u):
"""
前向传播函数:将输入的特征向量x和控制向量u拼接后,通过一系列的卷积或全连接层处理,得到两路输出。
参数:
- x: 输入的特征向量,shape为(batch_size, feature_dim_x)
- u: 控制向量,shape为(batch_size, control_dim)
返回值:
- x1, x2: 两路输出的特征向量,分别经过不同的层处理得到,shape同输入x但维度可能发生变化
"""
# 将特征向量x和控制向量u在第1维(特征维度)上拼接
xu = torch.cat([x, u], 1)
# 第一路处理:通过两个ReLU激活函数和一个线性层
x1 = F.relu(self.l1(xu)) # 使用ReLU激活函数处理拼接后的输入
x1 = F.relu(self.l2(x1)) # 再次使用ReLU激活函数处理上一層的输出
x1 = self.l3(x1) # 经过一个线性层(全连接层或卷积层)处理
# 第二路处理:与第一路类似,但使用不同的层
x2 = F.relu(self.l4(xu)) # 第一个ReLU激活函数处理
x2 = F.relu(self.l5(x2)) # 第二个ReLU激活函数处理
x2 = self.l6(x2) # 经过最后一个线性层处理
return x1, x2
def Q1(self, x, u):
"""
函数Q1:将输入的x和u拼接后通过一系列神经网络层进行处理。
参数:
- x: 输入特征向量x,torch.Tensor类型。
- u: 控制输入u,torch.Tensor类型,与x将在维度1上拼接。
返回:
- x1: 经过处理后的输出特征向量x1,torch.Tensor类型。
"""
# 将输入x和u在第1维上拼接
xu = torch.cat([x, u], 1)
# 通过第一个ReLU激活函数和层l1处理输入
x1 = F.relu(self.l1(xu))
# 通过第二个ReLU激活函数和层l2继续处理
x1 = F.relu(self.l2(x1))
# 通过层l3得到最终输出
x1 = self.l3(x1)
return x1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 效果
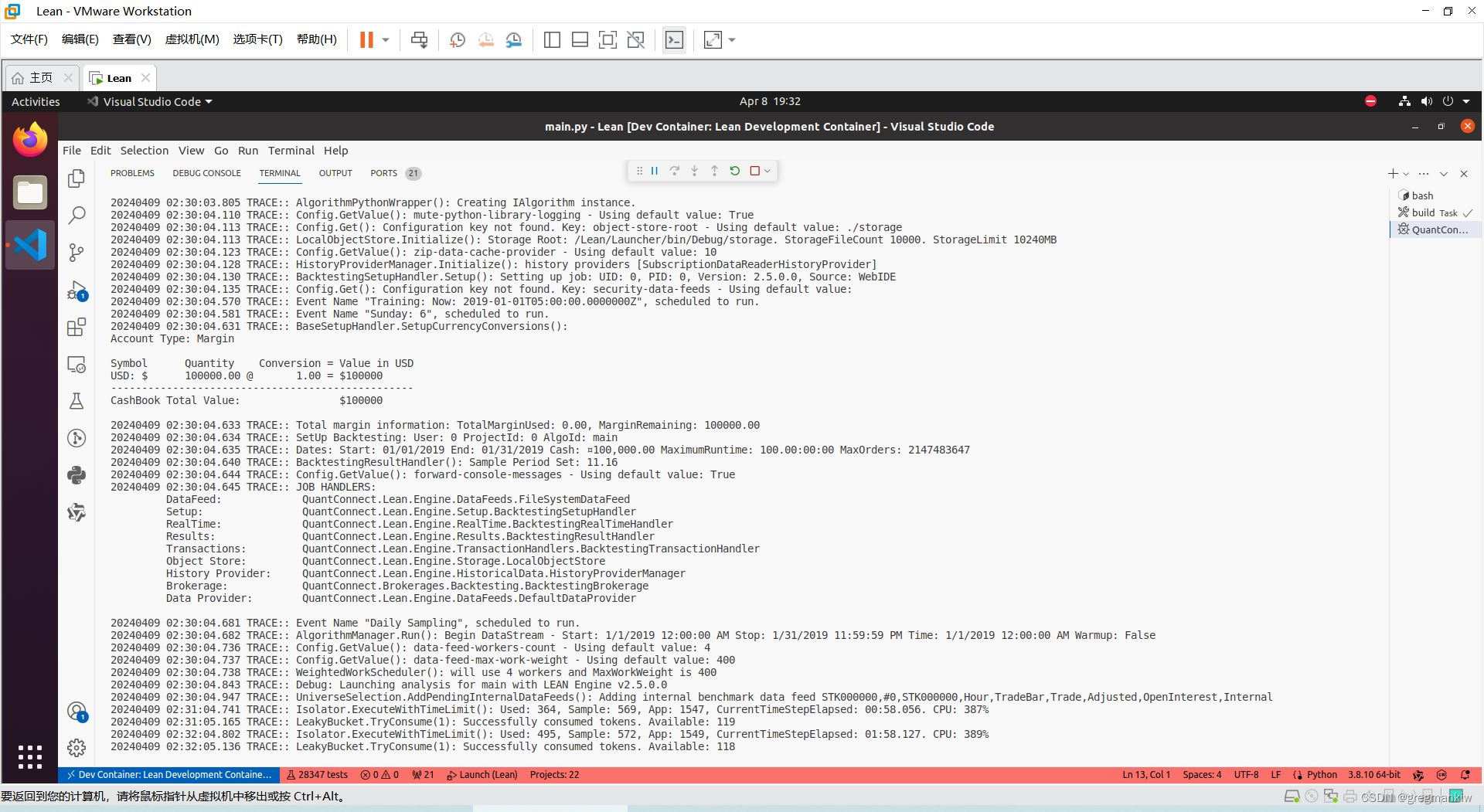
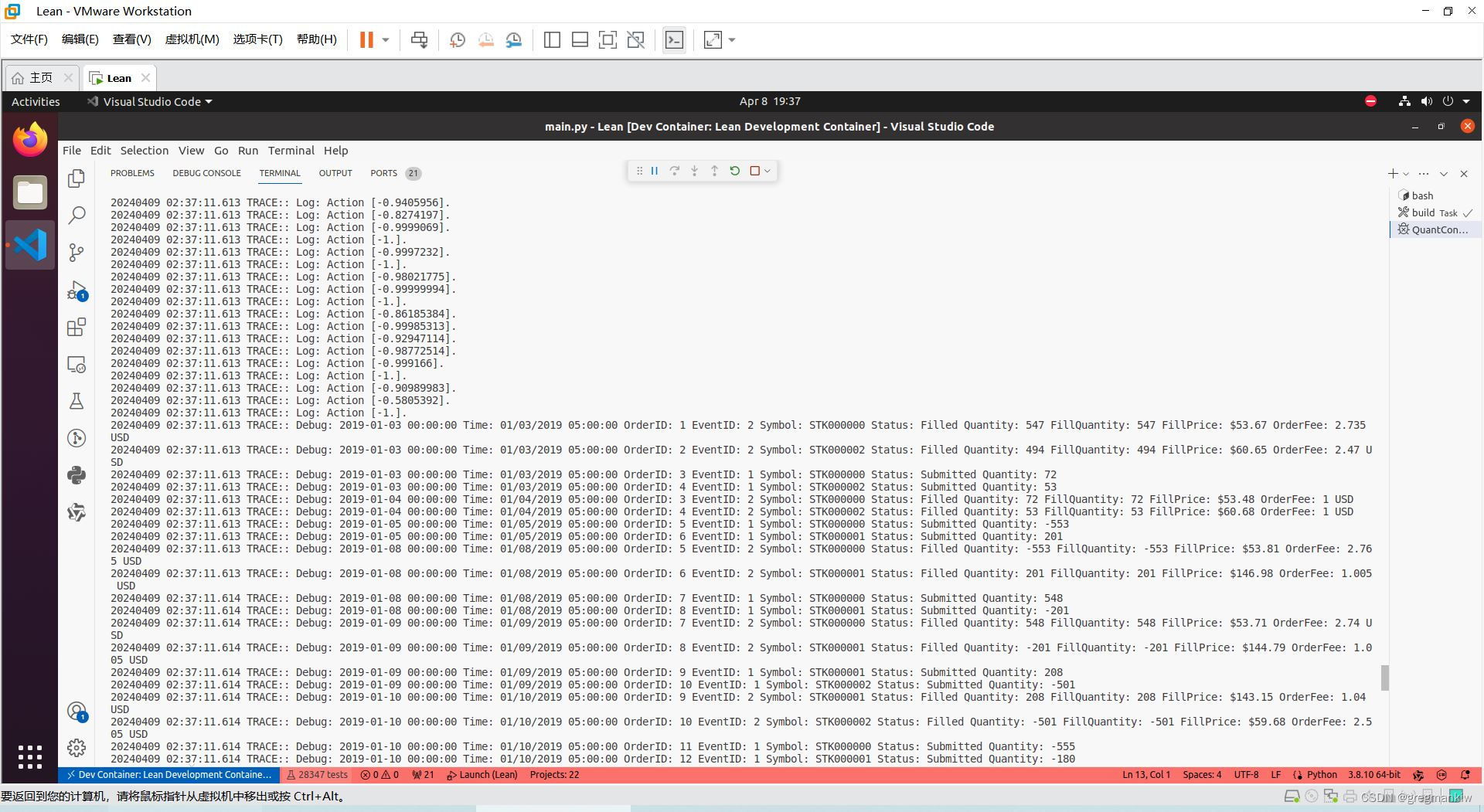
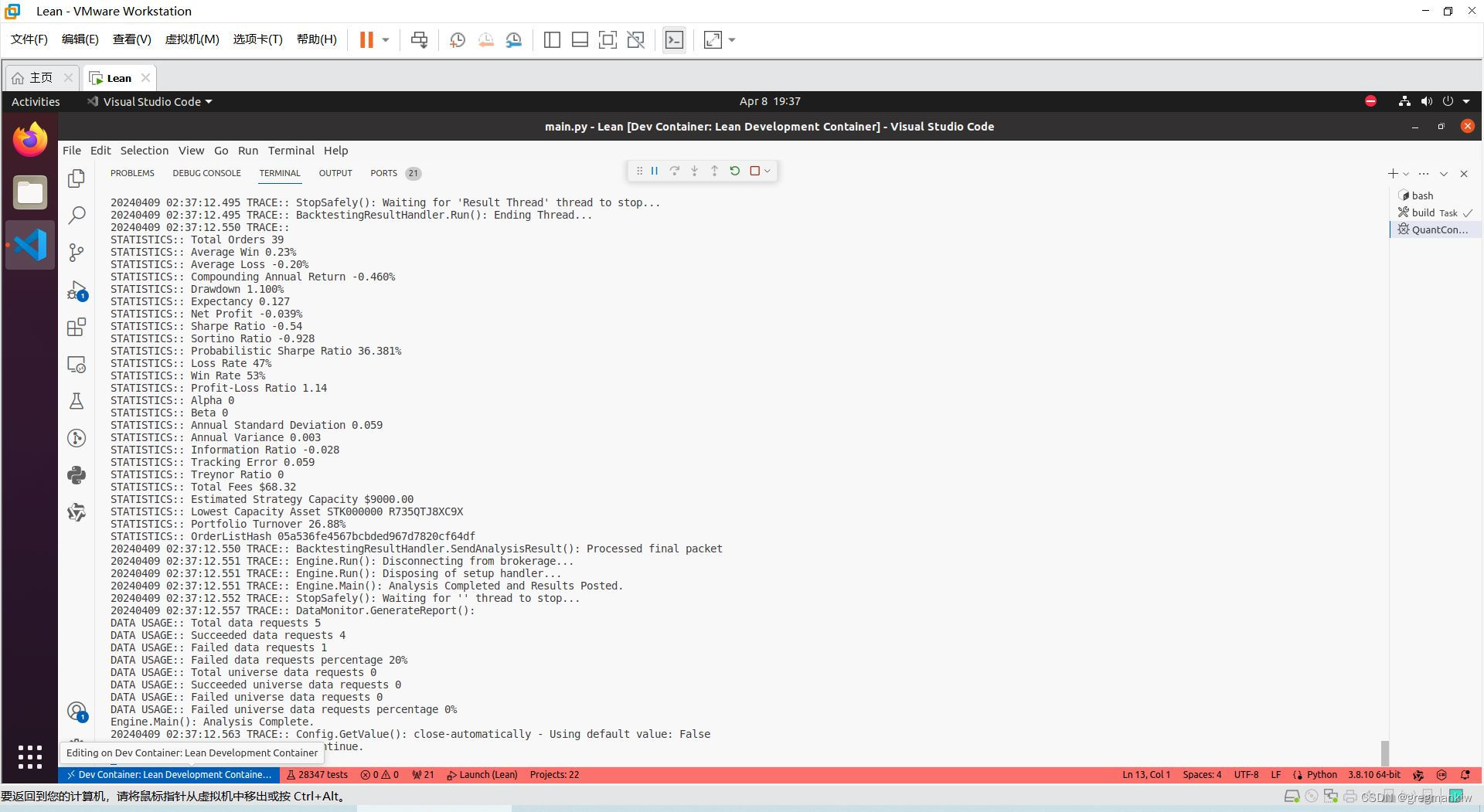
小结
本案例属于基础策略,后续可在此基础上进行迭代升级。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/840183
推荐阅读
相关标签

