
- 1idea拉取项目报错:master has no tracked branch或master 没有跟踪的分支
- 2typora使用command line与gitee同步图床及主题推荐_typora picgo command-line gitee
- 3拉格朗日插值法在数据分析中的应用——Python插值scimpy,lagrange_拉格朗日插值在数据清洗的应用
- 4【穿越2024:AI绘画的艺术革命与未来畅想】_ai梵高”——《星夜再现》
- 5关于数据结构和算法的面试题_数据结构与算法面试题
- 6数据挖掘算法之 k-means_数据挖掘kmeans采用的数学方法
- 7查找不可见字符的正则表达式_正则表达式 不可见字符
- 8Portal 共享 session
- 9推荐一款高性能的 Rust Web 框架 - Actix-Web
- 10实验9-20211127 1+X 中级实操考试(id:2660)_20211127 1+x 中级实操考试(id:2660)
RabbitMQ 之 幂等性 | 优先级队列 | 惰性队列_rabbitmq幂等
赞
踩

目录
一、幂等性
1、概念
用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣钱了,流水记录也变成了两条。
在以前的单应用系统中,我们只需要把数据操作放入事务中即可,发生错误立即回滚,但是再响应客户端的时候也有可能出现网络中断或者异常等等
2、消息重复消费
消费者在消费 MQ 中的消息时,MQ 已把消息发送给消费者,消费者在给 MQ 返回 ack 时网络中断,故 MQ 未收到确认信息,该条消息会重新发给其他的消费者,或者在网络重连后再次发送给该消费者,但实际上该消费者已成功消费了该条消息,造成消费者消费了重复的消息。
3、解决思路
MQ 消费者的幂等性的解决一般使用全局 ID 或者写个唯一标识比如时间戳 或者 UUID 或者订单消费者消费 MQ 中的消息也可利用 MQ 的该 id 来判断,或者可按自己的规则生成一个全局唯一 id,每次消费消息时用该 id 先判断该消息是否已消费过。
4、消费端的幂等性保障
在海量订单生成的业务高峰期,生产端有可能就会重复发生了消息,这时候消费端就要实现幂等性,这就意味着我们的消息永远不会被消费多次,即使我们收到了一样的消息。业界主流的幂等性有两种操作
a.唯一 ID+指纹码机制,利用数据库主键去重,
b.利用 redis 的原子性去实现
5、唯一 ID + 指纹码机制
指纹码:我们的一些规则或者时间戳加别的服务给到的唯一信息码,它并不一定是我们系统生成的,基本都是由我们的业务规则拼接而来,但是一定要保证唯一性,然后就利用查询语句进行判断这个 id 是否存在数据库中
优势:实现简单就一个拼接,然后查询判断是否重复
劣势:在高并发时,如果是单个数据库就会有写入性能瓶颈当然也可以采用分库分表提升性能,但也不是我们最推荐的方式。
6、Redis 原子性
利用 redis 执行 setnx 命令,天然具有幂等性。从而实现不重复消费
二、优先级队列
1、使用场景
在我们系统中有一个订单催付的场景,我们的客户在天猫下的订单,淘宝会及时将订单推送给我们,如果在用户设定的时间内未付款那么就会给用户推送一条短信提醒,但是,商家对我们来说,肯定是要分VIP和普通客户的对吧,VIP 客户的订单必须得到优先处理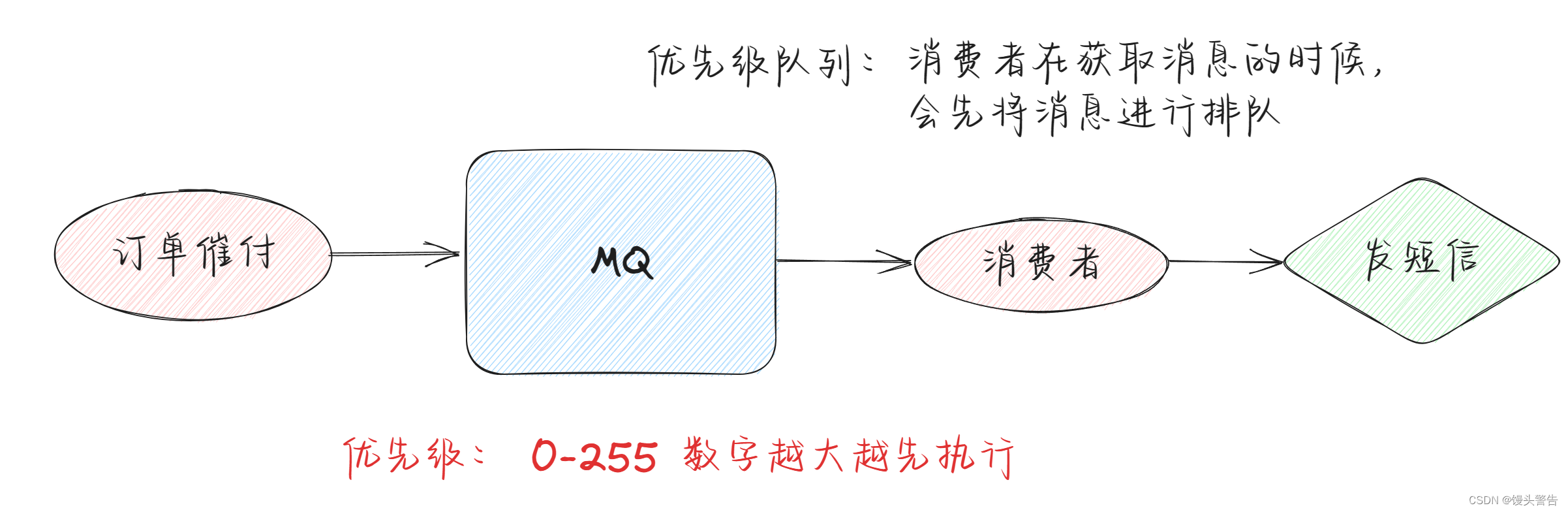
而曾经我们的后端系统是使用 redis 来存放的定时轮询,大家都知道 redis 只能用 List 做一个简简单单的消息队列,并不能实现一个优先级的场景,所以订单量大了后采用 RabbitMQ 进行改造和优化,如果发现是大客户的订单给一个相对比较高的优先级,否则就是默认优先级。
2、添加优先级队列
第一种:控制台页面添加
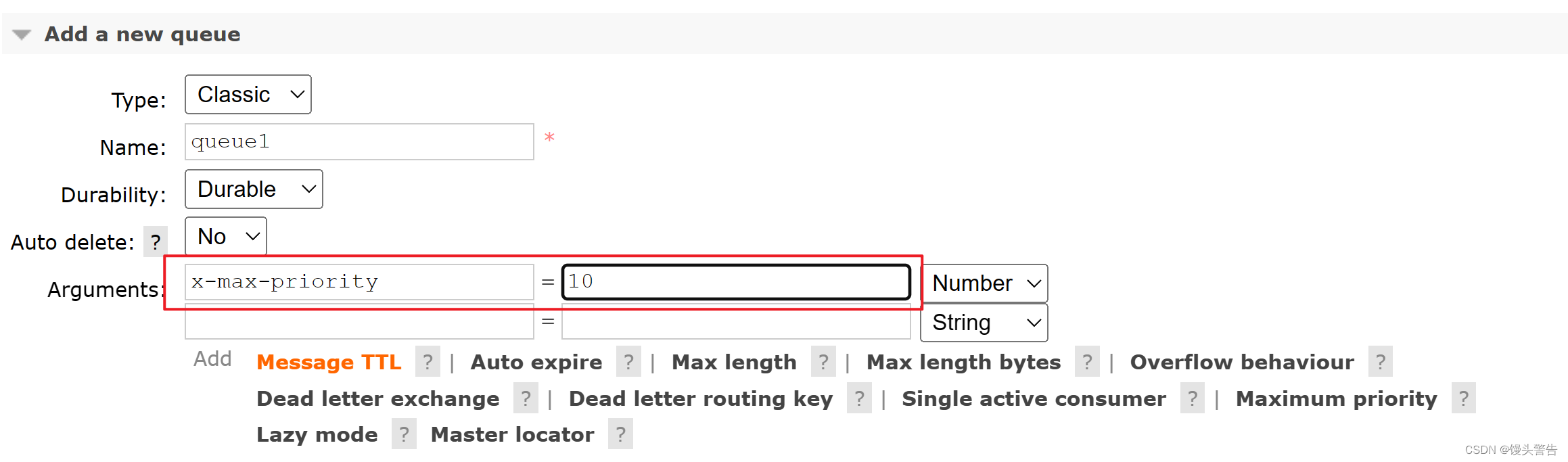
第二种: 队列中代码添加优先级
- Map<String, Object> params = new HashMap();
- params.put("x-max-priority", 10);
- channel.queueDeclare("hello", true, false, false, params);

第三种:消息中代码添加优先级
- AMQP.BasicProperties properties = new
- AMQP.BasicProperties().builder().priority(5).build();
注意事项:
要让队列实现优先级需要做的事情有如下事情:
队列需要设置为优先级队列,消息需要设置消息的优先级,消费者需要等待消息已经发送到队列中才去消费因为,这样才有机会对消息进行排序
3、生产者
- public class Producer {
- private static final String QUEUE_NAME="hello";
- public static void main(String[] args) throws Exception {
- try (Channel channel = RabbitMqUtils.getChannel();) {
- //给消息赋予一个 priority 属性
- AMQP.BasicProperties properties = new
- AMQP.BasicProperties().builder().priority(5).build();
- for (int i = 1; i <11; i++) {
- String message = "info"+i;
- if(i==5){
- channel.basicPublish("", QUEUE_NAME, properties, message.getBytes());
- }else{
- channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
- }
- System.out.println("发送消息完成:" + message);
- }
- }
- }
- }

4、消费者
- private static final String QUEUE_NAME="hello";
-
- public static void main(String[] args) throws Exception {
- Channel channel = RabbitMqUtils.getChannel();
- //设置队列的最大优先级 最大可以设置到 255 官网推荐 1-10 如果设置太高比较吃内存和 CPU
- Map<String, Object> params = new HashMap();
- params.put("x-max-priority", 10);
- channel.queueDeclare(QUEUE_NAME, true, false, false, params);
- System.out.println("消费者启动等待消费......");
- DeliverCallback deliverCallback=(consumerTag, delivery)->{
- String receivedMessage = new String(delivery.getBody());
- System.out.println("接收到消息:"+receivedMessage);
- };
- channel.basicConsume(QUEUE_NAME,true,deliverCallback,(consumerTag)->{
- System.out.println("消费者无法消费消息时调用,如队列被删除");
- });
- }
- }
三、惰性队列
1、使用场景
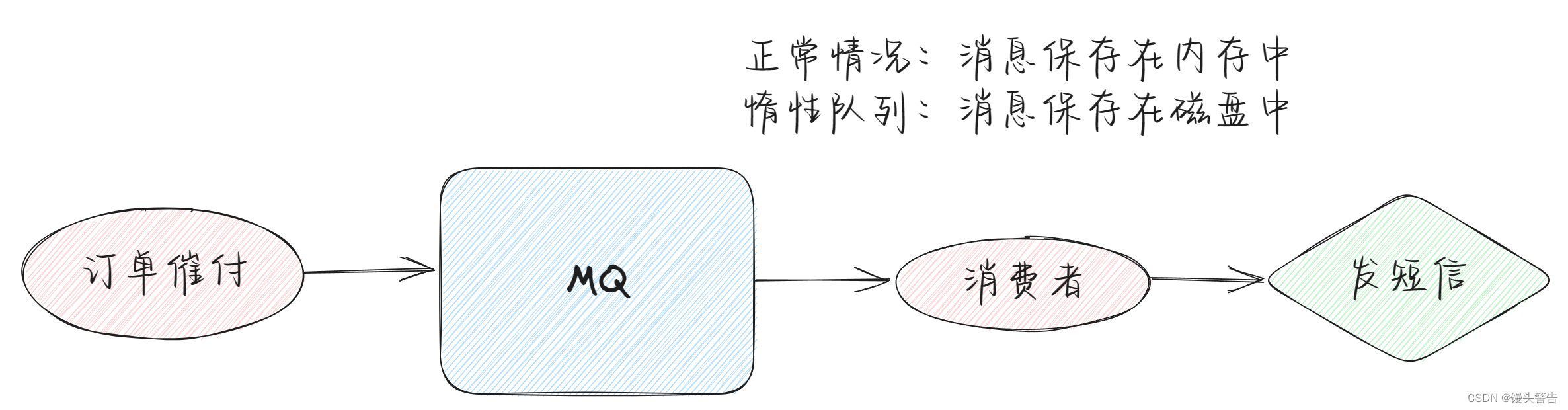 当我们发送一条消息到达 MQ 当中,如果 MQ 正好是惰性队列,会马上将消息存放在磁盘里,
当我们发送一条消息到达 MQ 当中,如果 MQ 正好是惰性队列,会马上将消息存放在磁盘里,
而消费者去消费需要先从磁盘里读取到内存中,在这之后再进行消费,所以惰性队列消费速度是很慢的,一般不采用惰性队列。
什么时候会采用惰性队列呢?
例如:发消息过来,积压了有 100w 的消息,而消费者宕机了 / 关闭了,就导致 MQ 中堆积了大量的消息,没有人消费,这个时候采用惰性队列就非常适合,因为他会把这 100w 的消息存放在磁盘上,就不会浪费 MQ 的内存,也不会造成 MQ 消息的积压
2、两种模式
队列具备两种模式:default 和 lazy。默认的为 default 模式
在 3.6.0 之前的版本无需做任何变更。lazy模式即为惰性队列的模式,可以通过调用 channel.queueDeclare 方法的时候在参数中设置,也可以通过 Policy 的方式设置
如果一个队列同时使用这两种方式设置的话,那么 Policy 的方式具备更高的优先级。
如果要通过声明的方式改变已有队列的模式的话,那么只能先删除队列,然后再重新声明一个新的。
在队列声明的时候可以通过“x-queue-mode”参数来设置队列的模式,取值为“default”和“lazy”。下面示例中演示了一个惰性队列的声明细节:
- Map<String, Object> args = new HashMap<String, Object>();
- args.put("x-queue-mode", "lazy");
- channel.queueDeclare("myqueue", false, false, false, args);
3、内存开销对比

在发送 1 百万条消息,每条消息大概占 1KB 的情况下,普通队列占用内存是 1.2GB,而惰性队列仅仅占用 1.5MB

