
- 1介绍一下QNX Neutrino、WindRiver VxWorks和Green Hills INTEGRITY、 NVIDIA DRIVE OS、Mentor Nucl等智能驾驶操作系统平台的特点?_ghs integrity rtos
- 2Hystrix之四种触发fallback情况的验证_@hystrixcommand(fallbackmethod = "failback") 触发 条件
- 3【MongoDB】Windows安装MongoDB_mongodb supported win10 or 2016
- 4命名数据网络(NDN)上的路由转发过程_ndn网络 pit路由
- 5web前端-------css盒子模型_web前端css部分弹性边框里再设计一个边框标签
- 6狂神 MYSQL 笔记整理_java狂神mysql
- 7Java基于web的软件资源库的设计与实现(源码+mysql+文档)_javaweb做一个智库
- 8论文翻译:从传统数据仓库到实时数据仓库_rtdw
- 9Jenkins通过Nexus artifact uploader 上传制品失败排查_failed to deploy artifacts: could not transfer art
- 10“hadoop:未找到命令”解决办法
图像识别之ResNet(结构详解以及代码实现)_resnet结构
赞
踩
前言
在人工智能的浪潮中,深度学习已经成为了推动计算机视觉、自然语言处理等领域突破的关键技术。在这众多技术中,ResNet(残差网络)无疑是一个闪耀的名字。自从2015年Kaiming He等人提出ResNet架构以来,它不仅在图像识别领域取得了革命性的进展,更影响了后续神经网络设计的诸多方面。
那么,什么是ResNet?简而言之,ResNet是一种深度卷积神经网络(CNN),其核心创新在于引入了“残差学习”的概念,通过残差块(residual block)的设计优雅地解决了深度网络训练中的退化问题。这种结构允许网络通过简单的恒等映射来学习复杂的表示,有效地促进了更深网络的训练。
让我们先看看网络退化问题

在作者论文中提及随着网络层数的不断加深,模型的准确率起初会不断的提高,最后达到饱和值,之后随着网络深度的不断增加,模型准确率不但不会继续增加,反而会出现大幅度降低的现象。如上图,模型训练以及验证的过程中56层的error比20层的还要高,这是由于之前的网络模型随着网络层不断加深会造成梯度爆炸和梯度消失的问题。
随着深度学习技术的不断进步,ResNet及其变体已经广泛应用于多种视觉任务,包括但不限于图像分类、物体检测、语义分割等。ResNet的成功不仅体现在它的性能上,更在于它为后来的网络架构设计提供了灵感,诸如DenseNet、Inception等都受到了ResNet设计的启发。
论文地址:https://arxiv.org/pdf/1512.03385.pdf
亮点
- 1、提出Residual模块
- 2、使用Batch Normalization加速训练(丢弃dropout)
- 3、残差网络:易于收敛、很好的解决了退化问题、模型可以很深,准确率大大提高
ResNet模型结构
1、残差学习
结构1:Identity Block:输入和输出的dimension是一样的,用于增加网络的深度,可以串联多个

结构2:Conv Block:输入和输出的dimension是不一样的,用于改变网络的维度,不能连续串联
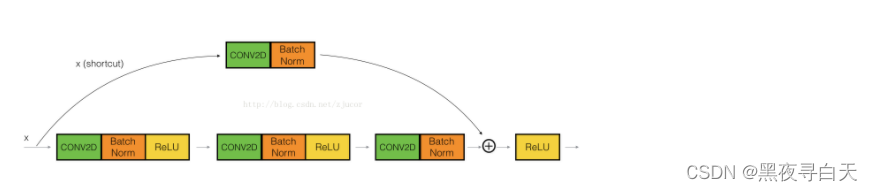
2、ResNet模型
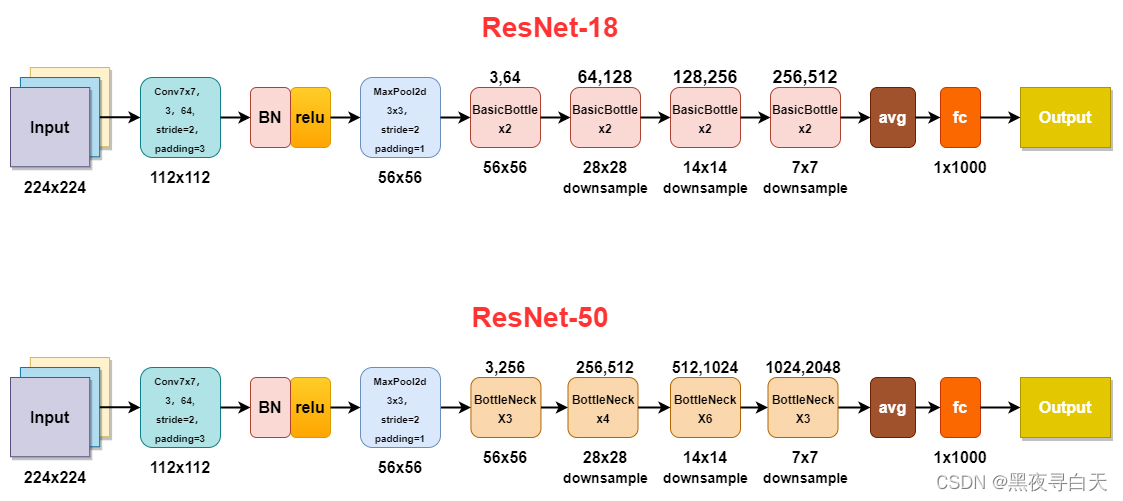
论文展示的ResNet-layer模型
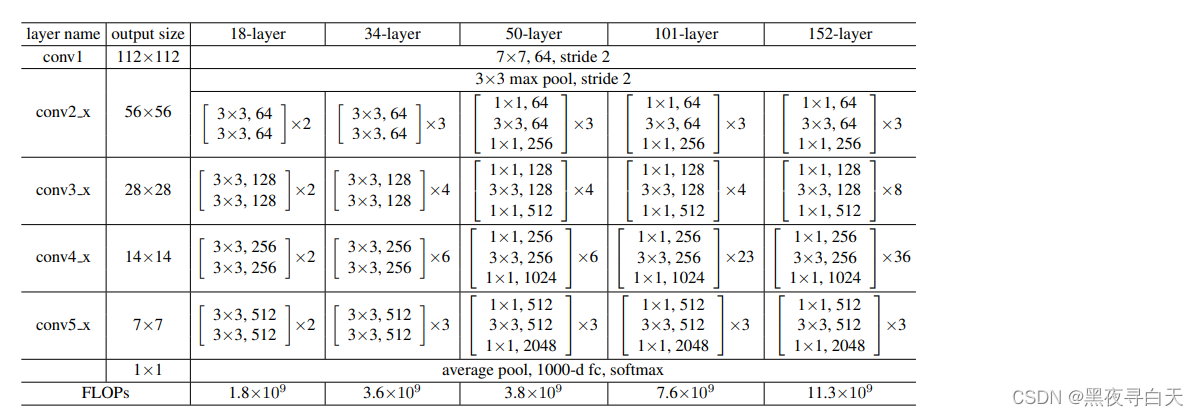
BottleNeck中就是咱们先前学习的残差块啦,往往第一个BottleNeck中是Conv Block,之后是Identity Block串联,例如BottleNeck × 4中 第一个残差块是Conv Block,剩下三个是Identity Block
因为CNN最后都是要把输入图像一点点的转换成很小但是depth很深的feature map,
一般的套路是用统一的比较小的kernel(比如VGG都是用3*3),但是随着网络深度的增加,output的channel也增大(学到的东西越来越复杂)
所以有必要在进入Identity Block之前,用Conv Block转换一下维度,这样后面就可以连续接Identity Block.

当BottleNeck是Conv Block时,3 × 3 卷积核中的stride =2,从而实现将特征图大小减半,在上诉论文展示的图片的output size中可以体现出来,当是Identity Block,3 × 3 卷积核中的stride =1,不改变特征图大小
不过在原论文中第一个1 × 1卷积层的步长是2,第二个3 × 3卷积层步长是1
但在pytorch官方实现过程中第一个1 × 1卷积层的步长是1,第二个3 × 3卷积层步长是2,这样能给在imagenet的top1上提升大概0.5%的准确率
BN层使用注意事项

代码
我回去翻翻 找到了立马上传水平有限,有错希望大家能指正
点赞或收藏,能鼓励作者不断更新哟~
参考链接:
【DL系列】ResNet网络结构详解、完整代码实现-CSDN博客

