
- 1LangChain 核心模块学习 模型输入 Prompts_langchian中怎么构建llama的prompt
- 2蓝桥杯嵌入式G4-按键(单击双击长按)定时器扫描_蓝桥杯嵌入式长按按键
- 3Transformers 中原生支持的量化方案概述_transformers quantize
- 4绝对受用的求职经验分享_绝对受用的求职经历及经验分享
- 5队列的顺序实现(用顺序存储实现队列)_实现顺序存储队列的判断队空,判断队满,进队,出队,取队顶元素等相关操作。
- 6php_mt_seed - PHP mt_rand() 随机数种子破解使用
- 7Centos 6 安装PPTP服务,实现内网穿透_pptp内网穿透
- 8探秘智能对话:ChatBotCourse - 开源你的AI助手
- 9Ubuntu20.04双系统 无线网卡驱动(未发现wifi适配器)、Nvidia显卡驱动安装一条龙教程+疑难杂症修复【多坑预警】_ubuntu20.04安装无线网卡驱动
- 10第五章C语言程序设计实训教程2_c语言程序设计实训教程实验二
Java数据结构(一)——准备知识(初识集合框架、包装类、初识泛型)_java集合的数据结构
赞
踩
从这篇文章开始,我们将踏上Java数据结构的旅途,这是我们的第一站!
Java 数据结构之准备知识
集合框架
Java的集合框架是一组用于表示和操作数据结构的类和接口。
主要包括以下几部分:
Collection接口:是所有集合类的根接口,定义了集合的基本操作,如添加、删除、遍历等。List接口:表示有序、可重复的元素集合,实现类有ArrayList、LinkedList等。Set接口:表示无序、不可重复的元素集合,实现类有HashSet、TreeSet等。Queue接口:表示队列,实现类有PriorityQueue、LinkedList等。Map接口:表示键值对映射关系,实现类有HashMap、TreeMap等。Iterator接口:用于遍历集合元素,提供了hasNext()和next()方法。Comparator接口:用于自定义排序规则,实现了compare()方法。Collections类:提供了静态方法对集合进行操作,如排序、查找、同步等。
如下图:
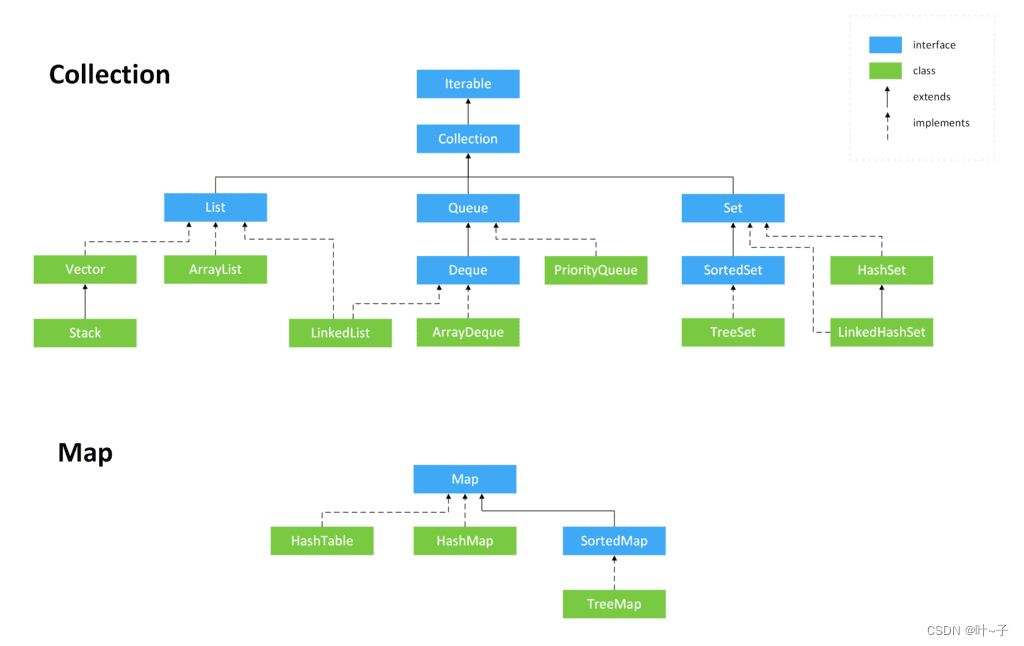
对于刚入门的我们,理解这么庞大的体系是困难的,我们这里仅作一个了解,后面会慢慢深入讲解每个部分,相信最后总结的时候就会吃透这个框架了。
包装类
拆箱与装箱
拆箱,又叫拆包,即将包装类中存储的值存放到对应的基本类型变量中
装箱,又叫装包,即将基本类型变量存放的值存放到对应的包装类对象中
拆箱 和 装箱,都有两种方式:
- 显式装箱(拆箱)
- 自动装箱(拆箱)
/** * 演示装箱和拆箱操作 * @param args */ public static void main(String[] args) { //自动装箱 int i1 = 10; Integer integer1 = 10; //显式装箱 int i2 = 20; Integer integer2 = Integer.valueOf(i2); //自动拆箱 int j1 = integer1; //显式拆箱 int j2 = integer2.intValue(); //打印测试 System.out.println(i1); System.out.println(integer1); System.out.println(i2); System.out.println(integer2); System.out.println(j1); System.out.println(j2); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

-
自动拆箱和装箱操作,就是对显式行为的简写,在代码实际运行时,Java已经自动帮我们执行了显式语句
我们可以通过观察反汇编代码验证这一点:

观察反汇编代码,我们发现valueOf和intValue实际上各调用了两次,即自动装箱和自动拆箱时,Java会自动帮我们调用合适的类方法。
- 显式装箱用到
valueOf()方法,并且要通过包装类访问;而显式拆箱用到的类方法要由实际类型决定,如int就要对应intValue方法、double就要用到doubleValue,要通过包装类对象访问对应方法
为什么我们打印Integer类的引用变量的结果不是地址呢?
结合前面的知识,不难推断Integer类重写了Object类中的toString方法

对包装类有了基本认识后,我们看一道题目:
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
System.out.println(a == b);
Integer c = 200;
Integer d = 200;
System.out.println(c == d);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

为什么出现这样的结果呢?
首先,我们知道:1. ==判断两个引用指向的地址 2. 上代码执行了自动装箱操作,底层调用了valueOf()方法
a == b为true意味着a和b引用了同一地址;c == d为false意味着c和d引用不同的地址
接着,我们尝试从valueOf()的源码中寻找原因:

观察发现:如果我们用于装箱的数在[low, high]区间内,那么会从一个cache数组中取;否则,直接new一个对象。
我们继续观察low、high、cache



我们能得到low和high的值,从而确定区间为[-128, 127],一共256个;而cache是一个Integer类型的数组,称它为缓存数组。
所以,得到当装箱的值在[-128, 127]时,会从Integer类型的cache数组拿,所以有题目a 和b引用的地址一样;而超出这一区间的值会直接new一个对象,自然得题目中的c和d引用不同的地址。
初识泛型
认识泛型
泛型,又叫做 “类型参数化”,它能帮助我们实现将类型作为参数传递的操作,目的就是指定当前容器,要持有什么类型
引子:
假设我们现在有一个类,类中将要创建一个数组成员,要求: 这个数组中可以存放任意类型的数据,怎么办?
首先我们想到所有类的父类Object类,创建一个Object类的数组,此时,该数组能够存放任意类型的数据
如下代码:
public class MyArray {
//创建Object数组
private Object[] objects = new Object[10];
//取元素
public Object getObjects(int pos) {
return this.objects[pos];
}
//存元素
public void setObjects(int pos, Object object) {
this.objects[pos] = object;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
接下来,我们测试该类:
public static void main(String[] args) {
MyArray myArray = new MyArray();
myArray.setObjects(0, 12);
myArray.setObjects(1, "hello");
int a = (int) myArray.getObjects(0);
String s = (String) myArray.getObjects(1);
System.out.println(a);
System.out.println(s);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如上代码所示,我们可以在此数组中存放任意类型的数据,且可以从中拿取指定下标位置的元素,不过必须强制类型转换,因为方法返回值是Object类型
对于这样的解决方案,有很多缺点:
- 需要手动强制类型转换:每次从数组中取值接收,必须强制类型转换,使得操作较麻烦
- 编译时类型不匹配不会报错:当出现类型不匹配的情况时,编译器不会报错,程序运行时报错,这使得程序员在写代码时不能及时发现错误
- 记忆困难:即便是写代码的人,也很难记住数组中的哪个位置存放了什么类型的数据
针对以上问题,我们给出泛型的解决方案:
public class MyArray <E> { private Object[] objects = new Object[10]; public E getObjects(int pos) { return (E)this.objects[pos]; } public void setObjects(int pos, E val) { this.objects[pos] = val; } } class Main { public static void main(String[] args) { MyArray<Integer> myArray = new MyArray<Integer>(); myArray.setObjects(0, 12); int elem = myArray.getObjects(0);//这里Java执行了自动拆箱操作 Integer elem1 = myArray.getObjects(0); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 自动类型转换:使用泛型解决方案,使用者(调用者)无需手动强制类型转换,因为泛型类中已经实现好了
- 自动类型检查:当出现类型不匹配的情况时,代码会报错(代码出现红线),提醒使用者修改代码,否则编译不会通过
- 方便记忆:如上例,我们创建
MyArray对象时,将类型Integer以类似参数的形式传递,此时,实例化的对象中的数组中存放的就只是Integer类型(所有的占位符E都等价于我们传递的类型Integer)
注意:
-
定义泛型类:
<>以及其中的标识符,为占位符,表示此类为泛型类<>中的标识符叫做类型形参,仅起到占位作用,允许自定义,但一般用一个大写的字母表示,并且我们有一套更为官方的使用建议:E:表示ElementK:表示KeyV:表示ValueN:表示NumberT:表示TypeS、U、V等等:表示第二个、第三个…若干个类型形参
对于类型参数
E,为什么我们不能直接new E[10]或new E()?因为并不是每个类型都有一个空的构造器
-
实例化泛型类对象:
类名后面加上
<>,其中传入类型,注意这里的类型不能为基本类型,如int;必须传入基本类型的包装类,如Integer不过,在
new后的<>内可以不写类型,如:MyArray<Integer> myArray = new MyArray<>();,编译器可以通过上下文推导出此处的类型,即类型推导 -
裸类型(仅了解)
裸类型是一个泛型类但没有类型实参,即在实例化一个泛型类对象时,不加
<>,只有类名,此时语法不会报错,如:public class MyArray <E> { private Object[] objects = new Object[10]; public E getObjects(int pos) { return (E)this.objects[pos]; } public void setObjects(int pos, E val) { this.objects[pos] = val; } } class Main { public static void main(String[] args) { MyArray array = new MyArray(); array.setVal(0, 10); array.setVal(1, "hello"); String str = (String) array.getVal(1); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
此时,相当于普通的类,如上代码,可以在数组中存放不同的类型,且拿值时必须手动强制类型转换。
这一语法仅是为了兼容以前的老版本
擦除机制
要谈擦除机制,就是要谈泛型是如何编译的。
在编译的过程当中,将所有的类型形参替换为Object这种机制,我们称为:擦除机制。
即,Java的泛型机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。
基于上面的泛型类解决方案,我们通过jclasslib插件看一下它的部分字节码文件信息:

我们看描述符,()内部表示方法的参数,V表示方法返回值为void,()内部分为两部分:I和Ljava/lang/Object:I表示第一个参数为int类型,Ljava/lang/Object表示第二个参数为Object,而非E。(此时类型参数E被擦除为Object)
这就体现了Java的擦除机制,泛型机制的自动类型检查和自动类型转换都发生在擦除前。
我们再看一个例子:
我们知道,直接打印引用类型变量,将会打印一段字符,如下:
public static void main(String[] args) {
int[] arrayInt = new int[10];
System.out.println(arrayInt);
}
- 1
- 2
- 3
- 4

[I:表示当前引用指向了int类型数组
对于一个泛型类的引用:
public static void main(String[] args) {
MyArray<Integer> myArray = new MyArray<>();
System.out.println(myArray);
}
- 1
- 2
- 3
- 4

demo4.MyArray:表示当前引用指向了demo4底下的MyArray类型的对象
<Integer>不参与类型的组成,一定程度上印证了擦除机制
泛型的上界
定义泛型类时,我们可以通过类型边界对传入的类型变量做一定的约束,如下语法:
class 泛型类名称 <类型形参 extends 类型边界> {
}
此时,传入的类型实参只能为类型边界类或者其子类,否则会报错
例如:
public class MyArray<E extends Number> {
//...
}
- 1
- 2
- 3
此时,类型形参只能接受Number或其子类,如Integer;而String不能被接收,它不是Number或其子类
另外,如果没有指定类型边界,那么类型边界默认为Object
除了上面提到的限制传入类型变量的方法,我们补充一种,其语法如下:
class 泛型类名称 <E extends Comparable> {
}
此时传入的
E必须实现了Comparable接口
泛型方法
除了定义泛型类,Java允许定义泛型方法
【语法】
方法限定符 <类型形参> 返回值类型 方法名称(形参列表) {
}
例如:
public class Test {
public <E extends Comparable<E>> E findMax(E[] array) {
E max = array[0];
for (int i = 0; i < array.length; i++) {
if(max.compareTo(array[i]) < 0) {
max = array[i];
}
}
return max;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如代码,我们定义了一个普通类,里面实现了一个泛型成员方法。
【使用】
我们怎么使用泛型方法呢?
public class Test { public <E extends Comparable<E>> E findMax(E[] array) { E max = array[0]; for (int i = 0; i < array.length; i++) { if(max.compareTo(array[i]) < 0) { max = array[i]; } } return max; } } class Main { public static void main(String[] args) { Integer[] a = new Integer[]{1, 2, 3, 4, 5}; Test test = new Test(); test.<Integer>findMax(a);//完整书写 test.findMax(a);//类型推导 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 我们实现的是一个非静态的方法,所以使用时必须实例化其所在类的对象,然后去调用
- 调用时,在方法名前使用
<>传入类型;当然,也可以选择不写(类型推导)
上面的方法每次调用需要new一个对象,太麻烦了,我们可以用static修饰上方法,使其成为一个静态泛型方法,这样我们就可以使用类名.方法去调用了:
public class Test { public static <E extends Comparable<E>> E findMax(E[] array) { E max = array[0]; for (int i = 0; i < array.length; i++) { if(max.compareTo(array[i]) < 0) { max = array[i]; } } return max; } } class Main { public static void main(String[] args) { Integer[] a = new Integer[]{1, 2, 3, 4, 5}; Test.findMax(a); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 此处注意
static的位置是在<>之前,否则会报错。包括final等修饰符都必须写在<>之前
以上就是我们要介绍的准备知识了,有了这些知识,就撬开了数据结构的大门!

