
- 1传输门、D 锁存器、D触发器、建立时间与保持时间_传输门dff
- 2智能语音技术助力金融客服提效降本
- 3【AI虚拟试衣】_ai试衣
- 4多模态AnyGPT——整合图像、语音和文本多模态大规模语言模型算法原理与实践_语音文字多模态模型
- 5sql server 2008 忘记sa密码的解决方法_sqlserver2008sa密码忘记无法设置主体的凭据
- 6R11020Z-10高效智能模块:引领未来科技新潮流
- 7springboot深入实践-2.4Neo4j数据库详解_spring-data-neo4j relation
- 8covariance 公式_酒店人常用的计算公式,果断收藏了!
- 9VLAN简单配置_vlan配置
- 10Android Studio 国内镜像代理设置(如果设置之后还是远程仓库下载失败,请仔细阅读其内容就可以解决了)_mirrors.neusoft.edu.cn
帮AI摆脱“智障”之名,NLP这条路还有多远?
赞
踩

CSDN 出品的《2018-2019 中国人工智能产业路线图》V2.0 版即将重磅面世!
V1.0 版发布以来,我们有幸得到了诸多读者朋友及行业专家的鼎力支持,在此表示由衷感谢。此次 V2.0 版路线图将进行新一轮大升级,内容包括 3 大 AI 前沿产业趋势分析,10 位 AI 特邀专家的深度技术分析,15 家一线互联网企业的 AI 实力大巡展,以及 20 个 AI 优秀应用案例,力求为读者呈现更全面的中国人工智能产业发展概况和趋势判断。
V2.0 版将于 11 月 8 日举办的 2018 AI 开发者大会上正式发布,在此之前,我们将不间断公布精要内容,以飨读者。此为 V2.0 版中深度技术分析系列稿件第 7 篇,作者为 CSDN 特邀 AI 专家——王文广 达观数据副总裁 。(回顾:第 1、2、3、4、5、6篇)
什么是 NLP
自然语言处理(NLP)是人工智能(AI)的一个分支,其目标是让计算机能够像人类一样理解、处理和生成自然语言。自然语言,又称人类语言,一般以文字或文本的形式存在于计算机中,从而在某些地方,也被通俗的称为文本智能处理。与自然语言相对的是形式语言(比如 Python 等编程语言),计算机可以精确地处理。自然语言往往因为在使用中省略背景,模糊而不精确、多义、引申、晦涩,甚至由于各种原因而故意使用曲折的表达,而使计算机处理自然语言时困难重重,成为人工智能发展中最大的难点之一。
NLP 技术诞生于1950年代,其分支也枝繁叶茂。有基于语法和规则的方法,也有基于统计学习的方法,从 21世纪初以来蓬勃发展的深度学习、深度强化学习和迁移学习的方法在 NLP 领域也被广泛地使用。微观层面,在学术界一般将 NLP 划分为四个层级:即词法(Lexicon)、句法(Syntax)、语义(Semantics)和语用(Pragmatics)。面向普通大众,也通常使用偏向应用层面的直接的划分方法,即字词级、 句段级和篇章级。
NLP 技术在宏观层面通常又划分为划分为自然语言理解(NLU)和自然语言生成(NLG)两部分。通俗的讲,自然语言理解就是我们常说的“阅读”,即让计算机读懂语言文字的技术。而自然语言生成则是“写作”,即让计算机能够像人类一样写句子和文章的技术。除此之外,光学字符识别(OCR)和语音技术(包括识别与合成),也会在某些场景下被归为自然语言处理的一部分,但本文不涉及这两块内容。
NLP 是实现认知智能的关键
人工智能(AI)通常被分为三大块:计算智能,感知智能和认知智能。计算智能方面,以 AlphaGo 打败了人类围棋最顶尖选手李世石和柯洁为标志,已将人类远远抛在后面。感知智能则以语音和图像技术为代表,对应于人类的视觉和听觉,经过近十几年深度学习、迁移学习等技术的发展,也在非常多领域超越了人类。人工智能在近些年不断的在计算智能和感知智能上发展,一方面是技术迅猛发展的原因,另外一方面也是人类并不擅长这两种。然而,在认知智能上,目前还有待技术层面的进一步突破,而这里面的关键就是 NLP 技术。
一般认为,认知智能是以语言为基础,实现推理、思考、决策和想象。语言,是人类区别于动物的标志性能力,而让机器拥有语言能力的关键技术就是自然语言处理技术。当前计算机在认知智能上还处于非常初级的阶段,特别是在中文上。今年遍地开花的各类智能音箱,随便与之对话几句便能够感受到强烈的“智障”气息。因此,为了达到更强的认知智能,急需 NLP 技术的进一步发展。当前学术界的热点也在往 NLP 领域迁徙,投向 NLP 方面的资本也在增加。
迁移学习和预训练模型在 NLP 领域出现了突破
以 ImageNet 为代表的预训练模型以及相应的迁移学习技术,促使了感知智能的极大发展。为了提升认知智能的水平,必须在 NLP 技术上有所突破。在深度学习出现以后,对于有大量标注数据的场景,比如中文和英文之间的机器翻译,通过深度学习和 NLP 技术的结合能够达到不错的效果。然而对于缺乏标注数据的绝大多数场景,则依赖于好的预训练模型以及迁移学习技术的发展。此前,这个在图像领域已经被证明了的范式,在 NLP 领域一直发展得不温不火。大概是量变引起质变,从 Word2Vec 出现以来,NLP 领域的预训练模型在 5 年内的积累,以及深度网络在 NLP 领域的应用,使得今年出现了突破。这里面最耀眼的当属 Google 刚刚提出的 BERT 预训练模型以及基于 BERT 的迁移学习。

NLP领域的预训练模型的发展历史(配图:达观数据)
早在 2013 年 Google 提出了 Word2Vec 之后,NLP 领域的深度学习就开始使用预训练模型,而后斯坦福大学提出的 GloVe 和 Facebook 提出的 Fasttext 则是进一步发展。然而在今年之前,这方面的尝试大都局限于使用浅层网络,在词的层面上进行建模。针对具体的应用场景,要达到较好的效果依然需要非常大量的标注语料。预训练深层模型以及之上的迁移学习在图像领域的成功,引领着 NLP 领域专家们也在思考如何实现同样的范式。多年的努力与探索,终于在今年迎来了丰收。
首先是年初发表于 NAACL-HIT 2018 的 ELMo 预训练模型,用正向和反向两个 LSTM 语言模型(BiLM)在通用语料上进行训练,将得到的预训练好的模型(即 ELMo)用于深度网络的输入上,在多个任务上能够明显改善已有的模型的效果。
此后,FastAI 基于三层 AWD-LSTM 构建出的语言模型,使用大规模通用语料预训练出 ULMFiT 模型。将该模型应用于特定领域,只要使用非常少量的标注数据就可以达到普通模型需要大量标注数据的效果。这个模型的成功,使得大家看到了迁移学习在 NLP 领域上的曙光。
紧接着,OpenAI 使用 Transformer 和无监督结合的方法在大规模通用语料上进行训练,得到预训练好的 GPT 模型。针对特定的场景,在预训练好的 GPT 模型基础上,用小得多的数据集进行有监督学习,获得了当时最好的成绩。
2018 年10月,Google 在 GPT 的基础上进一步改进,提出了基于 Transofrmer 的 BERT 模型。在训练 BERT 的过程中,Google 构造出 MLM(Masked Language Model)语言模型,这是一个“真”双向语言模型。并在通用的大规模语料 BooksCorpus(800M words)加上英文维基百科(2,500M words)上进行无监督训练,得到预训练模型 BERT。论文中,使用预训练的模型 BERT 在 11 个任务上进行有监督的微调(迁移学习),其效果全部达到当前最优。特别地,在斯坦福问答评测数据集(SQuAD 1.1)上超越了人类专家的评测结果。
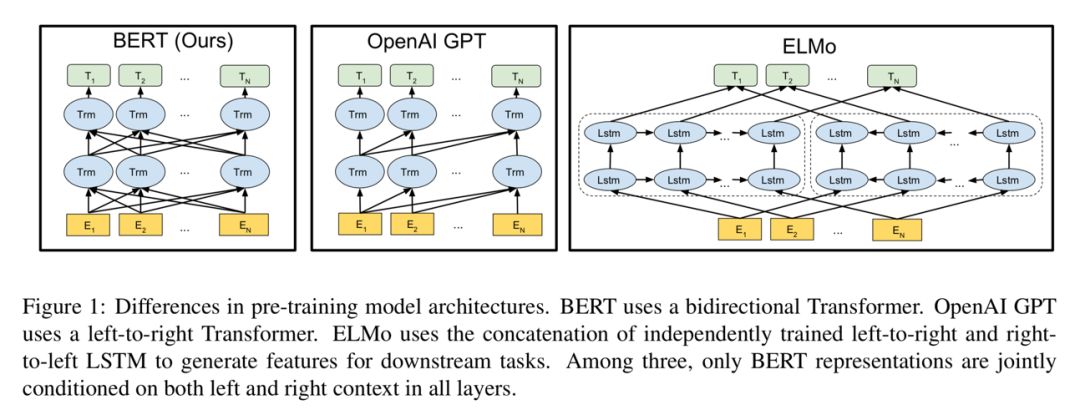
BERT、OpenAI GPT 和 ELMo 三个模型的示意图
BERT 的出现及其在多个任务上进行迁移学习所达到非常好的效果,证明了预训练模型和迁移学习的范式在NLP领域同样有效。这将在接下来的一段时间中,极大地促进 NLP 的发展。这是因为绝大多数场景都缺乏大量的标注语料,BERT 的成功使得人们看到了曙光。春江水暖鸭先知,也许可以说,NLP 的春天来了。
除了前面提到的迁移学习,其他迁移学习的方法也取得一些进展。比如对风格迁移的研究,多语言和跨语言的迁移学习等。除此之外,在知识图谱领域中,应用于实体、关系和事件抽取的迁移技术也有一定的进展。
NLP各个方向的进展多姿多彩
在 NLP 上的迁移学习之外,深度强化学习(Deep Reinforcement Learning, DRL)技术在 NLP 上的应用也表现出色。深度强化学习最耀眼的表现莫过于 Google 的 AlphaZero,通过完全舍弃人类经验,仅根据围棋规则构建深度强化学习模型,通过超级计算力进行学习,并最终打败了当前围棋界公认的最顶尖的大师柯洁。这证明了强化学习技术的能力非凡,多个团队将其在NLP领域进行了尝试。这些尝试包括使用 DRL 进行机器翻译,摘要生成、信息抽取、问答系统等,并都取得了非常不错的效果。
生成对抗网络(GAN)也是当前最热门的技术之一,今年在图像生成方面非进展非常大。特别值得一提的是,Deepmind 发布了 BigGAN 模型,该模型生成的图片非常的逼真,在 ImageNet 的评测集上从之前的最高分 52.52 提升到 66.3,效果的提升简直惨无人道。然而,GAN 在 NLP 领域所取的成绩则逊色很多。部分研究者使用 GAN 在信息抽取上获得不错的效果,在自然语言生成 NLG(包括摘要生成等)上有所进展,并且在机器翻译、词性标注等方面进行了一些尝试。
行业应用出现系统化和集约化
另外,同样重要的一方面是如何将这些成果应用于工业界,帮助企事业单位和科研研所等提升效率。而这也决定了资本是否能够持续投入,从而促使 AI 走向更强的认知智能。可喜的是,各行各业对 NLP 的接受越来越高,也越来越希望使用 NLP 技术帮助他们实现精耕细作和提升效率。
系统化体现在需要运用 NLP 方方面面的技术,甚至结合其他人工智能技术来实现业务的需求。从 NLP 传统应用领域—搜索说起。几乎可以说,现代 NLP 技术是伴随着搜索引擎的发展一起成长的。然而,此前,搜索系统上用到的 NLP 技术更多的是在字词层面上,而今年开始,专业的搜索几乎都要求句段以及篇章级别的搜索。
招聘领域是一个典型的场景,以往的搜索引擎都是根据 HR 提供的关键词进行简历搜索,而今年,达观智慧招聘提供的人岗匹配功能则是直接根据 JD(职位描述)来自动的从简历库里面搜索简历,实现篇章级的搜索功能,并在多个 10 万员工级别的企业实施,效果非常好。与此类似的场景还包括根据专利搜索相似专利,根据文档(比如 doc,pdf 等)搜索相似文档等等。除此之外,时至今年,问答式搜索几乎已经成为垂直搜索引擎的标配;与知识图谱结合实现推理性搜索也在部分领域(如金融、大型企业的信息管理、科研机构等)尝试中,未来可期。
与此同时,信息抽取技术也取得了极大的发展。像 DRL(深度强化学习)和 GAN(对抗生成网络)等技术被应用到实体和关系的抽取环节中,从而对知识图谱的构建起到较大的促进作用。目前工业界在行业知识图谱的构建中,基于规则的算法和基于模板的算法依然占据大多数,期待接下来能够促进这些技术进展在知识图谱中的广泛使用,实现知识工程的自动化,为认知智能的实现添砖加瓦。
文本的自动化审核,也开始逐步被市场接受。文档审核涉及多方面技术,是 AI 和 NLP 技术在工业界系统化应用的直接体现。其技术包括基于语言模型的错别字审核、通过信息抽取技术进行关键要素的精准抽取、基于领域词表或实体抽取审核要素完整性和一致性,以及基于前述信息之上构建布尔逻辑的审核。文本自动化审核应用非常广泛,像法务合同、金融类文档(如财报、股票发行说明书等)、新闻和公文等等。
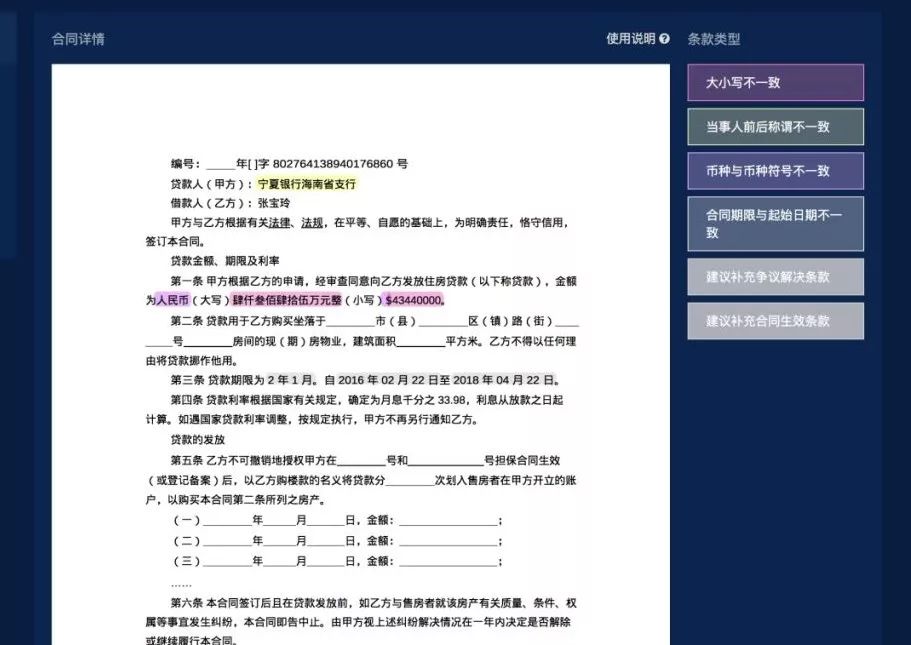
文档审阅系统(配图:达观数据)
前面提到的大多是从 NLP 的“读”(即 NLU)的层面的应用,与之相应的 NLG 方面则刚刚出现萌芽,大面积的应用还未出现,期待在接下里的一年里技术上能够有所突破,从而使得AI写作方面在工业界的应用能够全面开花。
目前,NLG 部分的应用主要体现在几个方面:部分公司在尝试使用 NLG 技术来进行新闻写作,从而实现部分新闻(如股市收评,体育快报等)的实时推送;部分技术领先的智能客服企业会使用NLG技术来生成问题的回答,从而实现更接近人的交互。今年 5 月份的 Google Assistant 的演示表现出来的惊艳的一幕,也有 NLG 的一份功劳。
除了应用多种技术来实现系统化的应用之外,集约化也是今年 NLP 领域的主题之一。“集约”原意是指农业上在同一土地面积上投入较多的生产资料和劳动,进行精耕细作,以提高单位面积产量从而来增加产品总量。这里是指将 NLP 技术应用于某个特定领域,从而提高生成效率。首先是司法方面,尝试使用 NLP 技术来帮助法院法官的审判。司法智能所要求能够深入理解长篇文档的内容,而这涉及到对大规模语料的训练以及将结果迁移到专业领域。而迁移学习在文本上的应用恰好在今年实现了突破,故而司法智能这类的领域应用则是水到渠成的。同样的应用还有科技情报、企业内部的知识管理,以及金融领域的监管智能等等。
从NLP迈向认知智能
今年 NLP 技术的突破可喜可贺,行业应用也全面开花。然而,NLP 的核心问题依然存在,主要体现在几个方面:
-
NLU 有待进一步突破,提高机器理解文字的能力,与人类进行更好地交互。
-
标注语料的积累;由于 NLP 的特点,与图像、语音领域相比,即便专家也很难做好语料标注,质与量的积累都是关键因素。
-
能效比有待提升;目前虽然很多模型效果不错,但其训练和预测过程所需时间很长,对计算力的要求非常高。
-
迁移学习研究与应用的还需更大的发展;可以更低成本地实现从通用到领域、从领域到通用的知识迁移;
-
亟待 NLG 技术的进一步发展;目前 NLG 方面的突破还乏善可陈。
-
期待知识工程和知识图谱领域的新进展与突破;如何自动、持续地构建更加全面的知识库是一个极大的挑战。
总的来说,从科研界到工业界再到资本市场的积极投入,人才也不断地积累,NLP 技术在未来几年会更加蓬勃发展,相信上面提到的这些问题在接下来的几年内会被逐步的解决。特别地,延续今年的突破,明年迁移学习在 NLP 的应用还会上一个台阶;NLG 方面今年已见曙光,期待明年在此方向有所突破。标注语料库、知识工程和知识图谱等概念已经深入产业的人心,这方面会持续积累,也许未来 3 到 5 年会实现量变到质变的变化。而这里面最难的当属能效比,可能需要从基础科学到芯片到 NLP 等各方面专家的努力,期待的是在未来 5 年能有所发展。
当这些问题在被逐步解决的时候,也是机器逐步实现认知智能的时候,从而实现在大部分场景下帮助人类解决文字处理相关的工作,让人类不用再加班,与机器的交互更加自然和谐,使得我们的生活更加美好。而 NLP 人工作的点点滴滴,最终都会汇聚在这条美好的生活的大江中。“合抱之木,生于毫末”,对于 NLP 来说,我们不断在成长,苍天大树即将长成,认知智能咫尺可期。
作者简介:王文广 达观数据副总裁
在人工智能领域和系统架构设计上有十余年工作经验,浙江大学计算机硕士。曾担任金融 AI 公司 Kavout 首席架构师,将人工智能和自然语言处理技术应用于金融、证券、量化交易等领域,效果得到美国大型基金公司认可。曾负责盛大创新院搜索、推荐、广告等多个项目的架构设计工作,所设计和开发的系统具备海量数据的快速处理和高度智能的挖掘能力,多次获得嘉奖。早期在百度负责 MP3 搜索、语音识别与搜索和音频指纹等系统的核心研发。
--【完】--
2018 AI开发者大会
AI技术年度盛会即将开启!11月8-9日,来自Google、Amazon、微软、Facebook、LinkedIn、阿里巴巴、百度、腾讯、美团、京东、小米、字节跳动、滴滴、商汤、旷视、思必驰、第四范式、云知声等企业的技术大咖将带来工业界AI应用的最新思维。
如果你是某个AI技术领域的专业人才,或想寻求将AI技术整合至传统企业业务当中,扫码填写大会注册信息表,我们将从中挑选出20名相关性最高的幸运读者,送出单场分论坛入场券。大会嘉宾阵容和议题,请查看文末海报。

此外,如果你想与所有参会大牛充分交流沟通,点击阅读原文购票,使用优惠码:AI2018-DBY 购买两日通票,立减999元;此外大会还推出了1024定制票,主会+分会自由组合,精彩随心。


