
- 1JDK8新特性之Lambda表达式_jdk8 lamda
- 2Kafka之ISR机制的理解
- 3MCK主机加固:智能科技,构筑网络安全的铜墙铁壁
- 4win系统的Git安装及配置_git环境变量配置win11
- 5机器学习系列15-半监督学习_low density separation assumption
- 6【论文泛读】 知识蒸馏:Distilling the knowledge in a neural network
- 7在Linux编写程序arm程序,通过usb烧写在Android系统中安装和运行C程序_linuxarmc语言通过usb下载视频流代码
- 8大数据开发---阿里云ECS上搭建Hadoop伪分布式环境(下篇)_阿里云伪分布式hadoop集群搭建过程
- 9seetaface 使用总结_seetaface是中科院的吗
- 10思科模拟器OSPF V2配置_思科ospfv2
AI强化学习正渗入“更高级学科”,比如心理学!
赞
踩

全文共2359字,预计学习时长5分钟

图片来源:pexels.com/@pixabay
最近,拉斯维加斯举行了AWSre: MARS大会,会议的主题是机器学习、自动化和机器人技术(包括太空中的)将如何改变未来。很多人的关注点都放到了小罗伯特·唐尼身上,但其实,几乎每一个主题演讲会议上都出现的模拟和强化学习才是最瞩目的:
第一天:通过强化学习,Boston Dynamics公司的机器人已经掌握了后空翻、跳上窗台和托举的数据。而迪斯尼幻想工程已经把这一点带到了一个新的层面——让人形机器人来执行玩命的特技。
第二天:亚马逊通过模拟在Go商店中的困难场景来训练模型机。亚马逊配送中心的机器人在接受过强化学习的培训后还可以对包裹进行分类。Alexa使用模拟交互自动学习对话流。亚马逊无人机快递使用模拟数据来训练如何检测无人机下方的人。而像Insitro这样的公司已经开始通过生成生物交互数据来解决生物医学问题。
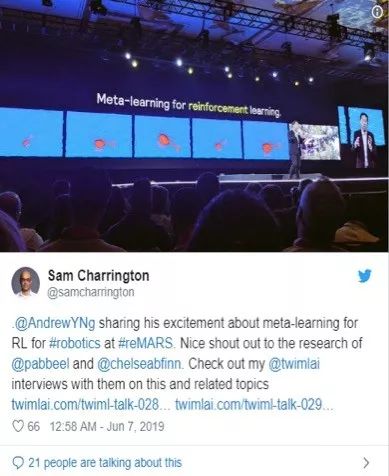
第三天:吴恩达呼吁元学习。成百上千的不同的模拟器被用来建立更通用的强化学习代理,这可以说是AI的“下一件大事”。自动驾驶汽车公司Zoox和Aurora就在利用RL和元学习以解决城市环境中驾驶的复杂性的问题。而Dexnet试图通过模拟建造一个庞大的3D模型数据库,以更好的掌握问题所在。Jeff Bezos对Daphne Koller关于RL生物工程将在10年内发展壮大的观点表示赞同。
总而言之:
如若一个领域的相关事务可以被准确地模拟,强化学习将能够在未来的几年急剧地抬升此领域的技术水平。
那么又关物理什么事呢?
一个4岁的孩子,进入了人生中的“为什么”阶段,这个时候她的大脑开始从简单的认知事物转移成了想要理解这个世界的所有东西。这就是大人和孩子之间典型的交流:

绘制使用http://cmx.io
那这些又和数据科学有什么关系呢?
Jeff Dean在今年谷歌I/O会议上发表关于深度学习的演讲时提到,神经网络已经被训练得近似物理模拟器所能生成的结果,并且速度是物理模拟器的30万倍,也就是说,研究人员甚至可能一顿午餐的时间就测试了100M的分子。
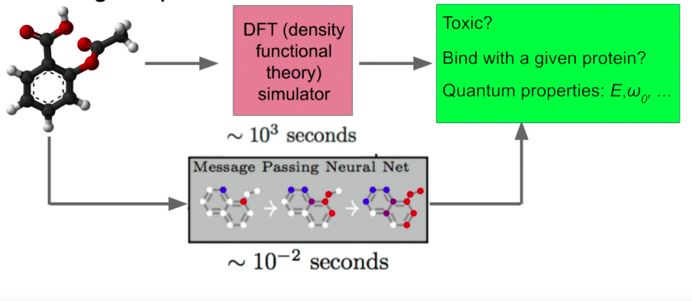
图片来源: Jeff Dean在谷歌 I/O 2019的演讲
这是一个巨大的进步,因为它允许我们使用re: MARS上引人瞩目的强化学习来解决新的各种问题。在这些进步之前,为每个潜在的结果完整运行一个物理模拟器所需的循环时间太长,以至于RL很难达成一个有回报的结果。但现在,RL可以学习分子的物理特性,从而优化化学工程师的预期收获。

图片来源:https://xkcd.com/435/
鉴于一切都可以被简化为物理学,我们甚至可以想象一个能以最基础的原理建立更多方案的世界。在这个会议之前,很多人都以为模拟生物学相关的研究是遥不可及的,但事实上,Insitro这样的公司已经着手应对这些问题。
那时RL将可用于“更高级别的”科学,如心理学:
1. 原始计算能力:谷歌发布了T3 TPU Pods的私有数据,拥有超过100的每秒浮点运算次数的处理能力,为运行神经网络训练构架而造。拥有这样的计算能力后,像材质分析这类的任务就变得十分易学。另外,谷歌开始使用RL设计他们自己的芯片,随着时间的推移也预期能够带来更多的进展。
2. 更优良的可重用性:DeepMind被用于多层网络构架中,而RL负责根据任务需要选择合适的下游网络。这类的RL代理通过训练就可以把高难的任务通过分解的方式简单化,并运用迁移学习解决多任务。
3. 更好的归纳:上述的元学习技术正被用于提高RL代理应对未遇到过的情景的能力。
4. 更好的优化:麻省理工学院的彩票假设论文展示了神经网络可以通过寻找“优胜票”的路径来进行进一步压缩,随后仅使用这些路径来进行训练。
5. 更好的训练数据生成:类似AutoCad的生成设计的界面可以帮助设计师/工程师找到所需的规格,以使RL代理正确运行。每次新的人接管时,自动驾驶汽车公司都会生成新的训练情景。
你又该做些什么呢?
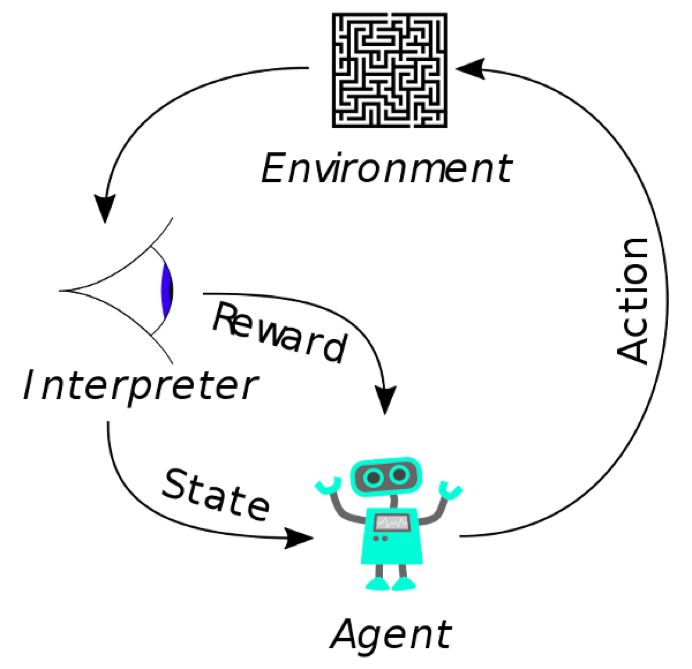
图片来源:
https://en.wikipedia.org/wiki/Reinforcement_learning#/media/File:Reinforcement_learning_diagram.svg
首先,你需要去了解强化学习,这里简明扼要地介绍了RL代理获取情景状态,选择一个行动影响环境,观察新的情景,重复步骤。如果行动得到了积极的结果,代理得到奖励,它就倾向于在将来类似的情景中给出相同的一系列动作。
这些步骤被大量重复,最终,它变得十分擅长获得奖励(我们也为此训练它)。丰富经验的最好办法就是使用AWS Deep Racer,这是一个可以提供模拟环境的缩小版的赛车、一个RL训练装置,以及一块与模拟相对应的物理硬件。你只需要调控奖励机制来训练你的赛车代理。
图片来源:
https://www.semanticscholar.org/paper/OpenAI-Gym-Brockman-Cheung/2b10281297ee001a9f3f4ea1aa9bea6b638c27df/figure/0
其次,你需要积极寻找可以更好模拟业务系统的方法。任何现有的模拟器都是很好的起点,但更新的模拟器更可能带来显著的影响。AWS在这类领域中提供名为“RoboMaker”的服务,但还有许多其他的备选方案,而其中大多数都基于开放式API Gym。
最后,应当密切关注那些驾驭这股技术潮流的新公司。很可能最终会发展出一系列互相构建的开放资源模拟器,附带压缩每层可学习的信息的神经网络。在此之前,有众多领域可能会有许多专有的解决方案超越当前最先进的水平。随着时间推移,这项技术终将给以科学为基础的领域带来可观的收益,例如药物、材料科学、医学、石油与天然气,及各种各样的其他领域。

AI未来说*青年学术论坛 火热报名中

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:赵明琦、牟钰莹
相关链接:
https://towardsdatascience.com/reinforcement-learning-is-going-mainstream-heres-what-to-expect-d0fa4c8c30cf
如需转载,请后台留言,遵守转载规范
推荐文章阅读
长按识别二维码可添加关注
读芯君爱你


