
- 1web前端微服务设计:深入剖析与实践
- 2ArrayList的操作_arraylist有顺序吗
- 3SQL Server中的查询_sqlserver查询第1行
- 4阿里云使用笔记(一):从零开始配置阿里云GPU服务器训练深度学习模型_用阿里云gpu跑算法
- 5最短路dijkstra算法详解_L3图论第04课 最短路Dijkstra算法
- 6EAP设备自动化系统基本功能与概念_eap系统基于scada
- 7IDEA Copilot1.1.26.1691版本提示Your Copilot experience is not fully configured, complete your setup._your current copilot license doesn't support proxy
- 8Mysql安装_mysql 安装
- 9【毕业设计】18-基于单片机的数字直流电源设计(源代码工程+仿真工程+答辩论文+答辩PPT)_单片机 数字电源
- 10Springboot启动时报端口被占用_springboot 只占用tcp端口
2. 机器学习概述
赞
踩
机器学习是对能通过经验自动改进的计算机算法的研究。 ---汤姆. 米切尔 1997
通俗来讲,机器学习就是让计算机从数据中进行自动学习,得到某种知识(或规律)。在早期的工程领域,机器学习也经常被称为模式识别(Pattern Recognition), 但模式识别更偏向于具体的应用任务,比如语音识别,字符识别,人脸识别等。现在机器学习的概念已经逐渐替代模式识别。
假设我们要训练一个芒果分类的机器学习模型,首先我们列出每个芒果的特征(feature),包括颜色,大小,形状,产地,品牌等,以及我们需要预测的标签(label)。标签可以是连续值也可以是离散值。一个标记好特征以及标签的芒果可以看作是一个样本(sample).一组样本构成的集合称为数据集(data set)。一般将数据集分为两部分:训练集和测试集。我们通产公用一个D维向量x = [x1,x2,x3...,xd]T表示一个芒果的所有特征构成的向量,称为特征向量,其中每一维代表一个特征。而芒果的标签通常用标量y来表示。下面是机器学习学习系统的示例。
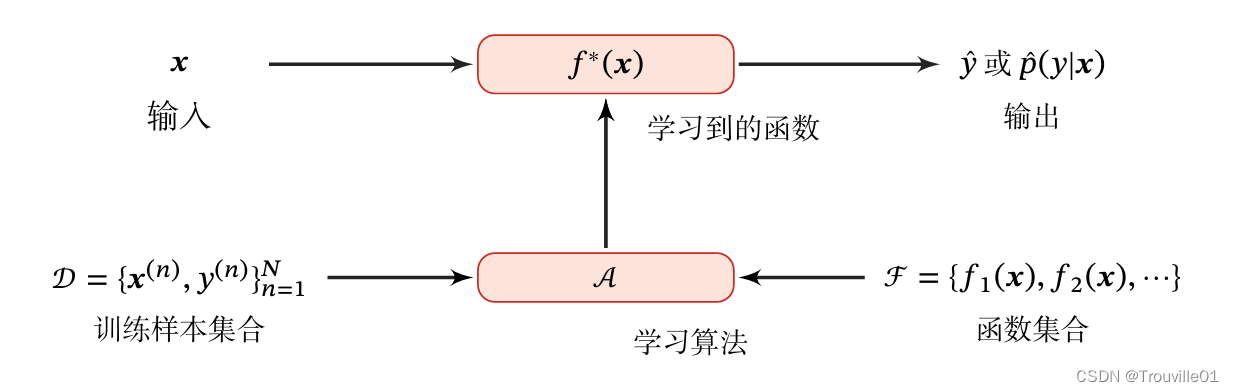
机器学习可以粗略地分为三个基本要素:模型,学习准则,优化算法。
一. 模型
1.1 线性模型
线性模型的假设空间为一个参数化的线性函数族,即:
其中参数 权重向量w和偏置b。
1.2 非线性模型
广义的非线性模型可以写为多个非线性基函数的线性组合
其中为K个非线性基函数组成的向量,参数
包含了权重向量
和偏置
。
二. 学习准则
模型的好坏可以通过期望风险
来衡量,它的定义是:
![]()
其中为真实的数据分布,
为损失函数,用来量化两个变量之间的差异。
2.1 损失函数
损失函数是一种非负实数函数,用来量化模型预测和真实标签之间的差异。几种常用的损失函数如下:
2.1.1 0-1损失函数:最直观的损失函数是模型在训练集上的错误率。
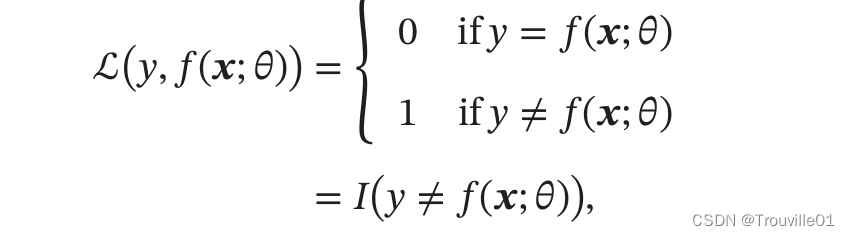
其中是指示函数。虽然0-1损失函数可以客观评价模型的好坏,但其缺点是数学性质不太好,不连续且导数为0,难以优化。因此常用连续可微的损失函数替代。
2.1.2 平方损失函数: 经常用在预测标签为实数值的任务中,定义为:
![]()
平方损失函数一般不适用于分类问题。
2.1.3 交叉熵损失函数:一般用于分类问题。


2.1.4 Hinge 损失函数: 对于二分类问题

2.1.5 风险最小化准则: 一个好的模型应当有一个比较小的期望错误,但由于不知道真实的数据分布和映射函数,实际上无法计算其期望风险
.给定一个训练集,我们可以计算的是经验风险。因此一个切实可行的学习准则是找到一组参数
使得经验风险最小。这就是经验风险最小化准则。
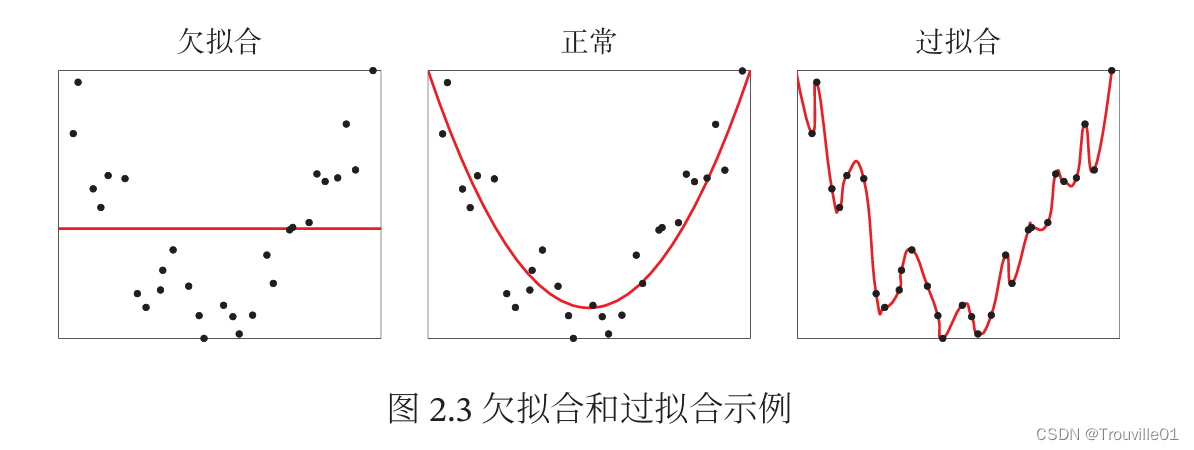
2.1.6 过拟合:根据大数定理可知,当训练集大小||趋向于无穷大时,经验风险就趋向于期望风险。然而通常情况下,我们无法获取无限的训练样本,并且训练样本往往是真实数据的一个很小的子集或者包含一定的噪声数据,不能很好地反映全部数据的真实分布。经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高。这就是所谓的过拟合(Overfitting).
过拟合问题往往是因为训练数据少以及模型能力强等原因造成的。为了解决过拟合问题,一般是在经验风险最小化准则的基础上引入参数的正则化来限制模型能力,使其不要过度地最小化经验风险。这种准则就是结构风险最小化准则。
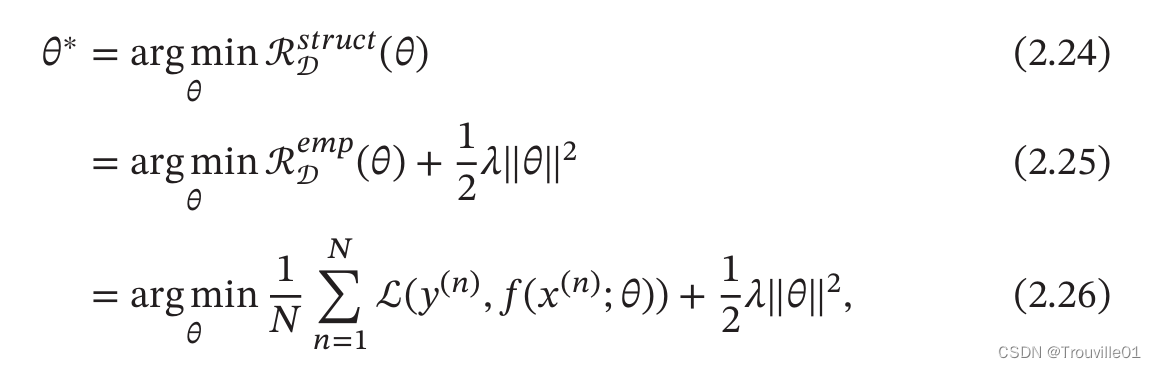
其中|||| 是
范数的正则化项,用来减少参数空间,避免过拟合;
用来控制正则化的强度。
正则化项也可以使用其他函数,L1范数的引入通常会使得参数有一定稀疏性,因此在很多算法中也经常使用。和过拟合相反的一个概念是欠拟合,即模型不能很好的拟合训练数据,在训练集的错误率比较高。欠拟合一般是由于模型能力不足造成的。
总之,机器学习的学习准则并不仅仅是拟合训练集上的数据,同时也要使泛化错误最低。因此机器学习可以看作使一个从有限,高维,有噪声的数据上得到更一般性规律的泛化问题。
三. 优化算法
3.1 参数与超参数:在机器学习过程中,优化可以分为参数优化和超参数优化。 模型f( 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

