
热门标签
热门文章
- 1算法随笔:Floyd_floyd算法 力扣
- 2【vueUse库Reactivity模块各函数简介及使用方法--下篇】
- 3GCN/GNN_gcn输出
- 4Docker-An unexpected error occurred_docker an unexpected error occurred
- 5苹果iPhone一键解锁破解流程(新机篇)_iphone js代码解锁
- 6基于Javaweb的网上订餐系统的设计与实现(完整程序+数据库+开题报告+任务书+论文)_完整的javaweb订餐系统
- 7RabbitMQ启动出现的问题与解决办法_runuser user rabbitmq does not exits
- 8轻松上手 LangChain 开发框架之 Agent 技术 !!
- 9推荐开源项目:ProtonVPN Linux CLI - 强大的Linux终端下安全浏览工具
- 10Java版Flink使用指南——定制RabbitMQ数据源的序列化器
当前位置: article > 正文
基于Python 爬书旗网小说数据并可视化,通过js逆向对抗网站反爬,想爬啥就爬啥_网络小说网站反爬虫
作者:酷酷是懒虫 | 2024-07-11 09:55:00
赞
踩
网络小说网站反爬虫
目标:
基于Python的书旗网小说网站的数据采集与分析的目标是通过自动化程序收集书旗网上的小说相关数据,并对这些数据进行分析和处理,以获取有价值的信息和洞察。具体目标包括以下几个方面,首先利用Python编写网络爬虫程序,从书旗网上抓取小说的标题、作者、分类、评分、阅读量等信息,对采集到的数据进行清洗和整理,去除重复、错误或无效的数据,然后将清洗后的数据存储到数据库或文件中,以备后续分析使用。利用Python的数据分析工具,如Pandas、NumPy等,对采集到的数据进行统计分析、可视化和挖掘,分析小说的热门分类、作者的作品数量分布、读者评分情况等,揭示用户喜好和趋势。通过对书旗网上小说市场的数据进行分析,如同类小说的数量、观看量等,了解竞争对手的情况,为制定市场策略和推广活动提供依据。
爬虫过程:
通过分析网页中的JavaScript代码,了解网站的加密和反爬机制,使用Python的相关库(如PyExecJS)模拟执行JavaScript代码,绕过反爬机制,获取所需数据。使用requests库发送HTTP请求:利用Python的requests库发送GET或POST请求,携带相应的URL、参数和请求头信息,模拟浏览器行为,获取整个网页的内容。对于返回的网页内容,如果是JSON格式的数据,可以使用Python内置的json库解析和提取所需的数据字段,将其转化为Python的数据结构,如字典、列表等。具体如下:
1、确定网页URL

2、寻找规律,发现有反爬,其中timestamp用到13位的时间序列,只要转换就可以发现这个数是当前电脑的点击时间,而最难的则是sign,这个数据一直在变化,所以得找到sign对应的js,对这个数据进行逆向,找到规律。
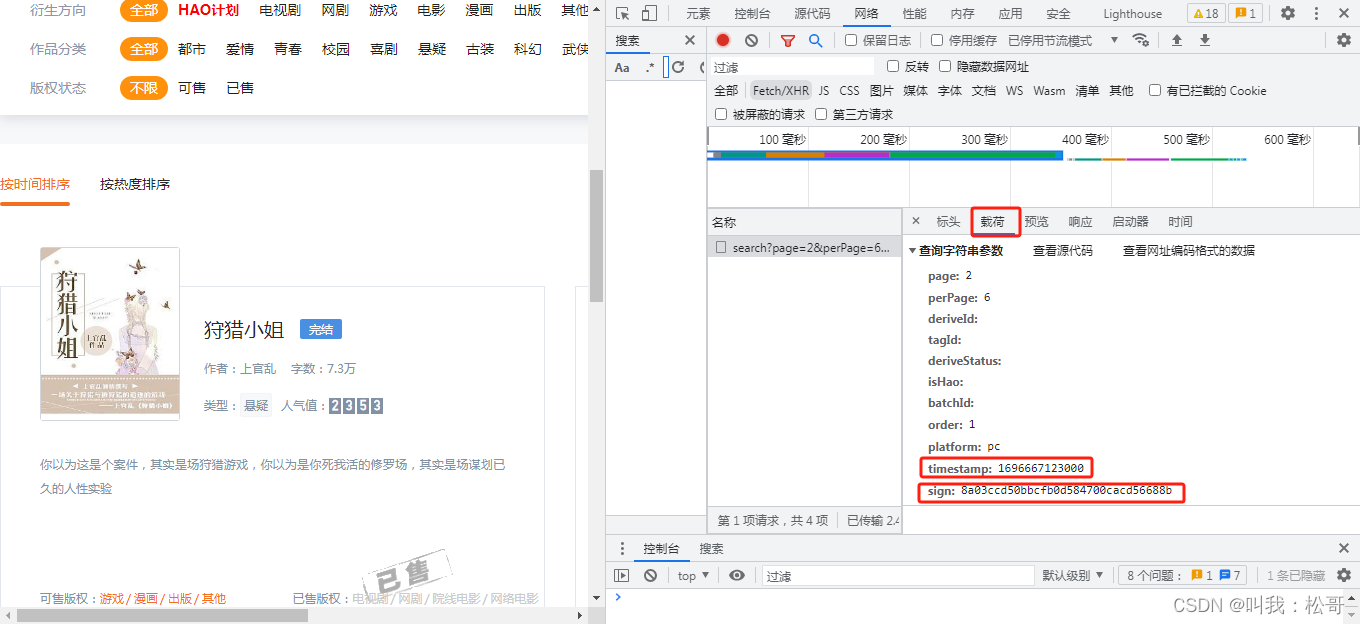
3、定位js,分析js进行逆向

通过分析发现sign的值是经过这个组合生成的:
'1'+页码+'6'+'pc'+当前时间的序列数据+'000'+'MJWLLtDX9kXAHY3EIP8hNvVLiA5qsD8A'
所以只需要通过复制sign的js文件,就能生成所需的sign值,通过PyExecJS库将js文件运行即可。
主要代码如下:
data_m = open('MD5.js', 'r', encoding='utf-8').read()
data_z = js2py.eval_js(data_m)
sign_n='1'+str(j+1)+'6'+'pc'+str(int(time.time()))+'000'+'MJWLLtDX9kXAHY3EIP8hNvVLiA5qsD8A'
print(sign_n)
最后将采集到的数据存储为MySQL。爬虫代码如下:
def shuqi(shu):
url='https://jognv1.shuqireader.com/copyright/search?page={}&perPage=6&deriveId=&tagId=&deriveStatus=&isHao=&batchId=&order=1&platform=pc×tamp={}&sign='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.47'
}
for j in range(35,shu):
data_m = open('MD5.js', 'r', encoding='utf-8').read()
data_z = js2py.eval_js(data_m)
sign_n='1'+str(j+1)+'6'+'pc'+str(int(time.time()))+'000'+'MJWLLtDX9kXAHY3EIP8hNvVLiA5qsD8A'
print(sign_n)
url1=url.format(str(j+1),str(int(time.time()))+'000')+data_z(sign_n)
print(url1)
print(data_z(sign_n))
res=requests.get(url.format(str(j+1),str(int(time.time()))+'000')+data_z(sign_n),headers=headers).json()
soup=res['data']['bookList']
for book_list in soup:
list0=[]
name=book_list['bookName']
author=book_list['authorName']
num=book_list['wordNum']
type=book_list['copyrightTags']
type0=''
for t in type:
type0+=t['name']+' '
hot=book_list['hotScore']
save_type=book_list['derives']['sell']
save_type0=''
for d in save_type:
save_type0 += d['name'] + ' '
sell_out=book_list['derives']['sellOut']
sell_out0=''
for s in sell_out:
sell_out0 += s['name'] + ' '
zhuangtai=book_list['state']
list0.append(name)
list0.append(author)
list0.append(num)
list0.append(type0)
list0.append(hot)
list0.append(save_type0)
list0.append(sell_out0)
list0.append(zhuangtai)
print(list0)
cun(list0)
time.sleep(random.randint(2,4))
if __name__ == '__main__':
shuqi(40)
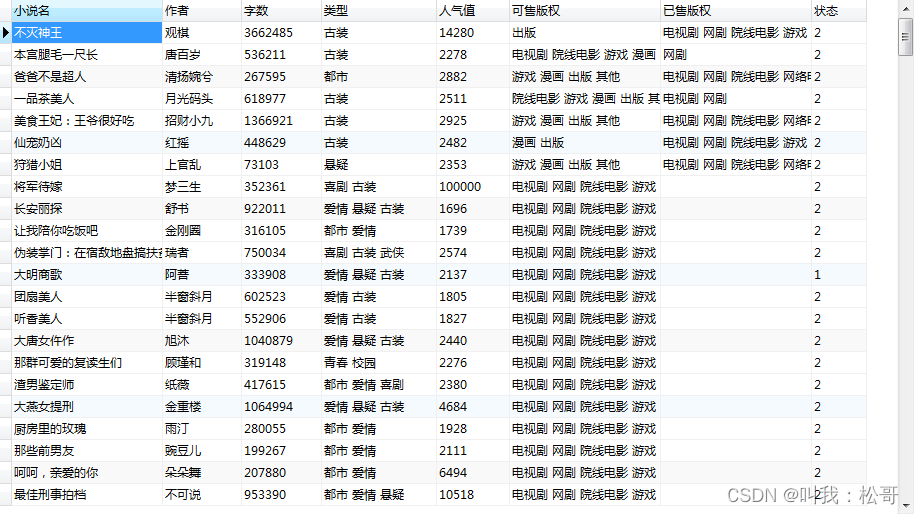
爬取效果:
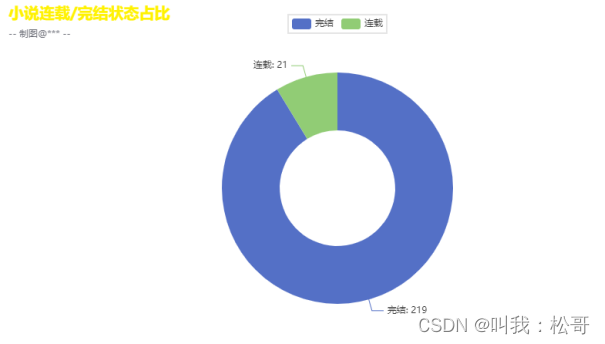
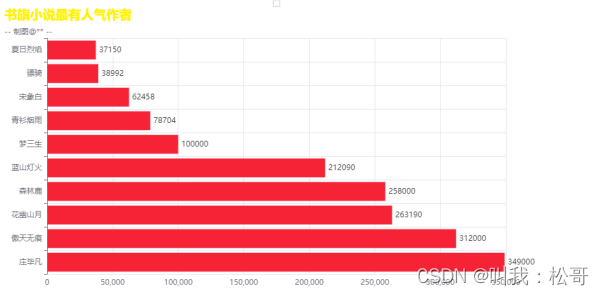
可视化代码就省略了,想要的可以联系我,这里是可视化效果:



声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/809570
推荐阅读
相关标签

