
- 1基于Matlab的简单小车路径规划及控制Demo_matlab模拟小车轨迹规划程序
- 2HumanPlus——斯坦福ALOHA团队开源的人形机器人:融合影子学习技术、RL、模仿学习
- 3复杂度——时间复杂度_时间复杂度题目
- 4前端 JS 经典:迭代器
- 5Git 入门_猴子都能懂的git
- 6自定义地图障碍物,Matlab实现A星路径规划算法,灵活起终点坐标_a星算法自定义地图,matlab
- 7Postman 汉化 中文版_postman汉化包
- 8吐血整理的Google Guava
- 9Tomcat与JDK各版本的兼容性_tomcat9.0和jdk1.8兼容吗
- 10培训班出来的人后来都怎么样了?(五)_培训完什么也不会
如何在OrangePi AIpro智能小车上实现安全强化学习算法_orangepi pytorch
赞
踩
随着人工智能和智能移动机器人的广泛应用,智能机器人的安全性和高效性问题受到了广泛关注。在实际应用中,智能小车需要在复杂的环境中自主导航和决策,这对算法的安全性和可靠性提出了很高的要求。传统的强化学习算法在处理安全约束时存在一定的局限性,引入安全强化学习算法成为了解决这一问题的有效途径。安全强化学习算法通过在强化学习过程中引入安全约束,确保在训练和实际应用中系统的行为始终在安全范围内。这对于智能小车在无人监督的情况下自主运行尤为重要。本文将介绍如何在OrangePi AIpro智能小车上实现安全强化学习算法,详细探讨硬件和软件的配置、算法的设计与实现、实验设置与结果分析等内容,以期为相关研究提供参考和借鉴。
一、OrangePi AIpro开发板
由于强化学习算法对计算能力有着极高的要求,一般的开发板难以满足其算力需求。经过对比众多开发板的性能,最终选用了OrangePi AIpro作为系统的主控,用于部署安全强化学习算法。OrangePi AIpro是一款高性能的开发板,专为AI和IoT应用设计。搭载了4核64位处理器和强大的AI处理器,支持8TOPS的AI算力。具备8GB或16GB LPDDR4X内存和可扩展的32GB至256GB eMMC存储。板载多种高速接口,包括双HDMI 2.0输出、两个USB 3.0端口、一个Type-C 3.0端口以及支持SATA/NVMe SSD的M.2接口,适合进行大容量数据处理和快速读写。此外,它还提供了丰富的连接选项,如千兆以太网、多种MIPI接口用于摄像头和显示屏,以及预留的电池接口,使其非常适合用于边缘计算、深度学习、视频分析、自然语言处理等多种AI应用场景。OrangePi AIpro支持Ubuntu和openEuler操作系统,配备MindStudio全流程开发工具链,实现简化的开发和模型适配,适用于从AI教学到企业级应用的广泛场景。下图为OrangePi AIpro硬件的详细图。

本文将详细介绍如何在OrangePi AIpro智能小车上部署强化学习算法,并测试OrangePi AIpro开发板的性能。通过实际应用场景中的实验,评估其在高计算需求任务中的表现,以及其在处理复杂导航和决策任务时的效率和可靠性。
二、安全强化学习
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过智能体与环境的交互,学习如何在不同情况下采取行动,以最大化某种累积奖励。强化学习广泛应用于机器人运动控制、自动驾驶等领域。在运动控制任务中,基于强化学习的智能体能够根据环境变化调整策略,以完成复杂的场景任务,并可以直接从数据中学习策略降低控制系统的设计成本。然而,由于在策略训练过程中强化学习算法可能会探索危险动作,对机器人的安全性构成潜在威胁,并且随着训练周期的增加,反复试验可能会对机器人的运动性能和使用寿命造成损害。因此,为确保运动体在训练策略和实现目标过程中的安全,安全强化学习算法被提出。
安全强化学习通过结合传统强化学习框架与先进的安全约束策略,致力于增强智能体在复杂环境中的表现与安全性。这些技术主要包括状态约束、安全层和恢复策略等,用以确保在执行任务时,智能体不仅能达成预设目标,同时也能避免对自身及环境造成潜在的危害。通过引入如状态约束,可以限制智能体的行为在安全的状态空间内进行;安全层则通过覆盖或修改原有的行为策略来防止危险行为的发生;恢复策略则在智能体偏离安全路径时提供了必要的干预手段。这些方法的综合应用显著提升了强化学习算法在实际应用中的可靠性和安全性。下图为状态约束下安全强化学习的算法框架。
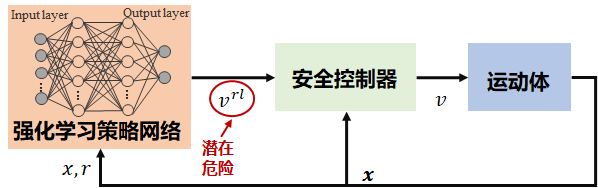
三、OrangePi AIpro智能小车的硬件和软件配置
3.1 硬件
OrangePi AIpro智能小车总体硬件图:

全向移动小车的运动控制是整个实验系统的关键技术之一,它能实现全向移动小车的避障、跟踪等功能。为了保证运动体的安全性和跟踪性,需要通过运动控制器控制四个麦克纳姆轮的的转速和转向,可以控制全向移动小车沿任意方向平移或旋转,从而使小车能够跟踪其安全控制指令。
根据运动控制的硬件配置,选择了嵌入式芯片STM32F407作为运动控制器。为了开发运动控制相关的程序,使用了keil开发环境,并编写了uart串口通信协议来接收安全控制量。由于数据传输过程中可能会出现误码或数据丢失的情况,为了保证数据传输的可靠性和准确性,采用了首尾检验的方法来确保数据的完整性和正确性。接收到安全控制量(Vx,Vy,Yaw)后,不能直接用于电机的控制,需要根据全向移动小车的逆运动学模型,将安全控制量解算为四个轮子的转速。在运动控制器内部,我们使用了PI控制算法对轮子的转速进行闭环控制。同时,为了方便调节PI控制器的参数,使用了Matlab/Simulink系统工具箱。首先,采集全向移动小车的输入和输出数据,并通过系统辨识方法得到了以状态空间表达式呈现的动力学模型。其次,针对该全向移动小车的动力学模型,并根据系统的调节时间和鲁棒性的性能指标,设计了PI控制器的相关参数,实现了全向移动小车能够精确跟踪安全控制量。
3.2 软件环境配置
3.2.1 连接OrangePi AIpro
开机显示页面如下,连接wifi

3.2.2 ssh连接
为了方便配置环境及进行文件传输,使用ssh连接OrangePi AIpro进行环境配置
连接成功

3.2.3 配置运行环境
创建环境
conda create -n srl python=3.8
- 1
安装依赖环境
pip install torch==1.10.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pybullet==3.2.6 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install gym==0.25.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install cvxopt==1.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install qpth -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
- 3
- 4
- 5
- 6
安装cvxopt报错
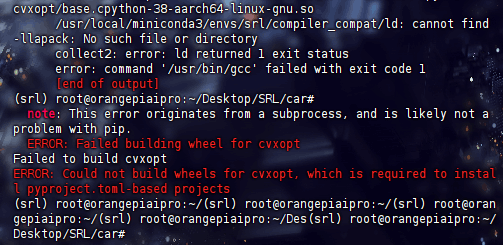
在尝试构建 cvxopt 时,链接器无法找到 llapack 库。
安装 lapack 和 blas 库
sudo apt-get install liblapack-dev libblas-dev
- 1
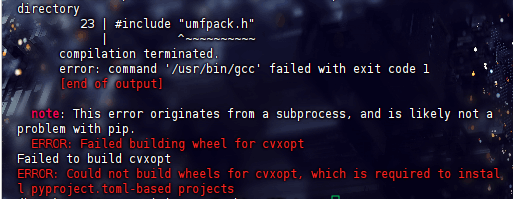
表明在编译 cvxopt 时,找不到 umfpack.h 头文件。umfpack.h 是 SuiteSparse 库的一部分,需要安装该库才能解决这个问题
安装 SuiteSparse 库
sudo apt-get install libsuitesparse-dev
export SUITESPARSE_INCLUDE_DIR=/usr/include/suitesparse
export SUITESPARSE_LIBRARY_DIR=/usr/lib
pip install --no-cache-dir --no-binary :all: cvxopt
- 1
- 2
- 3
- 4
四、安全强化学习算法的设计与实现
强化学习 (RL) 的重点是寻找一个的最优得策略, 以获得最大化的长期回报。它通过反 复观察智能体的状态、采取行动, 并获得奖励来反复优化策略以获得最佳策略。该方法已 成功应用于连续控制任务, 其中多次策略迭代得策略已学会稳定复杂机器人。然而, 由于RL专注于最大化长期奖励, 它很可能在学习过程中探索不安全的行为。这个特性是有问题 的尤其对于将部署在硬件上的 RL 算法, 因为不安全的学习策略可能会损坏硬件或给人类 带来伤害。本文是将现有的无模型 RL 算法(DDPG)与控制障碍函数 (CBF) 集成, 在稀疏 奖励下完成运动体的安全控制, 提高学习过程中的探索效率。
由于控制障碍函数具有强约束性的特点, 将强化学习策略探索过程中的动作输出作为标称控制器的输出, 即控制障碍函数的输入, 以保证探索过程中的实时安全, 其与环境交互的原理如图:
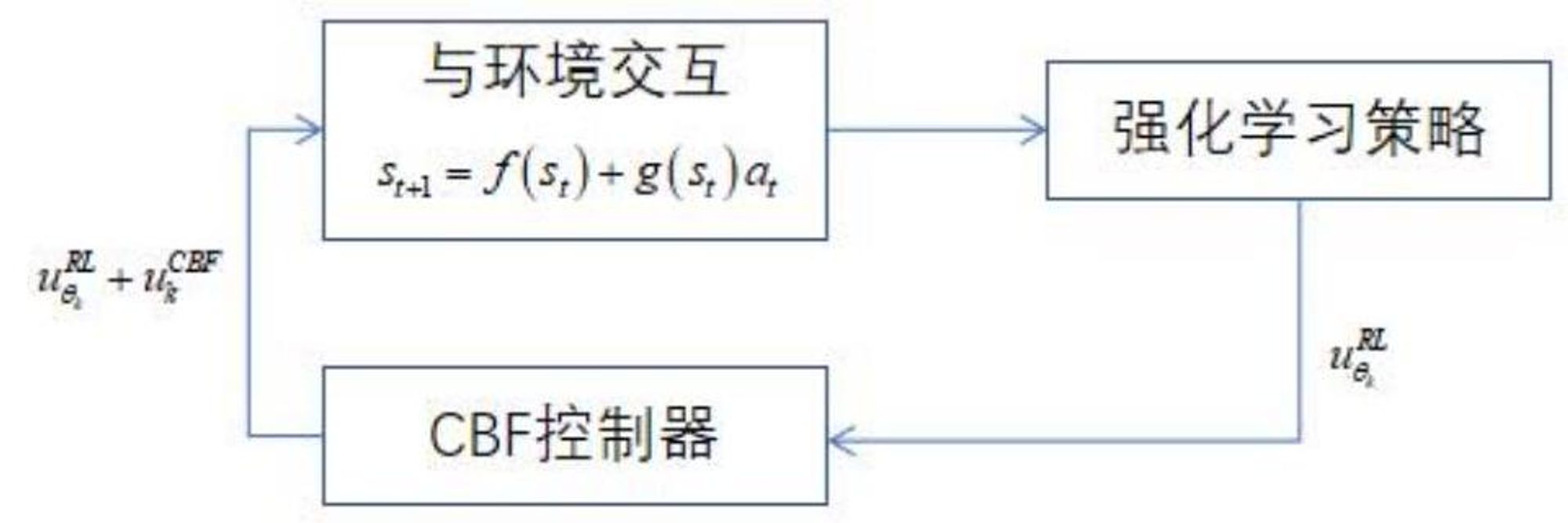
运动体执行的动作为:
在无模型强化学习的策略探索中, $u_{\theta_{k}}^{R L}(s)$ 给出了一个动作, 试图优化长期奖励, 但可能是不安全的。CBF控制器 $u_{k}^{C B F}\left(s, u_{\theta_{k}}^{R L}\right)$ 过滤掉强化学习动作中不安全的行为, 并提供最小的控制干预, 以确保总体控制器 $u_{k}(s)$安全, 同时使系统状态保持在安全集内。
CBF控制器的输出 $u_{k}^{C B F}\left(s, u_{\theta_{k}}^{R L}\right)$ 由以下公式在每个时间步长进行一次规划求解得出:
其中 $a_{\mathrm{low}}^{i} \leq a_{t}^{i}+u_{\theta_{k}}^{R L(i)}\left(s_{t}\right) \leq a_{\mathrm{high}}^{i}$ 对输出的限幅, 在实际控制对象中, 执行器的动作空间有限, 将动作界限做为二次规划的约束条件, 其输出结果就是在界限内的安全动作, 保证运动体的安全。
五、实验和结果
仿真实验
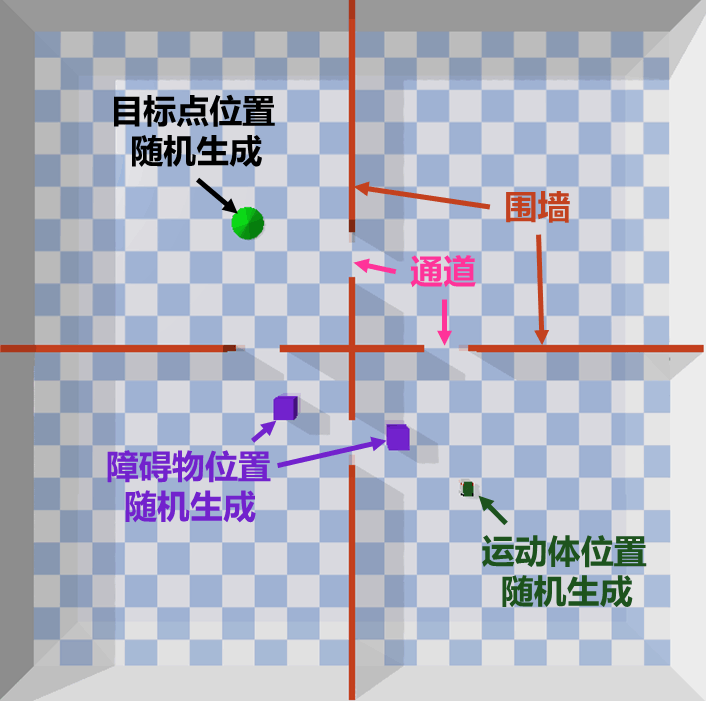
为了验证安全强化控制算法, 在如下的环境中进行安全控制实验, 运动体 (四轮小车) 需要绕过紫色障碍, 安全到达绿色区域即可获得相应奖励。
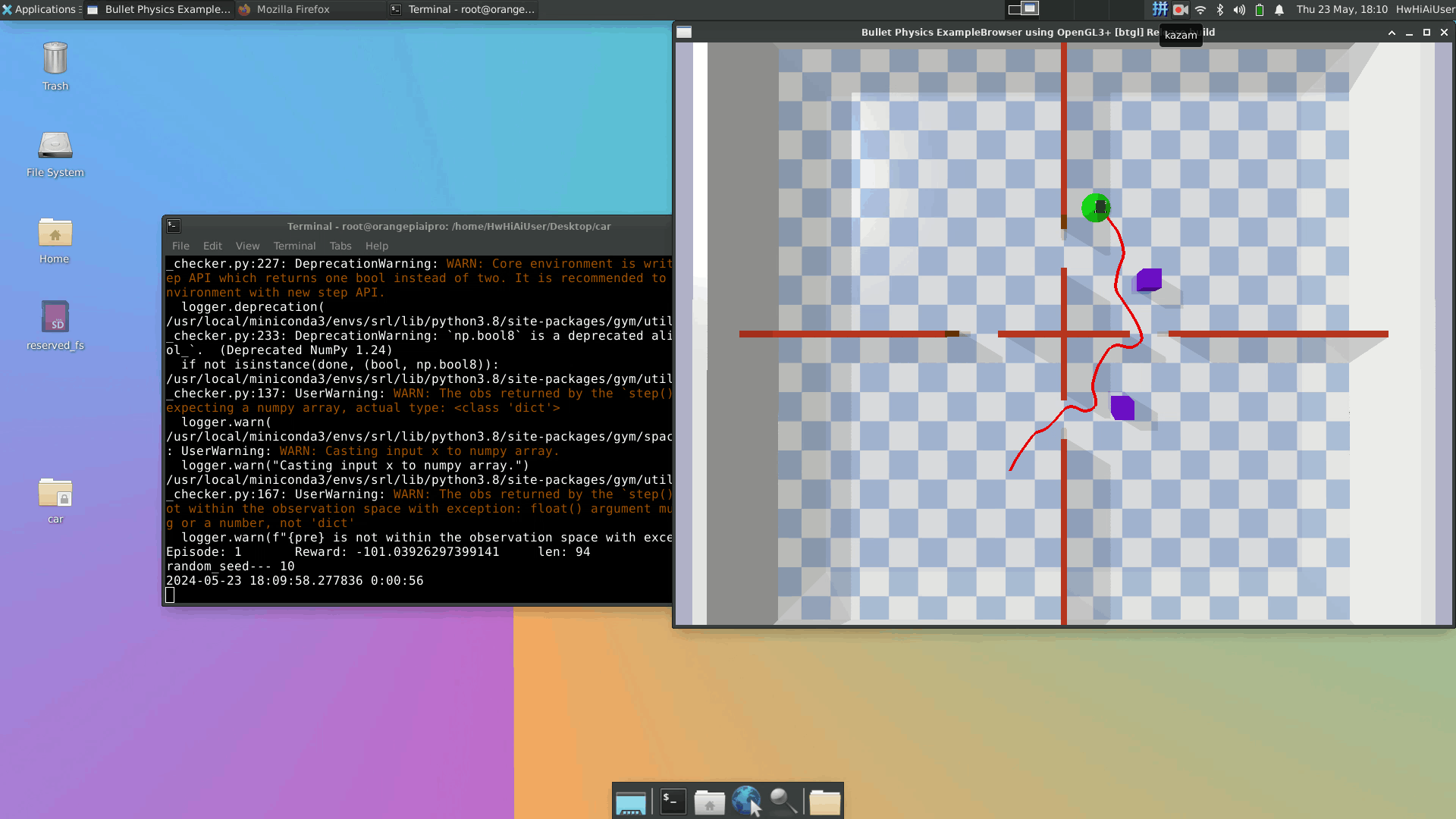
OrangePi AIpro开发板仿真实验运行效果:
动态运行效果:
Pybullet动态效果:

物理实验
本节以全向移动机器人在复杂环境中的路径跟踪为背景设计实验系统,实验系统的总体框图如图所示

该实验系统由运动捕捉系统、地面站和搭载OrangePi AIpro开发板的全向移动小车组成。运动捕捉系统能够获取全向移动小车的实时位姿, 并将其作为反馈信息传递给地面站。地面站讲定位数据解算完成,讲小车的控制指令与位置信息发送给小车, 小车OrangePi AIpro运行安全强化学习策略,给出小车的速度控制指令,产生安全控制,控制全向移动小车安全地到达目标点。
物理实验效果:

六、总结
本文成功在OrangePi AIpro智能小车上实现安全强化学习算法的部署,并进行了仿真及物理实验测试,均取得了良好的测试效果,显示了该开发板在AI应用中的潜力和实用性。以下是对OrangePi AIpro的综合评价,包括其优点和一些改进建议:
优点:
- 环境配置便利: 通过支持conda环境管理工具,使得环境配置变得迅速且高效,对于强化学习等算法依赖的安装过程中没有出现致命的编译错误。
- 高性能AI算力: 支持8TOPS的AI算力,表现出色,尤其适用于计算需求较高的AI应用场景。
- 高性价比与流畅度: 相比于其他竞争对手如树莓派,OrangePi AIpro提供了更优的性价比和更流畅的开发体验。
改进建议:
- 供电方案优化: 在移动机器人等移动设备上部署时,现有的供电方案不够理想。建议提供更详细的供电指南,包括是否可以通过引脚供电的具体方法。
- 框架兼容性与部署流程: 虽然OrangePi AIpro在性能上表现出色,但主流AI算法框架(如TensorFlow、Pytorch、PaddlePaddle)的兼容性仍有待提高。建议开发更系统的算法框架转换和部署流程,以便开发者能够更顺利地实现算法的迁移和应用。
七、参考资料
- 基于分层强化学习与控制障碍函数的安全控制算法[J]. 控制工程
- OrangePi 官方文档

