
- 1软件测试V模型
- 2linux yum baseurl,Linux系统yum安装报错Cannot find a valid baseurl for repo的解决方法
- 3CSerialPort串口类最新修正版2017-03-12_cserialport串口git地址是什么
- 4ES 中时间日期类型 “yyyy-MM-dd HH:mm:ss” 的完全避坑指南_es时间格式
- 5ssh -o 常用选项
- 6SequoiaDB巨杉数据库-实例管理工具_sequoiadb的数据库实例数据库鉴权的账号密码是多少
- 7vscode插件-05 C/C++_code runner 的 han jun 是?
- 8Java代码漏洞检测-常见漏洞与修复建议_代码执行漏洞测试方法
- 9前端实现常见机器学习算法_mljs
- 10LeetCode 224. 基本计算器_基本计算器leetcode
(2021|ICLR,LoRA,秩分解矩阵,更少的可训练参数)LoRA:大语言模型的低秩自适应_lora 低秩自适应
赞
踩
LoRA: Low-Rank Adaptation of Large Language Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
7.1 在 Transformer 中应该应用 LoRA 的权重矩阵是哪些?
0. 摘要
一个自然语言处理的重要范例包括在一般领域数据上进行大规模的预训练,然后适应特定任务或领域。随着我们预训练更大的模型,完全微调,即重新训练所有模型参数,变得不太可行。以 GPT-3 175B 为例 - 部署独立的经过微调的模型实例,每个模型有 175B 个参数,是非常昂贵的。我们提出低秩适应(Low-Rank Adaptation,LoRA),它冻结预训练模型的权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了用于下游任务的可训练参数的数量。与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数的数量减少 10,000 倍,GPU 内存需求减少 3 倍。在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上,LoRA 在模型质量上表现出与微调相当或更好的性能,尽管它具有更少的可训练参数、更高的训练吞吐量,并且与适配器不同,没有额外的推断延迟。我们还对语言模型适应中的秩缺失(rank-deficient)进行了实证研究,这揭示了 LoRA 的有效性。
代码:https://github.com/microsoft/LoRA
术语和约定:我们频繁引用 Transformer 架构,并使用其维度的传统术语。我们将 Transformer 层的输入和输出维度大小称为 d_model。我们使用 Wq、Wk、Wv 和 Wo 来指代自注意力模块中的查询/键/值/输出投影矩阵。W 或 W0 指的是预训练的权重矩阵,ΔW 指的是在适应过程中的累积梯度更新。我们使用 r 来表示 LoRA 模块的秩。
我们遵循 (Vaswani等人,2017;Brown等人,2020) 设定的约定,使用 Adam (Loshchilov&Hutter,2019;Kingma&Ba,2017) 进行模型优化,并使用 Transformer MLP 前馈维度 d_ffn = 4 * d_model。
2. 问题陈述
虽然我们的提议对训练目标不加限制,但我们专注于语言建模作为我们的动机用例。以下是语言建模问题的简要描述,特别是在给定任务特定提示的情况下最大化条件概率。
假设我们有一个参数为 Φ 的预训练自回归语言模型 P_Φ(y|x)。例如,P_Φ(y|x) 可以是基于Transformer 架构(Vaswani等人,2017) 的通用多任务学习器,如 GPT (Radford等人,b; Brown等人,2020)。考虑将这个预训练模型调整到下游条件文本生成任务,如摘要、机器阅读理解(MRC)和自然语言到 SQL(NL2SQL)。每个下游任务由上下文-目标对的训练数据集表示:
![]()
其中 xi 和 yi 都是 token 序列。例如,在 NL2SQL 中,xi 是一个自然语言查询,yi 是其对应的 SQL 命令;对于摘要,xi 是文章的内容,yi 是其摘要。
在完全微调过程中,模型被初始化为预训练权重 Φ_0,并通过重复遵循梯度来最大化条件语言建模目标而更新为 Φ_0 + ΔΦ:
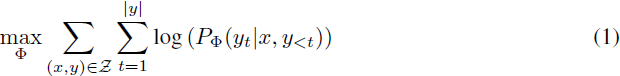
全面微调的一个主要缺点是,对于每个下游任务,我们学习一个不同的参数集 ΔΦ,其维度 |ΔΦ| 等于 |Φ_0|。因此,如果预训练模型很大(例如 GPT-3,|Φ_0| 大约为 1750 亿),存储和部署许多独立的微调模型实例可能具有挑战性。
在本文中,我们采用一种更具参数效率的方法,其中任务特定的参数增量 ΔΦ = ΔΦ(θ) 被一个更小的参数集 θ(|θ| ≤ |Φ_0|)进一步编码。因此,找到 ΔΦ 的任务变为在 θ 上进行优化:

在接下来的部分中,我们提出使用低秩表示来编码 ΔΦ,这既具有计算效率又具有内存效率。当预训练模型是 GPT-3 175B 时,可训练参数的数量 |θ| 可以小到 0.01% 的 |Φ_0|。
3. 现有的解决方案不够好吗?
我们着手解决的问题绝不是新问题。自迁移学习开始以来,数十项工作都致力于使模型适应更具参数和计算效率。请参阅第 6 节,了解一些著名作品的调查。以语言建模为例,当涉及到有效适应时,有两种显著的策略:添加适配器层(Houlsby等人,2019;Rebuffi等人,2017;Pfeiffer等人,2021;Rückl´e等人,2020)或优化某些形式的输入层激活(Li&Liang,2021;Lester等人,2021;Hambardzumyan等人,2020;Liu等人,2021)。然而,这两种策略都有其局限性,特别是在大规模和对延迟敏感的生产场景中。
适配器层引入推断延迟。有许多适配器的变体,我们关注 Houlsby 等人(2019)的原始设计,每个 Transformer 块有两个适配器层,以及 Lin 等人(2020)的最新设计,每个块只有一个适配器层,但带有额外的 LayerNorm(Ba等人,2016)。虽然可以通过修剪层或利用多任务设置(R¨uckl´e等人,2020;Pfeiffer等人,2021)来减少总体延迟,但没有直接的方法来规避适配器层中的额外计算。这似乎不是一个问题,因为适配器层的设计是要通过具有小瓶颈维度来限制它们可能添加的 FLOP 数,从而具有很少的参数(有时 <1% 的原始模型)。然而,大型神经网络依赖于硬件并行性来保持延迟低,而适配器层必须按顺序处理。这在在线推断设置中产生差异,其中 batch 大小通常很小。在没有模型并行性的通用情况下,例如在单个 GPU 上运行中等规模的 GPT-2(Radford等人,b)进行推断时,即使使用了非常小的瓶颈维度(表 1),使用适配器时延迟也会明显增加。
当我们需要像 Shoeybi等人(2020);Lepikhin等人(2020)那样对模型进行分片时,问题变得更加严重,因为额外的深度需要更多同步的 GPU 操作,例如 AllReduce 和 Broadcast,除非我们多次冗余地存储适配器参数。

直接优化提示很难。另一方向,如 Li&Liang(2021)所示范的前序调整(prefix tuning),面临着不同的挑战。我们观察到前序调整难以优化,并且其性能在可训练参数中呈非单调变化,证实了原始论文中的类似观察。更基本地,为自适应保留序列长度的一部分必然会减少用于处理下游任务的序列长度,我们怀疑这使得调整提示的性能较其他方法更差。我们将任务性能的研究推迟到第 5 节。
4. 我们的方法
我们描述 LoRA 的简单设计以及其实际优势。这里概述的原则适用于深度学习模型中的任何密集层,尽管在我们的实验中,我们只关注 Transformer 语言模型中的某些权重,作为激发的使用案例。
4.1 低秩参数化的更新矩阵
神经网络包含许多执行矩阵乘法的密集层。这些层中的权重矩阵通常满秩。当适应特定任务时,Aghajanyan 等人(2020)表明预训练语言模型具有低 “内在维度”,即使对较小子空间的随机投影,它仍然可以有效学习。受此启发,我们假设权重的更新在适应过程中也具有低 “内在秩”。对于一个预训练的权重矩阵 W0 ∈ R^(d×k),我们通过使用低秩分解来表示其更新 W0+ΔW=W0+BA,其中 B ∈ R^(d×r);A ∈ R^(r×k) ,秩 r << min(d,k)。在训练过程中,W0 被冻结并且不接收梯度更新,而 A 和 B 包含可训练的参数。请注意,W0 和 ΔW=BA 都与相同的输入进行乘法运算,它们各自的输出向量在坐标方向上求和。对于 h=W0x,我们的修改后的前向传播为:
![]()
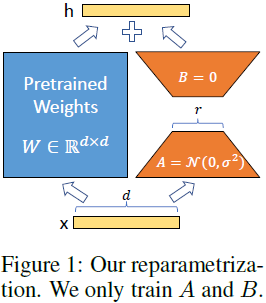
我们在图 1 中说明了我们的重参数化。我们对 A 使用随机高斯初始化,对 B 使用零初始化,因此在训练开始时 ΔW=BA 为零。然后,我们通过 α/r 缩放 ΔWx,其中 α 是 r 中的一个常数。当使用 Adam 进行优化时,调整 α 大致相当于调整学习率,如果我们适当地缩放初始化。因此,我们简单地将 α 设置为我们尝试的第一个 r,并且不对其进行调整。这种缩放有助于在我们改变 r 时减少需要重新调整超参数的需求(Yang&Hu,2021)。
对全面微调的泛化。微调的更一般形式允许对预训练参数的子集进行训练。LoRA 更进一步,并且在适应过程中不要求权重矩阵的累积梯度更新具有满秩。这意味着当将 LoRA 应用于所有权重矩阵并训练所有偏置时,通过将 LoRA 秩 r 设置为预训练权重矩阵的秩,我们大致可以恢复全面微调的表达能力。换句话说,随着我们增加可训练参数的数量,训练 LoRA 大致趋于训练原始模型,而基于适配器的方法趋于一个 MLP,而基于前序的方法趋于一个不能处理长输入序列的模型。
没有额外的推断延迟。在生产环境中,我们可以显式计算并存储 W=W0+BA,并进行正常推断。请注意,W0 和 BA 都在 R^(d×k) 中。当我们需要切换到另一个下游任务时,我们可以通过减去 BA 来恢复 W0,然后添加不同的 B'A' ,这是一项快速的操作,几乎没有内存开销。关键是,这确保了与微调模型相比,在推断过程中我们不会引入任何额外的延迟。
4.2 将 LoRA 应用于 Transformer
原则上,我们可以将 LoRA 应用于神经网络中的任何权重矩阵的子集,以减少可训练参数的数量。在 Transformer 架构中,自注意力模块中有四个权重矩阵(Wq; Wk; Wv; Wo),MLP 模块中有两个权重矩阵。我们将 Wq(或 Wk,Wv)视为维度为 d_model * d_model 的单个矩阵,即使输出维度通常被切片成注意力头。出于简单性和参数效率的考虑,我们仅研究自注意力权重的适应性,并冻结 MLP 模块(因此它们在下游任务中不被训练)。我们在第 7.1 节进一步研究了在 Transformer 中适应不同类型的注意力权重矩阵的效果。我们将适应 MLP 层、LayerNorm 层和偏置的实证研究留待未来工作。
实际优势和局限性。最显著的好处来自内存和存储使用的减少。对于使用 Adam 训练的大型Transformer,如果 r << d_model,我们可以将 VRAM 使用量减少到 2/3,因为我们不需要存储冻结参数的优化器状态。在 GPT-3 175B 上,我们将训练期间的 VRAM 消耗从 1.2TB 减少到350GB。当 r=4 且只适应查询和值投影矩阵时,检查点大小大致减小了 10,000 倍(从 350GB 减少到 35MB)。这使我们能够使用更少的 GPU 进行训练,避免 I/O 瓶颈。另一个好处是,我们可以以更低的成本在部署时在不同任务之间切换,只需交换 LoRA 权重而不是所有参数。这允许创建许多定制模型,可以在存储预训练权重的 VRAM 上随时切换。与全面微调相比,我们还观察到在GPT-3 175B 上训练时有 25% 的加速,因为我们不需要计算大多数参数的梯度。
LoRA 也有其局限性。例如,如果选择将 A 和 B 合并到 W 中以消除额外的推断延迟,则在单个前向传播中对不同任务的输入进行分批处理是不直观的。尽管可以选择不合并权重,并在对延迟不敏感的情况下动态选择用于批次样本的 LoRA 模块。
5. 实验
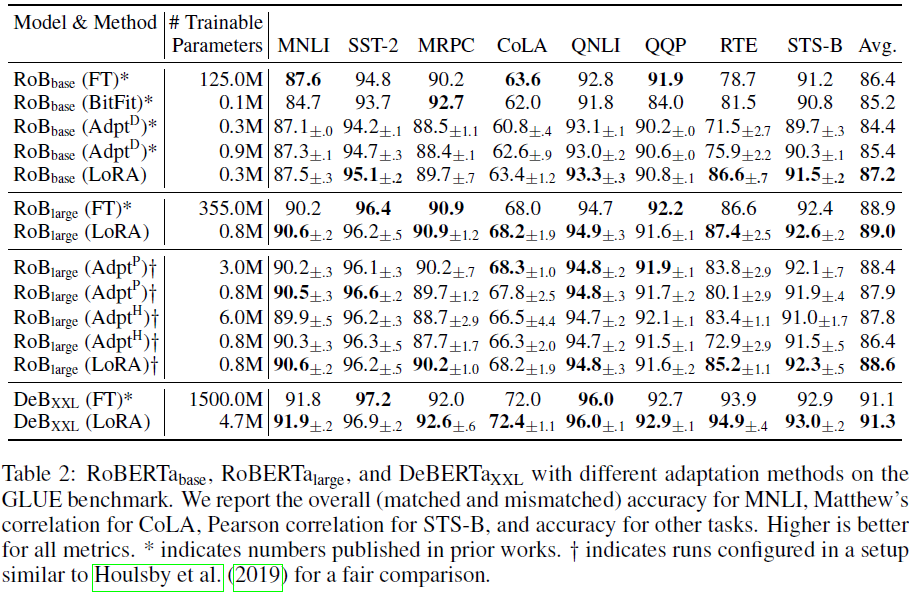
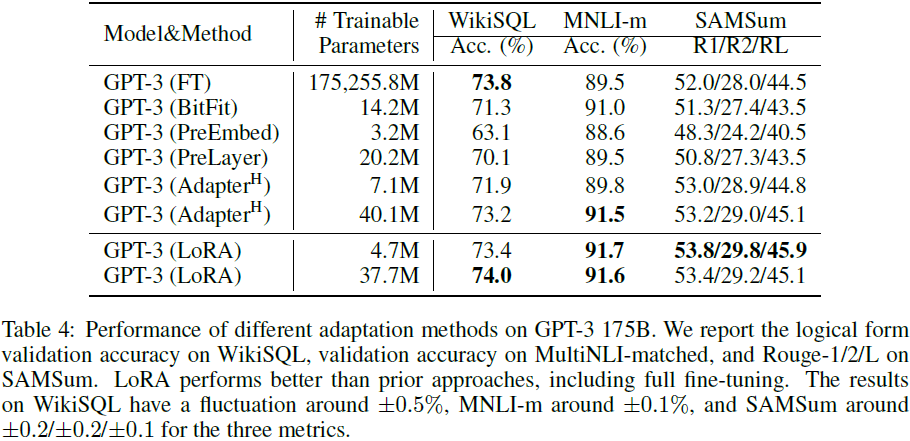
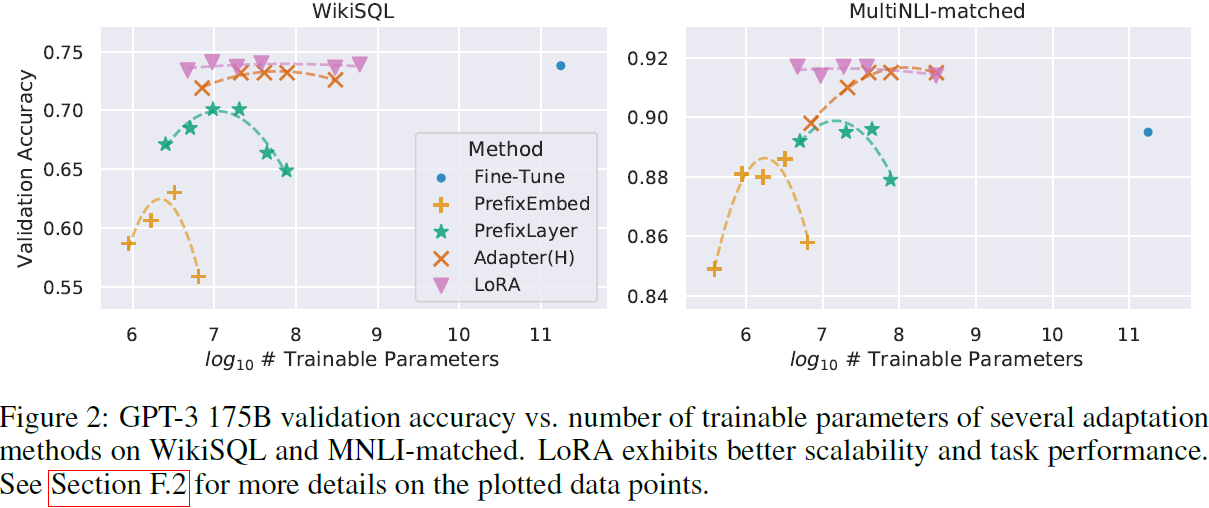
相比于适配器(Adaptor),除了没有额外的推断时延,LoRA 使用相同或更少的可训练参数,却有更突出的性能。

7. 理解低秩更新
鉴于 LoRA 的实证优势,我们希望进一步解释从下游任务中学到的低秩适应性的性质。请注意,低秩结构不仅降低了硬件入门门槛,使我们能够并行运行多个实验,还提高了更新权重与预训练权重相关性的可解释性。我们将研究重点放在 GPT-3 175B 上,在这里我们实现了可训练参数的最大减少(高达 10,000 倍),而不对任务性能产生不利影响。
我们进行一系列实证研究以回答以下问题:
1)在参数预算约束下,应该适应预训练 Transformer 中的哪些权重矩阵,以最大化下游性能?
2)“最佳” 适应矩阵 ΔW 确实是秩不足的吗?如果是的话,实际上使用的好秩是多少?
3)ΔW 与 W 之间有什么联系?ΔW 与 W 高度相关吗?与 W 相比,ΔW 有多大?
我们相信我们对问题(2)和(3)的回答为使用预训练语言模型进行下游任务提供了启示,这是自然语言处理中的一个关键主题。
7.1 在 Transformer 中应该应用 LoRA 的权重矩阵是哪些?
在有限的参数预算下,我们应该使用 LoRA 适应哪些类型的权重,以获得在下游任务上最佳性能?如第 4.2 节所述,我们仅考虑自注意力模块中的权重矩阵。我们在 GPT-3 175B 上设置了 18M 的参数预算(如果以 FP16 存储,大约为 35MB),这对应于,对于所有的 96 层,如果我们适应一种类型的注意力权重则 r=8 ,或者如果我们适应两种类型,则 r=4 。结果呈现在表 5 中。

请注意,将所有参数放入 ΔWq 或 ΔWk 导致性能显著降低,而同时适应 Wq 和 Wv 产生最佳结果。这表明,即使秩为 4,ΔW 中包含的信息足够多,因此适应更多的权重矩阵优于适应具有较大秩的单一类型的权重。
7.2 LORA 的最佳秩 r 是多少?
我们将注意力转向秩 r 对模型性能的影响。我们适应了(Wq,Wv)、(Wq,Wk,Wv,Wc) 和仅 Wq 进行比较。

表 6 显示,令人惊讶的是,LoRA 在非常小的 r 下(尤其是对于 (Wq,Wv) 而言,比仅 Wq 更明显)已经表现出竞争性。这表明更新矩阵 ΔW 可能具有非常小的 “内在秩”。为了进一步支持这一发现,我们检查了由不同的 r 选择和不同的随机种子学习的子空间之间的重叠。我们认为增加 r 不会覆盖一个更有意义的子空间,这表明低秩适应矩阵是足够的。
然而,我们并不期望对于每个任务或数据集,较小的 r 都能够奏效。考虑以下思想实验:如果下游任务的语言与用于预训练的语言不同,那么重新训练整个模型(r = d_model)肯定能够胜过具有较小 r 的 LoRA。
不同 r 之间的子空间相似性。给定 A_(r=8) 和 A_(r=64),它们是使用相同的预训练模型学到的秩为 8 和 64 的适应矩阵,我们进行奇异值分解并得到右奇异单元矩阵(right-singular unitary matrices) U_(A_(r=8)) 和 U_(A_(r=64))。我们希望回答:U_(A_(r=8)) 中前 i 个奇异向量张成的子空间有多少包含在 U_(A_(r=64)) 中前 j 个奇异向量张成的子空间中?我们用基于 Grassmann 距离的标准化子空间相似性来测量这个数量(有关更正式的讨论,请参见附录 G):

其中
![]()
表示与前 i 个奇异向量相对应的 U_(A_(r=8)) 的列。
ϕ(⋅) 的范围是 [0,1],其中 1 表示子空间完全重叠,0 表示完全分离。查看图 3,了解在改变 i 和 j 时 ϕ 的变化。由于空间限制,我们只考虑了第 48 层(共 96 层),但结论对其他层同样成立,详见第 H.1 节。
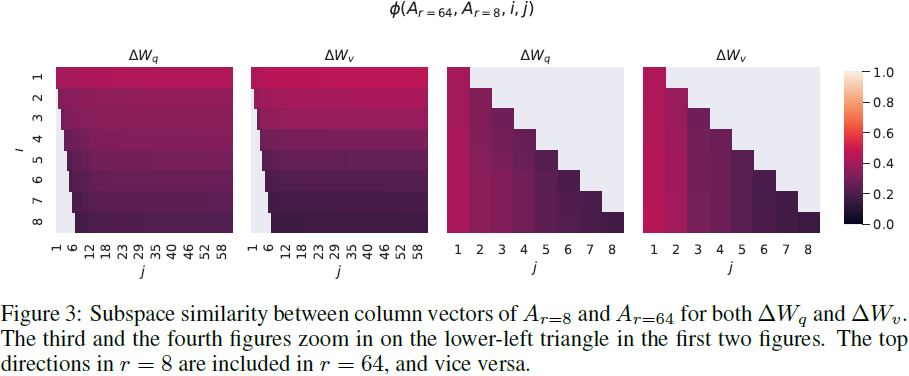
从图 3 中我们做出一个重要的观察。 与 A_(r=8) 和 A_(r=64) 相对应的前几个奇异向量存在显著的重叠,而其他则没有。具体来说,A_(r=8) 的 ΔWv(或 ΔWq) 和 A_(r=64) 的 ΔWv(或 ΔWq) 共享一个维度为 1 的子空间,其标准化相似性 > 0.5,这解释了为什么在我们的 GPT-3 下游任务中,r=1 的性能相当不错。
由于 A_(r=8) 和 A_(r=64) 都是使用相同的预训练模型学到的,图 3 表明了 A_(r=8) 和 A_(r=64) 的前几个奇异向量是最有用的,而其他的可能主要包含在训练期间积累的大部分随机噪声。因此,适应矩阵确实可以具有非常低的秩。
不同随机种子之间的子空间相似性。我们通过绘制两个具有 r=64 的不同随机种子运行之间的标准化子空间相似性,进一步证实了这一点,如图 4 所示。由于对于 ΔWq,两个运行都学到了更多的共同奇异值,它似乎具有更高的 “内在秩”,这与我们在表 6 中的实证观察一致。 作为比较,我们还绘制了两个随机高斯矩阵,它们彼此没有共同的奇异值。

7.3 适应矩阵 ΔW 与权重矩阵 W 相比如何?
我们进一步研究了 ΔW 与 W 之间的关系。特别地,ΔW 是否与 W 高度相关?(或者在数学上说,ΔW 是否主要包含在 W 的前几个奇异值中?)另外,
ΔW 相对于其在 W 中对应奇异值有多 “大”?这可以为适应预训练语言模型的基本机制提供一些启示。
为了回答这些问题,我们通过计算 U^T·W·V^T 将 W 投影到 ΔW 的 r 维子空间上,其中 U/V 是 ΔW 的左/右奇异向量矩阵。然后,我们比较 ||U^T·W·V^T||_F 与 ||W||_F 之间的 Frobenius 范数。作为比较,还通过用 W 的前 r 个奇异向量或一个随机矩阵替换 U,V 来计算 ||U^T·W·V^T||_F。

我们从表 7 中得出几个结论。
- 首先,与随机矩阵相比,ΔW 与 W 有更强的相关性,这表明 ΔW 放大了已经存在于 W 中的一些特征。
- 其次,与重复 W 的前几个奇异值不同,ΔW 只放大了在 W 中没有强调的奇异值。
- 第三,放大因子相当巨大:对于 r=4,21.5≈6.91/0.32。
有关为什么 r=64 具有较小放大因子的详细信息,请参见第 H.4 节。我们还在第 H.3 节中提供了一个可视化,展示了当我们包含来自 Wq 的更多前几个奇异值时,相关性的变化。这表明低秩适应矩阵可能放大了在通用预训练模型中学到但没有强调的特定下游任务的重要特征。
8. 未来工作
有许多未来工作的方向。
1) LoRA 可以与其他高效的适应方法结合,可能提供正交的改进。
2) 微调或 LoRA 背后的机制仍不清楚 - 在预训练期间学到的特征如何转化为在下游任务上表现良好?我们认为相对于完全微调,LoRA 使得这个问题更容易回答。
3) 我们主要依赖启发式方法来选择应用 LoRA 的权重矩阵。是否有更有原则的方法呢?
4) 最后,ΔW 的秩缺陷表明 W 也可能是秩缺陷的,这也可以成为未来研究的灵感来源。


