
- 1传入日期格式错误“message“: “JSON parse error: Cannot deserialize value of type `java.util.Date` from String_msg": "json parse error: cannot deserialize value
- 2基于FPGA的光口通信开发案例_tx diff swing
- 3MAC搭建MySQL,同时使用dataGrip可视化数据库_datagrip download from maven failed
- 4Java增加线程后kafka仍然消费很慢
- 5springcloud+hibernate+JPA+EntityManager Oracle 双数据源配置_java中yml配置hibernate多数据源调用接口
- 6Python课程设计:图书馆管理系统_python图书信息管理系统课设
- 7Dom4j教程详解+XML详解(详解+举例)
- 8产品读书《自卑与超越》_母亲带着三个孩子去动物园看狮子
- 9国密算法SM3
- 10Python针对MAC OS X安装_python3.12.1 mac安装教程
【深度学习】LoRA: Low-Rank Adaptation of Large Language Models,论文解读_lora: low-rank adaptation of large lan- guage mode
赞
踩
文章:
https://arxiv.org/abs/2106.09685
摘要
自然语言处理的一个重要范式是在通用领域数据上进行大规模预训练,并适应特定任务或领域。随着我们预训练更大的模型,全面微调,即重新训练所有模型参数,变得不太可行。以GPT-3 175B为例 - 部署独立的微调模型实例,每个模型有175B个参数,成本过高。我们提出了低秩适应,或LoRA,它冻结了预训练模型的权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层中,大大减少了下游任务的可训练参数数量。与使用Adam微调的GPT-3 175B相比,LoRA可以将可训练参数数量减少10,000倍,GPU内存需求减少3倍。LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3的模型质量上表现出与微调相当或更好的性能,尽管它具有更少的可训练参数、更高的训练吞吐量,并且与适配器不同,没有额外的推理延迟。我们还对语言模型适应中的秩缺失进行了实证研究,这揭示了LoRA的有效性。我们发布了一个软件包,可以方便地将LoRA与PyTorch模型集成,并在https://github.com/microsoft/LoRA 上提供我们的RoBERTa、DeBERTa和GPT-2的实现和模型检查点。
介绍
许多自然语言处理中的应用依赖于将一个大规模、预训练的语言模型适应到多个下游应用程序。这种适应通常通过微调来完成,微调会更新预训练模型的所有参数。微调的主要缺点是新模型包含与原始模型一样多的参数。随着每隔几个月训练更大的模型,这从仅仅是对于GPT-2(Radford等,b)或RoBERTa大型(Liu等,2019)的一个“不便”变成了对于具有1750亿个可训练参数的GPT-3(Brown等,2020)的一个关键的部署挑战。
许多人试图通过仅适应一些参数或为新任务学习外部模块来缓解这一挑战。这样,我们只需要在每个任务中存储和加载一小部分与任务相关的参数,除了预训练模型,这样在部署时可以大大提高操作效率。然而,现有的技术往往通过扩展模型深度或减少模型可用序列长度(Li&Liang,2021;Lester等,2021;Hambardzumyan等,2020;Liu等,2021)(第3节)引入推理延迟。更重要的是,这些方法往往无法与微调基线相匹配,提出了效率和模型质量之间的折衷。
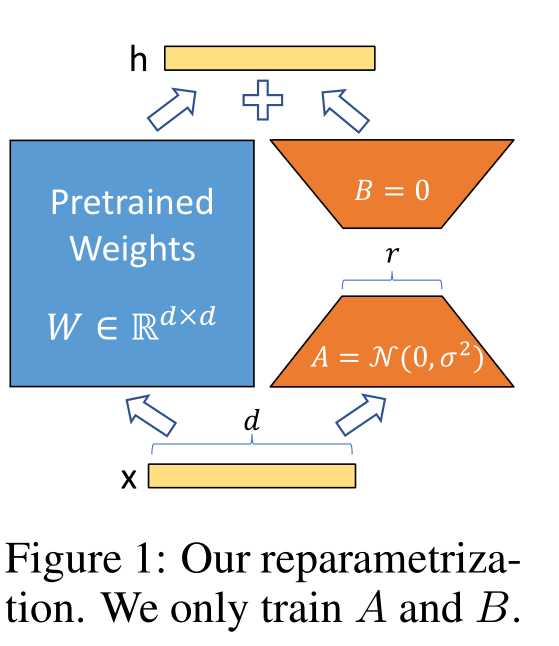
我们受到Li等人(2018a)和Aghajanyan等人(2020)的启发,他们表明学习的过度参数化模型实际上驻留在低固有维度上。我们假设模型适应期间权重的变化也具有低“固有秩”,这导致了我们提出的低秩适应(LoRA)方法。LoRA允许我们通过优化适应期间密集层的秩分解矩阵间接地训练一些密集层,同时保持预训练权重冻结,如图1所示。以GPT-3 175B为例,我们展示了即使在完整秩(即d)高达12,288时,非常低的秩(即图1中的r可以是一或两)也足以满足要求,使LoRA在存储和计算方面都非常高效。LoRA具有几个关键优势。
- 预训练模型可以被共享,并用于构建许多不同任务的小LoRA模块。我们可以冻结共享模型,并通过替换图1中的矩阵A和B来高效地切换任务,从而大大降低存储需求和任务切换开销。
- LoRA使训练更加高效,并且在使用自适应优化器时将硬件门槛降低了最多3倍,因为我们不需要计算大多数参数的梯度或维护优化器状态。相反,我们只优化注入的、更小的低秩矩阵。
- 我们简单的线性设计允许我们在部署时将可训练矩阵与冻结的权重合并,与完全微调的模型相比,不会引入推理延迟,因为构造上是如此。
- LoRA与许多先前的方法是正交的,可以与其中许多方法结合使用,例如前缀调整。我们在附录E中提供了一个示例。
LoRA的特点
低秩适应矩阵:在适应阶段,LoRA引入了一个低秩矩阵,将其与预训练的权重矩阵相乘,以生成适应后的权重。这个低秩矩阵的引入使得适应过程中的参数数量大大减少,从而降低了计算成本和内存需求。
参数共享:LoRA允许大部分模型参数在不同任务之间进行共享,只有少量参数需要在适应特定任务时进行微调。这种参数共享的机制使得在部署时可以快速切换任务,而无需针对每个任务都维护独立的模型实例。
无额外推理延迟:在部署时,可以通过计算和存储适应后的权重矩阵来执行推理,而无需额外的推理延迟。当需要切换到另一个任务时,可以通过简单的操作来恢复原始的权重矩阵,实现快速任务切换。
与其他方法的结合:LoRA是一种灵活的适应策略,可以与其他高效适应方法结合使用,从而进一步提升模型性能。例如,可以将LoRA与前缀调整等方法相结合,实现更好的适应效果。
什么是低秩适应矩阵?什么是适应阶段?
低秩适应矩阵是指在LoRA(Low-Rank Adaptation)中引入的一种机制,用于在适应阶段对预训练模型进行调整以适应特定任务或领域。在适应阶段,低秩适应矩阵被注入到预训练模型的每一层Transformer结构中,以减少可训练参数的数量,从而降低计算成本和内存需求。
具体来说,适应阶段是指在将预训练模型应用于特定任务之前的阶段,其中通过引入低秩适应矩阵来对模型进行微调以适应任务的需求。在适应阶段,预训练模型的权重被冻结,而低秩适应矩阵则被训练以调整模型以适应新任务。通过这种方式,可以在不重新训练所有模型参数的情况下实现对模型的有效调整,从而提高了适应的效率和速度。
低秩适应矩阵是LoRA中的关键组成部分,用于在适应阶段对预训练模型进行调整,以实现高效的任务适应和模型优化。适应阶段是指在应用模型于特定任务之前的阶段,其中通过引入低秩适应矩阵来对模型进行微调以适应任务的需求。
低秩适应矩阵被注入到预训练模型的每一层Transformer结构中,这一步是如何做到的?
在LoRA中,低秩适应矩阵被注入到预训练模型的每一层Transformer结构中是通过以下步骤实现的:
-
选择注入层:首先,确定要将低秩适应矩阵注入的Transformer模型的每一层。通常,这些层包括Self-Attention层和前馈神经网络(Feed-Forward Neural Network)层。
-
构建低秩适应矩阵:为每个选择的层构建低秩适应矩阵。这些矩阵通常由两个较小的矩阵相乘得到,其中一个矩阵的维度较小,从而降低了参数数量。
-
将低秩适应矩阵与权重矩阵相乘:在适应阶段,将构建的低秩适应矩阵与每一层的权重矩阵相乘,以生成适应后的权重矩阵。这样可以在保持模型结构的同时,通过调整低秩矩阵的参数来实现对模型的微调。
-
训练低秩适应矩阵:在训练过程中,通过优化算法(如梯度下降)来调整低秩适应矩阵的参数,以最大程度地适应特定任务或领域的需求。这样可以在不改变预训练模型大部分参数的情况下,实现对模型的有效调整。
通过以上步骤,低秩适应矩阵可以被成功注入到预训练模型的每一层Transformer结构中,从而实现对模型的高效适应和优化。这种注入机制使得在适应阶段可以快速调整模型以适应特定任务的需求,同时保持模型的整体结构和质量。


