
- 1GUI图形编程(6)---事件_图形交互 编程模型 事件
- 2浅谈用二分和三分法解决问题(c++)_三分法c++
- 3N2N(docker方式安装)实现远程访问家里群晖
- 4Android可信执行环境TEE最全介绍_android tee
- 5基于STM32的四种波形发生器控制设计_stm32输出可调频率幅值方波
- 6Pandas的qcut()与cut()_pandas 如何由qcut 返回第几组
- 7数字IC验证高频面试问题整理(附答案)_数字验证 面试
- 8【linux】软件包安装pip/yum/apt_yum 安装pip
- 9[精品毕设]微信小程序springboot居家养老服务+后台管理前后分离_springboot前后端分离 管理后台微信小程序
- 10jwt ---- json web token_jsonwebtoken依赖
【NLP】给Transformer降降秩,通过分层选择性降阶提高语言模型的推理能力_counterfact数据集
赞
踩
【NLP】给Transformer降降秩,通过分层选择性降阶提高语言模型的推理能力
【自然语言处理-论文翻译与学习】序
论文摘要
- 标题: The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction
- 摘要:
基于Transformer的大型语言模型(LLM)已成为现代机器学习的固定模式。相应地,大量资源被分配用于旨在进一步推动这项技术发展的研究,其结果通常是模型的规模越来越大,训练的数据量也越来越大。然而,这项工作展示了一个令人惊讶的结果 :通过有选择性地移除权重矩阵中的高阶成分,通常可以显著提高 LLM 的性能 。我们将这种简单的干预称为 “LAyer-SElective Rank reduction (LASER)”,它可以在训练完成后对模型进行,不需要额外的参数或数据。我们通过大量实验证明了这一发现在不同语言模型和数据集上的通用性,并提供了深入分析,深入揭示了 LASER 的有效时间及其运行机制。 - 作者信息

- 论文原文
论文主页
项目地址 - ICLR了解一下
补充信息
-
机器之心翻译-给Transformer降降秩,移除特定层90%以上组件LLM性能不减
简化版Transformer来了,网友:年度论文 -
MIT、微软联合研究:不需要额外训练,也能增强大语言模型的任务性能并降低其大小。
-
Transformer最早于Attention is all you need一文中被提出,PPT。
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30: 5998-6008.
中文翻译可以参考1,2,3,4,5 -
在大模型时代,Transformer 凭一己之力撑起了整个科研领域。自发布以来,基于 Transformer 的 LLM 在各种任务上表现出卓越的性能,其底层的 Transformer 架构已成为自然语言建模和推理的最先进技术,并在计算机视觉和强化学习等领域显示出强有力的前景。
-
然而,当前 Transformer 架构非常庞大,通常需要大量计算资源来进行训练和推理。 这是有意为之的,因为经过更多参数或数据训练的 Transformer 显然比其他模型更有能力。尽管如此,越来越多的工作表明,基于 Transformer 的模型以及神经网络不需要所有拟合参数来保留其学到的假设。
-
关键词:权重、参数、剪枝、奇异值分解(SVD)、计算机视觉、神经网络、准确率、强化学习、语言模型
SVD相关介绍
-
《虚假的对话》
“都2023了怎么还有人在用svd这么古老的技术啊,而且还用来做NLP,也太low了吧”,
“你别说,还真有大佬用(雾,而且是2024” -
《某次答辩》
起因是前段时间某段科研经历的项目拿出来答辩的时候,被某位老师说,SVD是很古老的技术(确实啊SVD用于NLP大概19,20年那会儿就有人在做了,而且后来矩阵降维和分解好像又搞了几个新的出来),,,怎么还在用,可是我这个题确实没人做过啊,,当时挺尴的,也只是大概解释了下,当时还想着还好我选的课题和领域够小众,,又套了不少其他的东西,也做了一些改造什么的。 -
但是最近看到这篇文章确实感觉很震惊啊,大佬竟然还拿来改Transformer的,有点厉害了。翻译一波,仰望一下。(仅供读懂大致意思,就不翻译具体的公式符号了哈,比较费时间,有需要的可以看原文)
1、导论
自首次发布以来,基于 Transformer 的 LLM 已被证明在一系列重要的机器学习任务上表现非常出色。 其底层 Transformer 架构已成为自然语言建模和推理领域的最先进技术,并在计算机视觉 [Dosovitskiy 等人,2020 年] 和强化学习 [Chen 等人,2021 年] 等领域也显示出良好的前景。
Transformer 架构的当代实例非常庞大,通常需要大量计算资源来进行训练和推理。这是设计使然,因为使用更多参数或数据训练的 Transformer 显然比其更精简的前辈更有能力——通常优势显著 [Brown 等人,2020 年,Touvron 等人,2023 年]。尽管如此,越来越多的研究表明,基于 Transformer 的模型以及更普遍的神经网络不需要所有拟合参数来保留其学习到的假设。虽然在训练时进行大量过度参数化似乎很有帮助 [Hinton 等人,2015 年,Bengio 等人,2005 年],但众所周知,这些模型可以在推理之前进行大幅修剪;神经网络通常可以删除超过 90% 的权重,而不会显著降低性能 [Frankle and Carbin,2018 年]。这一现象的发现激发了人们对泛化和过度参数化之间关系的兴趣 [Zhang et al., 2017],并引发了开发有助于有效模型推理的修剪策略的研究 [Molchanov et al., 2016]。
本文提出了一个令人惊讶的发现,即在 Transformer 模型的特定层上进行仔细的修剪可以显著提高某些任务的性能。 我们描述了层选择性降阶 (LASER),这是一种干预措施,可以删除由奇异值分解确定的学习权重矩阵的高阶分量。 此减少在 Transformer 模型的特定权重矩阵和层中执行。与以前的工作一致,我们发现许多这样的矩阵可以显著减少,并且通常只有在完全删除超过 90% 的组件后才会观察到性能下降。 然而,与以前的工作不同,我们发现这些减少可以大大提高准确性,这是通过 NLP 中各种经过充分研究的推理基准来衡量的。更妙的是,这一发现似乎不仅限于自然语言,在强化学习中也发现了性能提升。
本文分析了模型训练数据与受益于 LASER 的样本之间的关系。我们发现模型性能的提升主要来自模型训练数据集中出现频率较低的信息,这表明 LASER 提供了一种去噪程序,使弱学习事实变得可访问。我们单独观察到,LASER 为先前正确的问题的释义提供了更高的稳健性。
此外,我们尝试推断高阶组件中存储的内容,以便删除它们可以提高性能。对于仅在 LASER 之后才正确回答的问题,在没有干预的情况下,原始模型主要使用高频词(例如“the”、“of”等)来回答,这些词的语义类型甚至与正确答案不同 。但是,经过一定程度的降阶后,模型的答案就会变为正确答案。 为了理解这一点,我们查看了剩余组件本身的编码;我们仅使用其高阶奇异向量来近似权重矩阵。 我们发现这些组件要么描述的是与正确答案具有相同语义类别的不同响应,要么是通用的高频词。似乎当嘈杂的高阶组件与低阶组件相结合时,它们的冲突响应会产生一种“平均答案”,而这很可能是不正确的。

图 1 直观显示了 Transformer 架构和 LASER 所遵循的流程。这里,特定层的多层感知器 (MLP) 的权重矩阵被其低秩近似值替换。
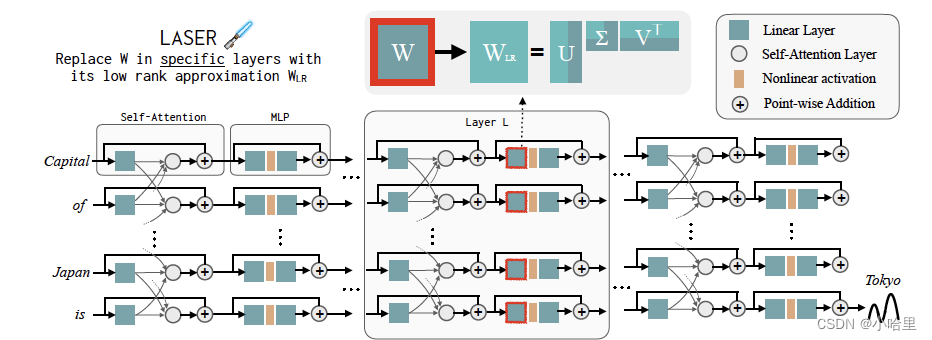
图 1:LAyer SElective Rank Reduction (LASER) 将 Transformer 模型的特定权重矩阵 W 替换为其秩 k 近似 WLR,并观察模型行为的变化。我们发现,这种秩近似,尤其是对于模型后面几层的 MLP 权重,通常会为模型性能带来令人惊讶的好处
2、相关工作
据我们所知,这篇论文首次指出,精心选择的降阶可以提高 Transformer 的性能。不过,还有很多研究相关问题的作品,包括事实如何存储在 LLM 中以及如何最好地压缩神经网络。
1、事实是如何存储的。
探究模型表示中实体的选定属性的存在的研究 [Ettinger 等人,2016 年,Adi 等人,2016 年,Hupkes 等人,2018 年,Conneau 等人,2018 年] 表明,模型将事实信息存储在不同的层中,而 Lee 等人 [2023] 表明,通过微调选定层可以提高模型对分布偏移的鲁棒性。然而,关于如何在大型语言模型中组织和利用这些信息来构建答案,存在相互矛盾的证据。一些理论认为,有关不同实体的信息在 Transformer 模型的 MLP 部分中本地存储在两层键值内存中 [Geva 等人,2021 年],然后由自注意力模块通过后面的层复制 [Elhage,2021 年]。Meng 等人[2022] 提出了一种跟踪和编辑局部实体特定信息以映射到不同的“不可能”输出的程序,支持局部性理论。这些理论得到了“早期退出”现象的进一步支持,其中中间层的表示可以直接与模型的终端头一起使用以正确生成输出 [Zhao et al., 2021]。相比之下,Hase 等人 [2023] 观察到,可以通过编辑模型架构中的各种层来修改有关某些相同实体或实体关系的信息,因此,事实以碎片化的方式跨层存储。本文没有对局部性做出具体的主张,而是表明权重矩阵的高阶分量会在决策中引入噪声,而仅考虑低阶分量可能会使正确答案变得容易获得。
2、模型压缩。
神经网络剪枝方法发现,模型可以进行显著剪枝(通常删除 90% 以上的参数),而准确率几乎不会下降,从而显著降低模型的存储要求 [LeCun et al., 1989, Hassibi and Stork, 1992, Han et al., 2015, Li et al., 2016, Frankle and Carbin, 2018]。还有一些方法可以结构化地剪枝这些模型,以促进推理时间的改善 [Molchanov et al., 2016]。稀疏子网络的存在 [Frankle and Carbin, 2018, Hoefler et al., 2021] 已被发现适用于卷积、全连接和 Transformer 模型 [Lv et al., 2023, Murty et al., 2022]。而 Jin et al. [2022] 发现,通过修剪然后重新拟合参数可以提高模型泛化能力,只有在模型重新训练时才能观察到泛化能力的提高。据我们所知,模型修剪技术一直在所有参数上进行单方面减少,而不针对任何特定层——导致预测性能保持不变或下降 [Frankle and Carbin, 2018]。然而,在这项工作中,我们发现准确度降低的影响在不同类型的层中是不一致的,并且模型的泛化能力可以通过选择性修剪单独提高;无需额外的训练。粗略地说,我们发现性能下降可以通过降低早期层的等级来产生,而显着的性能优势通常可以通过修剪后面的层来获得。
3、权重矩阵的低秩近似。
大多数剪枝方法按绝对量级的顺序减少参数 [Frankle and Carbin,2018]。然而,另一种方法是降低其组成权重矩阵的秩,保留 SVD 找到的前 k 个组件。虽然已经发现神经模型(包括 Transformer 模型)的矩阵使用这种方法可以得到很好的近似,其中模型的显着减少版本可以保留其行为,但研究表明,随着干预的严重程度增加,性能最终会下降 [Lv et al.,2023,Hajimolahoseini et al.,2021,Yu et al.,2017]。请注意,这些减少通常是单方面进行的,删除模型中每个权重矩阵中相同数量的组件。与这些发现相反,我们表明,有针对性的降秩,即使只影响单个权重矩阵,也可以为 Transformer 的预测准确性带来好处。
4、模型蒸馏和低秩训练。
Ba 和 Caruana [2014] 以及 Hinton 等人 [2015] 训练了较小的网络来模仿较大网络的行为,这表明神经网络可能过度参数化,可以用更精简的替代方案代替。据我们所知,没有报告表明此过程导致模型预测有所改善。[Yang et al., 2020] 为提高内存效率而强制权重矩阵的低秩,但由此产生的模型未能达到与过度参数化的模型相当的性能。结果表明,过度参数化有助于通过 SGD 识别具有良好泛化能力的参数 [Bengio et al., 2005, Hinton et al., 2015, Zhang et al., 2017]。
3、相关工具
在这里我们回顾基本符号并描述我们研究的核心部分。
数学符号。
我们使用 R 表示实数,N 表示自然数,小写字母(如 v ∈ Rd)表示 d 维向量,大写字母(如 W ∈ Rm×n)表示大小为 m × n 的矩阵。我们使用 ∥v∥2 表示向量 v 的欧几里得范数,∥W∥2 表示矩阵 W 的谱范数。我们使用 [N] 表示集合 {1, 2, · · · ,N}。我们将使用 rank(W) 表示矩阵 W 的秩,σ↓ i (W) 表示其第 i 个最大奇异值。
Transformer 架构。
我们提供了与我们的分析相关的 vanilla Transformer 架构的简明描述。Transformer 架构可以被认为是 L 层 Transformer 块。第 l 个块将一个 T 长度向量序列 (h(l−1) 1 , · · · , h(l−1) T ) 映射到另一个 T 长度向量序列 (h(l) 1 , · · · , h(l) T ),其中所有向量都是 d 维。此转换使用两个连续步骤完成:一个自注意力机制,用于跨时间步骤混合信息,以及一个前馈网络,用于处理每个时间步骤内的信息。我们针对固定的第 l 层描述了这些转换的基本版本,并为了清晰起见删除了上标 (l − 1)。3
单头自注意力机制首先将每个向量 hi 映射到查询向量 qi = Wqhi、键向量 ki = Wkhi 和值向量 vi = Wvhi,其中 Wq、Wk、Wv ∈ Rd×d 是特定于层的权重矩阵。然后,我们计算每个 i、j ∈ [T] 的注意概率 p(j | i) = exp(q⊤ i kj/ √ d) PT l=1 exp(q⊤ i kl/ √ d)。这些用于计算注意向量 zi = PT j=1 p(j | i)vj。k 头自注意力通过对键、查询和值使用不同的线性变换来计算一组 k 个注意向量,然后连接这些注意向量。这些针对键、查询和值的 k 个独立线性变换都可以被吸收到它们各自的矩阵 Wq ∈ Rd×dk、Wk ∈ Rd×dk 和 Wv ∈ Rd×dk 中。最后,自注意力机制利用投影矩阵 Wo ∈ Rdk×d 输出 ui = ziWo + hi。
前馈步骤将 2 层多层感知器 (MLP) ψ : Rd → Rd 分别应用于每个向量 ui ∈ Rd。MLP 通常具有 ReLU 或 GELU 激活函数 [Hendrycks and Gimpel, 2016],在某些模型(例如 Llama)中,线性层的偏差设置为 0。我们分别用 Uin 和 Uout 表示此 MLP 的第一和第二线性层的权重矩阵。然后,这个第 l 个 Transformer 块的输出由 h(l) i = ψ(ui) + ui 给出。
总结一下,Transformer 架构的每一层都有以下权重矩阵 W = {Wq,Wk,Wv,Wo,Uin,Uout},此外还有用于嵌入输入标记的嵌入矩阵、在最后一层之后应用的投影权重矩阵(在采用 softmax 之前)以及与层规范化相关的所有权重矩阵。在我们的工作中,我们将主要关注 W 中的矩阵并通过修改它们进行干预。
秩 r 近似和 SVD。
给定一个矩阵 W ∈ Rm×n 和 r ∈ N,秩 r 近似问题需要找到一个矩阵 ˆW,使 ∥W−cW∥2 最小化,并满足秩 cW ≤ r。Eckart-Young-Mirsky 定理使用奇异值分解 (SVD) [Eckart and Young, 1936] 为该问题提供了最优解。形式上,矩阵 W 的 SVD 由 W = UΣV ⊤ 给出,其中 U = [u1, u2, · · · , um] ∈ Rm×m 和 V = [v1, v2, · · · , vn] ∈ Rn×n 和 Σ ∈ Rm×n。 U 和 V 的列向量分别构成 Rm 和 Rn 的正交基,Σ 是一个对角矩阵,其对角线项由 W 的奇异值按降序排列。也可以将 W 的 SVD 表示为 W = Pmin{m,n} i=1 σ↓ i (W)uiv⊤ i 。根据 Eckart–Young–Mirsky 定理,矩阵 cW = Pr i=1 σ↓ i (W)uiv⊤ i 是任意给定期望秩 r ≤ min{m, n} 的秩 r 近似问题的最优解。
在本文中,我们将使用高阶分量一词来指代 SVD 中与具有较小奇异值的分量相对应的条目。这些分量被 LASER 移除。术语低阶分量用于指代与较大奇异值相对应的奇异向量。这些分量保存在矩阵的低秩近似中
4、方案
在本节中,我们正式描述了 LASER 干预。单步 LASER 干预由三个量 (τ, ℓ, ρ) 定义,包括参数类型 τ、层数 ℓ 和秩降低 ρ。这些值共同描述了哪个矩阵将被它们的低秩近似替换以及近似的严重程度。参数类型对我们将要干预的矩阵类型进行分类。我们关注 W = {Wq,Wk,Wv,Wo,Uin,Uout} 中的矩阵,它们由 MLP 和注意层中的矩阵组成。层数描述我们干预的层(第一层从 0 开始索引)。例如,Llama-2 有 32 层,因此 ℓ ∈ {0, 1, 2, · · · 31}。最后,ρ ∈ [0, 1) 描述在进行低秩近似时应保留最大秩的几分之一。例如,令 τ = Uin ∈ Rd×d,则该矩阵的最大秩为 d。我们将其替换为秩 ⌊ρ · d⌋-近似。
图 1 显示了 LASER 的一个示例。在该图中,τ = Uin 和 ℓ = L,表示我们在第 L 层的 Transformer 块中更新 MLP 第一层中的权重矩阵。另一个参数(图中未显示)控制秩 k 近似中的 k。
LASER 会限制网络中某些信息的流动,令人惊讶的是,这可以产生显著的性能优势。这些干预措施也可以轻松组合——我们可以以任何顺序应用一组干预措施 {(τi, ℓi, ρi)}m i=1。LASER 方法是简单地搜索此类干预措施,并执行提供最大收益的修改。然而,还有许多其他方法可以组合这些干预措施,我们将此推迟到未来的工作中
5、实验
本节研究 LASER 对 Transformer 架构各个层的影响。我们首先结合预训练的 GPT-J 模型 [Wang and Komatsuzaki, 2021] 对 CounterFact [Meng et al., 2022] 问答数据集进行激励分析,并在研究潜在干预措施时研究模型的性能及其可变性。随后,我们研究了 LASER 对不同模型、数据集和模式的影响
GPT-J、CounterFact 和 PILE。我们使用在 PILE 数据集上预训练的具有 27 个层和 6B 个参数的 GPT-J 模型。我们分析的第一部分重点关注 GPT-J,主要是因为它的训练数据是公开可用的。我们在 CounterFact 数据集上评估了该模型的行为,该数据集由以(主题、关系、答案)三元组形式组织的样本和每个问题的三个释义提示组成。例如,(Danielle Darrieux,母语,法语)。
5.1 使用 GPT-J 对 CounterFact 数据集进行彻底分析
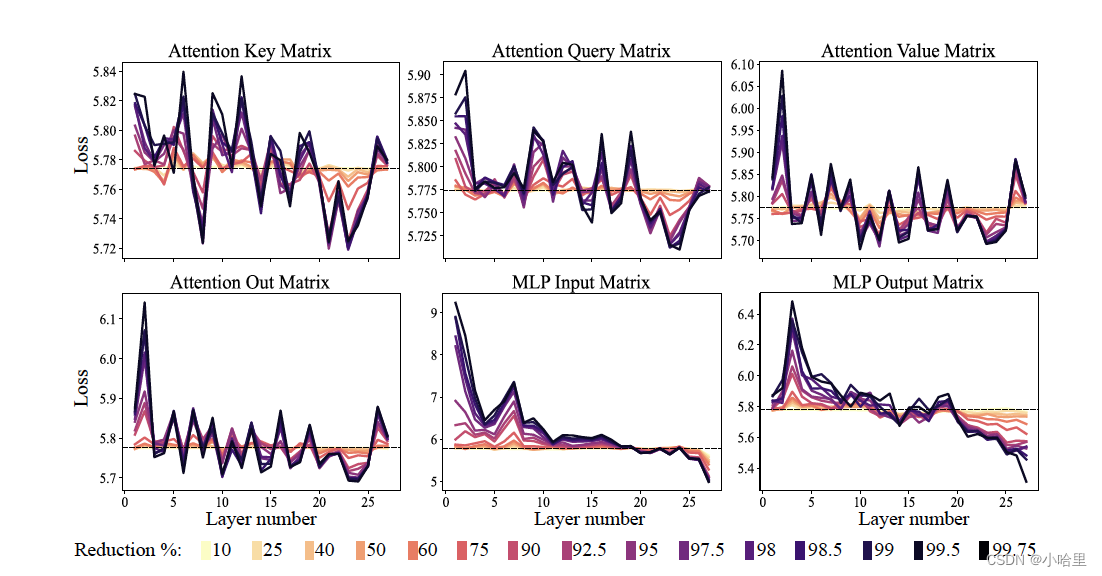
图 2:不同层类型之间的降阶效果并不统一。这里我们展示了在 CounterFact 数据集上研究的 GPT-J 的降阶效果。虚线是经过修改的网络的损失。在注意层(键、查询、值、输出矩阵)中,虽然很明显矩阵可以显著降阶而不会损害学习到的假设,但性能提升却很小。然而,对于多层感知器 (MLP) 层,降阶从均匀损害到提高模型的性能(大约在第 20 层)。
图 2 显示了对 Transformer 架构中的每个矩阵应用不同程度的降秩后的结果,以及该数据集的分类损失。这些图被分组,使得每个子图仅对应于指示类型的权重矩阵。请注意,每个 Transformer 层都由一个小型的两层 MLP 组成。组成输入和输出矩阵分别显示。不同的颜色表示移除组件的不同百分比。
该图中的注意力图举例说明了这些模型的已知信息:权重矩阵可以大幅减少,而不会对模型性能造成太大影响。然而,更有趣的结果是在 MLP 层中。在这里,不仅可以在不降低分类性能的情况下对矩阵进行降阶,而且可以通过减少模型的后续层来大幅提高性能。这种趋势在 MLP 的输入矩阵中最为明显。虽然 LASER 在注意力层中也有所提升,但收益通常较小。在接下来的部分中,我们将展示 LASER 在各种数据集和 Transformer 模型中的有效性。由于彻底搜索可能需要大量计算,并且一致的改进似乎集中在减少 MLP 层上,因此本节之后的所有结果都仅考虑对这些层进行简化搜索,除非另有说明。
提高了释义的准确性和鲁棒性。
CounterFact 数据集用于测试模型对 Wikipedia 数据的事实知识。由于 GPT-J 是在 PILE 上训练的,其内容包括 Wikidata,因此 CounterFact 中的不同事实是模型训练数据的一部分,尽管数量不同。由于在此设置下所有答案都是单个标记,因此我们根据正确答案是否在前 k 个预测标记中来计算前 k 个准确率。如图 2 和表 1 所示,我们发现,当在单层上进行缩减时,模型对 CounterFact 中事实的 top-1 准确率从 13.3% 提高到 24.1%。值得注意的是,这些改进仅仅是降阶的结果,不涉及对预先训练的 GPT-J 模型进行任何进一步的训练或微调。此外,降阶带来的改进是系统性的。模型正确得到的数据点集只会随着减少量的增加而增长,而不是数据点随机地进出集合或正确项目;如果模型在一定程度的降序 (x) 下得到正确答案,则该模型在更大的降序 (y,其中 y > x) 下继续得到正确答案。我们通过计算模型正确得到给定问题的所有释义的数据点百分比来评估模型对释义的稳健性。对于模型已经正确的数据点,模型对释义的稳健性也随着 LASER 提高了大约 24.8 个百分点。
对语言建模和流畅度的影响。
虽然模型的真实性有所提高,但这种降低是否会影响模型在其他指标上的表现?为了理解这一点,我们评估了模型在其训练数据上的困惑度,即其原始训练目标。对于与 MLP 输入矩阵相对应的层,模型的困惑度从 4.8 增加到 5.0,表明语言建模目标确实受到了轻微影响。对于 MLP 输出层,GPT-J 在 PILE 上的困惑度从 4.8 增加到 LASER 上的 4.9。通过校准模型的温度,可能可以修复这个小的退化。
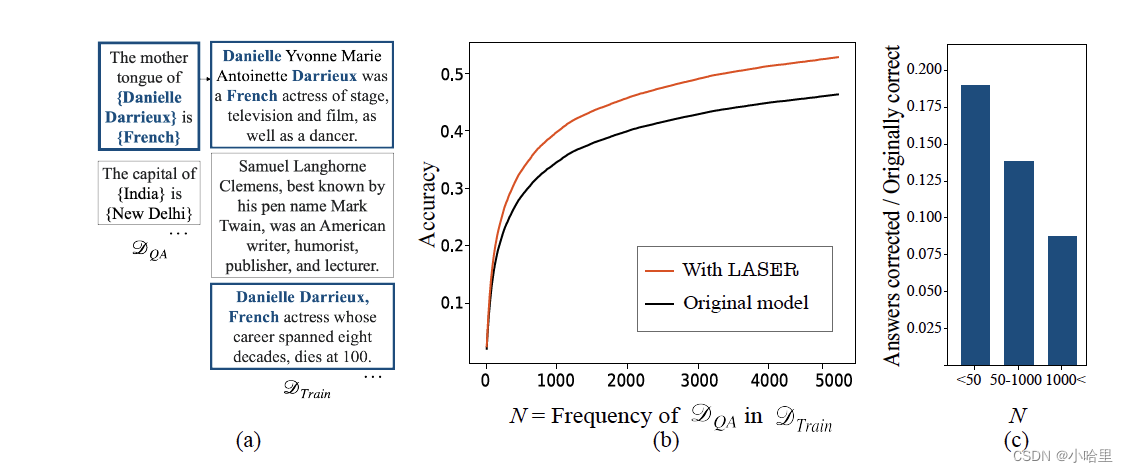
图 3:哪些数据点受益于 LASER?我们分析训练数据中“更正”事实出现的频率。GPT-J 是此类分析的理想测试平台,因为它的训练数据 (DTrain),即 PILE 数据集,是公开可用的。(a)对于在 CounterFact (DQA) 上评估的 GPT-J,我们检索 DTrain 中包含感兴趣的实体和与 DQA 中的每个样本相对应的答案的所有数据点。(b)描绘模型在训练数据中出现的频率小于或等于 x 轴上指示的频率的所有数据点上的累积前 10 名准确率的图。这里我们展示了有无 LASER 的准确率。(c)性能提升最大的是低频样本。此条形图显示了 LASER 为按 DTrain 中相应事实出现的频率分类的数据提供的提升量。准确率的最大改进来自训练数据中出现频率较低的数据点
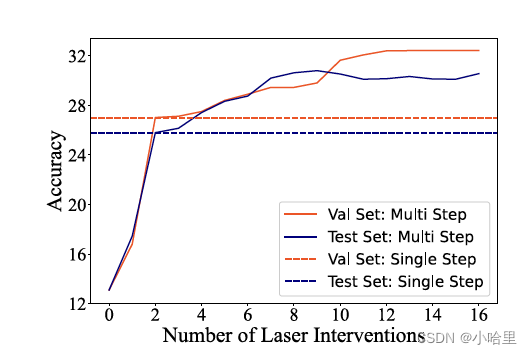
图 4:跨多层组合 LASER 操作可进一步提高模型性能。这里我们展示了使用简单的组合策略对验证数据(用于识别每个 (τ, ℓ, ρ))和测试数据进行准确率提升的方式
跨层组合降维。
我们发现,通过在多个层上执行不同程度的降维,可以进一步提高模型的性能。这是通过从最大的 ℓ 和最小的 ρ 开始贪婪地搜索 (τ, ℓ, ρ) 来完成的。为了加快速度,我们只在 MLP 层上进行搜索,因为这通常是可以找到最大改进的地方。与其他实验一致,搜索是在验证集上进行的,并在测试集上报告结果。在 CounterFact 上,基础 GPT-J 模型的 0-1 准确率为 13.1%。在执行最佳单步 LASER 后,模型的准确率提高到 24.0%。在不同层上执行 LASER 将前 10 名的准确率提高到 29.2%,与在单层上执行 LASER 相比,准确率绝对提高了 5.2%。不同 ℓ 和 ρ 值的组合搜索结果可以在图 4 中看到。
5.1.1 数据集中的哪些事实是通过降阶恢复的?
为了理解这一现象,我们研究了 LASER 之后正确回答的问题,以及与问题相关的信息在训练数据中出现的频率的影响。对于 CounterFact 中的每个数据点,我们检索 PILE 中包含实体和答案的所有示例。然后,我们计算与每个评估问题相关的信息在训练数据中出现的频率。我们发现,在降阶后恢复的事实很可能很少出现在数据中(图 3)。这里,“最初正确”描述的是即使没有任何干预也能正确分类的样本。“答案已纠正”是指模型只有在使用 LASER 进行干预后才能正确回答的问题
5.1.2 高阶组件存储了什么?
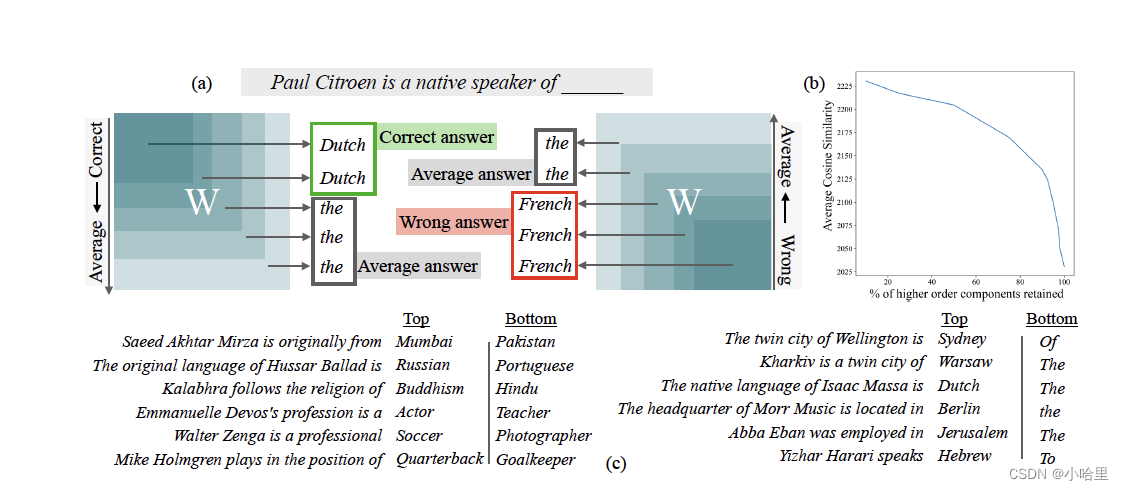
图 5:(a) [左] LASER 通过其低阶分量来近似学习矩阵。我们发现,对于模型预测在 LASER 之后有所改善的数据点,如果我们改用整个矩阵(包括高阶分量),模型通常只会预测“通用”单词。(a) [右] 为了了解这些高阶分量编码的内容,我们改用高阶分量来近似学习权重矩阵。我们发现这些高阶分量有时会编码答案的正确语义类型,但编码错误的响应。(b) 从分析上看,计算语义相似度(真实答案与奇异向量底部 k% 生成的答案之间的余弦距离)表明,平均而言,高阶分量计算出的答案与真实答案更相似。© 显示了数据集中的一些示例以及由分量的顶部分数和底部分数计算出的相应答案
我们在上面看到了保留低阶成分如何提高开放式问答任务的模型性能。我们发现,对于问答任务,改进通常出现在那些答案由训练集中出现频率较低的数据支持的问题上。虽然很明显,消除高阶成分会“降低”模型的噪声并有助于恢复“隐藏的”、不太频繁的信息,但尚不清楚高阶成分代表什么,以至于它们的去除会提高性能。本节使用 CounterFact 数据集和 GPT-J 研究这个问题。
为了理解高阶分量代表什么,我们使用最终权重矩阵的高阶分量来近似(而不是像 LASER 那样使用低阶分量来近似),如图 5(a) 所示。接下来,我们分析模型在数据点上的行为如何变化,这些数据点是 GPT-J 最初得到不正确的,但在执行 LASER 后被翻转为正确的。
首先,我们注意到,当原始的、未经修改的模型不能正确回答这些问题时,它通常会用常用词来回答,例如“a”、“the”、“of”和其他高频词。在执行 LASER 后,我们只保留前 k 个组件,模型对这些问题的答案从通用词变成了正确的实体。对于相同的数据点,当我们通过保留高阶组件来近似模型时,我们发现模型要么预测与正确答案具有相同语义类型的错误实体,要么预测诸如“a”、“the”和“of”之类的高频词,如图 5© 所示。然而,当我们系统地包含低阶组件时,模型的输出会变为预测频繁的词。
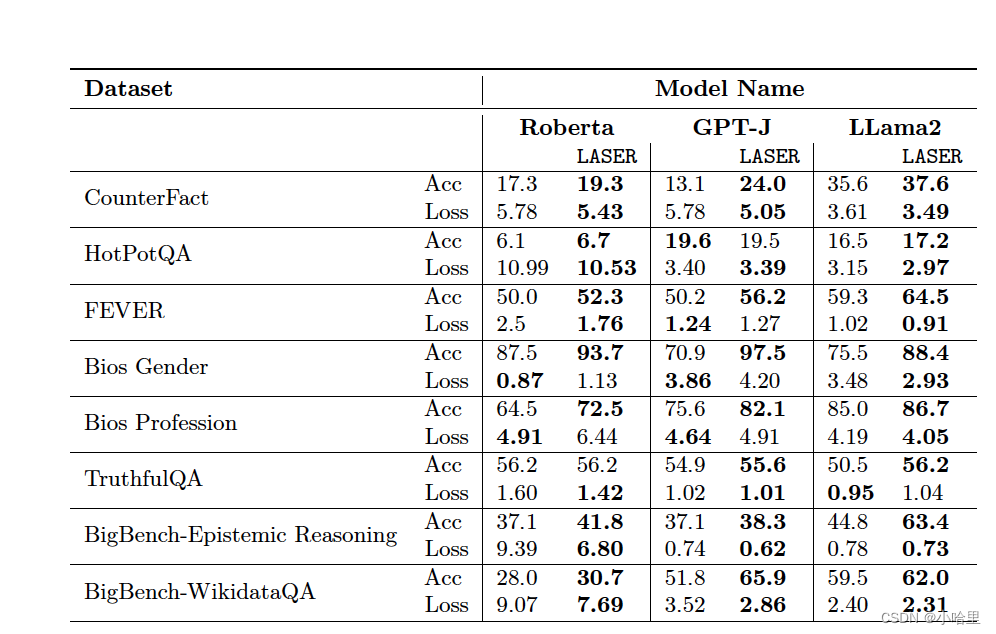
表 1:LASER 干预对八个自然语言理解数据集的影响。我们使用验证集上的准确率/0-1 为每个模型和任务找到最佳的 LASER 干预,并在保留的测试集上报告其性能。在某些情况下,虽然模型的准确率有所提高,但其损失略有恶化。
为了研究这种系统性退化,我们测量了当矩阵用不同数量的高阶组件近似时“真实”答案相对于预测答案的平均余弦相似度,如图 5(b) 所示。预测答案之间的平均余弦相似度恶化,证明了这种影响。我们假设这些矩阵通常编码多个相互冲突的响应,并且当使用所有组件时,它们会发生冲突以产生通用标记。删除高阶组件(据说这些组件通常捕获正确类型的错误响应)可以解决这种内部冲突并允许模型准确响应
5.2 这种说法普遍适用吗?
我们针对 3 个不同的 LLM 针对几个语言理解任务评估了我们的研究结果的普遍性。
自然语言理解任务。
我们在七个数据集上评估了 LASER 之前和之后的模型性能,包括 CounterFact [Meng et al., 2022]、HotPotQA [Yang et al., 2018]、FEVER [Thorne et al., 2018]、Bias in Bios [De-Arteaga et al., 2019] [性别和职业]、TruthfulQA [Lin et al., 2021]、BigBench-Epistemic Reasoning [Bowman et al., 2015] 和 BigBench-WikidataQA。这些数据集评估了语言理解问题的不同方面。CounterFact、Fever 和 Bigbench-Wiki 数据测试了模型的世界知识和事实性。Bias in Bios 通过根据简短的个人简介预测一个人的性别和职业来对模型偏差进行基准测试。我们将 Bios Gender 定义为 Bias in Bios 中的性别预测问题,将 Bios Profession 定义为职业预测问题。HotPotQA 提供了更具挑战性的开放式问答任务,其长答案包含许多标记。Big Bench Hard (BBH) 的 Epistemic Reasoning 数据集测试模型的逻辑和阅读理解能力。最后,TruthfulQA 测试 LLM 的真实性。我们使用 20% 的数据集作为验证集,并使用此验证集选择最佳 LASER 超参数 (τ、ℓ、ρ)。我们报告使用所选超参数对其余 80% 数据集的结果。用于问答任务的模型包括 Roberta [Liu et al., 2020]、GPT-J (6B) [Wang and Komatsuzaki, 2021] 和 LLAMA2 (7B) [Touvron et al., 2023]。有关数据集及其使用方式的详细信息,请参阅附录 A。
评估指标。
对于每一项任务,我们使用以下指标评估模型的性能:(i) 生成准确度。我们使用 LLM 生成 N 个标记序列,然后如果答案文本在生成的文本中则报告 1,否则报告 0;(ii) 分类准确度。如果答案位于一小组潜在值中,例如在标准分类问题中,如果答案将更多的概率质量放在正确答案上而不是放在任何其他候选答案上,则我们认为该响应正确;(iii) 损失。我们报告保留数据的对数损失。对于具有一小组可能标签的数据集,我们使用分类准确度报告准确度 (acc),而对于其他数据集,我们使用生成准确度
我们通过评估不同基准上的一系列语言模型来测试此结果的普遍性。如表 1 所示,我们发现即使大幅减少也不会导致模型的准确性下降,反而可以提高其性能。所需的减少量因模型而异。
5.3 非文本域
为了了解这种现象在文本领域的问答之外是否有效,我们评估了降阶对强化学习代理的影响。
策略学习。
对于策略学习,我们评估了 LASER 对在 Sokoban 游戏上训练并在同一游戏上进行评估的决策 Transformer 模型的影响。这是一个具有挑战性的规划问题,其中代理必须移动并将几个块推到洞中。当所有块都在洞上时,任务完成。决策 Transformer 的输入是给定状态下环境的视觉状态,输出是低级动作。我们发现,对于在 Sokoban 上训练的决策 Transformer,模型使用 LASER 解决了 3% 以上的任务(表 2)。实验的详细信息可以在附录 B 中找到。
尽管改进幅度小得多,但无论减少程度如何,改进都是一致的。这可能是因为该现象是文本特有的,或者需要足够大的 Transformer 模型。

6、结论
本文介绍了 LASER,这是一种现象,即在 Transformer 块的特定层上对特定层类型进行低秩近似可以提高 LLM 在问答任务上的性能。我们发现这在五个不同的数据集和三个不同的语言模型中都是如此。此外,由此产生的 LASER 减少是极端的。矩阵有时会减少到其原始秩的 99%,这比其有效秩 (C.1) 低得多。然而,尽管极端减少,模型在任务上的性能仍在继续提高。我们还观察到决策 Transformer 在具身域中的性能提升。我们发现模型准确度的最大改进对应于训练数据中不太常见的信息,并且 LASER 共同使模型对问题的释义更具鲁棒性。我们进一步发现,其中一些矩阵的高阶分量编码了高频词或与正确答案具有相同语义类型的备选答案。这些嘈杂的高阶分量可能会压倒稳定的低阶分量,导致模型回答问题不正确。在这些情况下,进行激光治疗可作为一种去噪技术,减少潜在反应中的内部冲突
尽管进行了这样的分析,LASER 的成功仍需要进一步研究。了解 (i) 为什么权重矩阵中的高阶分量会在训练过程中积累噪声答案,(ii) 模型架构和其他结构选择对这种现象发生的影响,以及 (iii) 为什么这种情况特别适用于 MLP 中的后续层,这不仅对我们理解 LASER 的成功很重要,而且对于更广泛地理解大型语言模型的行为也很重要。

