
- 1028:vue+openlayers使用geojson数据加载热力图_openlayer热力图需要的数据
- 2三元运算符以及if ,for ,while ,do...while结构,流程控制_三元操作符和if
- 3如何用golang实现一个简单的区块链结构_通过定义区块结构体实现区块的生成功能,之后验证区块的合法性并实现区块的顺
- 4基于SpringBoot+Vue的图书借阅系统(源码+文档+部署+讲解)_vue3图书馆借阅系统需求项目描述
- 5智慧养老系统(社区+居家+机构养老)
- 6AI与艺术——图像生成网络经典算法_图像生成算法
- 711.区块链系列之NFT从零到一开发及比特币NFT_nft开发
- 8工作一年的小鸟
- 9Android识别模拟器,判断是模拟器还是真机_项目方是如何知道用户用的是手机模拟器
- 10自制一个桌面宠物小狗(STM32hal库+ADC+IIC+DMA+PWM输出波)_stm32桌面小宠物
中国版 LMSYS 来了!扣子模型广场带来了什么?
赞
踩

这场由字节豆包引发的大厂至创业公司都杀疯了的国产大模型价格战,让大模型从卷价格的 PK 陡然卷到了质量、实打实的产品力竞争上来。当模型 API 迎来免费浪潮之际,AI 原生应用进一步成为了大模型厂商的“兵家必争之地”,也让无数想要使用大模型大展身手的用户们迎来了将创意落地应用的机会。
2023 年 11 月,OpenAI 发布了 GPTs ,并于今年初推出了 GPTs 商店,这一系列的动作,让普通开发者使用大模型创建出独有的 AI Agent 产品。在近期,OpenAI 也将 GPTs 的使用权限开放给全部用户,让 AI 逐步走向了大众化,普通用户可以深入其中感受到 AI 的魅力。
对于专业的开发者,可以使用诸如 LangChain 等开源框架快速搭建出自己的智能体,用于完成各种复杂的任务。但这些开源的框架对于众多完全不懂编程的用户而言,使用的门槛、成本都非常高,要想实现一个 AI 原生应用还需做大量的前期准备。于是,大模型打响的应用第一战,便是将门槛降到最低,无需编程经验,即可快速创建智能体,其中字节跳动的扣子(coze.cn)便是代表之一,直接集成了多个国内知名大语言模型,包括豆包、通义千问、智谱、MiniMax、Moonshot 、Baichuan等。
至此,选择模型就变得很方便,然而令人头疼的是,截止目前,大模型的数量已经多达 300 个,每个模型的能力表现上可能会有一些差距,有些模型可能在语言理解与生成很强,而有一些模型在逻辑推理上更胜一筹。对于 AI 原生应用开发者来说,要选择一个合适自己的大模型着实不易。要让我们创建的智能体有一个很好的运行效果,往往还需要一遍一遍地进行调整。
于是,对于用户而言,横亘在面前的一大问题就是,究竟该怎么选择趁手的模型呢?

大模型竞技场:盲测模型,先用后选
目前,各大模型公司在发布模型时,一般情况下都会对标 GPT-4 ,公布测试评分。这些评分包括如中/英文综合理解、知识、基础算数、数学解题、逻辑推理、指令遵从等方向测试的结果,这也是业界公认的数据。除此之外,还会有一些三方的企业,站在客观中立的角度,针对大模型构建一些私有的测试集,用于对大模型的能力进行评估,更好地体现出市场上模型的能力,这些测试集的维度包含语言理解与生成、专业技能与知识、安全性等方向。
也正是出于模型效果孰优孰劣的考虑,各式模型评测层出不穷。2023 年,大模型评测领域出现了很多复杂且充满挑战的测评风波,业界对测评标准的公正性与专业水平提出了更高要求。
在此背景下,LMSYS Org 提出了创新型的“实战竞技”模式,发布 Chatbot Arena ,以盲测的方式,由用户在模型匿名的前提下对模型效果进行打分,颇受业内认可,已经成为 OpenAI、Anthropic、Google、Meta 等国际大厂的大模型竞技场。比如在 OpenAI 正式发布 GPT-4o 之前,其便化名“gpt2-chatbot”现身 LMSYS Chatbot Arena,经过用户匿名实测,排名直超 GPT-4 Turbo、Gemini 1.5 Pro 等。
在 Chatbot Arena 的评测体系中,用户不知道当前具体使用哪个模型,而是先在聊天框里输入 Prompt,根据模型的回答质量满意度进行投票,投票后会显示出所用模型来。使用这种评价体系最大优势在于其公平性,评审者只能根据模型的性能表现进行打分,避免了“先入为主”的偏见,让真正优秀的模型脱颖而出。
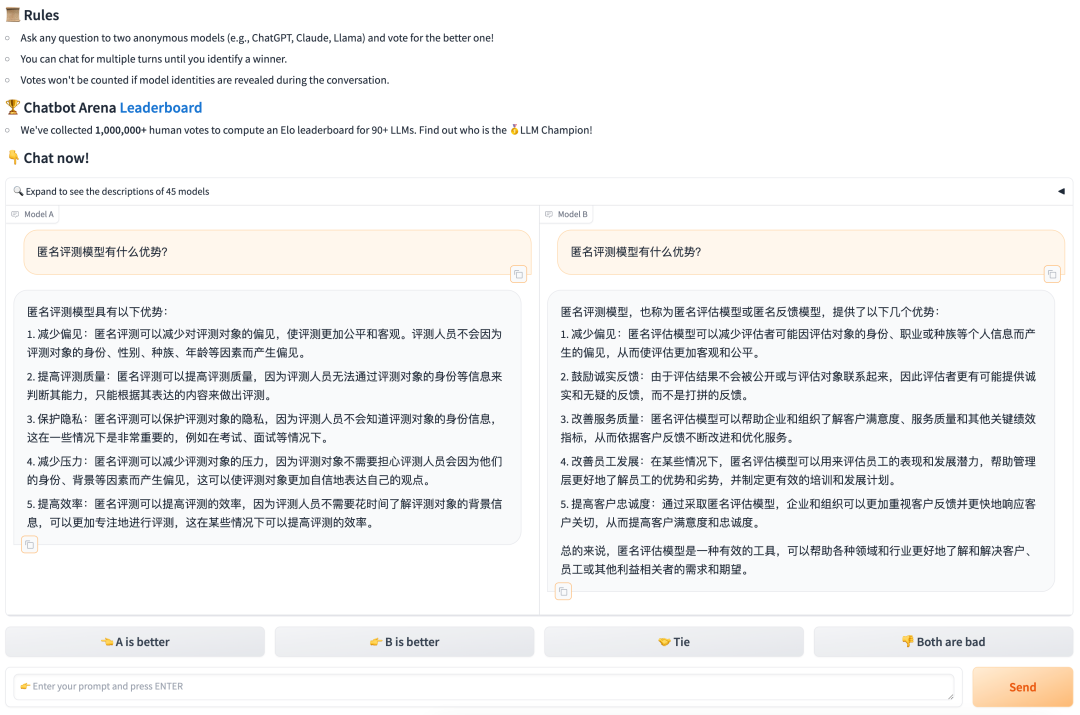
然而在大模型评测中,这种匿名测试还存在一些问题,比如模型的设计往往与其目标应用场景密切相关,而使用通用的 Prompt ,不能很好地表现出模型在其特定领域的能力。并且,大模型对 Prompt 很敏感,有时候仅仅是修改一下 Prompt ,对大模型输出结果的评分就会出现超过 10% 的扰动。
基于这样的需求及痛点问题,扣子模型广场应运而生。其不仅如 LMSYS Chatbot Arena 一般支持模型随机、匿名地对决,而且还支持基于 Bot 进行对战 PK,开发者可以很方便地使用对战功能,更直观地了解模型最擅长的能力。

扣子模型广场:告别模型选择困难症
如前文所说,现阶段评估报告能从一定程度上反映一个模型的强弱,但对于一个 AI 原生应用的开发者来说——特别是不怎么了解大模型的人,这些测试结果可能很难让他们做出决策。在这些评估报告的数据表现上,所有的大模型能力都很强。但在真实的应用上表现如何?却是非常难以评估的。为了让 AI 原生应用开发者找到合适自己的大模型,「扣子」给出了它的答案。
首先「扣子」会将很多的大模型接入到平台中,开发者只需要点点鼠标就能轻松切换模型,不需要进行二次开发,几乎没有迁移成本,让开发者能够以最低成本使用任何大模型。这也让开发者没有了后顾之忧。
其次,在「扣子」 的模型广场中,也引入了匿名模型对战功能。开发者也是点点鼠标就能运行一次实时对战,轻松看到不同模型在基础能力上、特定场景中的区别,也方便对模型响应速度与稳定进行对比,从而选出最佳的模型。
基于对模型通用能力、细分领域的表现等方向,模型广场提供了三种模型对战的模式:
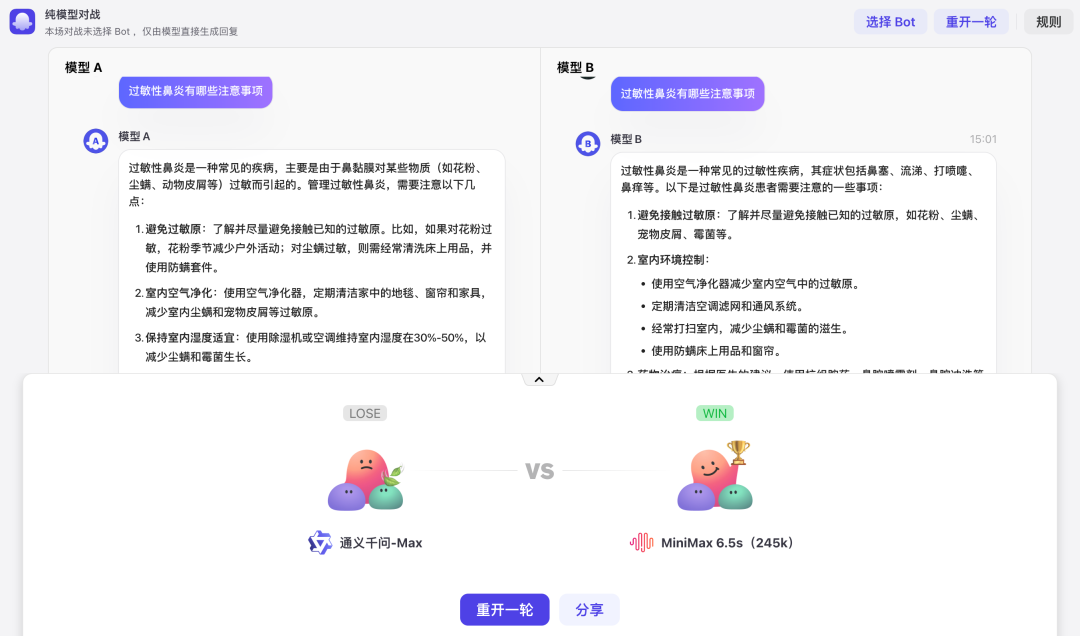
纯模型对战:这是一个和 Chatbot Arena 类似的能力,针对模型通用能力的一个评分,在运行过程中,不会受到 Bot 内置的 Prompt 、任务流等的影响。用户在匿名的情况下,系统随机选择两个模型展开对决。用户可以与匿名模型进行多轮对话,最后,用户根据模型的性能表现进行打分。当然,这种对战模式主要是用于评价大模型的基础能力,用户能够比较直观地感受到模型之间的差异。
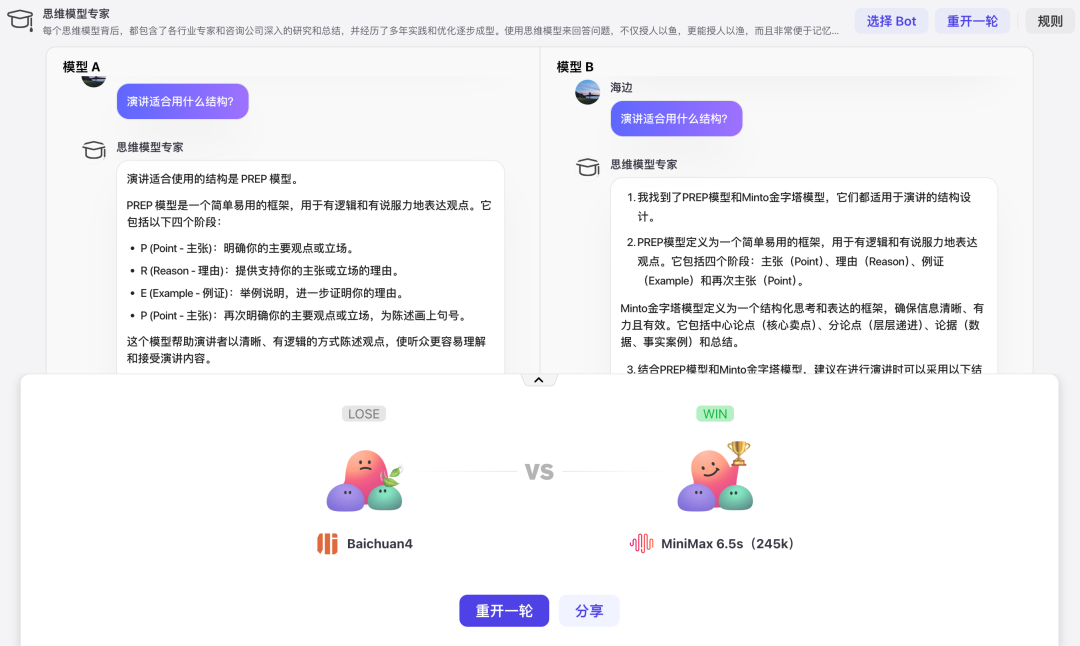
指定 Bot 对战:这种方式适用于评测模型在指定细分领域的能力,这应该也是普通开发者最喜欢的一种方式。用户可以选择感兴趣的 Bot 或者是刚开发完成的 Bot,启动对战时,「扣子」会随机选取两个匿名模型,根据 Bot 配置的 Prompt 、任务流、知识库等信息进行回答。用这种方式,可以轻松的选出哪个模型适合你的 Bot 。
随机 Bot 对战:除了模型基础能力与指定细分领域的能力外,模型在一些通用能力如技能和知识调用也是重点关注的一环,在此对战模式下「扣子」会在平台上线的 Bot 中随机选择一个 Bot,并随机选择两个匿名模型进行对战,以达到评测模型在任意业务场景下真实运行的能力。
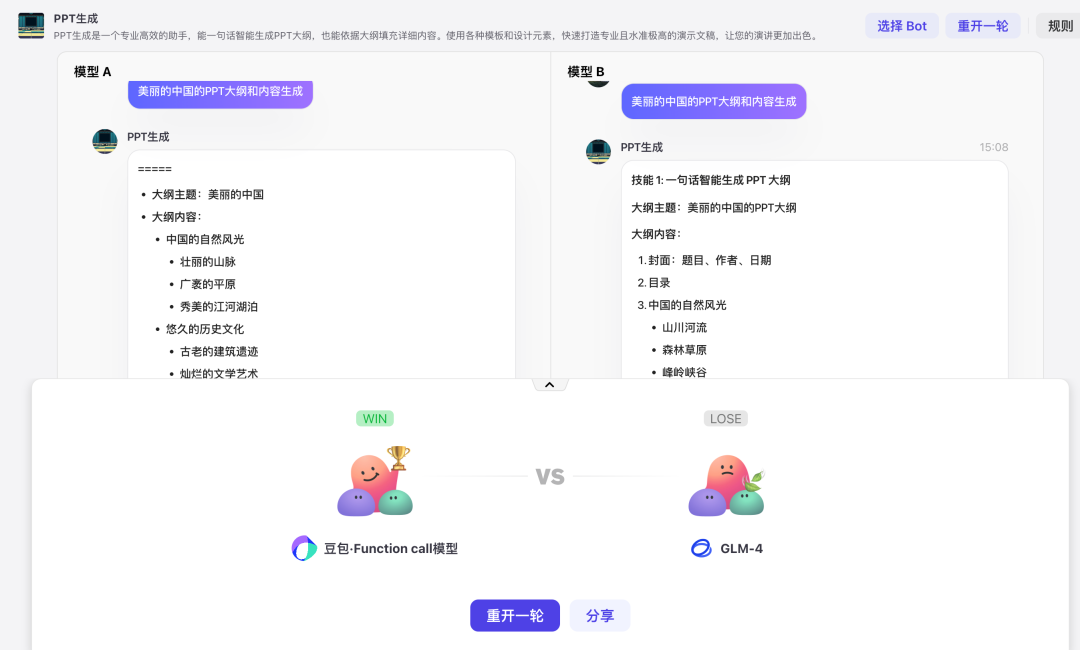
扣子模型广场通过接入足够多的模型,降低模型切换成本和通过模型对战选取最优模型,帮开发者解决模型选择的难题。在模型对战中,也让大模型厂商知道自家模型的能力边界,促进大模型厂商定点解决具体问题,更好地推动整个大模型生态的发展。

未来,人人都能开发智能体
我们都知道,要开发一个智能体,模型非常重要,但智能体需要的记忆、需要外部知识源、需要的很多工具也很重要。
笔者发现,在扣子 AI 应用开发平台中, 不仅解决模型选择的难题,同时为用户们提供了很多有用的工具,无论是否有编程基础,都可以在扣子上快速搭建基于大模型的各类 Bot。在首页的 Bot 商店中,可以看到,目前平台上已经非常丰富的 Bot 可供大家使用。
作为开发者的我们,当时是想实现一个自己的 Bot,为其他人提供帮助。当然,开发者最关心的整个应用生态。在扣子平台中为 Bot 提供了插件扩展的能力、知识库存储的能力,还有记忆能力。扣子同时还是一个社区,平台中还有插件商店、工作流商店。在创建 Bot 时,并不是所有的能力都需要自己去做,可以在商店中选择你需要的能力,快速构建你的智能体。
当前,「扣子」与 Intel 联合推出了主题 Bot 征集活动 —— 扣子 AI 工坊( Coze AI Factory),涵盖图文创作、实用工具、互动创意三大赛道,零基础、超低门槛。笔者认为,这有助于让人人都能成为开发者,只要你有想法,就能参与到 AI 智能体的创建中,在这波 AI 浪潮下,感受 AI 的魅力。

扣子 AI 模型广场全新上线,点击「阅读原文」即刻体验!

