
- 1生成3的乘方表 (15分)_7-13 生成3的乘方表 分数 15 作者 c课程组 单位 浙江大学 输入一个非负整数n,生成
- 2读书笔记-增强型分析:AI驱动的数据分析、业务决策与案例实践_增强型分析 ai
- 3PHY RGMII Interface Timing注意事项_rgmii-rxid
- 4三分钟彻底搞懂PostgreSQL 和 MySQL 区别之分_postgresql和mysql区别
- 5如何更改电脑密码?让黑客无机可乘!
- 6深入理解PHP的$_SESSION机制
- 7Fastjson反序列化漏洞(自学)_fastjson反序列化漏洞利用链
- 8计算机毕业设计springboot健康监测管理系统7f3049【附源码+数据库+部署+LW】_springbooth睡眠检测
- 9智能客服_qa机器人
- 10elasticsearch 对 SQL的支持_es的客户端支持sql语言开发吗
Prompt Engineering(提示词工程)- 典型构成、原则与技巧,代码中加入Prompt_提示词工程设计
赞
踩
从这篇文章开始,我们就正式开始学习AI大模型应用开发的相关知识了。首先是提示词工程(Prompt Engineering)。
0. 什么是提示词(Prompt)
AI大模型火了也已经有一年多了,相信大家或多或少都听过或见过一个词叫“Prompt”,这就是提示词。
用户给大模型输入一个Prompt,大模型会根据你的Prompt给出一个回复,这是目前为止,最常用的使用大模型的方法。网络上很多号称“不用编程,轻松实现自己的应用、助理”等,都是基于Prompt来做的。即使是需要通过编程的方式来使用大模型达到自己需求的,过程中也会大量使用Prompt,将Prompt固化到程序中,作为“代码”的一部分。
所以,在现在的AI时代,Prompt也可以看作是一门【编程语言】 ,最近新兴了一个职业叫做【提示词工程师】,也就类似是AI时代的程序员。
现在Prompt工程并没有形成一套完整的标准化体系,网络上关于如何使用Prompt的文章也是铺天盖地,非常杂乱,让人眼花缭乱。因为本人想以实战为主,因此本文只是总结一下Prompt的最基本构成和原则。
重要提醒:
- Promt是一个需要不断优化的过程,没有哪一篇文章或哪一个Prompt是适用于所有场景,或者拿来直接可用的。
- 即使同一个场景,相同的Prompt,不同的大模型之间也会效果不同。如果换了大模型,提示词大概率需要重新优化。
- 所以不要光看网上的什么【最佳实践】,还是要下场实操,在不断迭代中学会优化Prompt的方法,才是最重要的。
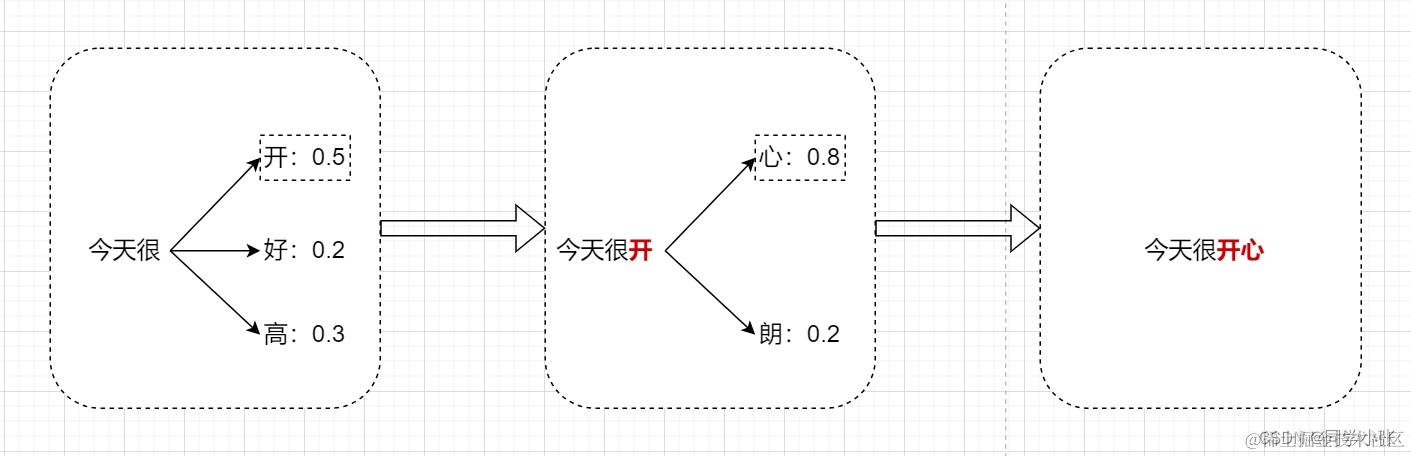
1. 为什么Prompt会起作用 - 大模型工作原理
简要概括:它只是根据上文,猜下一个词的概率,在前几个概率大的词中选择一个输出。
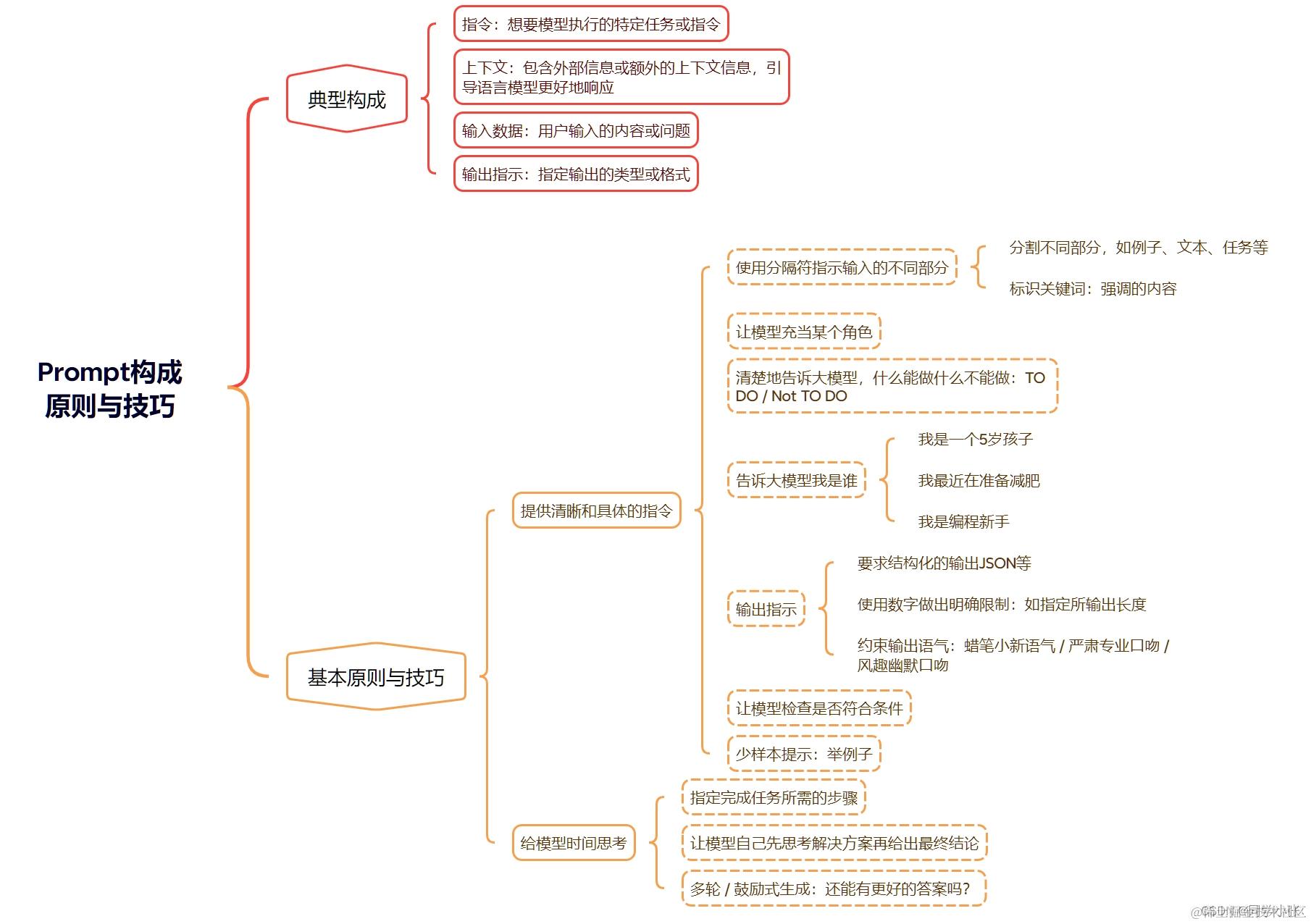
2. Prompt的典型构成、原则与技巧
3. 开始使用Prompt
如果不会编程,或不想写代码,可以直接在AI软件中使用Prompt,例如:
-
ChatGPT
-
文心一言
4. 代码中加入Prompt
4.1 OpenAI API解释
下面是上篇文章【AI大模型应用开发】0. 开篇,用OpenAI API写个Hello World !我们的“Hello World”程序,里面包含了一个函数chat.completions.create。
from openai import OpenAI
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{
"role": "user",
"content": "你是谁?"
}
],
)
print(response.choices[0].message.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
该函数有几个重要参数解释下:
-
model:用来指定使用哪个模型,例如:gpt-3.5-turbo-1106
-
messages:传入大模型的prompt,prompt有三种角色:
-
- system:系统指令,最重要,用于初始化GPT行为,以及规定GPT的角色、背景和后续行为模式。system是主提示,可以进行更加详细的设置。
- user: 用户输入的信息。
- assistant: 机器回复,由 API 根据 system 和 user 消息自动生成的。
-
temperature:参数值越小,模型就会返回越确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机、创意的结果,如诗歌、写作等,可以适当提高。
-
max_token:控制了输入和输出的总的token上限,要求我们的prompt不能太长,或者控制上下文轮次!(给你估算成本和节省成本用的)
-
Top_p:与 temperature 一起称为核采样的技术,可以用来控制模型返回结果的真实性。如果你需要准确和事实的答案,就把参数值调低。如果你想要更多样化的答案,就把参数值调高一些。
Temperature和Top_p,一般建议是改变其中一个参数就行,不用两个都调整。调了效果也不一定显著;
本篇文章就先写到这里,下篇文章我们开始在代码中将Prompt用起来,并尝试将一些技巧加进去看下效果。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/980035
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

