
热门标签
热门文章
- 1记录一次读取hdfs文件时出现的问题java.net.ConnectException: Connection refused_用tf接口读取hdfs数据时,出现connect
- 2使用Nodejs搭建HTTP服务,并实现公网远程访问「内网穿透」_node搭建的服务器怎么让外界访问
- 3智慧化工园区安全生产管理平台实现安全生产可视化的关键工具
- 4富文本编辑器TinyMCE使用方法
- 5是什么让 CSS 难以掌握_css is easy
- 6什么是支持向量机算法?它在机器学习中有什么优势?_支持向量机回归优点
- 7leetcode之Excel Sheet Column Title(168)
- 8创建大顶堆代码+时间复杂度详解+归纳过程!_如何构造大顶堆
- 9【Python系列】Python 方法变量参数详解_python方法参数
- 10关于redis的scan命令_golang scan redis match
当前位置: article > 正文
rostcm6情感分析案例分析_基于情感词典的情感分析方法
作者:黑客灵魂 | 2024-06-23 17:27:44
赞
踩
rostcm6情感分析
上节课我们介绍了基于SnowNLP快速进行评论数据情感分析的方法,本节课老shi将介绍基于情感词典的分析方法。基于情感词典的分析方法是情感挖掘分析方法中的一种,其普遍做法是:首先对文本进行情感词匹配,然后汇总情感词进行评分,最后得到文本的情感倾向。目前使用较多的情感词典主要有两种:一种是BosonNLP情感词典,另一种是知网推出的情感词典。
1.基于BosonNLP情感词典分析
BosonNLP情感词典是由波森自然语言处理公司推出的一款已经做好标注的情感词典。词典中对每个情感词进行情感值评分,BosonNLP情感词典大概如下图所示:
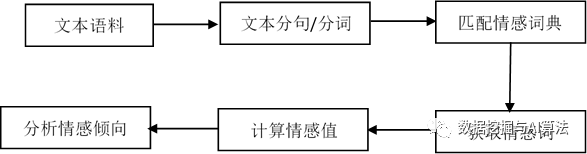
 基于BosonNLP情感词典的情感分析原理比较简单。首先需要对文本进行分句及分词,这里可以使用jieba分词。然后将分词好的列表数据对应BosonNLP词典进行逐个匹配,并记录匹配到的情感词分值,最后统计汇总所有情感分值。如果总分值大于0,表示情感倾向为积极的;如果总分值小于0,则表示情感倾向为消极的。其原理框图如下:
基于BosonNLP情感词典的情感分析原理比较简单。首先需要对文本进行分句及分词,这里可以使用jieba分词。然后将分词好的列表数据对应BosonNLP词典进行逐个匹配,并记录匹配到的情感词分值,最后统计汇总所有情感分值。如果总分值大于0,表示情感倾向为积极的;如果总分值小于0,则表示情感倾向为消极的。其原理框图如下:
 基于BosonNLP情感分析代码:
基于BosonNLP情感分析代码:
# -*- coding:utf-8 -*-import pandas as pdimport jieba#基于波森情感词典计算情感值def getscore(text): df = pd.read_table(r"BosonNLP_dict\BosonNLP_sentiment_score.txt", sep=" ", names=['key', 'score']) key = df['key'].values.tolist() score = df['score'].values.tolist()# jieba分词 segs = jieba.lcut(text,cut_all = False) # 计算得分 score_list = [score[key.index(x)] for x in segs if(x in key)]return sum(score_list)#读取文件def read_txt(filename):with open(filename,'r',encoding='utf-8')as f: txt = f.read()return txt#写入文件def write_data(filename,data):with open(filename,'a',encoding='utf-8')as f: f.write(data)if __name__=='__main__': text = read_txt('test_data\文本语料.txt') lists = text.split('\n')# al_senti = ['无','积极','消极','消极','中性','消极','积极','消极','积极','积极','积极',# '无','积极','积极','中性','积极','消极','积极','消极','积极','消极','积极',# '无','中性','消极','中性','消极','积极','声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/750178
推荐阅读
相关标签

