
- 1会话劫持 攻击:了解 和预防_会话数攻击
- 2vscode用git进行pull操作时提示:在签出前请清理存储库工作树_please clean your respository
- 3ShardingSphere系列01:Shardingjdbc实现分表(含项目实践)_shardingsphere分表
- 4时空预测 | 基于深度学习的碳排放时空预测模型_深度学习 发动机积碳预测
- 5互联网大厂职场各职级P6/P7和核心能力_大厂p7
- 6post formdata传值
- 72024年分布式场景下的并发安全问题,互联网行业“中年”危机_java并发安全问题案例分享
- 82022,银行数据能力怎么建?_如何构建商业银行的数据分析能力
- 9one-api离线安装解决failed to get gpt-3.5-turbo token encoder_failed to get gpt-3.5-turbo token encoder:
- 10全面理解Python中的迭代器_python 迭代器
机器学习实战1 泰坦尼克号沉船人员获救(随机森林)_泰坦尼克机器学习
赞
踩
预测泰坦尼克号沉船事件中哪些人员会获救?
目录
1. 背景
1912年4月15日,泰坦尼克号第一次远航,装上冰山后沉没,导致2224名人员中有1502名人员死亡。对于这些获救人员,是因为幸运获救还是因为有其他的因素影响?我们选择使用随机森林来对这个问题进行分析和预测。
随机森林就是通过集成学习的Bagging思想将多棵树集成的一种算法:它的基本单元就是决策树。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,其实这也是随机森林的主要思想--集成思想的体现。
我们要将一个输入样本进行分类,就需要将它输入到每棵树中进行分类。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。
2. 数据集
2.1 训练集(train.csv)
文件包括891条记录,11个特征,1个标签(0,1)。
2.2 测试集(test.csv)
文件包括418个待预测样本,11个特征。
3. 特征解读
| Passengeld | 乘客ID |
| Survived | 获救或死亡 |
| Pclass | 船舱等级 |
| Name | 姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟配偶 |
| Parch | 父母孩子 |
| Ticket | 船票信息 |
| Fare | 票价 |
| Cabin | 船舱信息 |
| Embarked | 港口 |
4. 解决思路
4.1.定义问题
4.2.收集数据
4.3.数据清洗
4.3.1 纠正:异常值
4.3.2 完整:补足缺失值
4.3.3构建:新的特征
4.3.4转换:字段格式替换
4.4.探索分析
4.5.数据建模
4.6.模型验证
4.7.模型优化
5. 实际操作
工具:anaconda
5.1 导入需要的库
5.2 收集数据
源数据集加载之后可以查看下数据:
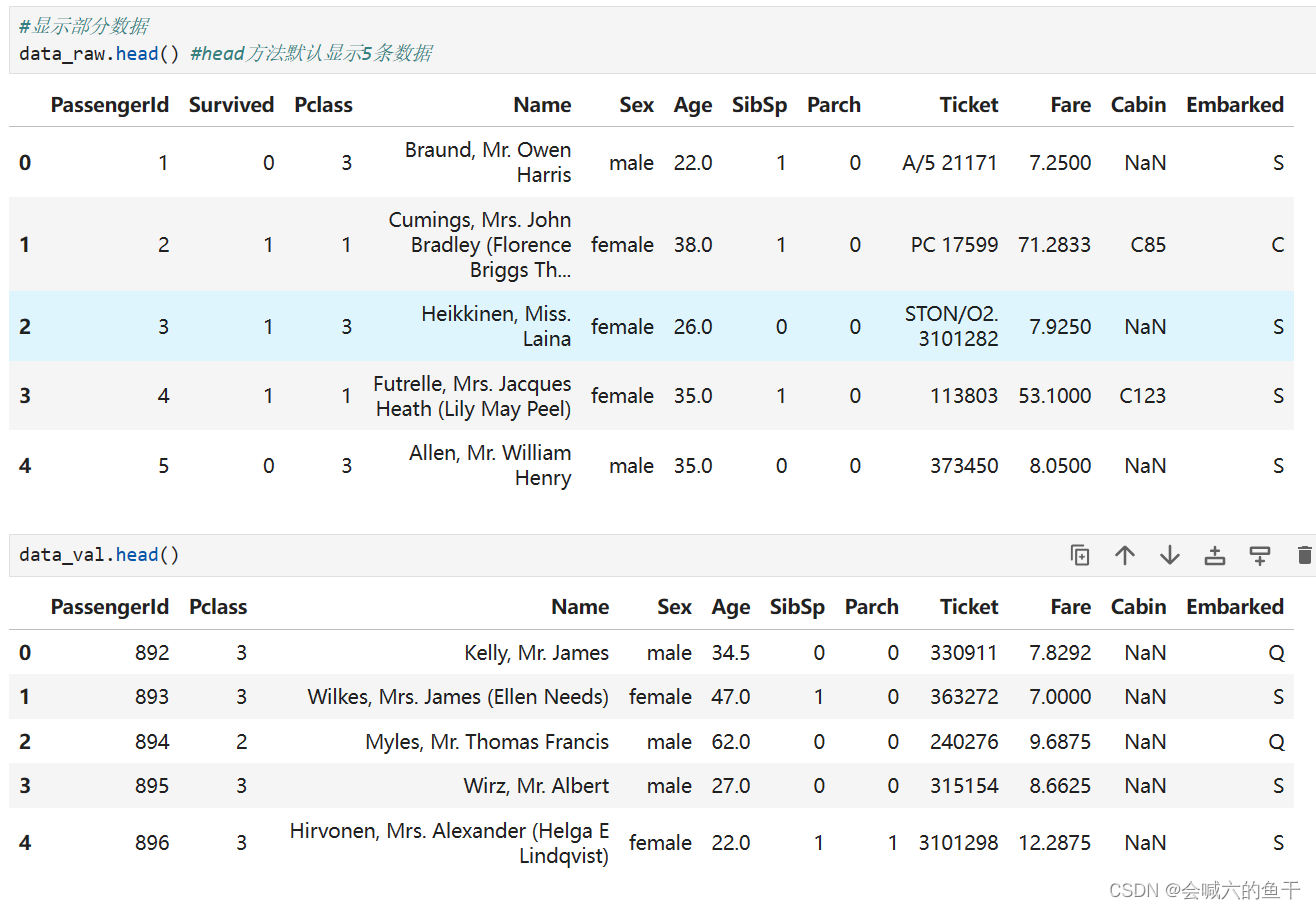
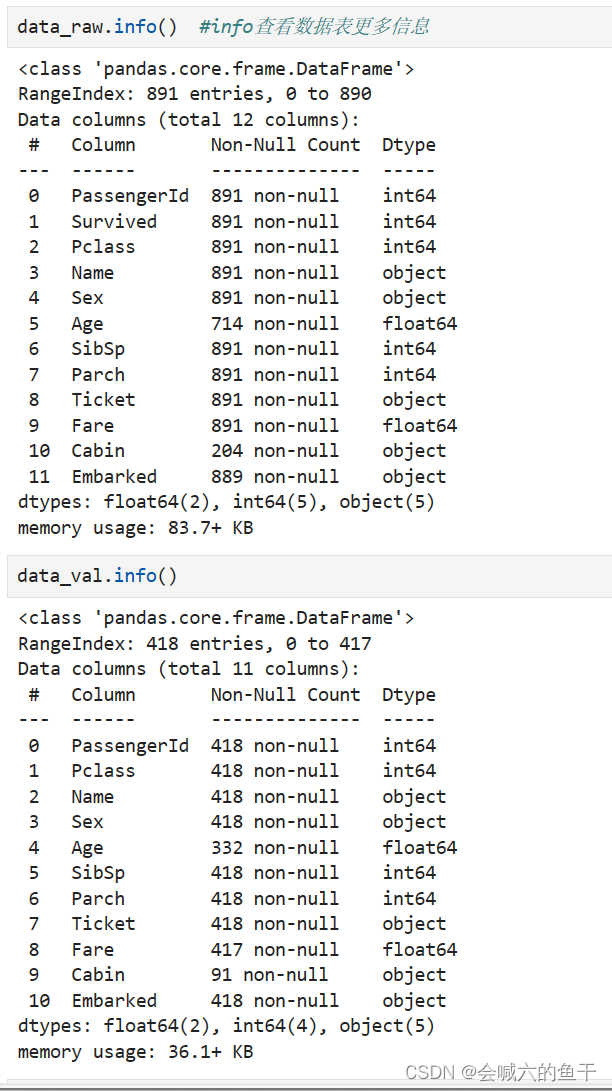
训练集的数据相比测试集的数据多出的Survived字段是生还结果,我们的目的就是预测出测试集的Survive。此外我们还可以查看下数据表的其他信息,例如每个字段有多少条数据,数据是什么类型等等。
为了之后处理数据方便,可以将列名称转换成小写(看个人喜好)
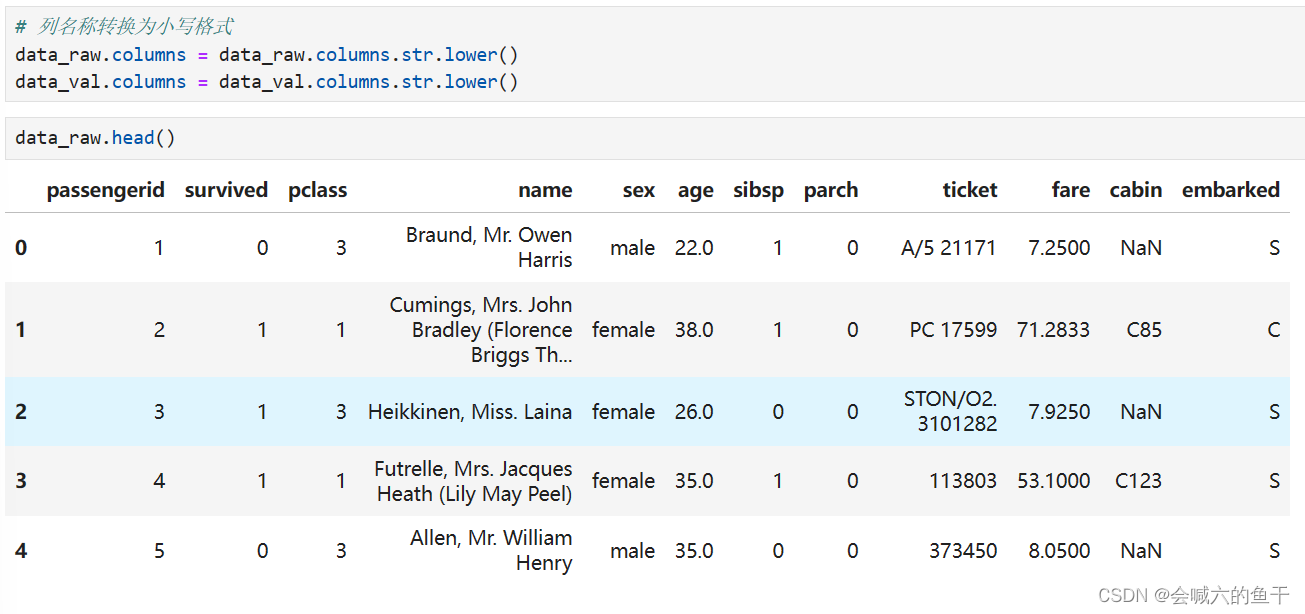
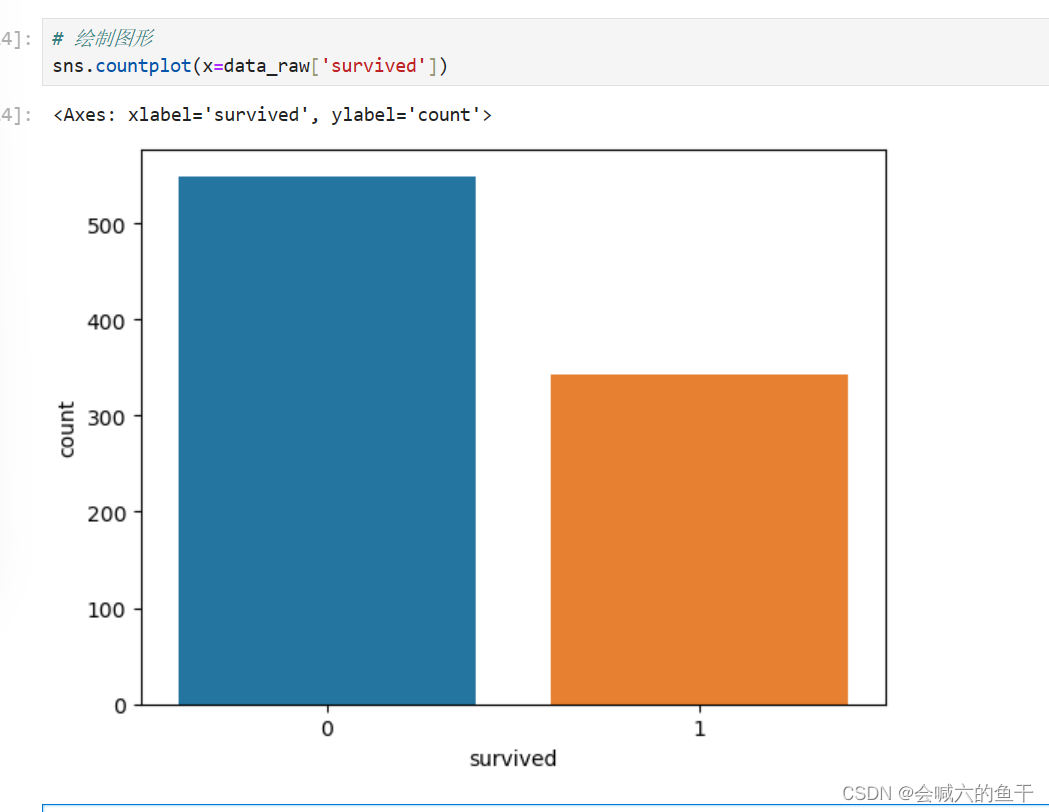
针对训练集的survived字段绘制图表查看生还情况,0表示死亡,1表示存活。
5.3 数据清洗
先将两个数据集合并在一起,方便后续进行统一数据清洗
首先查看训练集和验证集是否有空值
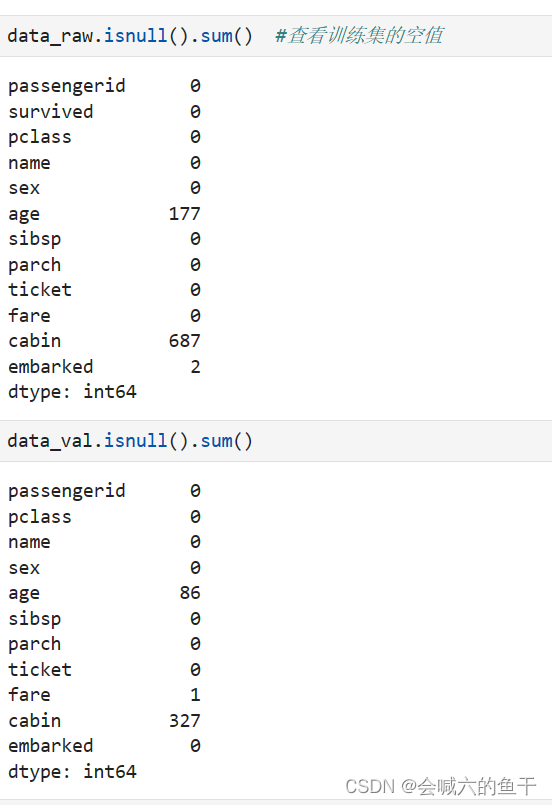
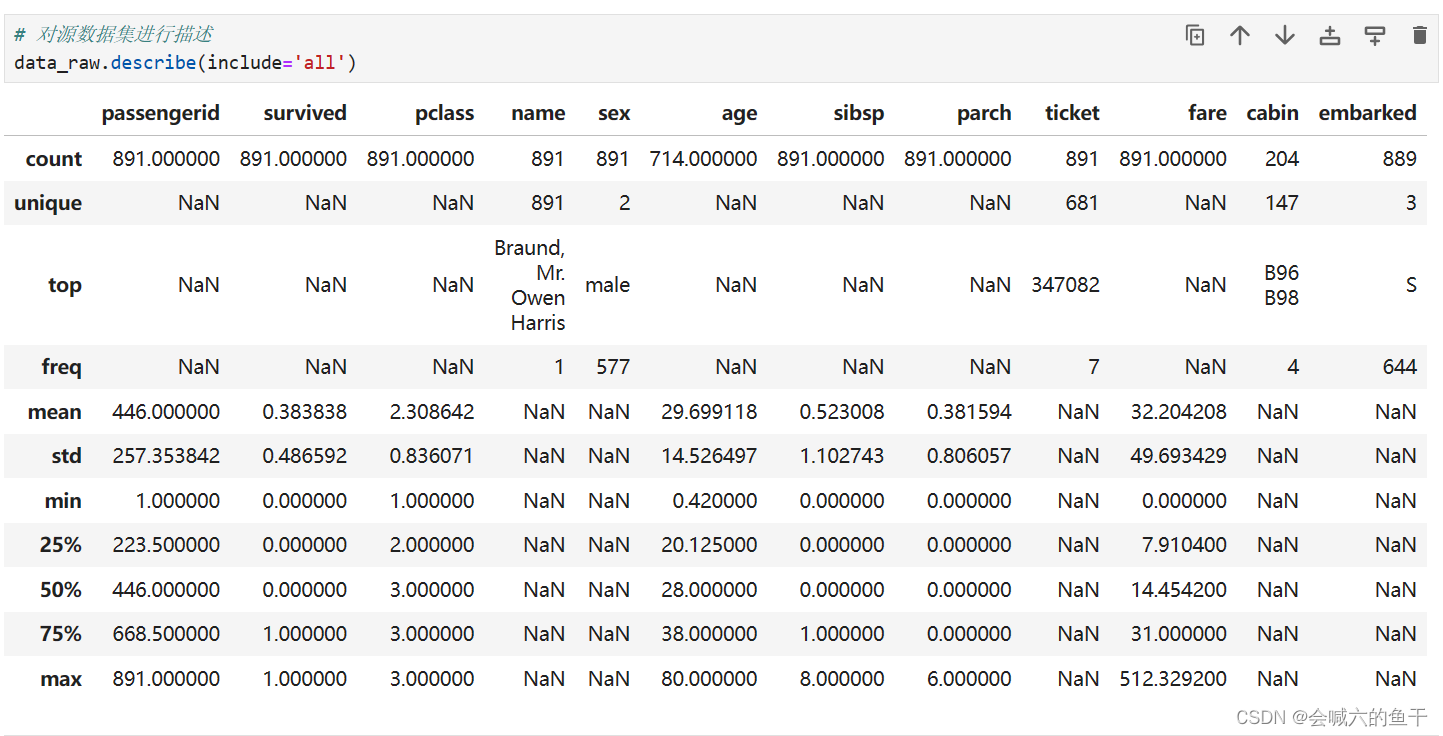
可以看到训练集的age有177个空值,cabin有2个空值,embarked有2个空值;验证集的age有86个空值,fare有2个空值,cabin有327个空值。还可以对源数据集进行描述查看更多的信息,例如每个字段的均值、最大值等等。
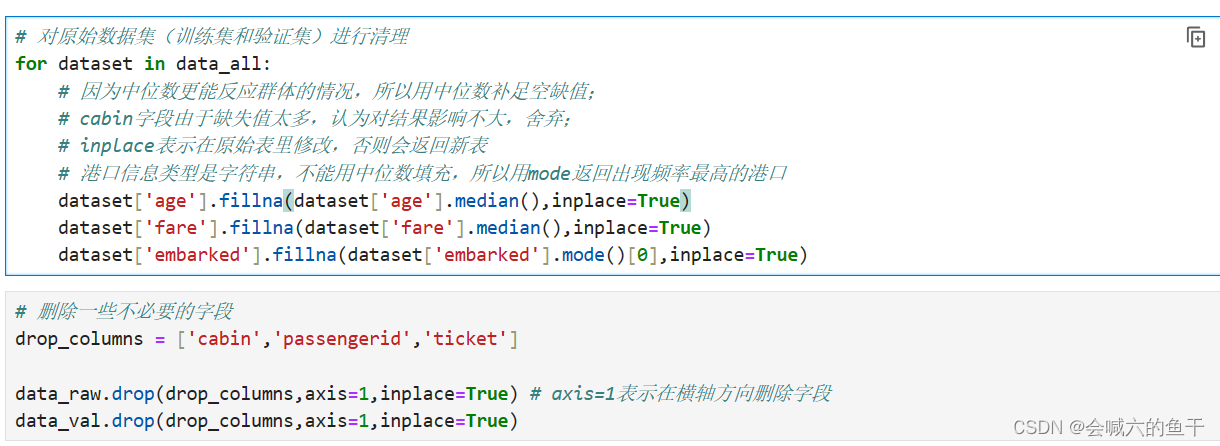
对原始数据集(训练集和验证集)进行清理
之前我们通过查看空值发现age、fare、embarked、cabin存在空值,因此首先要补全空值。
一般我们会用均值来表示一个群体的平均水平,但是如果群体中存在特别大的数值时均值易受影响,而中位数相对来说更客观一点,因此对于age和fare,我们选用中位数来补全空缺值;对于embarked,它的数据类型是字符串,因此我们用出现频率最高的港口来补全空缺值;对于cabin,无论是训练集还是验证集里的空值都占一半以上,因此完全可以认为该信息对结果影响不大,可以舍弃。passengerid表示乘客id,ticket表示船票信息,这两项也没有什么作用,可以舍弃。
数据处理之后再查看是否还存在空值
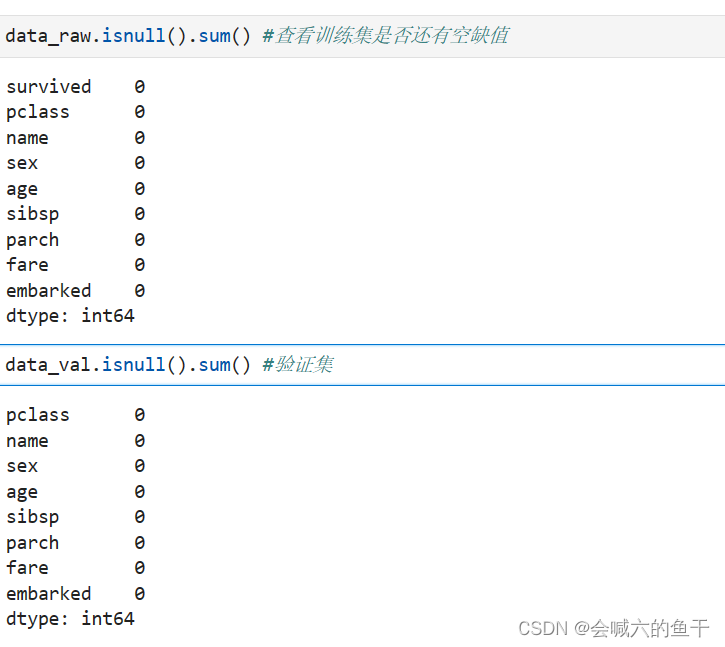
可以看到所有空值都已补全,不存在空值,接下来就可以进行特征构建了
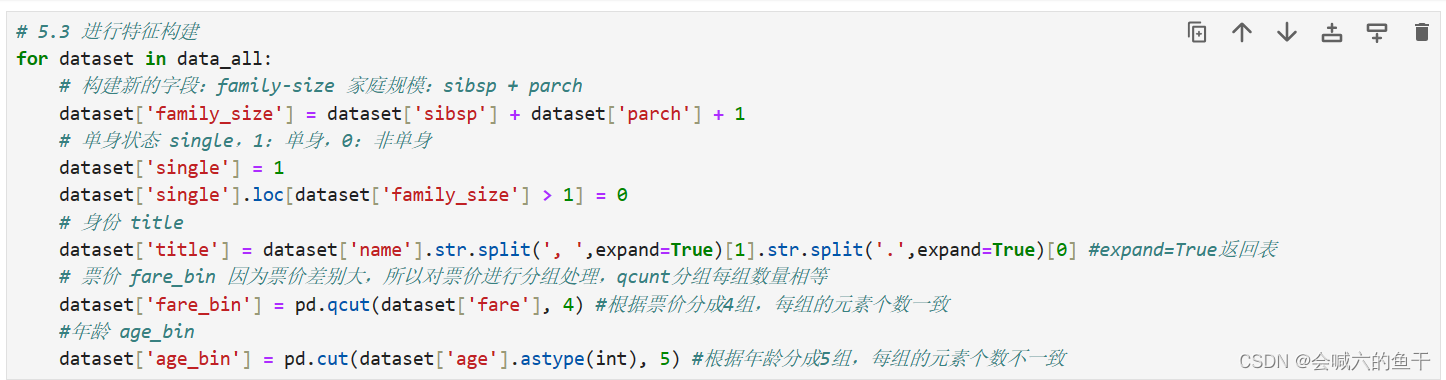
5.4 特征构建
通过原有字段构建新的字段来作为特征
family_size 家庭规模:sibsp+parch
single 单身状态:通过家庭规模是否大于1判断单身状态,等于1为单身,大于1为非单身。具体表示为 1:单身,0:非单身
title 身份 :通过姓名字段拆分可以看出每个人都有自己的身份标签,例如Mr、Mrs、Miss等等
fare_bin 票价:因为票价之间差别大,所以对票价进行分组处理
age_bin 年龄:和票价一样,因为数据较多,进行分组处理
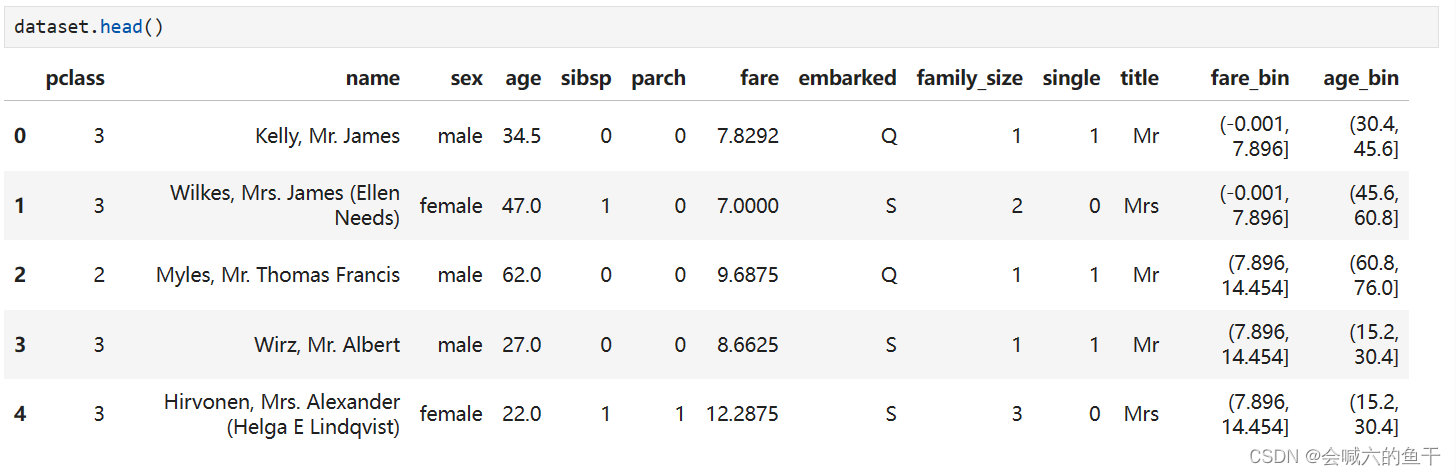
根据title统计对应人数
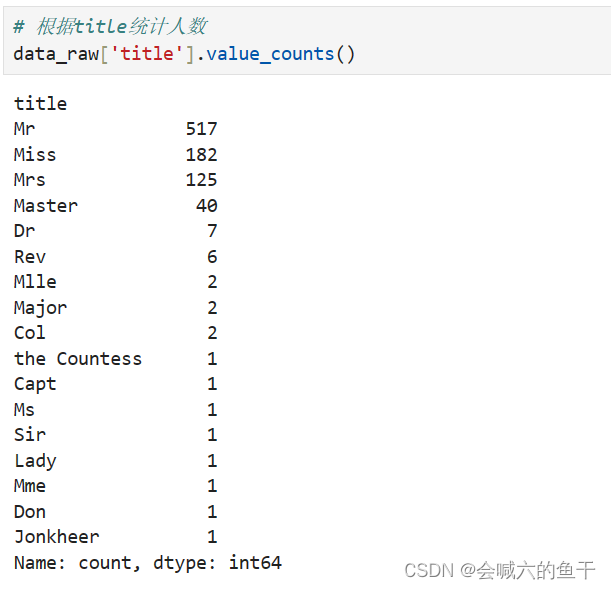
可以看到title的种类很多,为了方便分析,将数量小于10的title归于一类,定义为other
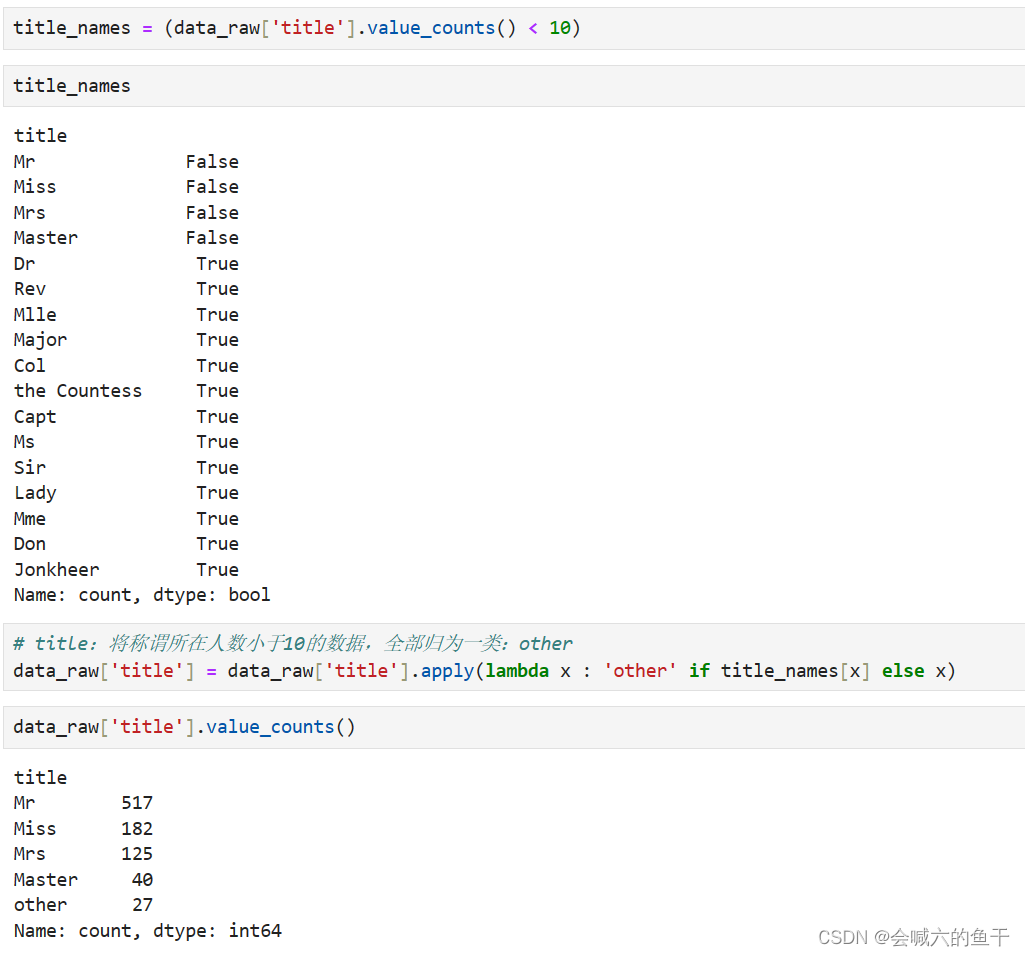
此时就可以根据title来查看对应的存活率
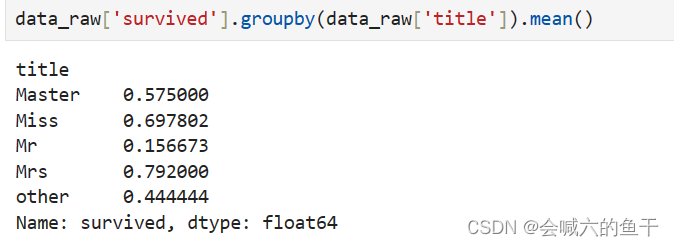
可以看出女性的存活率相对较高,男性的存活率较低。
5.5 字段格式转换
对于sex、title等字符串类型的字段是没有办法被识别处理的,因此要构建新的字段,将字符串转换成编码,例如sex有male和female两类结果,处理后就可以用1表示male,0表示female。

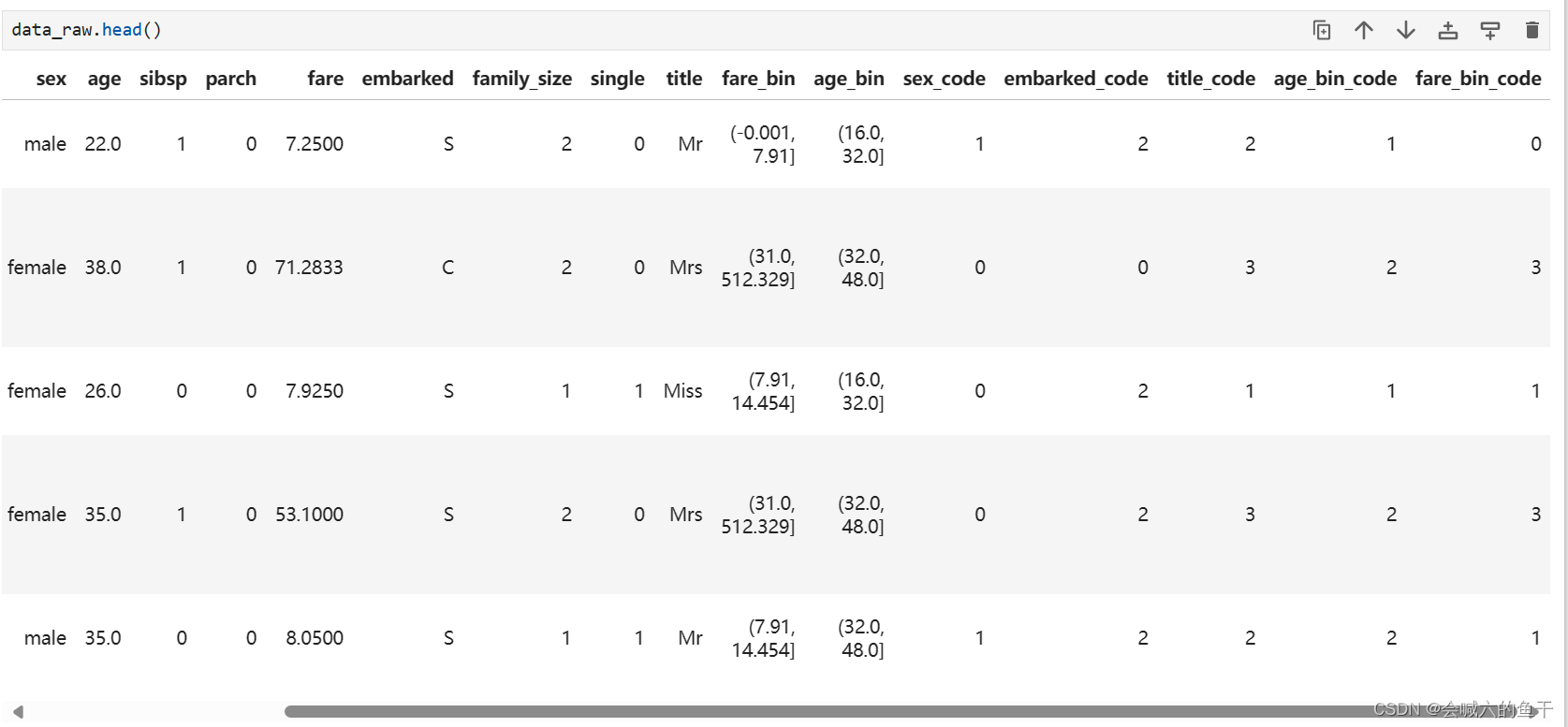
5.6 特征选择
选取三组不同的特征进行对比
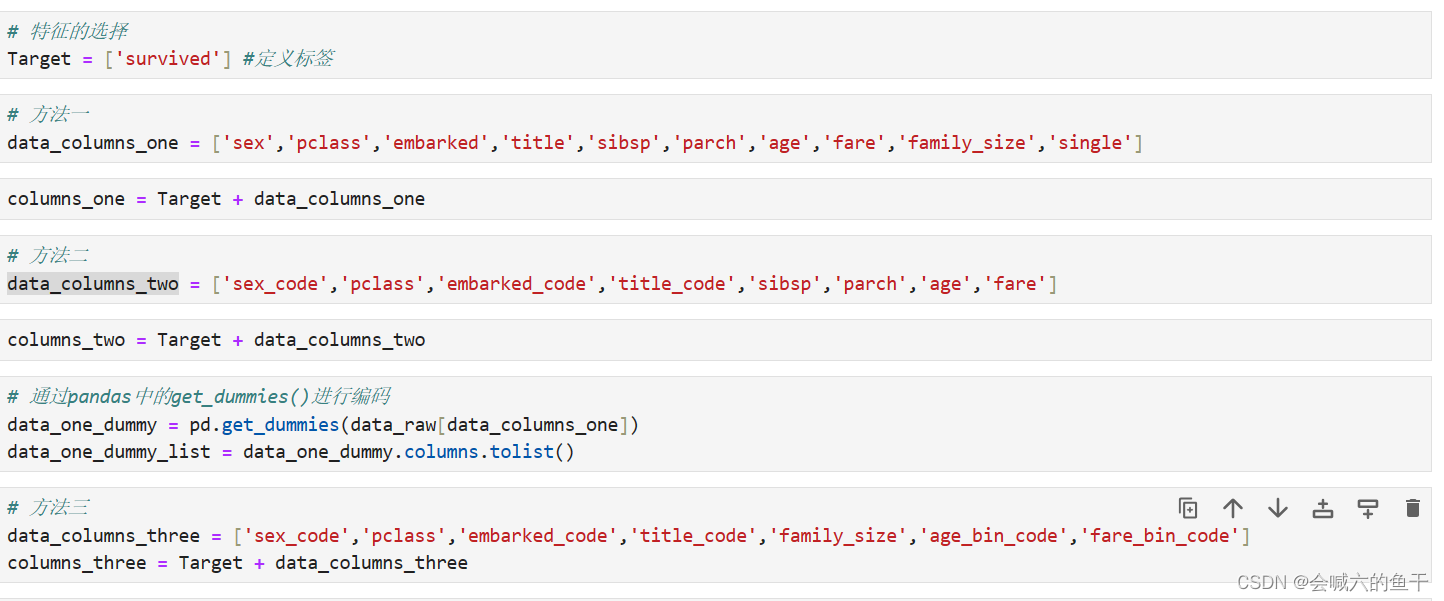
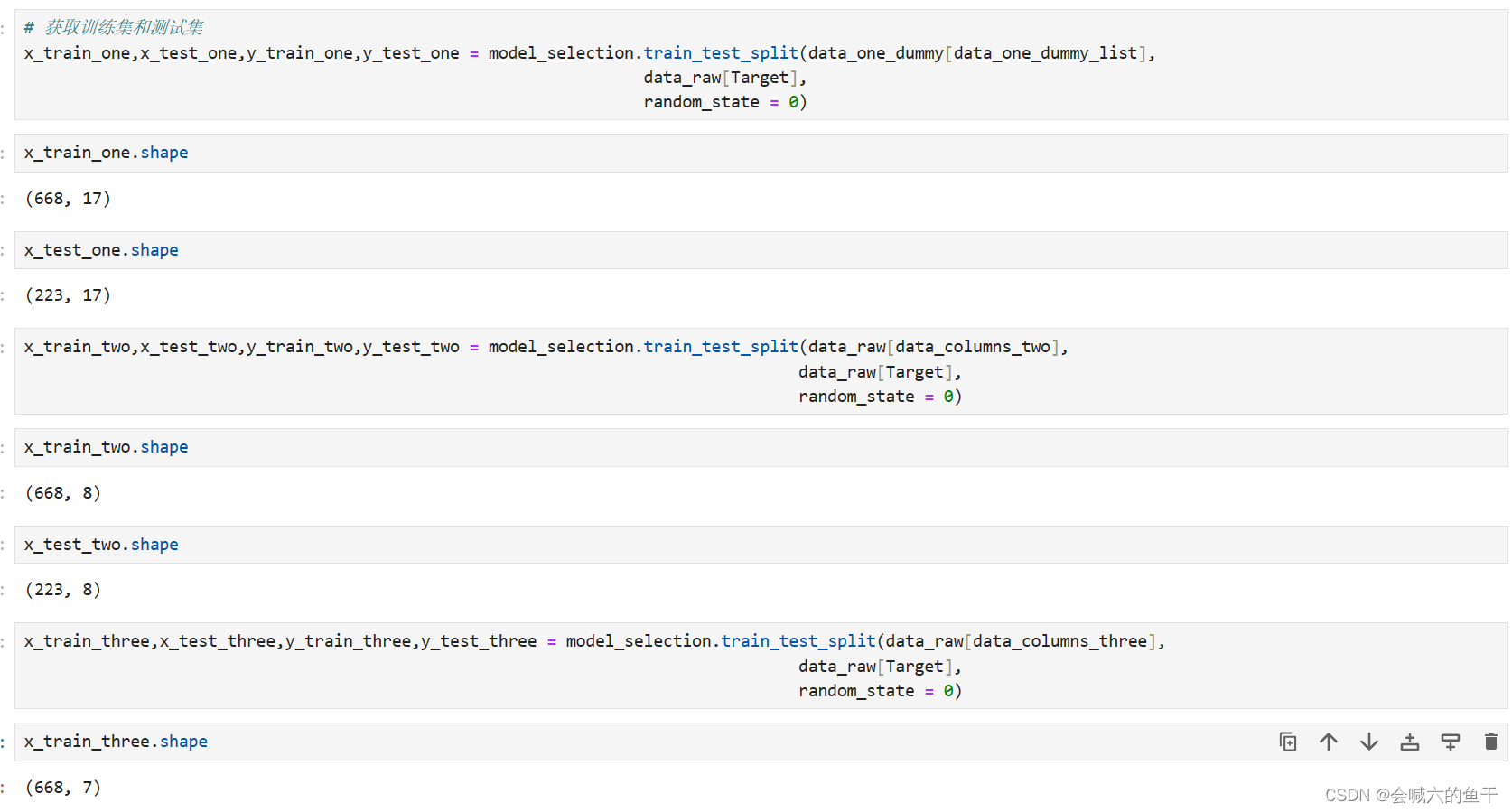
5.7 获取训练集和测试集
获取三组特征所对应的数据,并划分训练集和测试集
5.8 随机森林算法实现
设置参数

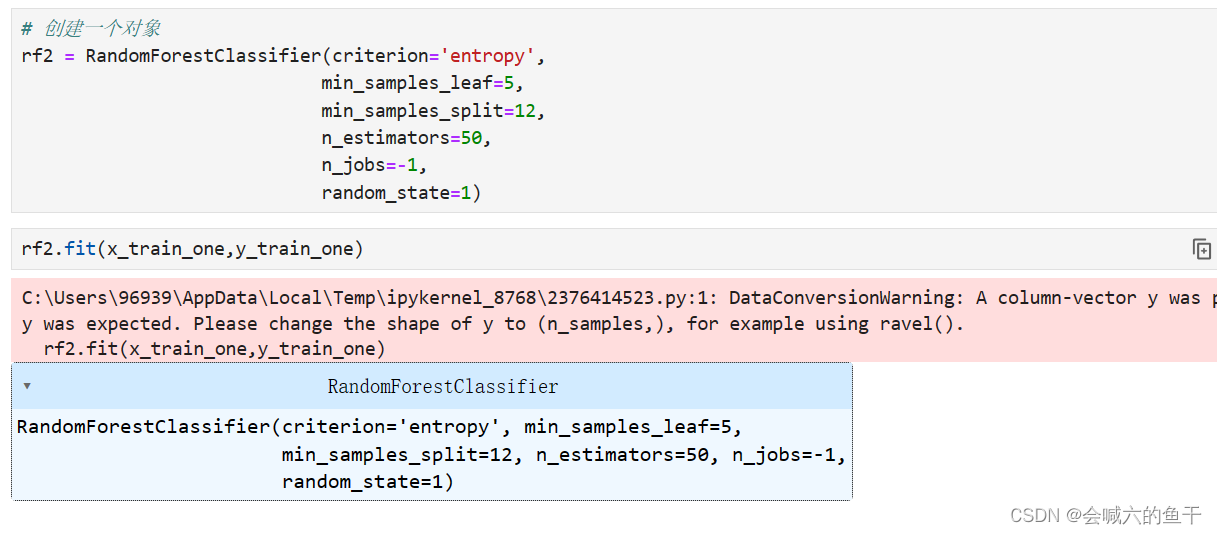
对第一组特征进行训练,查看准确率和最优参数
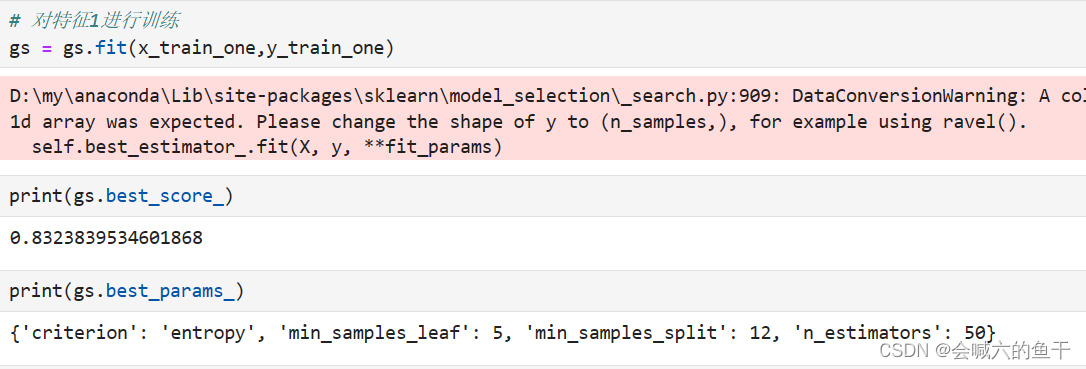
使用最优参数对测试集进行预测
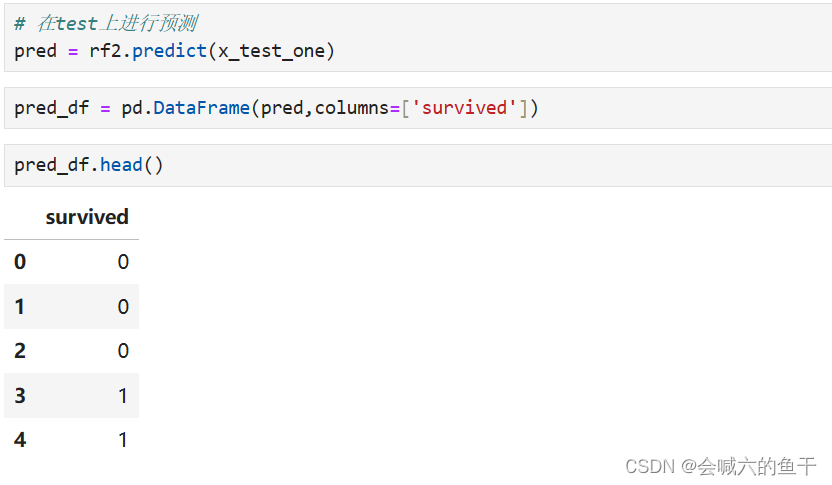
最后导出预测的结果表即可

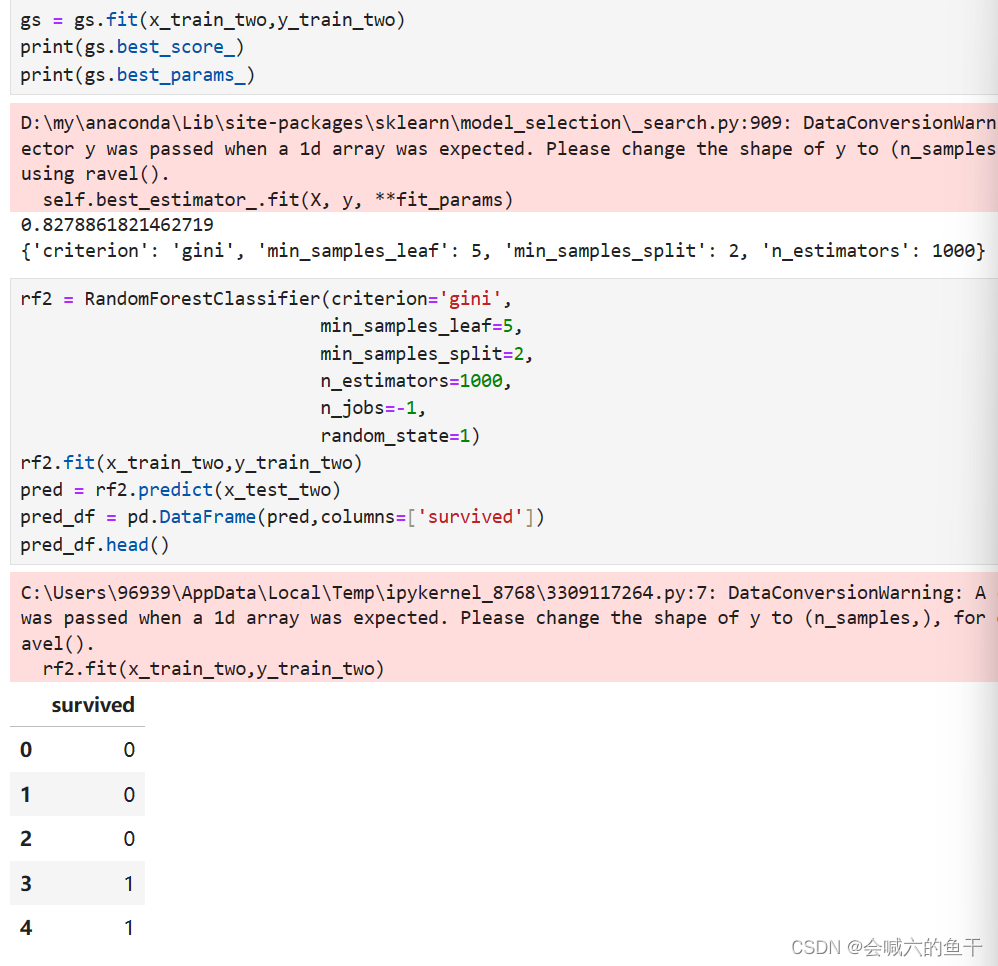
同理对第二组特征进行训练并预测:
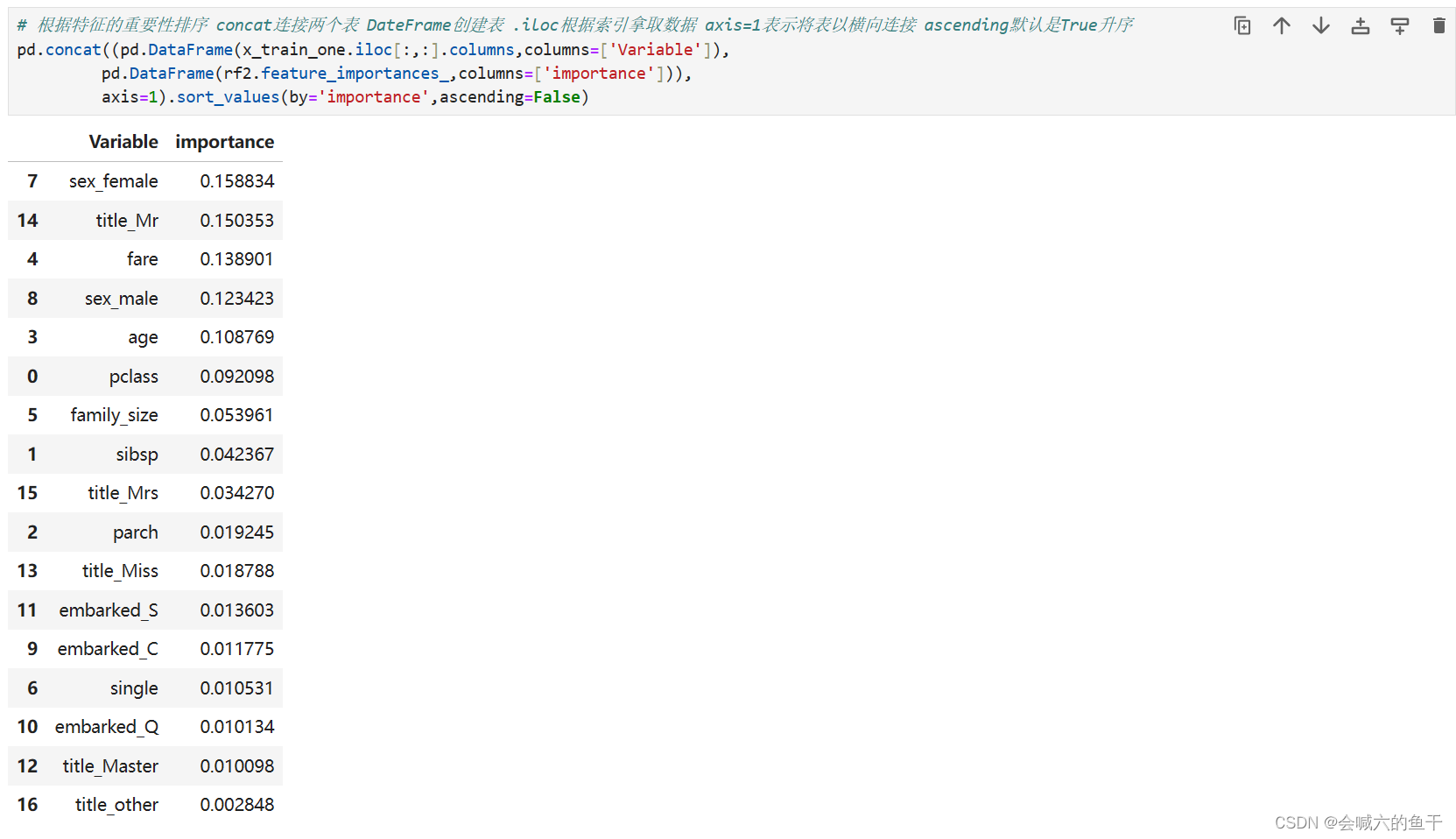
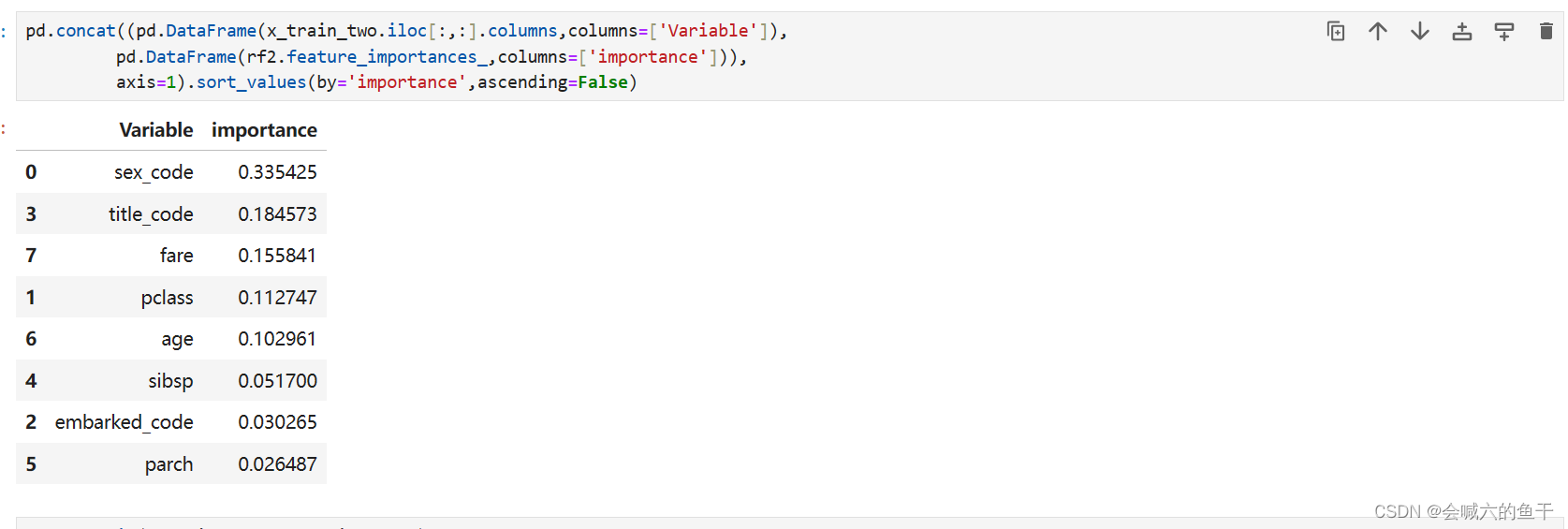
特征重要性排序:
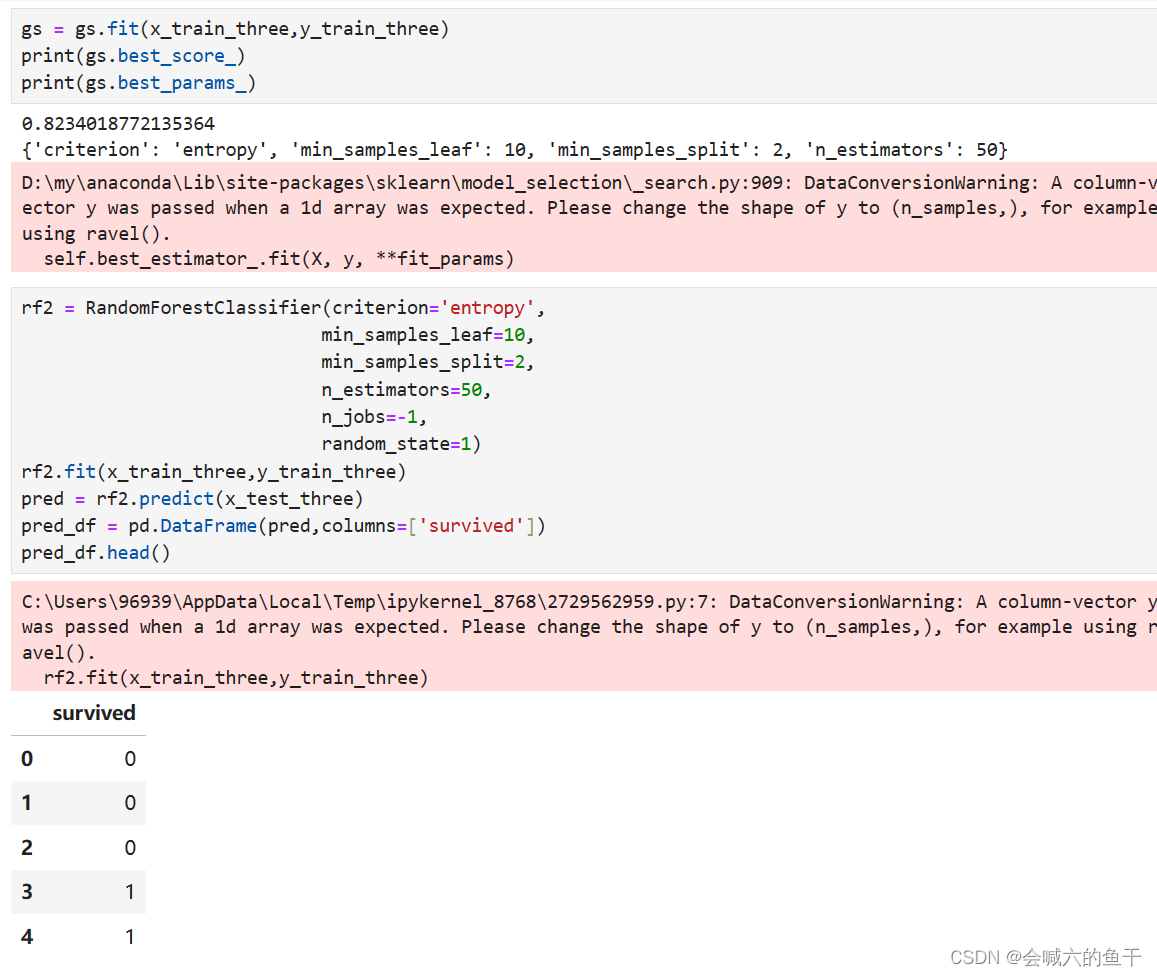
对第三组特征进行训练并预测:
对特征重要性进行排序:
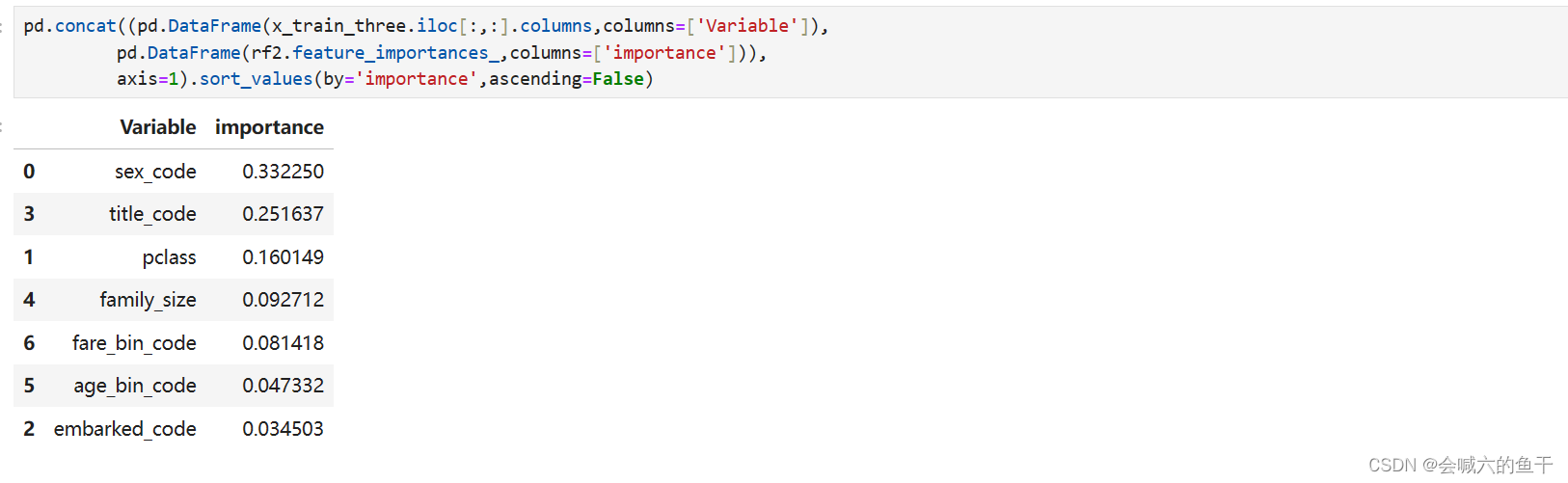
从上面三组特征训练结果可以看出第一组的效果最好,准确率有83%左右。如果是女性,获救几率会较大;票价对获救几率也有一定的影响,应该是票价决定船舱位置,而一个良好的位置会更容易获得逃生机会。
最后附上源代码:
- import sys
- import pandas as pd #做数据分析
- import numpy as np
- import sklearn #机器学习算法库
- import random
- import time #计算用时
-
- from sklearn import ensemble #集成学习库,随机森林在库里
- from sklearn.preprocessing import LabelEncoder #进行编码转换,将非数字转换成数字
- from sklearn import feature_selection #特征选择,工具表,有很多算法
- from sklearn import model_selection
- from sklearn import metrics #库里有很多评估算法
-
- import matplotlib as mpl #绘图库
- import matplotlib.pyplot as plt #进行绘图
- import seaborn as sns #画图的图
-
- data_raw = pd.read_csv('train.csv')
- data_val = pd.read_csv('test.csv')
- #显示部分数据
- data_raw.head() #head方法默认显示5条数据
- data_val.head()
- data_raw.info() #info查看数据表更多信息
- data_val.info()
- data_raw.columns = data_raw.columns.str.lower()
- data_val.columns = data_val.columns.str.lower()
- # 绘制图形
- sns.countplot(x=data_raw['survived'])
-
- # 合并两个数据集,进行统一的清洗
- data_all = [data_raw,data_val]
- data_raw.isnull().sum() #查看训练集的空值
- data_val.isnull().sum()
- data_raw.describe(include='all')
-
- # 对原始数据集(训练集和验证集)进行清理
- for dataset in data_all:
- # 因为中位数更能反应群体的情况,所以用中位数补足空缺值;
- # cabin字段由于缺失值太多,认为对结果影响不大,舍弃;
- # inplace表示在原始表里修改,否则会返回新表
- # 港口信息类型是字符串,不能用中位数填充,所以用mode返回出现频率最高的港口
- dataset['age'].fillna(dataset['age'].median(),inplace=True)
- dataset['fare'].fillna(dataset['fare'].median(),inplace=True)
- dataset['embarked'].fillna(dataset['embarked'].mode()[0],inplace=True)
-
- # 删除一些不必要的字段
- drop_columns = ['cabin','passengerid','ticket']
- data_raw.drop(drop_columns,axis=1,inplace=True) # axis=1表示在横轴方向删除字段
- data_val.drop(drop_columns,axis=1,inplace=True)
-
- data_raw.isnull().sum() #查看训练集是否还有空缺值
- data_val.isnull().sum() #验证集
-
- # 进行特征构建
- for dataset in data_all:
- # 构建新的字段:family-size 家庭规模:sibsp + parch
- dataset['family_size'] = dataset['sibsp'] + dataset['parch'] + 1
- # 单身状态 single,1:单身,0:非单身
- dataset['single'] = 1
- dataset['single'].loc[dataset['family_size'] > 1] = 0
- # 身份 title
- dataset['title'] = dataset['name'].str.split(', ',expand=True
- [1].str.split('.',expand=True)[0] #expand=True返回表
- # 票价 fare_bin 因为票价差别大,所以对票价进行分组处理,qcunt分组每组数量相等
- dataset['fare_bin'] = pd.qcut(dataset['fare'], 4)
- #年龄 age_bin 根据年龄分成5组,每组的元素个数不一致
- dataset['age_bin'] = pd.cut(dataset['age'].astype(int), 5)
-
- # 根据title统计人数
- data_raw['title'].value_counts()
- title_names = (data_raw['title'].value_counts() < 10)
- # title:将称谓所在人数小于10的数据,全部归为一类:other
- data_raw['title'] = data_raw['title'].apply(lambda x : 'other' if title_names[x] else x)
- data_raw['title'].value_counts()
- # 查看各个title的生还率
- data_raw['survived'].groupby(data_raw['title']).mean()
-
- ### 构建新的字段,基于scikit-learn中的labelencoder(),将字符串转变成编码
- label = LabelEncoder()
- for dataset in data_all:
- # 新字段 sex_code
- dataset['sex_code'] = label.fit_transform(dataset['sex'])
- # embarked_code
- dataset['embarked_code'] = label.fit_transform(dataset['embarked'])
- # title_code
- dataset['title_code'] = label.fit_transform(dataset['title'])
- # age_bin_code
- dataset['age_bin_code'] = label.fit_transform(dataset['age_bin'])
- # fare_bin_code
- dataset['fare_bin_code'] = label.fit_transform(dataset['fare_bin'])
-
- # 特征的选择
- Target = ['survived'] #定义标签
- # 方法一
- data_columns_one = ['sex','pclass','embarked','title','sibsp','parch','age','fare','family_size','single']
- columns_one = Target + data_columns_one
- # 通过pandas中的get_dummies()进行编码
- data_one_dummy = pd.get_dummies(data_raw[data_columns_one])
- data_one_dummy_list = data_one_dummy.columns.tolist()
-
- # 方法二
- data_columns_two = ['sex_code','pclass','embarked_code','title_code','sibsp','parch','age','fare']
- columns_two = Target + data_columns_two
-
- # 方法三
- data_columns_three = ['sex_code','pclass','embarked_code','title_code','family_size','age_bin_code','fare_bin_code']
- columns_three = Target + data_columns_three
-
- # 获取训练集和测试集
- x_train_one,x_test_one,y_train_one,y_test_one = model_selection.train_test_split(data_one_dummy[data_one_dummy_list],data_raw[Target],random_state = 0)
-
- x_train_two,x_test_two,y_train_two,y_test_two = model_selection.train_test_split(data_raw[data_columns_two],data_raw[Target],random_state = 0)
-
- x_train_three,x_test_three,y_train_three,y_test_three = model_selection.train_test_split(data_raw[data_columns_three],data_raw[Target],random_state = 0)
-
- # 随机森林算法实现
- from sklearn.model_selection import GridSearchCV
- from sklearn.ensemble import RandomForestClassifier
-
- rf = RandomForestClassifier(random_state=1,
- n_jobs=-1)
- param_gird = {
- 'criterion' : ['gini','entropy'],
- 'min_samples_leaf' : [1, 5, 10],
- 'min_samples_split' : [2, 4, 10, 12, 16],
- 'n_estimators' : [50, 100, 400, 700, 1000]
- }
- gs = GridSearchCV(estimator=rf,
- param_grid=param_gird,
- scoring='accuracy',
- cv=3,
- n_jobs=-1)
-
- # 对特征1进行训练
- gs = gs.fit(x_train_one,y_train_one)
- print(gs.best_score_)
- print(gs.best_params_)
-
- # 创建一个对象
- rf2 = RandomForestClassifier(criterion='entropy',
- min_samples_leaf=5,
- min_samples_split=12,
- n_estimators=50,
- n_jobs=-1,
- random_state=1)
- rf2.fit(x_train_one,y_train_one)
-
- # 根据特征的重要性排序 concat连接两个表 DateFrame创建表 .iloc根据索引拿取数据 axis=1表示将表以横向连接 ascending默认是True升序
- pd.concat((pd.DataFrame(x_train_one.iloc[:,:].columns,columns=['Variable']),
- pd.DataFrame(rf2.feature_importances_,columns=['importance'])),
- axis=1).sort_values(by='importance',ascending=False)
-
- # 在test上进行预测
- pred = rf2.predict(x_test_one)
- pred_df = pd.DataFrame(pred,columns=['survived'])
- pred_df.head()
- pred_df.to_csv('output.csv', index=False)
-
- # 对特征2进行训练
- gs = gs.fit(x_train_two,y_train_two)
- print(gs.best_score_)
- print(gs.best_params_)
-
- rf2 = RandomForestClassifier(criterion='gini',
- min_samples_leaf=5,
- min_samples_split=2,
- n_estimators=1000,
- n_jobs=-1,
- random_state=1)
- rf2.fit(x_train_two,y_train_two)
- pred = rf2.predict(x_test_two)
- pred_df = pd.DataFrame(pred,columns=['survived'])
- pred_df.head()
-
- pd.concat((pd.DataFrame(x_train_two.iloc[:,:].columns,columns=['Variable']),
- pd.DataFrame(rf2.feature_importances_,columns=['importance'])),
- axis=1).sort_values(by='importance',ascending=False)
-
- # 对特征3进行训练
- gs = gs.fit(x_train_three,y_train_three)
- print(gs.best_score_)
- print(gs.best_params_)
-
- rf2 = RandomForestClassifier(criterion='entropy',
- min_samples_leaf=10,
- min_samples_split=2,
- n_estimators=50,
- n_jobs=-1,
- random_state=1)
- rf2.fit(x_train_three,y_train_three)
- pred = rf2.predict(x_test_three)
- pred_df = pd.DataFrame(pred,columns=['survived'])
- pred_df.head()
-
- pd.concat((pd.DataFrame(x_train_three.iloc[:,:].columns,columns=['Variable']),
- pd.DataFrame(rf2.feature_importances_,columns=['importance'])),
- axis=1).sort_values(by='importance',ascending=False)


