
- 1Java接口,超详细整理,适合新手入门_java 接口
- 2闲话Zynq UltraScale+ MPSoC(连载4)——IO资源_hrio和hpio
- 3uni-app配置开发、测试、生产等多环境,process.env_uniapp process.env
- 4深入理解外观模式(Facade Pattern)及其实际应用
- 5git分支合并冲突解决_ugit 冲突文件
- 6XILINX 7系列FPGA_SelectIO_xilinx selectio
- 7龙蜥操作系统上安装MySQL:步骤详解与常见问题解决_龙蜥安装mysql
- 8Navicat实现 MYSQL数据库备份图文教程_navicat备份数据库
- 9【数据结构】线性表:顺序表
- 10ARIMA参数判定_如何通过acf和pacf判断arima的参数
Pytorch学习笔记(3)—word2vec_pytorch word2vec.word2vec经验
赞
踩
前言
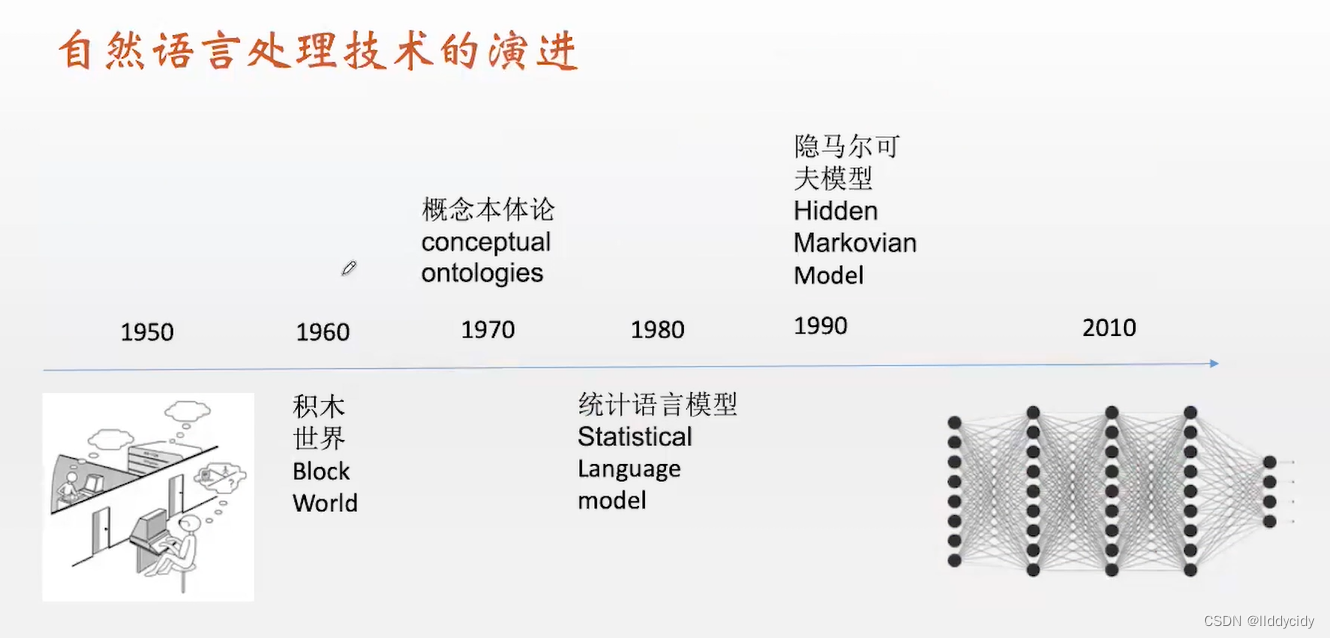
如何去表达词汇呢?— “bag of words”(词袋模型)— 只看单词出现的频数

解决方法
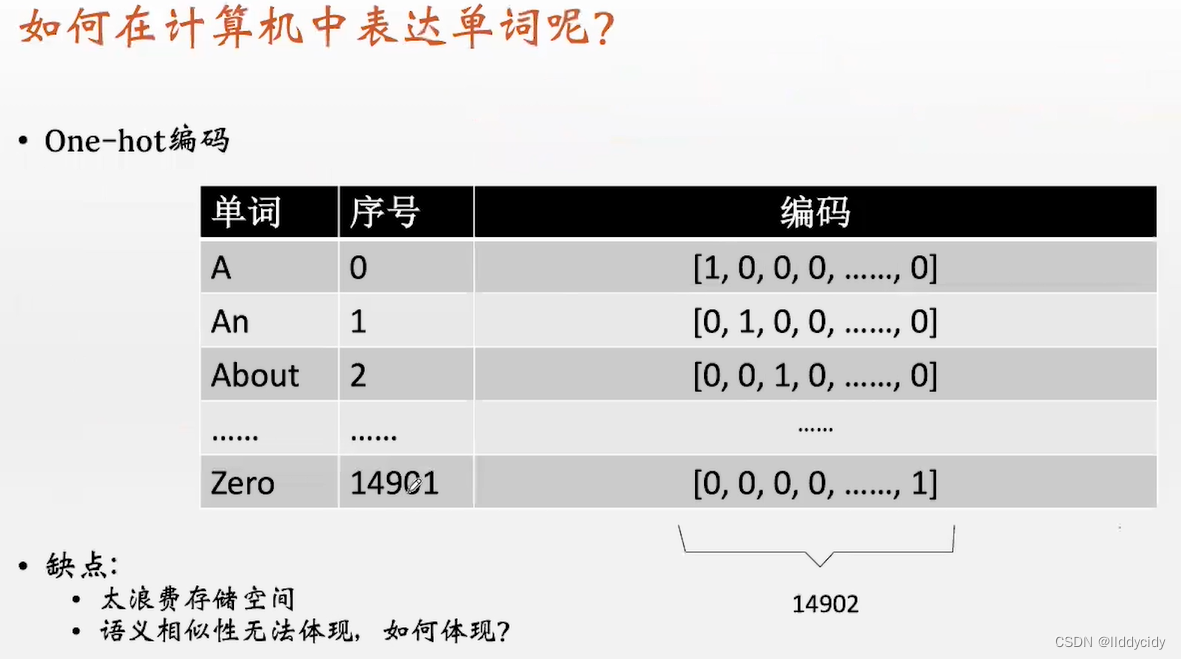
总结:
将word转化成向量并存储,相关可以看我上一篇pytorch学习笔记之情绪分类器里面对one-hot的讲解,也可以访问以下文章来获取。
独热编码(One-Hot Encoding)
什么是one-hot编码,他有什么用?
数据预处理之One-Hot
机器学习之独热编码(One-Hot)详解(代码解释)
一、NPLM基本思想:无监督模型
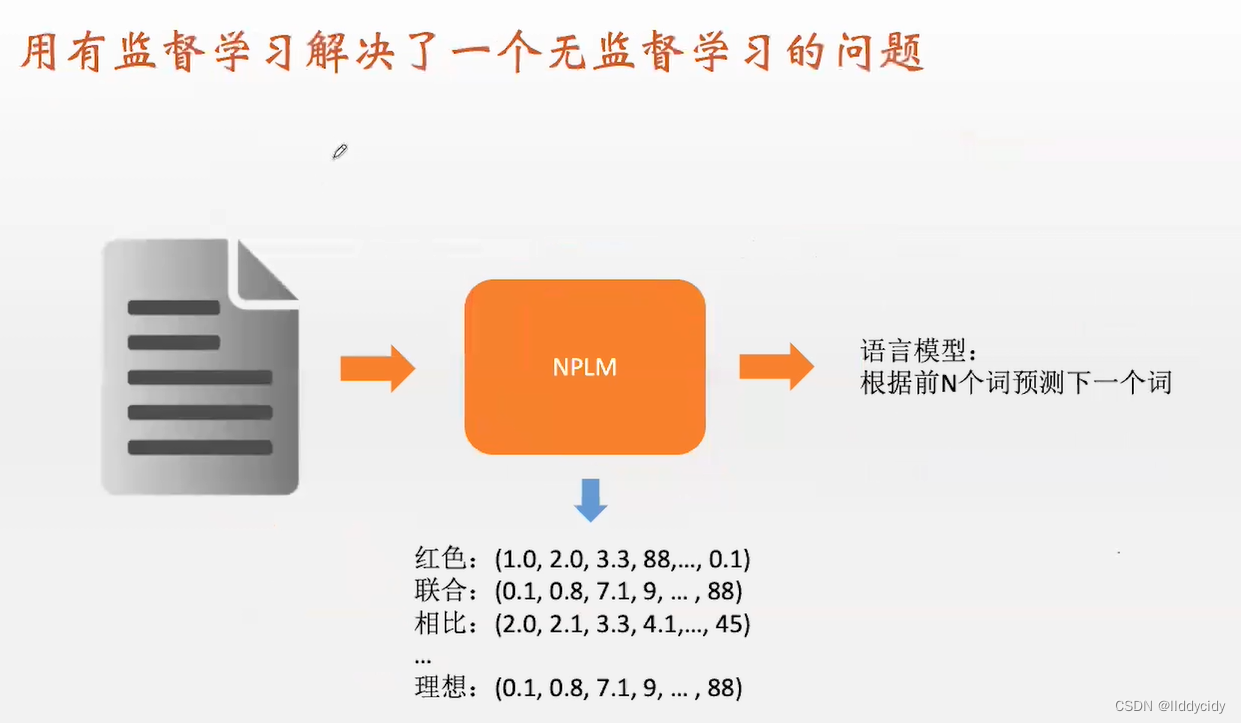
构造了一个有监督的任务,解决了无监督的问题
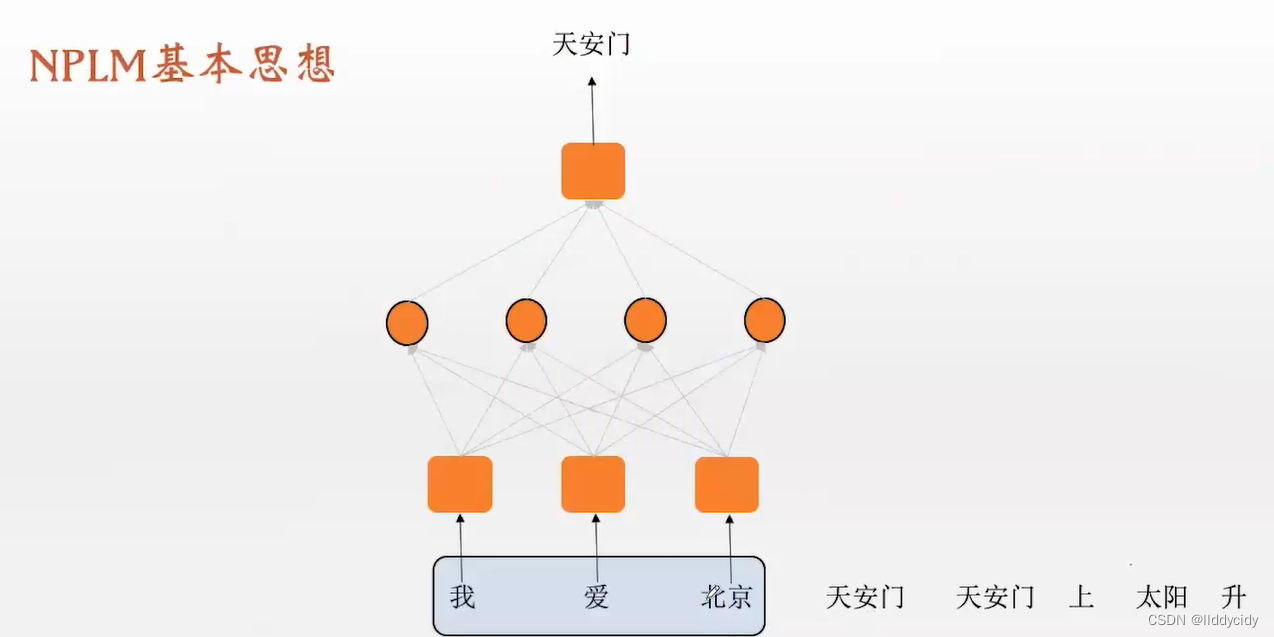
N-gram语言模型
s
t
e
p
1
:预处理文本
step1:预处理文本
step1:预处理文本
s
t
e
p
2
:滑动窗口
step2:滑动窗口
step2:滑动窗口
s
t
e
p
3
:训练做分类任务
step3:训练做分类任务
step3:训练做分类任务
.
.
.
...
...
问题:
我们需要将词向量化,但是此时的任务却要将词直接输入。这就产生了矛盾
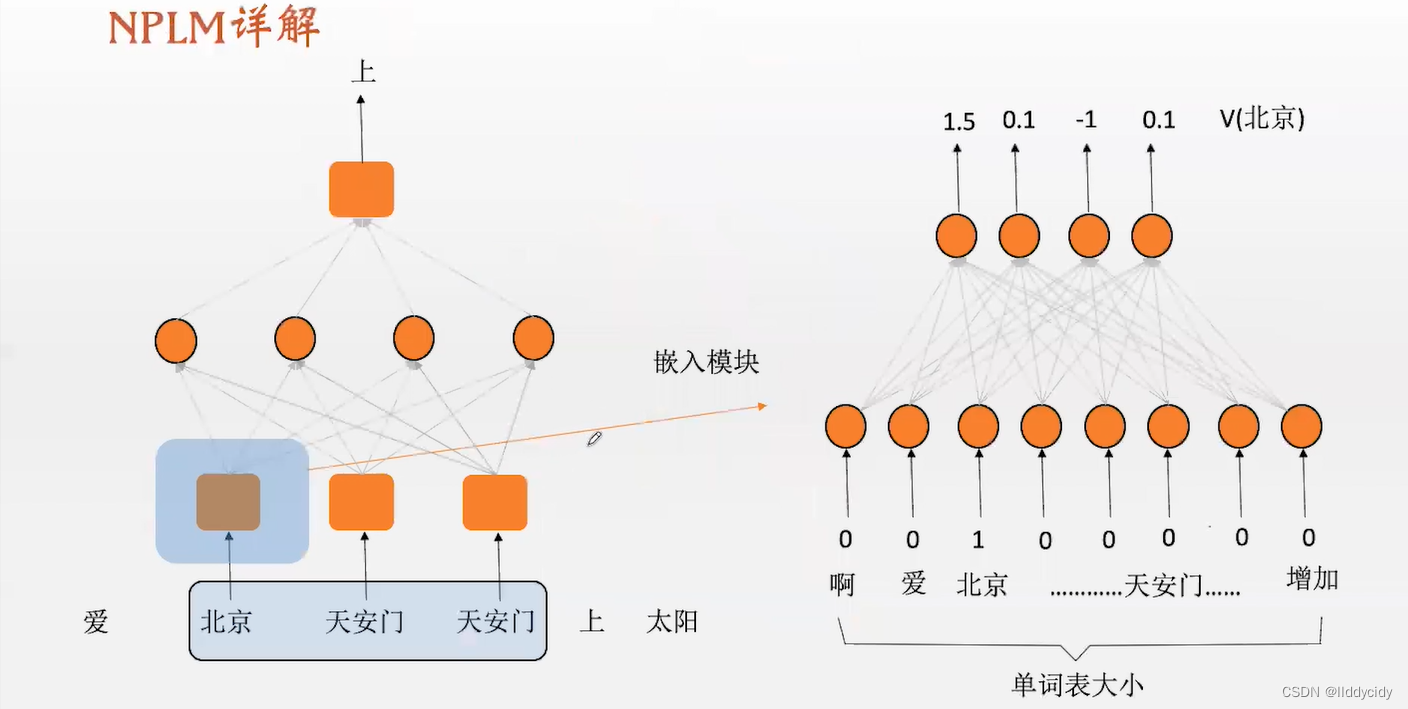
输入节点的个数等于单词表的大小,输出神经元的个数等于词向量的维度(通常为100),输入为one-hot编码,输出为D维向量(其实就是我们想要的(预测的)词向量),数值是稠密的向量(dense)
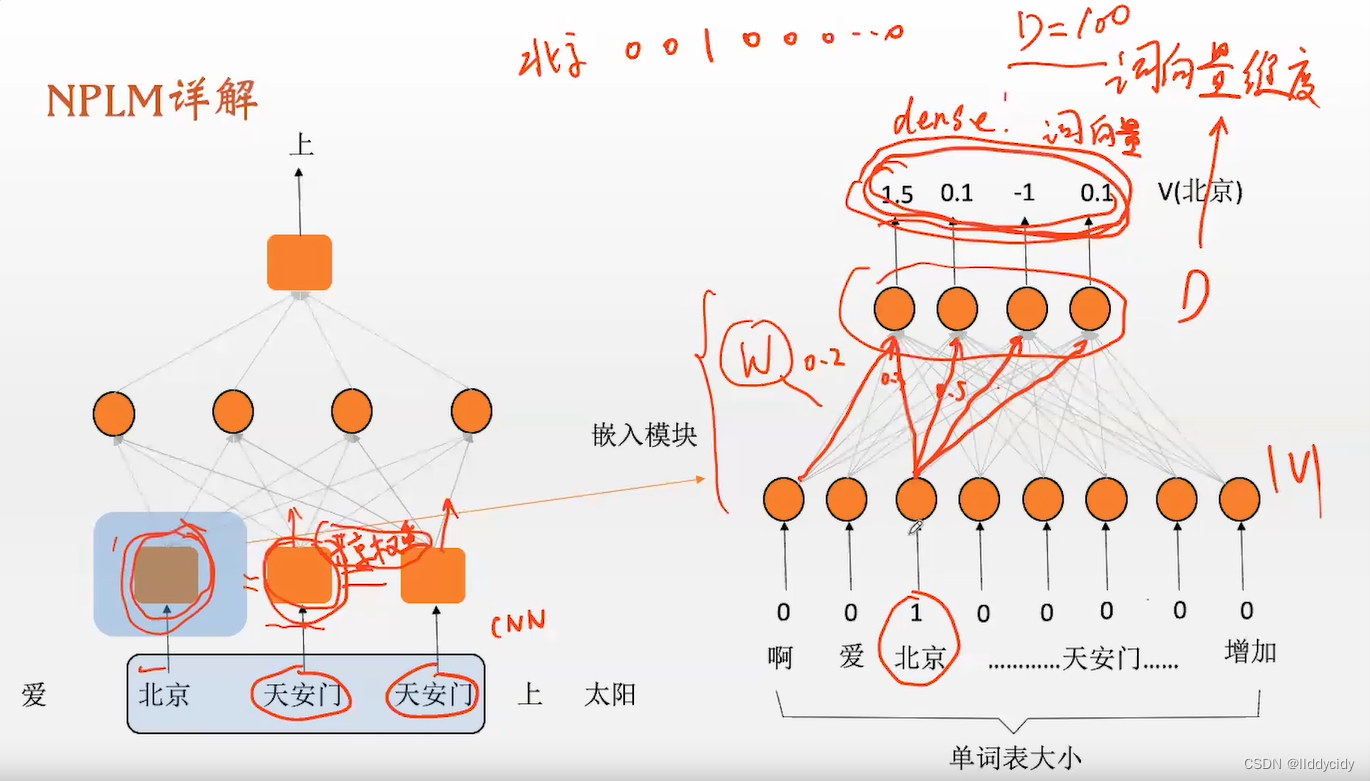
注:这里的灰箱子的权重是共享的,网络是线性的,这就意味着神经网络输出的结果就是词向量本身
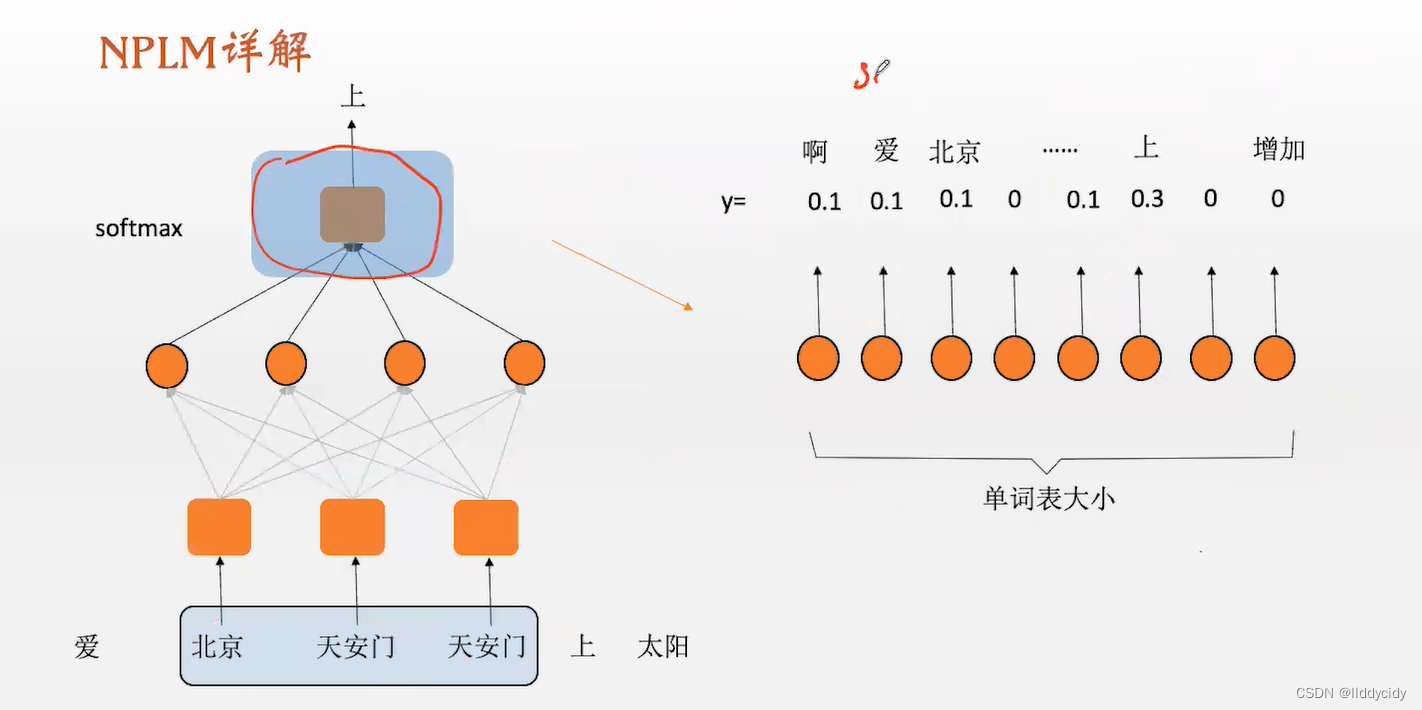
我们的模型就是要进行一个分类,即多分类任务;多分类任务详解
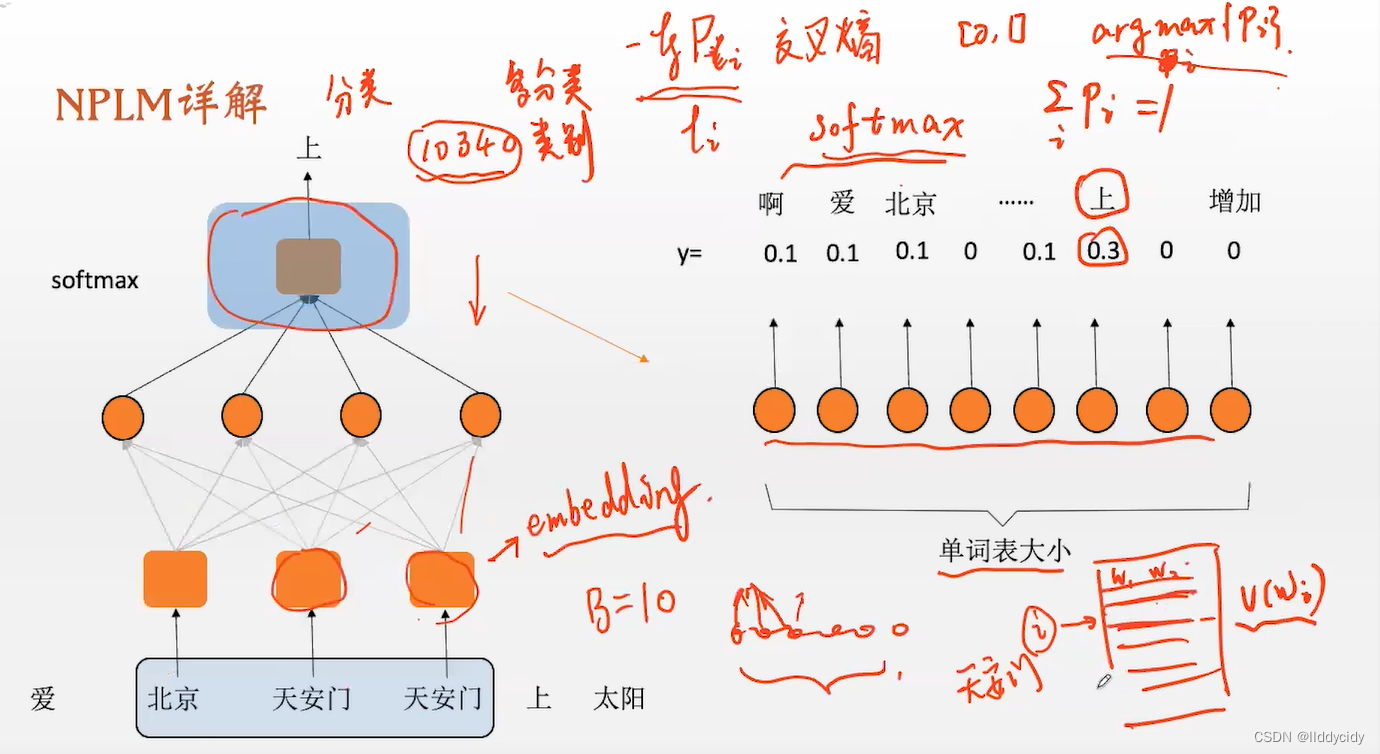

表最开始都是随机赋值,通过迭代,利用梯度反传进行更新迭代生成新的表
一文读懂Embedding的概念,以及它和深度学习的关系
embedding层和全连接层的区别是什么?
NLP中的Embedding方法总结

二、步骤
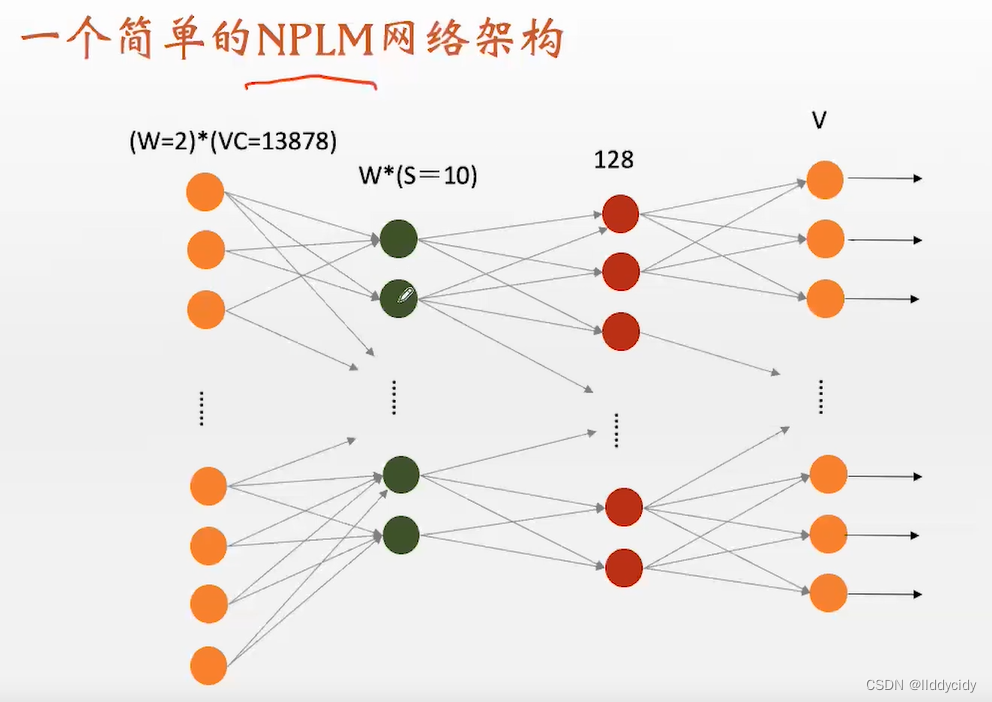
第一层为嵌入层:输入为ont-hot编码、输出为dense的
中间层:128dim
输出层:V的输出层
pip install jieba
# 看情感那个
- 1
- 2
建立词典,训练数据,此时
w
=
2
w=2
w=2

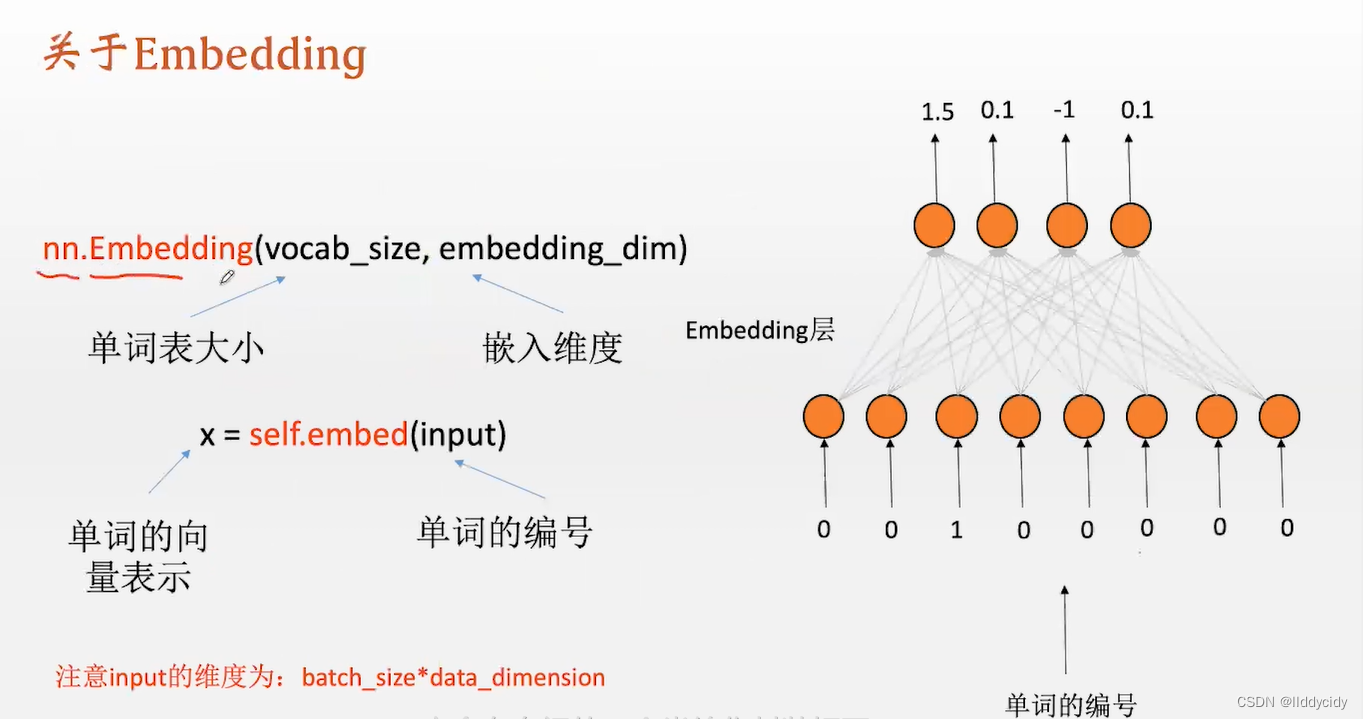
torch中的class— Embedding
三、word2vec
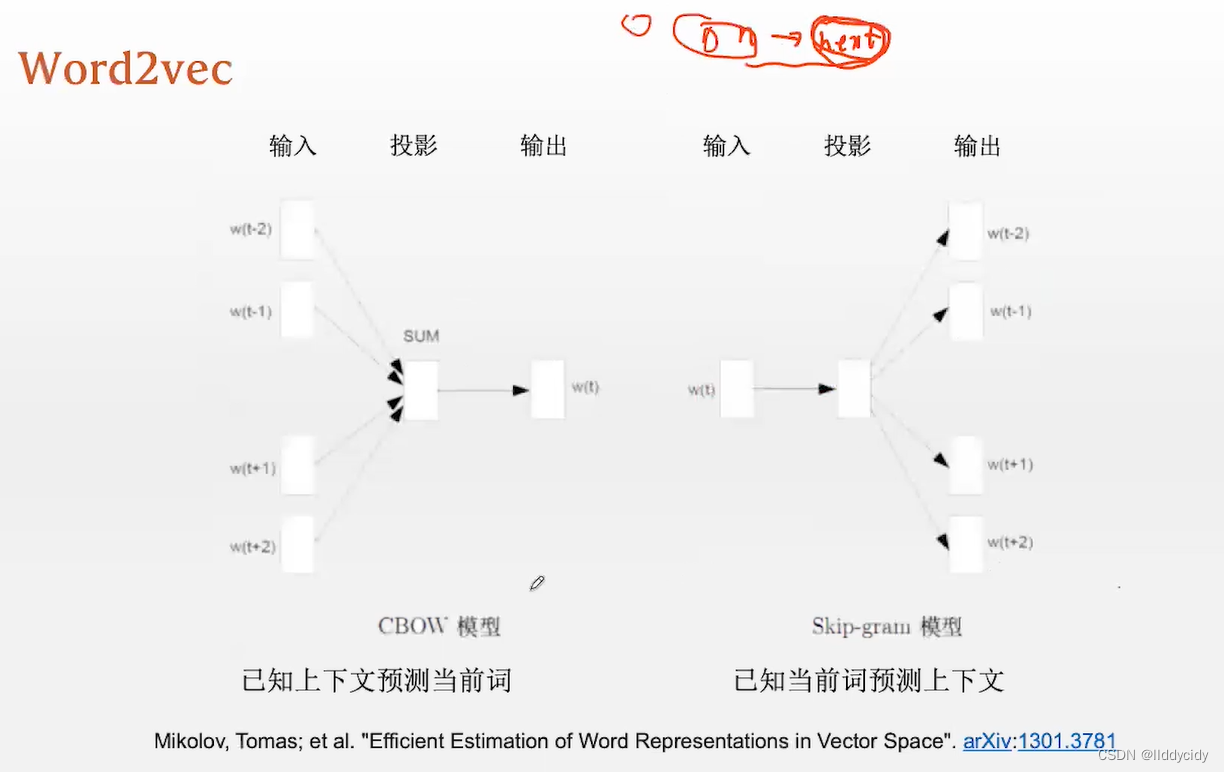

问题:
- 罕见词的出现频率很小,得不到训练的机会,因此得到的输出的词向量就很不准确
word2vec解决的方法:
- Hierarchical softmax(层次软最大)
- Negative sampling (负采样)
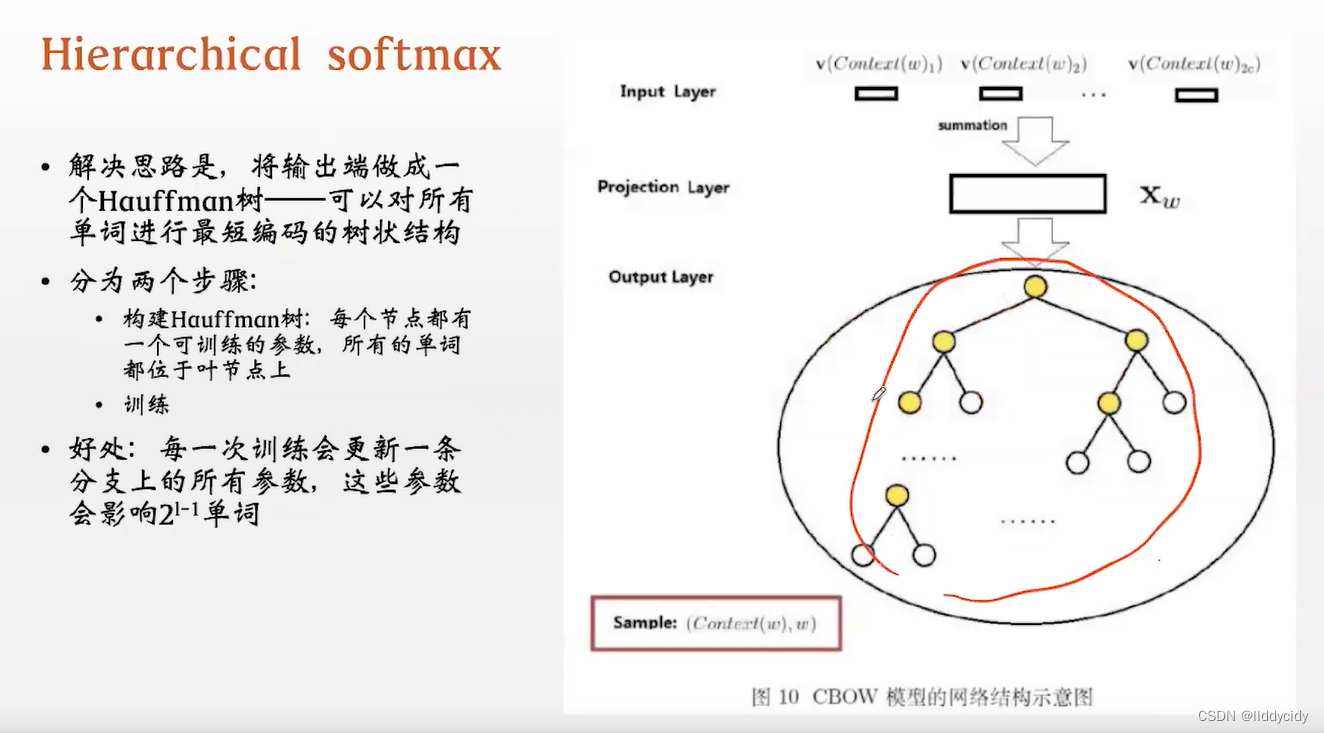
可学习参数变成树的节点(黄色)叶节点白色
当更新一条路径的时候,就会将一串路径同时进行更新
Haffman编码:根据词出现的频率和大小进行编码
详解:
Haffman编码
Huffman 编码原理详解(代码示例)


原文:Mikolov, Tomas: et al. “Efficient Estimation of Word Representations in Vector Space”. arXiv:1301.3781
如何下载?
输入doi:arXiv:1301.3781
参考:
图解Word2vec,读这一篇就够了(通俗易懂)
如何通俗理解Word2Vec
大白话讲解word2vec到底在做些什么
word2vec基础(非常容易理解)
总结
源码:代码文章末尾

引用
1、 独热编码(One-Hot Encoding)
2、什么是one-hot编码,他有什么用?
3、数据预处理之One-Hot
4、机器学习之独热编码(One-Hot)详解(代码解释)
5、one-hot基础讲解(自然语言入门)
6、一文读懂Embedding的概念,以及它和深度学习的关系
7、embedding层和全连接层的区别是什么?
8、NLP中的Embedding方法总结
9、图解Word2vec,读这一篇就够了(通俗易懂)
10、如何通俗理解Word2Vec
11、 大白话讲解word2vec到底在做些什么
12、word2vec基础(非常容易理解)
13、Haffman编码
14、Huffman 编码原理详解(代码示例)
问题:

