
- 1趣图丨阿里p6大概啥水平?是不是不行?
- 2算法数据结构——动态规划算法(Dynamic Programming)超详细总结加应用案例讲解_动态规划 算法
- 3华为OD 2024 | 什么是华为OD,OD 薪资待遇,OD机试题清单_华为od|
- 4Pytorch to(device)_pytorch to device
- 5【AI工具】 一款多SOTA模型集成的高精度自动标注工具(直接安装使用,附源码)_ai模型 识别图片文本自动标注
- 6Python 如何实现计算函数斜率和梯度?【详细教学】_计算一条曲线各点的梯度
- 7云创大数据及其总裁刘鹏教授所编图书双双摘奖!
- 8程序员写博客如何赚钱「5大盈利方向」_技术博客赚钱 收益
- 9GoLang协程与通道---上_协程 通道
- 10Windows C++ 应用软件开发从入门到精通详解_软件入门
JS逆向批改网实现自动提交作文 调用文心一言API自动生成作文_批改网脚本
赞
踩
前天熬了个大夜,下午一点才起,一听到舍友说又要写那个恶心的批改网,气得我直接写了个脚本自动把所有未完成的作文秒杀,话不多说直接开始分析。
一.登陆前的cookies处理
清空网站的所有本地存储,会话存储和cookies,并刷新
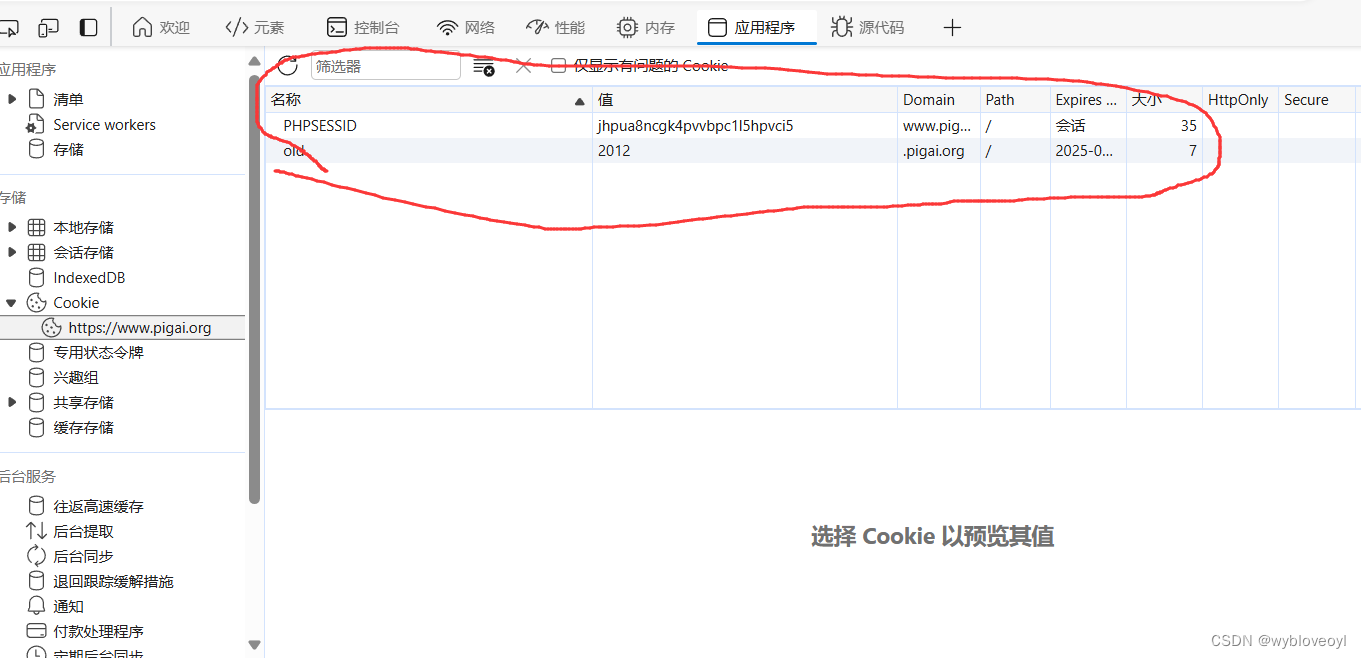
可以看到多出了两个cookies,在抓包的地方搜索set-cookie
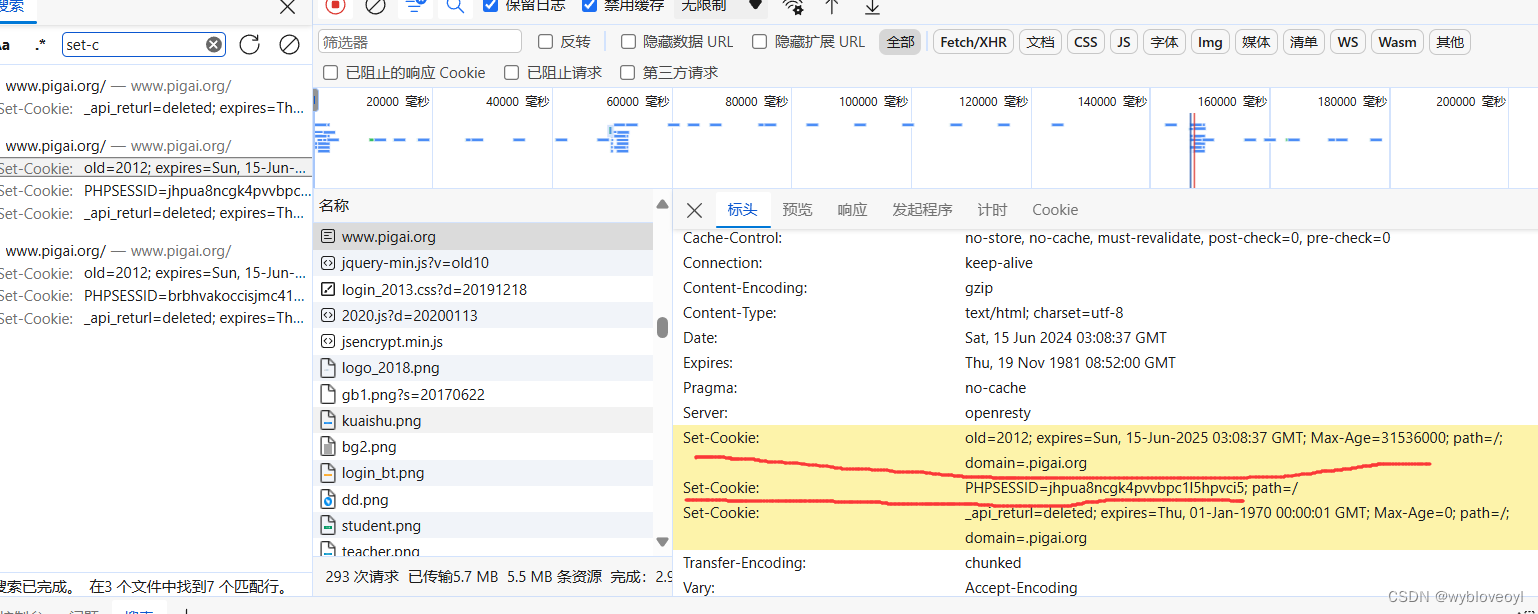 可以发现这两个cookies是服务器返回的
可以发现这两个cookies是服务器返回的
二.登录请求发送
输入账号密码,点击登录,开始抓包
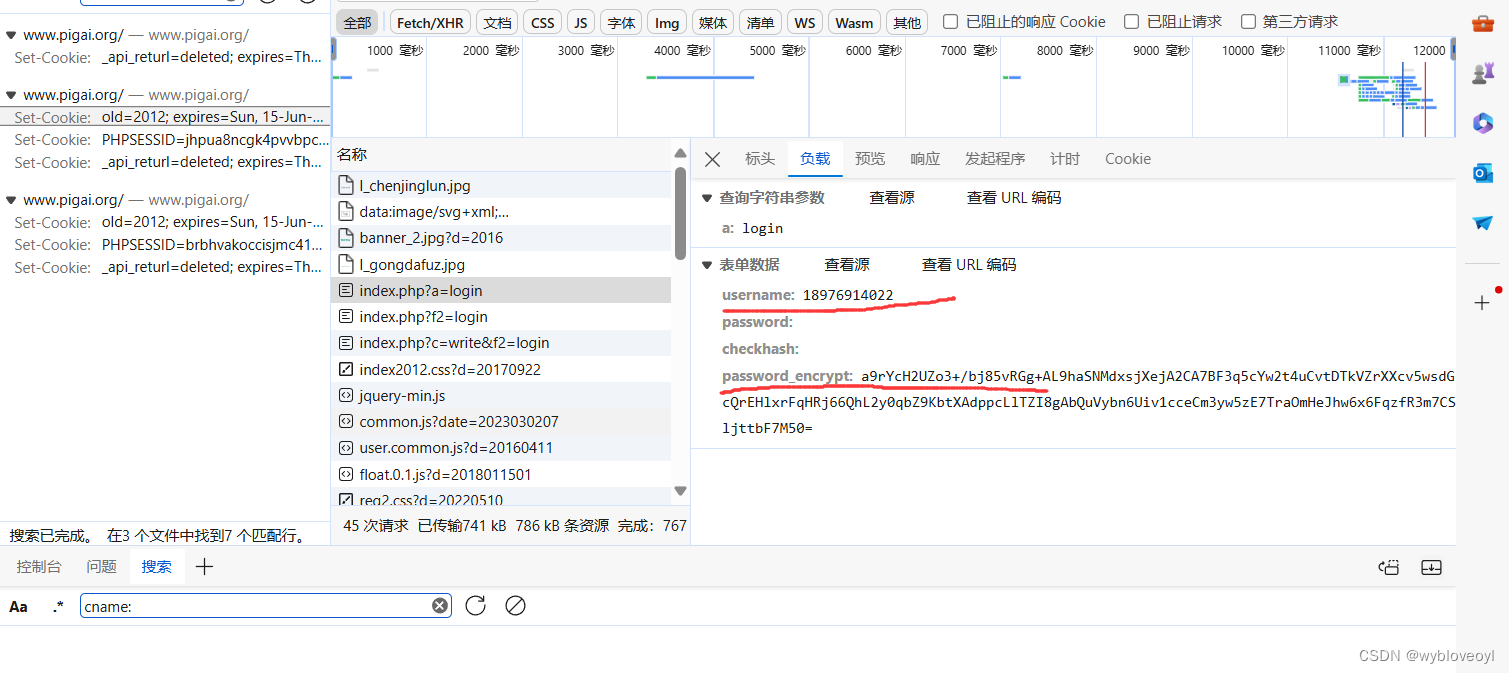
我们很快就发现了登录验证的请求,这个password被加密了
点击发起程序想看看调用堆栈,结果。。。
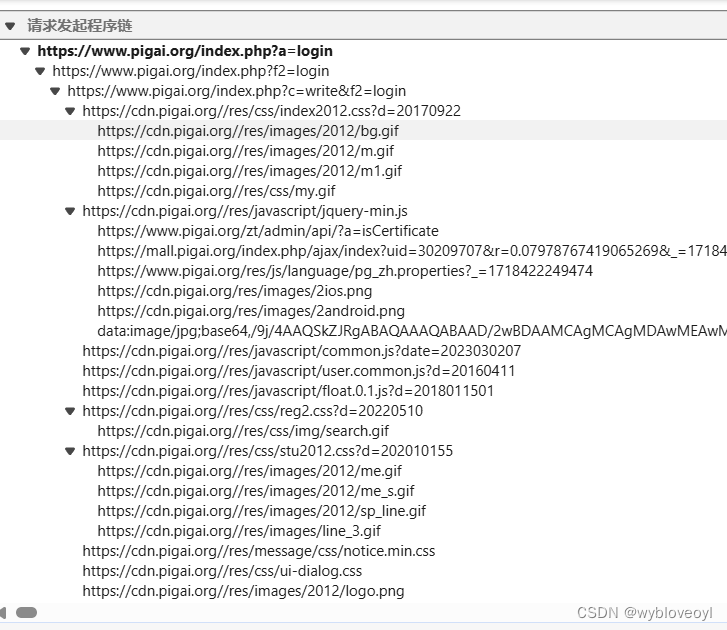
居然看不了,只能查看发起请求的程序链子
搜索几个关键字,很快就能发现加密函数
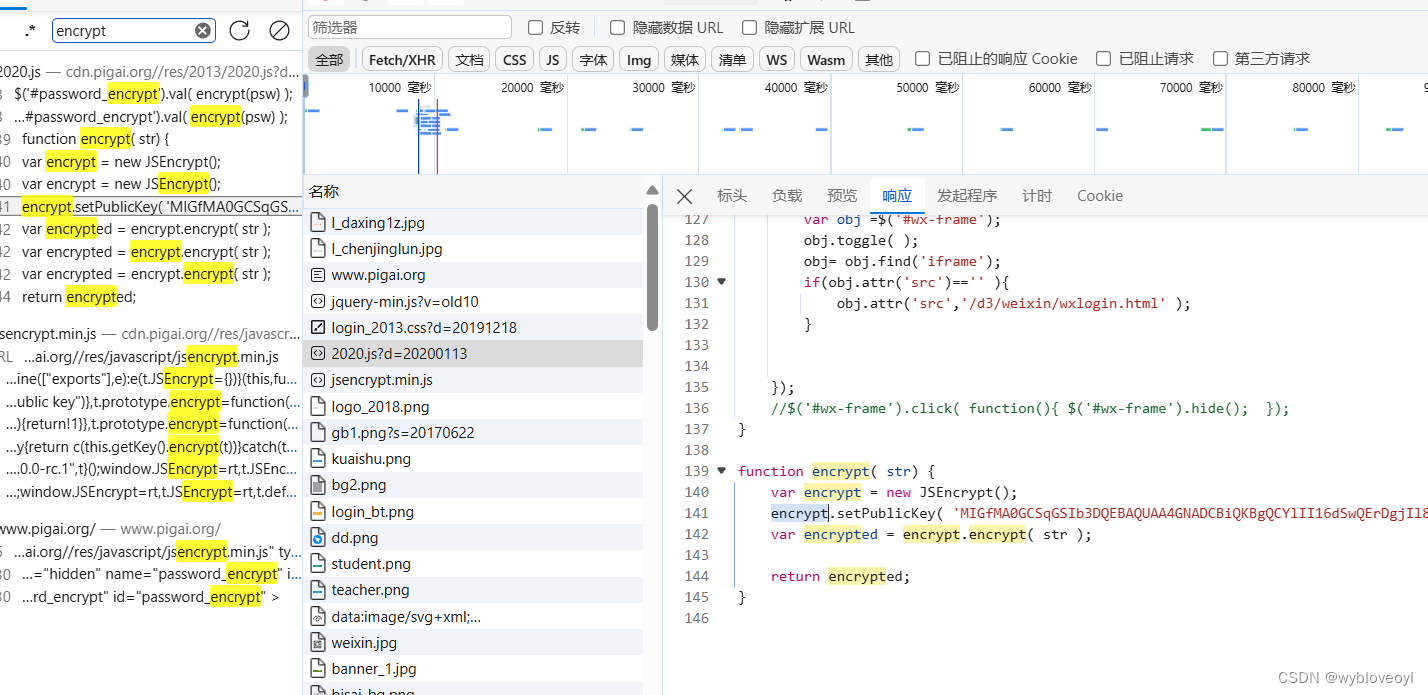
把加密函数搬到本地的js并封装,以便我们后续操作
- const JSEncrypt = require('jsencrypt');
-
- function encrypt(str) {
- var encrypt = new JSEncrypt();
- encrypt.setPublicKey('MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCYlII16dSwQErDgjIl8BzU4NEL2IzvyWiLNxie3mkpw6eseF/iUVb3bisAFH+lzgnrv/mBOKUMkbqtW2+8en/6r0hj6ctvGT+UOtg4P5LF/jxkbE+cA2fVJK2RaBzeEEbrKOvauVnGkEOvPVl1/NK4NgeN6aSPIK9ECfXcjlEOHwIDAQAB');
- var encrypted = encrypt.encrypt(str);
-
- return encrypted;
- }
-
- function main123(password){
- return encrypt(password)
- }
根据前面的分析逻辑,直接对着验证的链接发请求
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/?a=logout',
- 'Sec-Fetch-Dest': 'document',
- 'Sec-Fetch-Mode': 'navigate',
- 'Sec-Fetch-Site': 'same-origin',
- 'Sec-Fetch-User': '?1',
- 'Upgrade-Insecure-Requests': '1',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- response = requests.get('https://www.pigai.org/', headers=headers)
-
- PHPSESSID = response.cookies['PHPSESSID']
-
- old=response.cookies['old']
-
- cookies ={
- 'PHPSESSID': PHPSESSID,
- 'old': old,
- }
-
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- 'Content-Type': 'application/x-www-form-urlencoded',
- # 'Cookie': 'old=2012; PHPSESSID=8oj8mlkeavc583i7l2kutgen77',
- 'Origin': 'https://www.pigai.org',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/',
- 'Sec-Fetch-Dest': 'document',
- 'Sec-Fetch-Mode': 'navigate',
- 'Sec-Fetch-Site': 'same-origin',
- 'Sec-Fetch-User': '?1',
- 'Upgrade-Insecure-Requests': '1',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- params = {
- 'a': 'login',
- }
-
- data = {
- 'username': username,
- 'password': '',
- 'checkhash': '',
- 'password_encrypt': execjs.compile(open('密码加密.js', 'r', encoding='gbk').read()).call('main123', password),
- }
-
- response = requests.post('https://www.pigai.org/index.php', params=params, cookies=cookies, headers=headers, data=data,allow_redirects=False)
这样我们就算是登陆进去了,可以发现已上代码最后一句话
response = requests.post('https://www.pigai.org/index.php', params=params, cookies=cookies, headers=headers, data=data,allow_redirects=False)
这里我将allow_redirects=False,这是禁止重定向操作,但是为什么要这么做呢?
点击我们刚刚验证的请求,再点击cookies
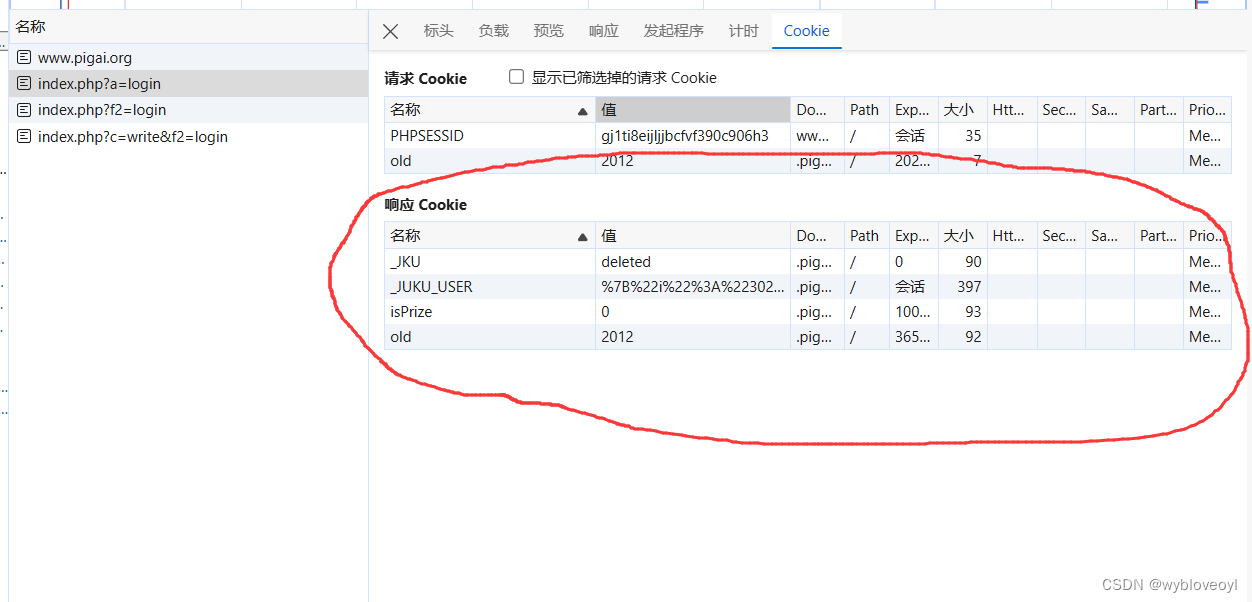 服务器给我们返回了很多cookies,这些cookies是服务器识别我们身份的标识,所以我们要将其保存下来
服务器给我们返回了很多cookies,这些cookies是服务器识别我们身份的标识,所以我们要将其保存下来
但是若我没有禁止重定向操作,最后请求中获取的cookie如下
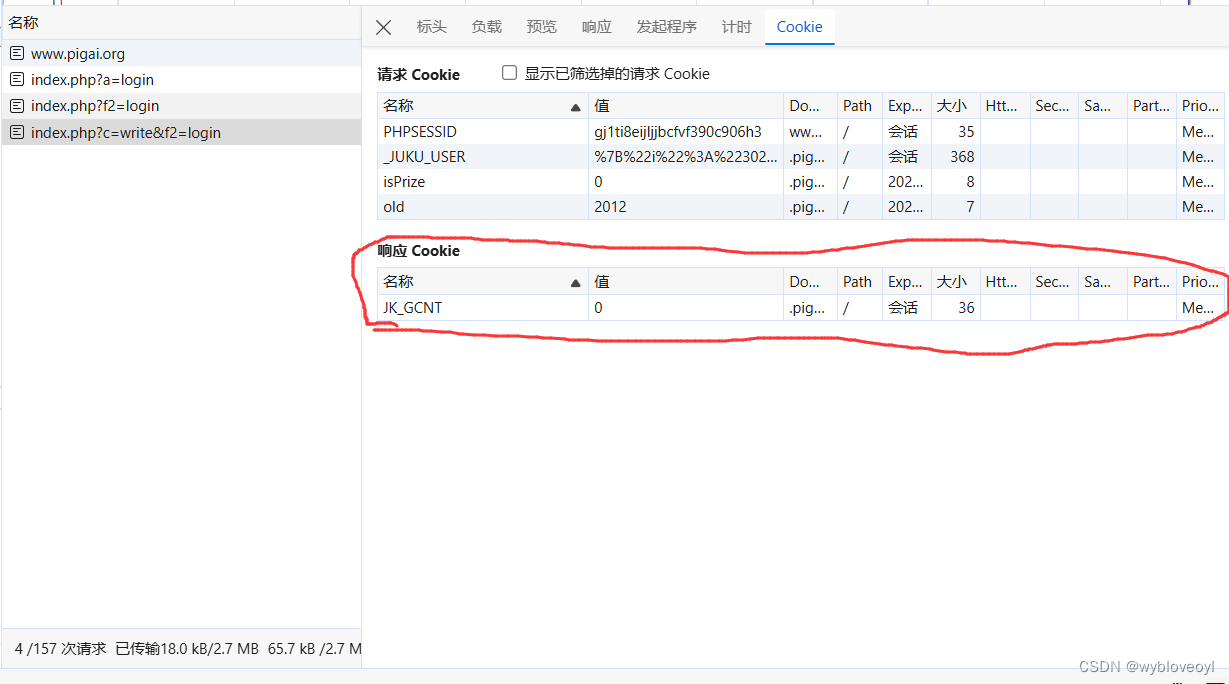
这是怎么回事呢?点击预览看看
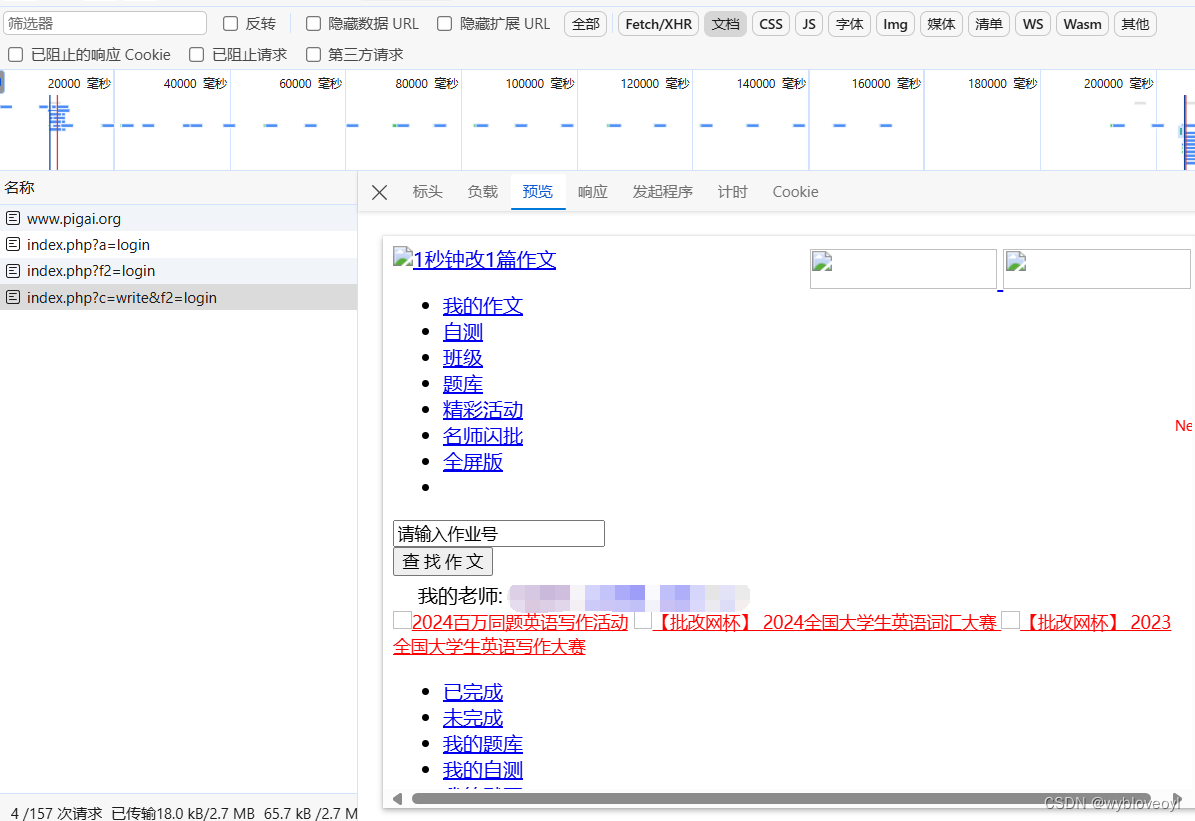 原来是我们验证通过后,服务器会直接给我们重定向到登陆的主界面,若我们不禁止重定向,就无法抓取到能验证我们身份的cookies
原来是我们验证通过后,服务器会直接给我们重定向到登陆的主界面,若我们不禁止重定向,就无法抓取到能验证我们身份的cookies
三.百度统计第三方cookies处理
点击存储查看一下存在我们本地的cookies
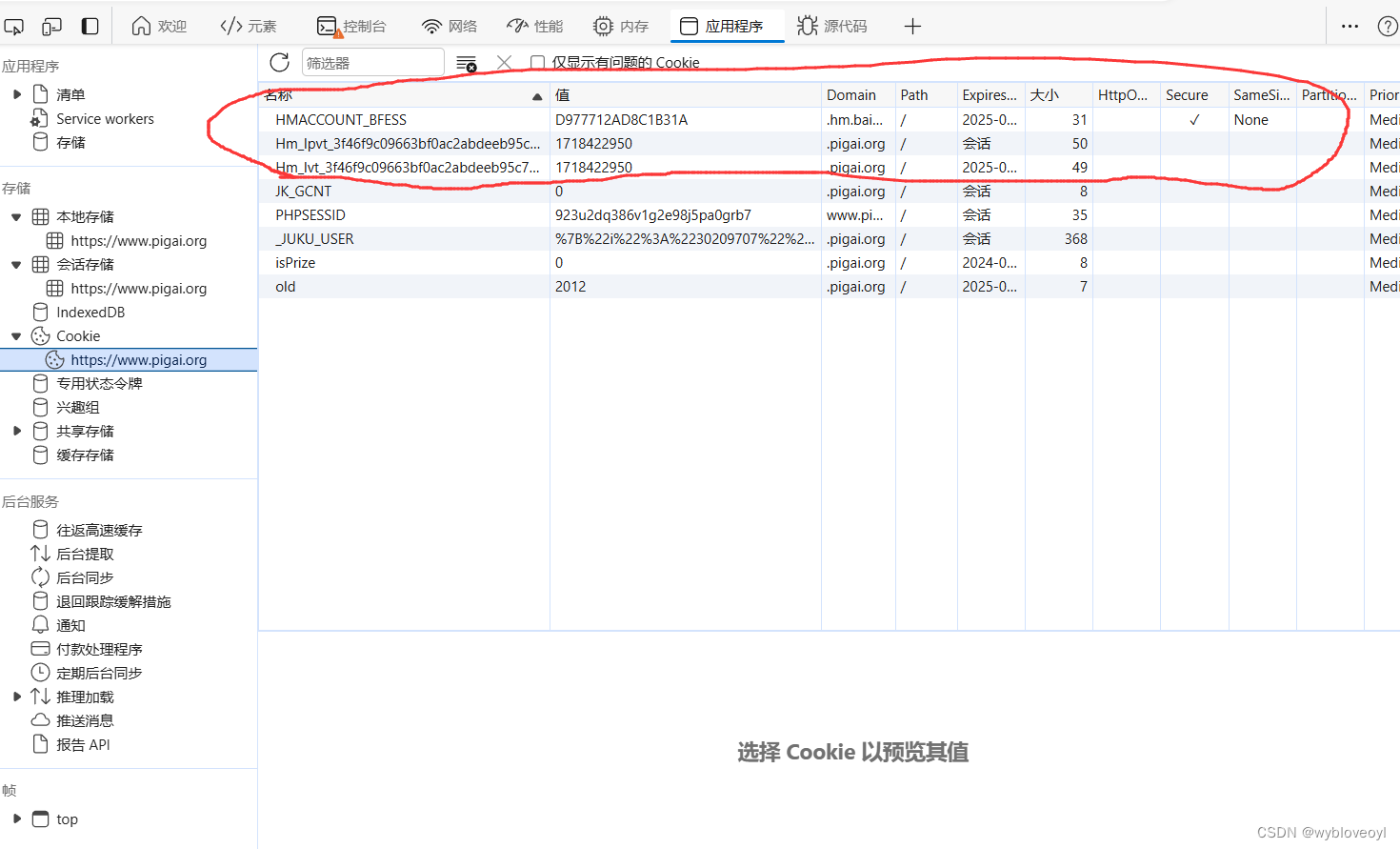 上面那三个cookies其实是批改网引入了百度统计的第三方cookies,百度统计是用来检测访客信息和访客行为的第三方网站,我们直接查看百度统计官方提供的文档
上面那三个cookies其实是批改网引入了百度统计的第三方cookies,百度统计是用来检测访客信息和访客行为的第三方网站,我们直接查看百度统计官方提供的文档
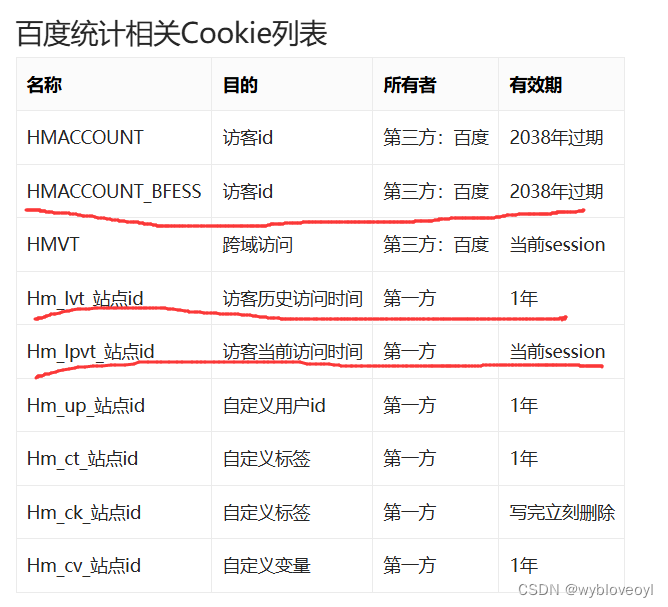
这个Hm_lpvt_和Hm_lvt_我们直接全部设置成当前时间的时间戳就好(意思就是伪装成我们是第一次登录)
这个HMACCOUNT_BFESS是由百度统计接口分配的一个访客id,我们只需要在网站存储中找到一个类似这样的js文件
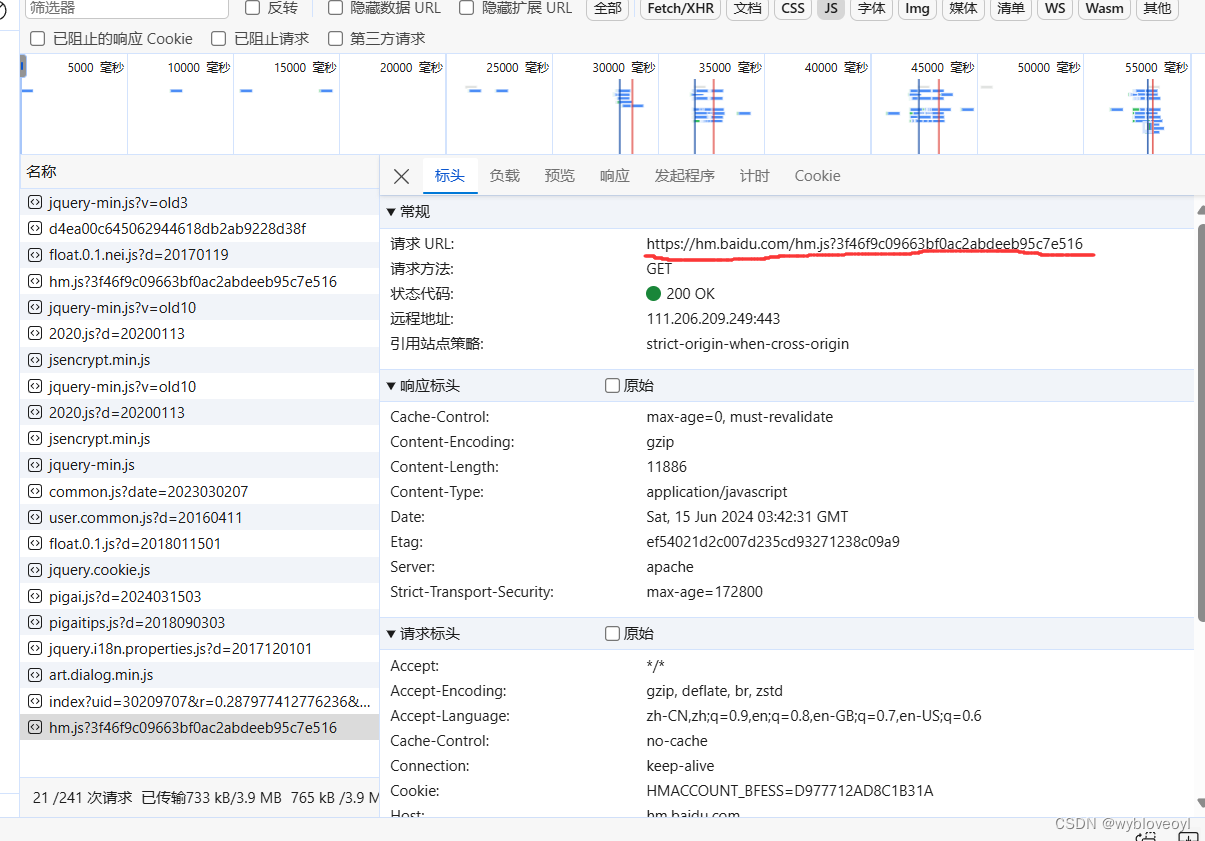 查看一下服务器响应
查看一下服务器响应
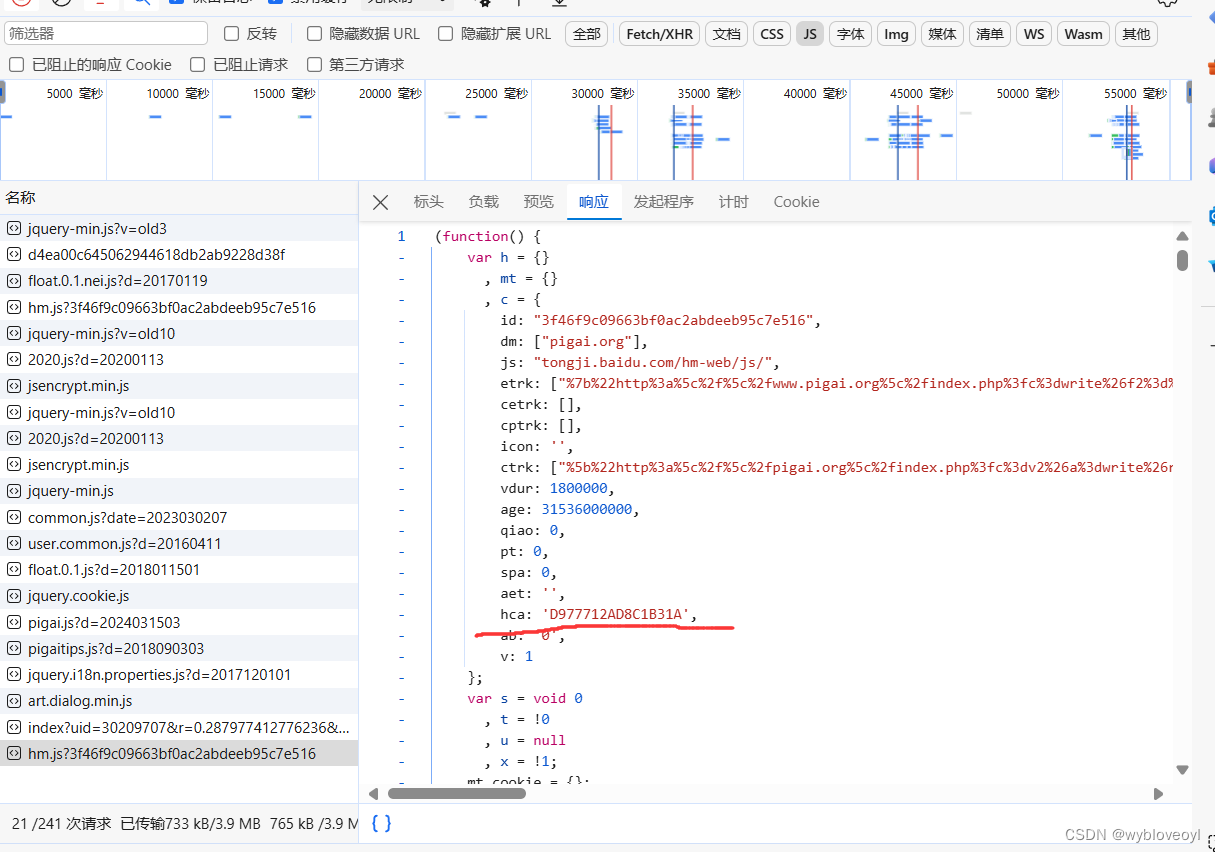 也是直接给我们分配了一个访客id,这里应为返回的是js代码的形式,所以要用到正则表达式将这个字段提取,提取过程如下
也是直接给我们分配了一个访客id,这里应为返回的是js代码的形式,所以要用到正则表达式将这个字段提取,提取过程如下
- headers = {
- 'Accept': '*/*',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- # 'Cookie': 'HMACCOUNT_BFESS=7C04F9FF37E951F6',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/',
- 'Sec-Fetch-Dest': 'script',
- 'Sec-Fetch-Mode': 'no-cors',
- 'Sec-Fetch-Site': 'cross-site',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- response = requests.get('https://hm.baidu.com/hm.js?3f46f9c09663bf0ac2abdeeb95c7e516', headers=headers)
-
- match = re.search(r"hca:'([0-9A-Fa-f]+)'", response.text)
-
- BFESS=match.group(1)
四.批量获取未完成的作文题目
然后,我们点击未完成
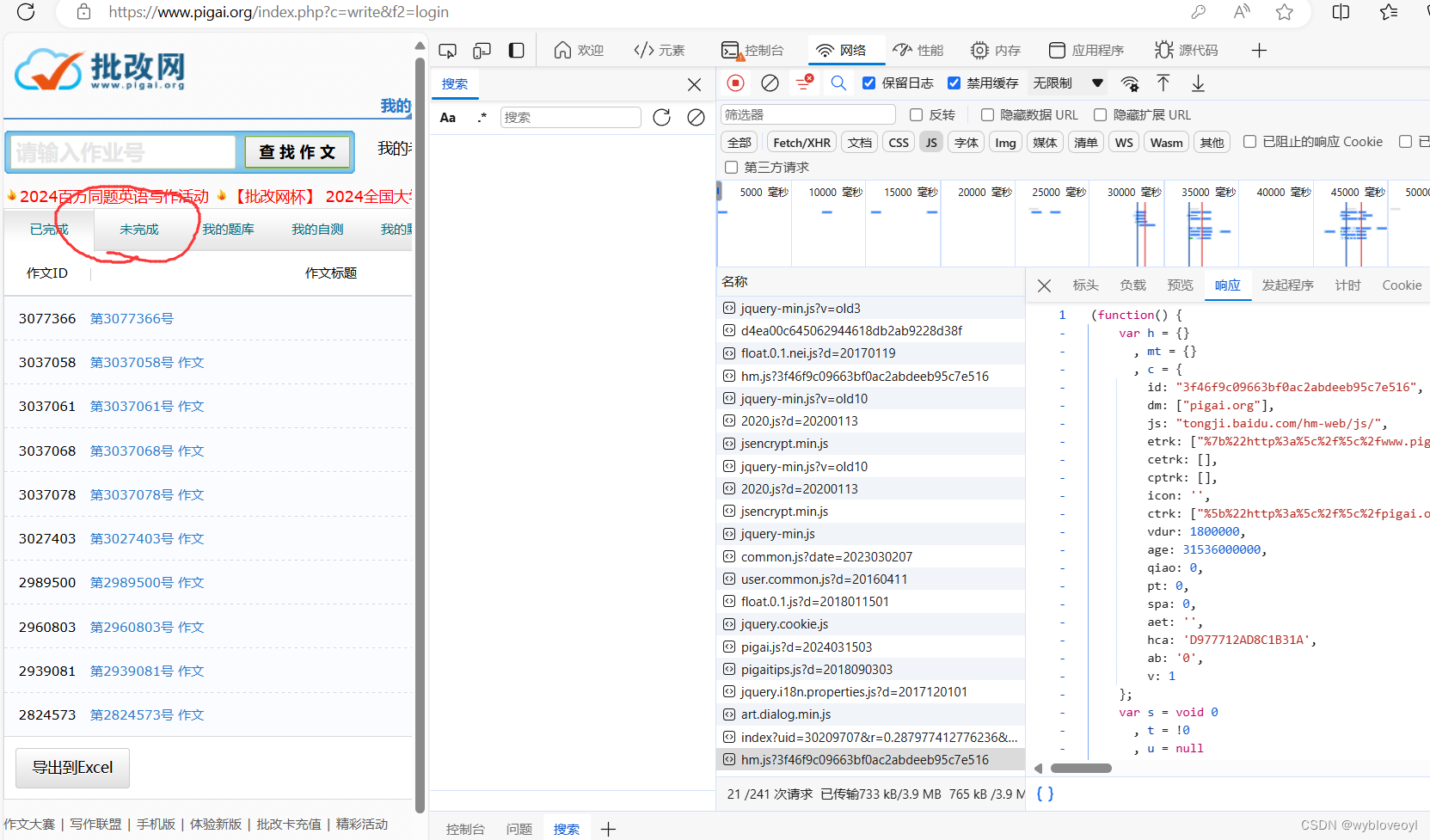
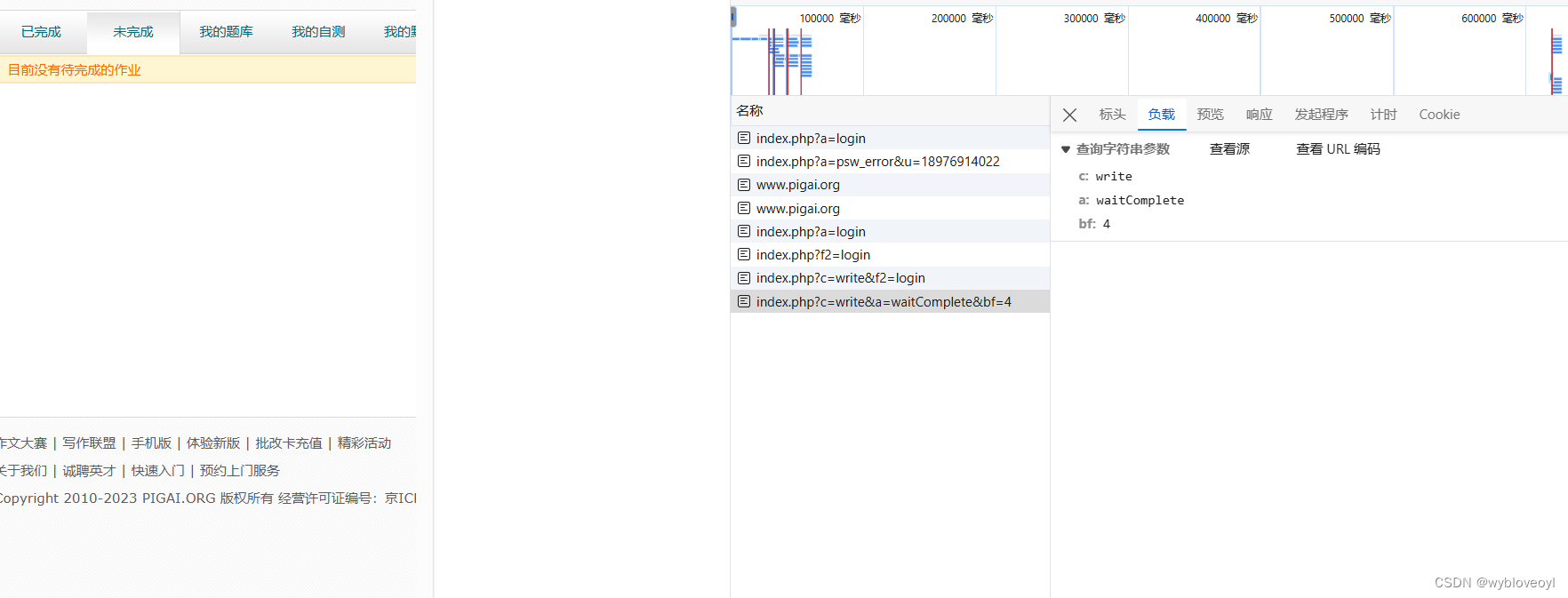 抓到了数据包,这里应该会返回我没写完作文的所有信息,但是因为我的作文全部用这个脚本秒了,所以啥都没看到,这里我是用xpath的方法批量提取我没完成作文的所有作文编号,并存在一个列表中
抓到了数据包,这里应该会返回我没写完作文的所有信息,但是因为我的作文全部用这个脚本秒了,所以啥都没看到,这里我是用xpath的方法批量提取我没完成作文的所有作文编号,并存在一个列表中
- cookies ={
- 'PHPSESSID': PHPSESSID,
- 'old': old,
- '_JUKU_USER':response.cookies['_JUKU_USER'],
- 'isPrize': response.cookies['isPrize'],
- 'Hm_lpvt_3f46f9c09663bf0ac2abdeeb95c7e516':str(int(time.time()*1000)),
- 'Hm_lvt_3f46f9c09663bf0ac2abdeeb95c7e516':str(int(time.time()*1000)),
- 'HMACCOUNT_BFESS':BFESS,
- 'JK_GCNT':'0'
- }
-
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- # 'Cookie': 'old=2012; PHPSESSID=eqnfap3mhnh5i894d1e0dorr44; _JUKU_USER=%7B%22i%22%3A%2230209707%22%2C%22u%22%3A%22N633f8e15a0a8a%22%2C%22u2%22%3A%22%5Cu5434%5Cu6bd3%5Cu535a%22%2C%22k%22%3A%22432d6aaf111ccba5cddcce2f653223b1%22%2C%22img%22%3A%22%22%2C%22ts%22%3A2%2C%22s%22%3A%22%5Cu56db%5Cu5ddd%5Cu5927%5Cu5b66%22%2C%22iv%22%3A0%2C%22st%22%3A%220%22%2C%22no%22%3A%222022141530099%22%2C%22cl%22%3A%22105%22%2C%22it%22%3A%221%22%7D; isPrize=0; JK_GCNT=0; Hm_lvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718356284; Hm_lpvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718356284',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/index.php?c=write&f2=login',
- 'Sec-Fetch-Dest': 'document',
- 'Sec-Fetch-Mode': 'navigate',
- 'Sec-Fetch-Site': 'same-origin',
- 'Sec-Fetch-User': '?1',
- 'Upgrade-Insecure-Requests': '1',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- params = {
- 'c': 'write',
- 'a': 'waitComplete',
- 'bf': '4',
- }
-
- response = requests.get('https://www.pigai.org/index.php', params=params, cookies=cookies, headers=headers)
-
- tree =etree.HTML(response.text)
-
- paragraphs = tree.xpath('//*[@id="essayList"]//ul')
-
- sum=0
-
- essayLisy=[]
-
- for ul in paragraphs:
- if(sum==0):
- sum+=1
-
- continue
-
- essayLisy.append(ul.xpath('.//li[1]/text()')[0])
-
- sum+=1
接着我们带着我们获取的作文编号就能直接请求到写作文的详情页
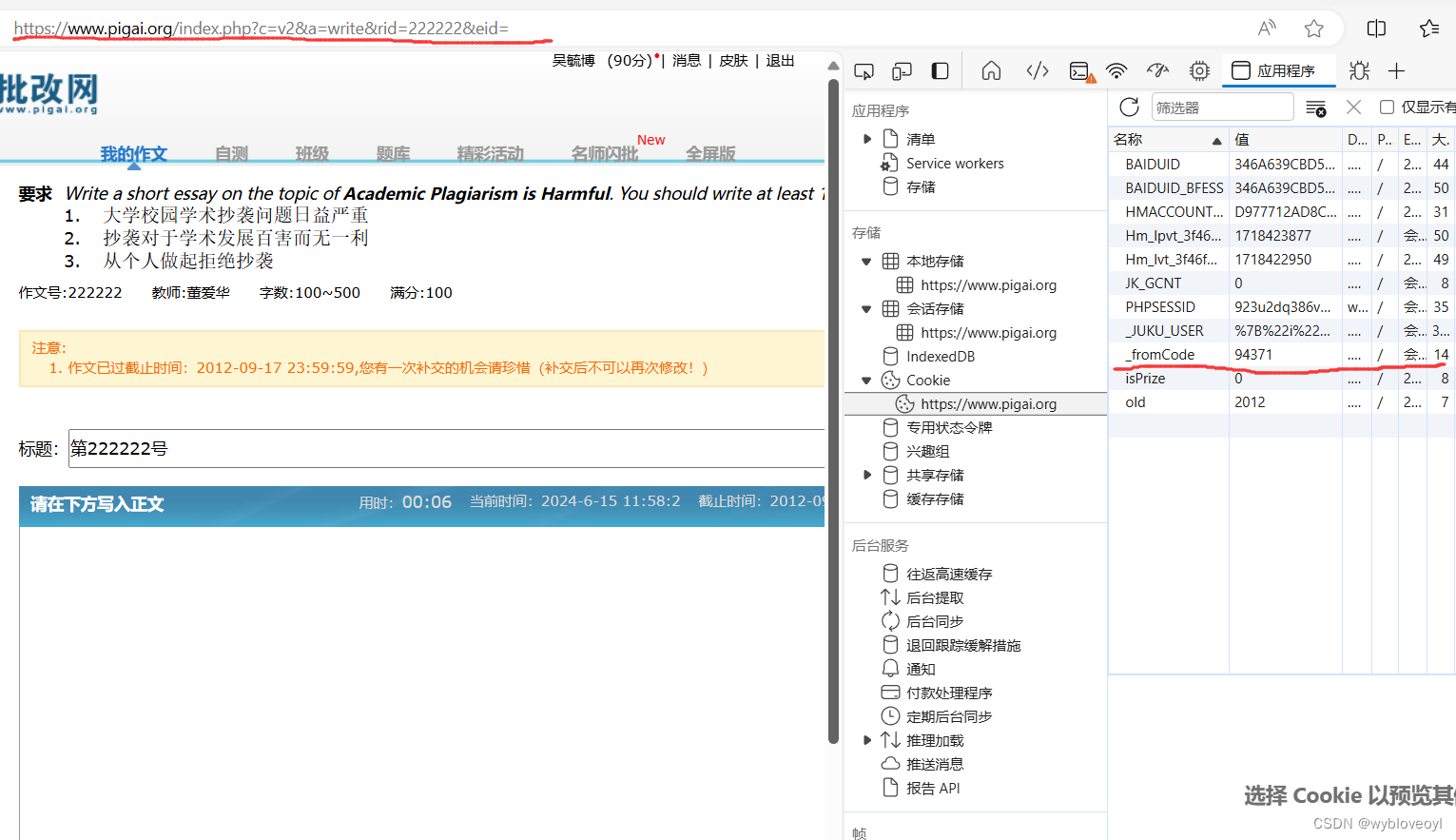
这里得注意,请求后服务器给我们返回了一个_fromcode的cookies,要注意保存
直接用xpath获取作文题目
- for rid in essayLisy:
- headers = {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- # 'Cookie': 'old=2012; PHPSESSID=02k4hi1jt2glddbfhvd381ek47; _JUKU_USER=%7B%22i%22%3A%2230209707%22%2C%22u%22%3A%22N633f8e15a0a8a%22%2C%22u2%22%3A%22%5Cu5434%5Cu6bd3%5Cu535a%22%2C%22k%22%3A%22432d6aaf111ccba5cddcce2f653223b1%22%2C%22img%22%3A%22%22%2C%22ts%22%3A2%2C%22s%22%3A%22%5Cu56db%5Cu5ddd%5Cu5927%5Cu5b66%22%2C%22iv%22%3A0%2C%22st%22%3A%220%22%2C%22no%22%3A%222022141530099%22%2C%22cl%22%3A%22105%22%2C%22it%22%3A%221%22%7D; isPrize=0; JK_GCNT=0; Hm_lvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718358190; Hm_lpvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718358199',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/index.php?c=write&a=waitComplete&bf=4',
- 'Sec-Fetch-Dest': 'document',
- 'Sec-Fetch-Mode': 'navigate',
- 'Sec-Fetch-Site': 'same-origin',
- 'Sec-Fetch-User': '?1',
- 'Upgrade-Insecure-Requests': '1',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- params = {
- 'c': 'v2',
- 'a': 'write',
- 'rid': rid,
- }
-
- response = requests.get('https://www.pigai.org/index.php', params=params, cookies=cookies, headers=headers)
-
- cookies.update({'_fromCode': response.cookies['_fromCode']})
-
- tree = etree.HTML(response.text)
-
- title = tree.xpath('string(//*[@id="request_y"])')
五.调用文言一心api
大公司就是好啊,模型的接口直接给我们随便用
打开百度智能云官网,搜索千帆大模型,创建应用
 阅读官方提供的API文档
阅读官方提供的API文档
 这里有个接口调试平台,非常的好用
这里有个接口调试平台,非常的好用
查看我写的调用代码
- def main(title):
- url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie-3.5-8k-0205?access_token=" + get_access_token()
-
- payload = json.dumps({
- "messages": [
-
- {
- "role": "user",
- "content": title
- }
-
- ],
- "temperature": 0.8,
- "top_p": 0.8,
- "penalty_score": 1,
- "disable_search": False,
- "enable_citation": False,
- "response_format": "text"
- })
- headers = {
- 'Content-Type': 'application/json'
- }
-
- response = requests.request("POST", url, headers=headers, data=payload)
-
- return response.json().get('result')
- def get_access_token():
- """
- 使用 AK,SK 生成鉴权签名(Access Token)
- :return: access_token,或是None(如果错误)
- """
- url = "https://aip.baidubce.com/oauth/2.0/token"
- params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
- return str(requests.post(url, params=params).json().get("access_token"))
直接调用main函数,并传入作文题目,就能返回对应的文章了
六.上传文章
直接对着这个链接发请求就行了,非常简单,作文仅是经过了简单的url编码
- essay=main(title)
-
- headers = {
- 'Accept': '*/*',
- 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
- 'Cache-Control': 'no-cache',
- 'Connection': 'keep-alive',
- 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
- # 'Cookie': 'old=2012; PHPSESSID=javkrsajhm585dur0nt1a6llf1; _JUKU_USER=%7B%22i%22%3A%2230209707%22%2C%22u%22%3A%22N633f8e15a0a8a%22%2C%22u2%22%3A%22%5Cu5434%5Cu6bd3%5Cu535a%22%2C%22k%22%3A%22432d6aaf111ccba5cddcce2f653223b1%22%2C%22img%22%3A%22%22%2C%22ts%22%3A2%2C%22s%22%3A%22%5Cu56db%5Cu5ddd%5Cu5927%5Cu5b66%22%2C%22iv%22%3A0%2C%22st%22%3A%220%22%2C%22no%22%3A%222022141530099%22%2C%22cl%22%3A%22105%22%2C%22it%22%3A%221%22%7D; isPrize=0; JK_GCNT=0; Hm_lvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718385312; _fromCode=692374; Hm_lpvt_3f46f9c09663bf0ac2abdeeb95c7e516=1718385738',
- 'Origin': 'https://www.pigai.org',
- 'Pragma': 'no-cache',
- 'Referer': 'https://www.pigai.org/index.php?c=v2&a=write&rid=11111&eid=',
- 'Sec-Fetch-Dest': 'empty',
- 'Sec-Fetch-Mode': 'cors',
- 'Sec-Fetch-Site': 'same-origin',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
- 'X-Requested-With': 'XMLHttpRequest',
- 'sec-ch-ua': '"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-platform': '"Windows"',
- }
-
- params = {
- 'c': 'ajax',
- 'a': 'postSave',
- }
-
- data = {
- 'utContent': quote(essay),
- 'utTitle': quote('第'+rid+'号 '),
- 'bzold': '',
- 'bz': '',
- 'fileName': '',
- 'filePath': '',
- 'rid': rid,
- 'eid': '',
- 'type': '0',
- 'utype': '',
- 'gao': '1',
- 'uncheck': '',
- 'tiku_id': '0',
- 'engine': '',
- 'fromCode': cookies['_fromCode'],
- 'autoDel': '',
- 'stu_class': '',
- }
-
- response = requests.post('https://www.pigai.org/index.php', params=params, cookies=cookies, headers=headers,
- data=data)
-
- print(response.text)
至此,整个脚本编写的思路就都搞定啦,妈妈再也不用担心我写不完作文了


