
- 1基于51单片机停车RFID一停车扣费充值语音播报系统_基于单片机的自动rfid收费
- 2后端框架-maven-springmvc_xssfcell 不能写入字符串,maven用哪一个
- 3日更2023年6月6日-日签659
- 4文心智能体平台介绍和应用:制作你的智能体(运维小帮手)_如何关闭百度首页的智能体推荐
- 5深入理解Transformer架构的编码器-解码器结构_解码器 自注意力
- 6前端性能提升之 - electorn 结合 vue3 使用webworker 调用go打包的wasm_go打包vue
- 7python OpenCV 图像像素访问 (三)_img.ndim
- 8Redis设计与实现——数据结构(一)_毕设使用redis数据库表结构怎么写
- 9a byte of python中文版_一行Python代码能做什么?
- 10常用技术开发网站记录(firefox版)
翻译: LLM大语言模型图像生成原理Image generation_llm模型 能用来生成图片么
赞
踩
文本生成是许多用户正在使用的,也是所有生成式人工智能工具中影响最大的。但生成式人工智能的一部分兴奋点也在于图像生成。目前也开始出现一些可以生成文本或图像的模型,这些有时被称为多模态模型,因为它们可以在多种模式中操作,如文本或图像。在这个视频中,我想与您分享图像生成是如何工作的。

让我们来看看。只需一个提示,您就可以使用生成式人工智能生成一个从未存在过的人的美丽图片,或者一个未来主义场景的图片,或者像这样一个酷炫的机器人的图片。这项技术是如何工作的呢?今天的图像生成主要是通过一种称为扩散模型的方法完成的。

扩散模型从互联网或其他地方找到的大量图像中学习。事实证明,扩散模型的核心是监督学习。这是它的工作原理。假设算法在互联网上找到了一个苹果的图片,像这样,它希望从这样的图片和其他数亿张图片中学习如何生成图像。第一步是拿这张图片,逐渐添加越来越多的噪声。你可以从这个漂亮的苹果图片,变成一个更嘈杂的,再到一个更嘈杂的,最后变成一个看起来像纯噪声的图片。所有像素都是随机选择的,一点也不像苹果。然后扩散模型使用这样的图片作为数据,通过监督学习,学会输入一个噪声图片并输出一个稍微清晰一点的图片。具体来说,它会创建一个数据集,其中第一个数据点说如果给出第二张输入图片,我们希望监督学习算法学会输出这个苹果的更清晰版本。这是另一个数据点,给出这第三张更嘈杂的图片,我们希望算法学会输出像这样稍微清晰一点的图片。最后,给出一个像这第四张图片的纯噪声,我们希望它学会输出一个暗示苹果存在的稍微清晰一点的图片。
在经过可能数亿张图片的培训后,像这样的过程,当你想要应用它来生成一张新图片时,这就是你运行它的方式。
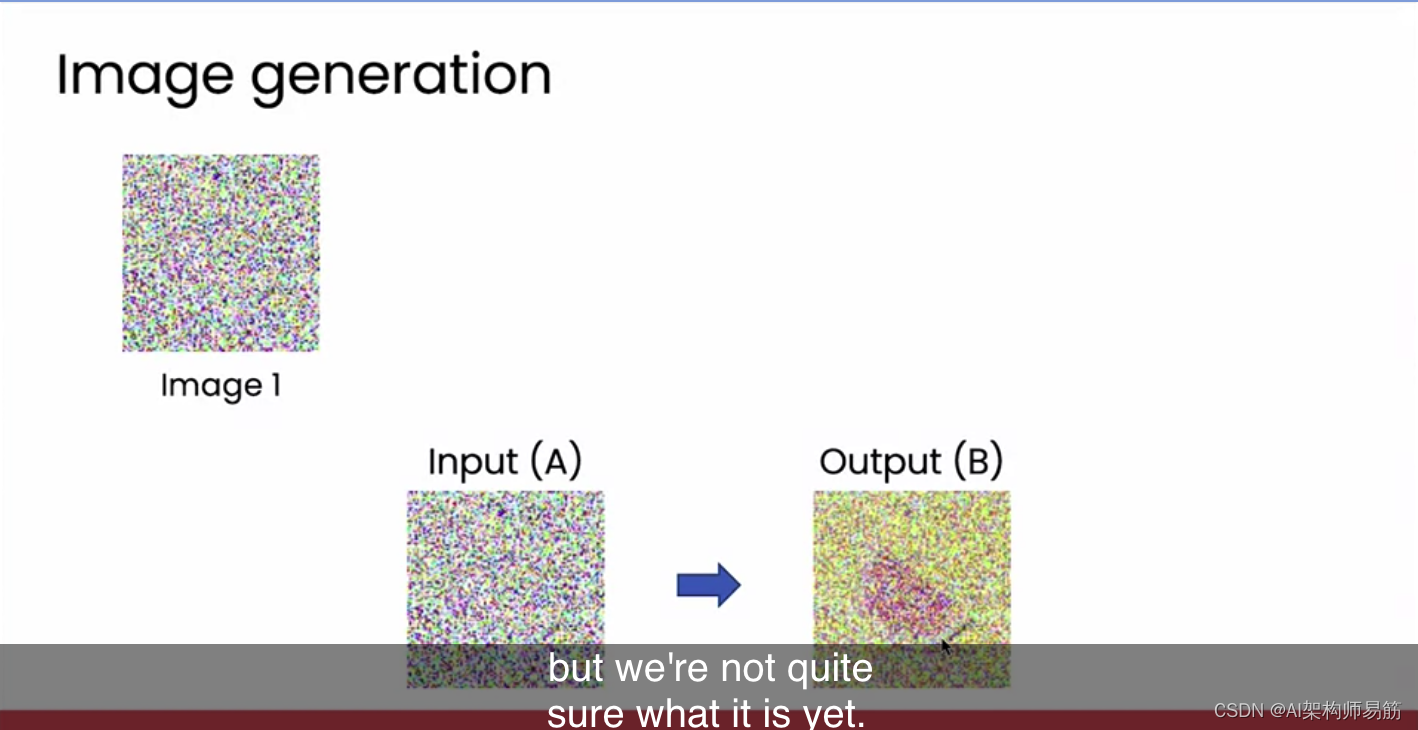
首先是从纯噪声图片开始。首先拍摄一张图片,图片中的每一个像素都是完全随机选择的。然后我们将这张图片输入到我们之前行的监督学习算法中。

当我们输入纯粹噪声时,它学会从这张图片中去除一点噪声,你可能会得到一张暗示着中间有某种水果的图片,但我们还不确定它是什么。给定第二张图片,我们再次输入到模型中,它会去除更多的噪声,现在看起来我们可以看到一张带有噪声的西瓜图片。
如果你再应用一
次这个过程,我们最终会得到这张第四张图片,看起来像是一张漂亮的西瓜图片。我在前一张幻灯片中用四个步骤说明增加噪声的过程,在这张幻灯片中用四个步骤说明去除噪声的过程。

但在实践中,扩散模型大概有100个步骤会更典型。这个算法适用于完全随机生成图片。

但我们想能够通过指定一个提示来控制它生成的图像,告诉它我们想要生成什么。让我描述一下这个算法的修改,让你添加文本或提示来告诉它你想生成什么。在这个训练数据中,我们得到了这样的苹果图片,以及可能生成这个苹果的描述或提示。这里,我有一个文本描述说这是一个红苹果。然后我们会像以前一样,向这张图片中添加噪声,直到得到第四张图像,即纯粹的噪声。但我们要改变构建学习算法的方式,也就是说,不是将稍微嘈杂的图片作为输入,期望它生成一张干净的图片,我们会将输入A给监督学习算法B,这个嘈杂的图片,以及能生成这张图片的文本标题或提示,即红苹果。给定这个输入,我们希望算法输出这张干净的苹果图片。
同样,我们将使用其他嘈杂的图像为算法生成额外的数据点。每次,给定一个嘈杂的图像和文本提示红苹果,我们希望算法学会生成一个红苹果的更清晰的图片。

在从大量数据集中学习之后,当你想应用这个算法生成比如说绿色香蕉时,这就是你要做的。和以前一样,我们从一张纯粹噪声的图像开始。每一个像素都是完全随机选择的。如果你想生成一个绿色的香蕉,你就把这张纯粹噪声的图片和提示“绿色香蕉”输入到监督学习算法中

。现在它知道你想要一个绿色的香蕉,希望它会输出这样的图片。看不清楚香蕉,但可能中间有一些建议绿色的水果,这是图像生成的第一步。下一步是,我们将这张右边的图像作为输出B,再次作为输入A,再加上提示“绿色香蕉”,让它生成一张稍微清晰的图片,现在我们清楚地看到,看起来有一个绿色的香蕉,但是相当嘈杂的。

我们再做一次这个过程,它最终去除了大部分噪声,直到我们得到了那张相当不错的绿色香蕉图片。这就是扩散模型用于生成图像的工作方式。在生成美丽图像的这个神奇过程的核心,再次是监督学习。感谢您坚持观看这个可选视频,期待下周见到您,届时我们将更深入地探讨使用生成AI构建的应用程序。下一个视频见。
参考
https://www.coursera.org/learn/generative-ai-for-everyone/lecture/CQP1v/image-generation-optional

