
- 1牛客网 奶酪_现有一块大奶酪它的高度为 hh它的长度和宽度我们可以认为是无限大的奶酪中间有
- 2Android逆向之路---让我们试试另一种方法看漫画-(2)
- 3Dify快速接入微信_dify on wechat
- 4JSREPL README.md 中文翻译_readme.md翻译成中文
- 5MySQL的基本操作(超详细)_mysql 基本操作
- 6spark scala 编写 词频统计案例_linux spark 词频统计
- 7Hadoop启动正常,但是进不了Hadoop102:9870_hadoop102:9870
- 8MySQL数据库笔记(二)
- 9checkout 撤销修改_Git的4个阶段的撤销更改
- 10HLS优化设计(一)
[论文解析] DreamBooth3D: Subject-Driven Text-to-3D Generation
赞
踩
Paper:https://arxiv.org/abs/2303.13508
Homepape: https://dreambooth3d.github.io/
Overview
3. Approach
Problem setup.
Text prompt T,and subject image:

Our aim is to generate a 3D asset that captures the identity (geometry and appearance) of the given subject while also being faithful to the text prompt.
We optimize 3D assets in the form of Neural Radiance Fields (NeRF) [28], which consists of an MLP network M that encodes radiance fields in a 3D volume.
we use DreamFusion [33] text-to-3D optimization and DreamBooth [38] personalization in our framework.
3.1. Preliminaries
DreamBooth T2I Personalization.
Briefly, DreamBooth uses the following diffusion loss function to finetune the T2I model:

where t ∼ U[0, 1] denotes the time-step in the diffusion process and wt, αt and σt are the corresponding scheduling parameters.
DreamFusion
DreamFusion introduced score distillation sampling (SDS) that pushes noisy versions of the rendered images to lower energy states of the T2I diffusion model:

3.2. Failure of Naive Dreambooth+Fusion
A straight-forward approach for subject-driven textto-3D generation is first personalizing a T2I model and then use the resulting model for Text-to-3D optimization. For instance, doing DreamBooth optimization followed by DreamFusion. which we refer to as DreamBooth+Fusion.
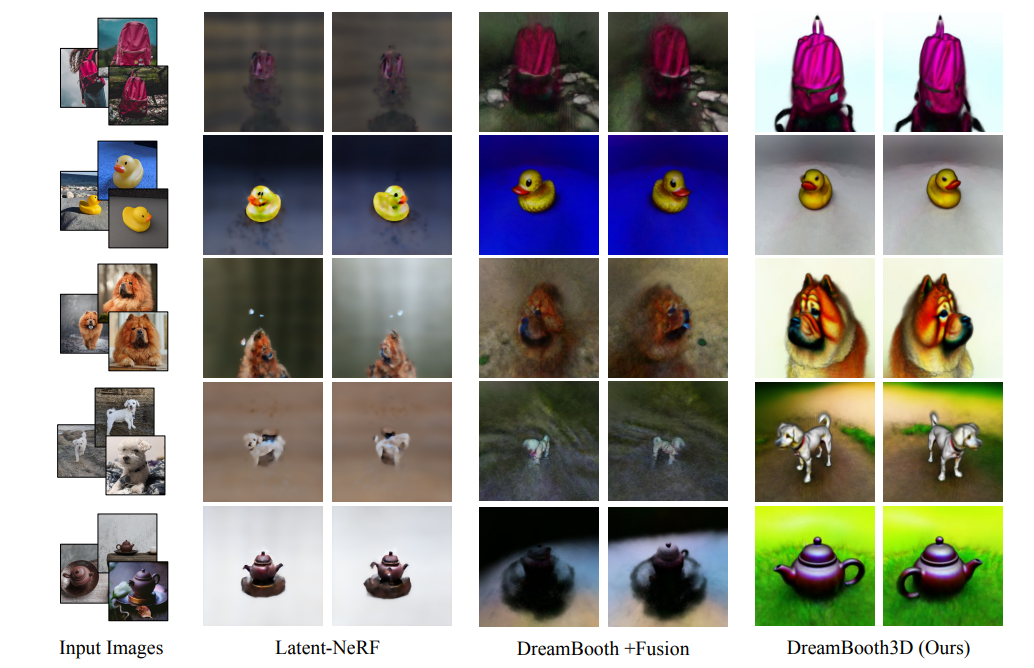
Figure 3: Visual Results on 5 different subjects with two baseline techniques of Latent-NeRF and DreamBooth+Fusion along with those of our technique (DreamBooth3D). Results clearly indicate better 3D consistent results with our approach compared to either of the baseline techniques. See the supplement for additional visualizations and videos.
A key issue we find is that DreamBooth tends to overfit to the subject views that are present in the training views, leading to reduced viewpoint diversity in the image generations.
3.3. Dreambooth3D Optimization
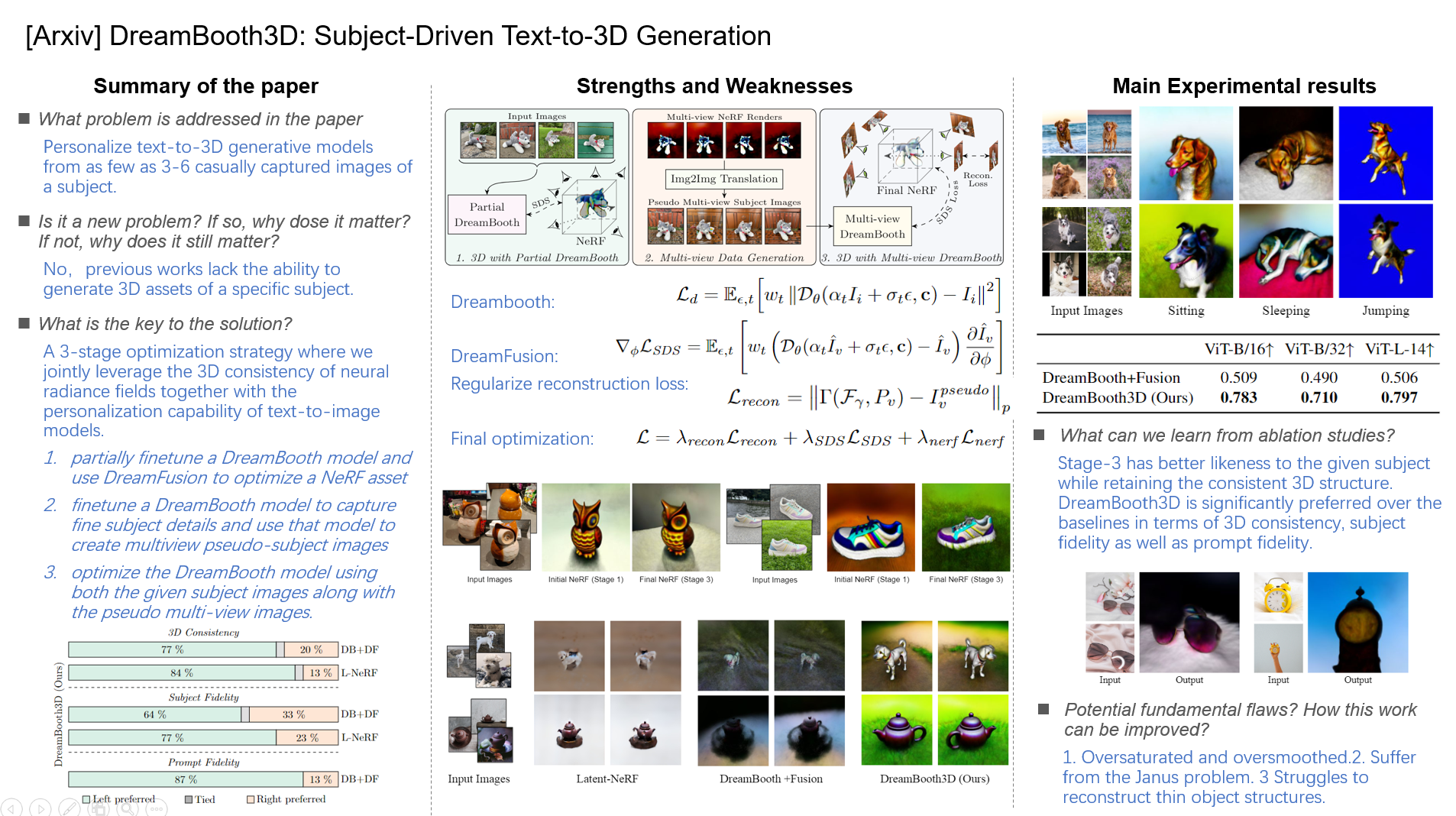
Fig. 2 illustrates the 3 stages in our approach, which we describe in detail next.

Figure 2: DreamBooth3D Overview. In the stage-1 (left), we first partially train a DreamBooth and use the resulting model to optimize the initial NeRF. In stage-2 (middle), we render multi-view images along random viewpoints from the initial NeRF and then translate them into pseudo multi-view subject images using a fully-trained DreamBooth model. In the final stage-3 (right), we further fine-tune the partial DreamBooth using multi-view images and then use the resulting multi-view DreamBooth to optimize the final NeRF 3D asset using the SDS loss along with the multi-view reconstruction loss.
Stage-1: 3D with Partial DreamBooth
We first train a personalized DreamBooth model ˆDθ on the input subject images such as those shown in Fig. 2 (left).
- DreamFusion on such partially finetuned DreamBooth models can produce a more coherent 3D NeRF.
- use the SDS loss (Eq. 2) to optimize an initial NeRF asset for a given text prompt as illustrated in Fig. 2 (left).
- However, the partial DreamBooth model as well as the NeRF asset lack complete likeness to the input subject.
Stage-2: Multi-view Data Generation.
we first render multiple images along random viewpoints {v} from the initial NeRF asset resulting in the multi-view renders as shown in Fig. 2 (middle).
- We then add a fixed amount of noise by running the forward diffusion process from each render to tpseudo , and then run the reverse diffusion process to generate samples using the fully-trained DreamBooth model ˆDθ as in [25].(SDEdit: Image Synthesis and Editing with Stochastic Differential Equations)
- However, these images are not multi-view consistent as the reverse diffusion process can add different details to different views, so we call this collection of images pseudo multi-view images.
Stage-3: Final NeRF with Multi-view DreamBooth.
Both the viewpoints as well as the subject-likeness are only approximately accurate due to the stochastic nature of DreamBooth and Img2Img translation.
We then use generated multi-view images and input subject images to optimize our final DreamBooth model followed by a final NeRF 3D asset.
We then use multi-view Dreambooth model to optimize NeRF 3D asset using the DreamFusion SDS loss (Eq.2).
In particular, since we know the camera parameters {Pv } from which these images were generated, we additionally regularize the training of the second NeRF MLP Fγ , with γ parameters with the reconstruction loss:

the first term in the right is the rendering function that renders an image from the NeRF Fγ along the camera viewpoint Pv .
Fig. 2 (right) illustrate the optimization of final NeRF with SDS and multi-view reconstruction losses. The final NeRF optimization objective is given as:

4. Experiments
4.1. Results
Visual Results.
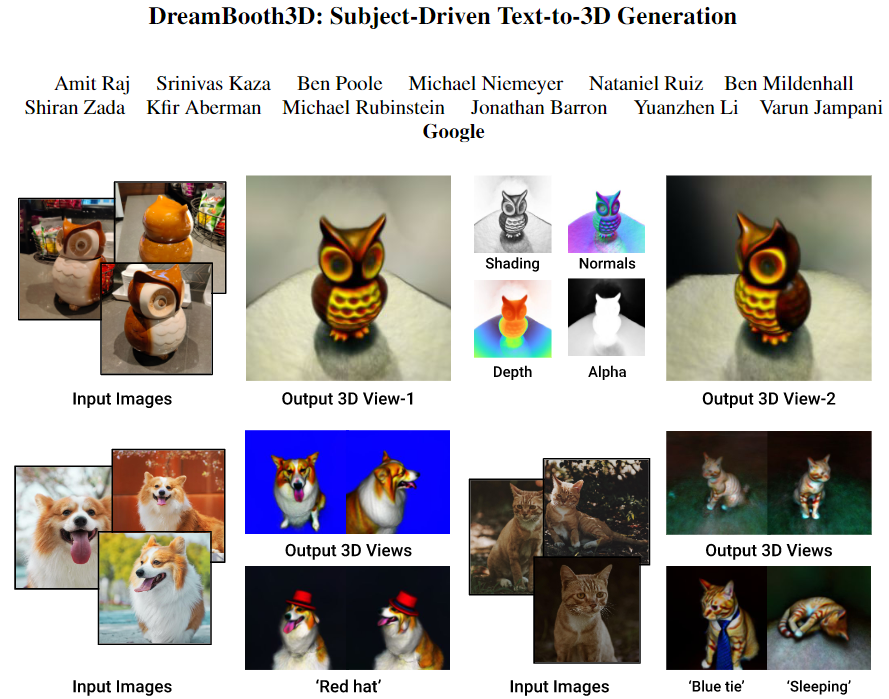
Fig. 1 shows sample visual results of our approach along with different semantic variations and contextualizations.

Figure 1: DreamBooth3D is a personalized text-to-3D generative model that creates plausible 3D assets of a specific subject from just 3-6 images. Top: 3D output and geometry estimated for an owl object. Bottom: our approach can generate variations of the 3D subject in different contexts (sleeping) or with different accessories (hat or tie) based on a text prompt.
Quantitative Comparisons.
Table 1. clearly demonstrate significantly higher scores for the DreamBooth3D results indicating better 3D consistency and textprompt alignment of our results.

Table 1: Quantitative comparisons using CLIP Rprecision on DreamBooth+Fusion (baseline) and DreamBooth3D generations indicate that renderings from our 3D model outputs more accurately resemble the text prompts.
Initial vs. Final NeRF.

Figure 4: Initial vs. Final NeRF Estimates. Sample multi-view results show that the initial NeRF obtained after stage-1 has only a partial likeness to the given subject whereas the final NeRF from stage-3 of our pipeline has better subject-identity
User Study.
We conduct pairwise user studies comparing DreamBooth3D to baselines in order to evaluate our method under three axes: (1) Subject fidelity (2) 3D consistency and plausibility (3) Prompt fidelity

Figure 5: User Study. Users show a significant preference for our DreamBooth3D over DB+DF and L-NeRF for 3D consistency, subject fidelity and prompt fidelity.
4.2. Sample Applications
Recontextualization.

Figure 6: 3D Recontextualizations with DreamBooth3D. With simple edits in the text prompt, we can generate nonrigid 3D articulations and deformations that correspond to the semantics of the input text. Visuals show consistent contexualization of different dogs in different contexts of sitting, sleeping and jumping. See the supplement for videos.
Color/Material Editing.

Figure 7: Sample Applications. DreamBooth3D’s subject preservation and faithfulness to the text prompt enables several applications such as color/material editing, accessorization, stylization, etc. DreamBooth3D can even produce plausible 3D models from unrealistic cartoon images. See the supplemental material for videos.
Accessorization
Fig. 7 shows sample accessorization results on a cat subject, where we put on a tie or a suit into the 3D cat model output. Likewise, one can think of other accessorizations like putting on a hat or sunglasses etc.
Stylization
Fig. 7 also shows sample stylization results, where a cream colored shoe is stylized based on color and the addition of frills.
Cartoon-to-3D.
Fig. 7 shows a sample result where the resulting 3D model for the red cartoon character is plausible, even though all the images show the cartoon only from the front. Refer to the supplementary material for more qualitative results on different applications.
4.3. Limitations
- First, the optimized 3D representations are sometimes oversaturated and oversmoothed
- the optimized 3D representations can sometimes suffer from the Janus problem of appearing to be front-facing from multiple inconsistent viewpoints if the input images do not contain any viewpoint variations.
- our model sometimes struggles to reconstruct thin object structures like sunglasses

Figure 8: Sample Failure Cases. We observe DreamBooth3D often fails to reconstruct thin object structures like sunglasses, and sometimes fails to reconstruct objects with not enough view variation in the input images.
5. Conclusion
In this paper, we have proposed DreamBooth3D , a method for subject-driven text-to-3D generation. Given a few (3-6) casual image captures of a subject (without any additional information such as camera pose), we generate subject-specific 3D assets that also adhere to the contextualization provided in the input text prompts (e.g. sleep-ing, jumping, red, etc.). Our extensive experiments on the DreamBooth dataset [38] have shown that our method can generate realistic 3D assets with high likeness to a given subject while also respecting the contexts present in the input text prompts. Our method outperforms several baselines in both quantitative and qualitative evaluations. In the future, we plan to continue to improve the photorealism and controllability of subject-driven 3D generation.

