
- 1常用的第三方库有哪些?_第三方软件库有哪些
- 2回归预测 | MATLAB实现WOA-CNN鲸鱼算法优化卷积神经网络的数据多输入单输出回归预测_matlab回归问题cnn 调优
- 3Linux集群 安全防御-iptables_linux服务器集群安全问题
- 4docker是什么?和kubernetes(k8s)是什么关系?
- 5flask中使用原生sql语句_flask 原生sql
- 6springboot整合积木报表_积木报表源码
- 7Ubuntu在win10上网络异常问题_乌班图kvm win10网路受限
- 8zabbix监控vSphere
- 92023年十大目标检测模型!
- 10FL Studio 21 for Mac安装教程及FL Studio 21软件制作人声混音效果教程_fl studio的混音set in ms是
机器学习:Python实现聚类算法之总结(1)_聚类代码
赞
踩
3)Spectral Clustering算法函数
a)核心函数:sklearn.cluster.SpectralClustering
因为是基于图论的算法,所以输入必须是对称矩阵。
b)主要参数(参数较多,详细参数)
n_clusters:聚类的个数。(官方的解释:投影子空间的维度)
affinity:核函数,默认是’rbf’,可选:“nearest_neighbors”,“precomputed”,"rbf"或sklearn.metrics.pairwise_kernels支持的其中一个内核之一。
gamma :affinity指定的核函数的内核系数,默认1.0
c)主要属性
labels_ :每个数据的分类标签
d)算法示例:代码中有详细讲解内容


from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import spectral_clustering
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from itertools import cycle ##python自带的迭代器模块
##产生随机数据的中心
centers = [[1, 1], [-1, -1], [1, -1]]
##产生的数据个数
n_samples=3000
##生产数据
X, lables_true = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.6,
random_state =0)
##变换成矩阵,输入必须是对称矩阵
metrics_metrix = (-1 * metrics.pairwise.pairwise_distances(X)).astype(np.int32)
metrics_metrix += -1 * metrics_metrix.min()
##设置谱聚类函数
n_clusters_= 4
lables = spectral_clustering(metrics_metrix,n_clusters=n_clusters_)
##绘图
plt.figure(1)
plt.clf()
colors = cycle(‘bgrcmykbgrcmykbgrcmykbgrcmyk’)
for k, col in zip(range(n_clusters_), colors):
##根据lables中的值是否等于k,重新组成一个True、False的数组
my_members = lables == k
##X[my_members, 0] 取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1], col + ‘.’)
plt.title(‘Estimated number of clusters: %d’ % n_clusters_)
plt.show()

e)效果图

图5
5.Hierarchical Clustering
1)概述
Hierarchical Clustering(层次聚类):就是按照某种方法进行层次分类,直到满足某种条件为止。
主要分成两类:
a)凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足。
b)分裂:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。(较少用)
2)算法步骤
a)将每个对象归为一类, 共得到N类, 每类仅包含一个对象. 类与类之间的距离就是它们所包含的对象之间的距离.
b)找到最接近的两个类并合并成一类, 于是总的类数少了一个.
c)重新计算新的类与所有旧类之间的距离.
d)重复第2步和第3步, 直到最后合并成一个类为止(此类包含了N个对象).
3)图解过程
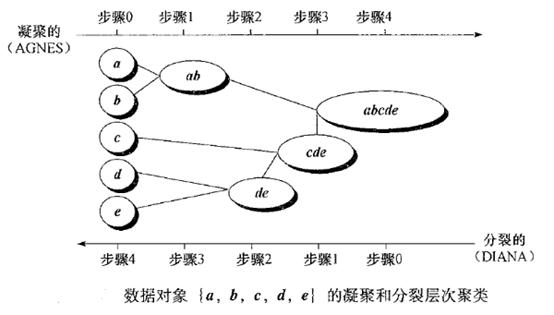
图6
4)Hierarchical Clustering算法函数
a)sklearn.cluster.AgglomerativeClustering
b)主要参数(详细参数)
n_clusters:聚类的个数
linkage:指定层次聚类判断相似度的方法,有以下三种:
ward:组间距离等于两类对象之间的最小距离。(即single-linkage聚类)
average:组间距离等于两组对象之间的平均距离。(average-linkage聚类)
complete:组间距离等于两组对象之间的最大距离。(complete-linkage聚类)
c)主要属性
labels_: 每个数据的分类标签
d)算法示例:代码中有详细讲解内容


from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import AgglomerativeClustering
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle ##python自带的迭代器模块
##产生随机数据的中心
centers = [[1, 1], [-1, -1], [1, -1]]
##产生的数据个数
n_samples=3000
##生产数据
X, lables_true = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.6,
random_state =0)
##设置分层聚类函数
linkages = [‘ward’, ‘average’, ‘complete’]
n_clusters_ = 3
ac = AgglomerativeClustering(linkage=linkages[2],n_clusters = n_clusters_)
##训练数据
ac.fit(X)
##每个数据的分类
lables = ac.labels_
##绘图
plt.figure(1)
plt.clf()
colors = cycle(‘bgrcmykbgrcmykbgrcmykbgrcmyk’)
for k, col in zip(range(n_clusters_), colors):
##根据lables中的值是否等于k,重新组成一个True、False的数组
my_members = lables == k
##X[my_members, 0] 取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1], col + ‘.’)
plt.title(‘Estimated number of clusters: %d’ % n_clusters_)
plt.show()

e)效果图:参数linkage的取值依次为:[‘ward’, ‘average’, ‘complete’]
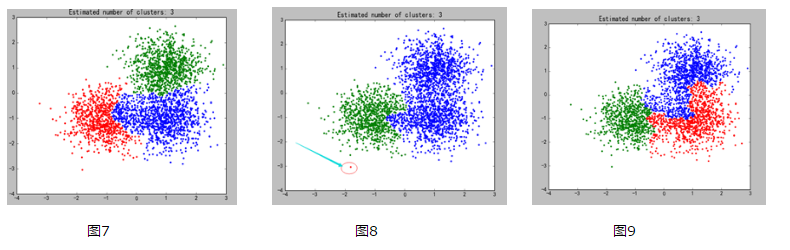
6.DBSCAN
1)概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇(即要求聚类空间中的一定区域内所包含对象的数目不小于某一给定阈值),并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
2) 算法步骤(大致非详细)
DBSCAN需要二个参数:扫描半径 (eps)和最小包含点数(min_samples)
a)遍历所有点,寻找核心点
b)连通核心点,并且在此过程中扩展某个分类集合中点的个数
3)图解过程
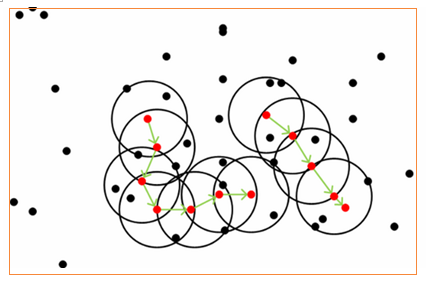
图10
在上图中,第一步就是寻找红色的核心点,第二步就是用绿色箭头联通红色点。图中点以绿色线条为中心被分成了两类。没在黑色圆中的点是噪声点。
4)DBSCAN算法函数
a)sklearn.cluster.DBSCAN
b)主要参数(详细参数)
eps:两个样本之间的最大距离,即扫描半径
min_samples :作为核心点的话邻域(即以其为圆心,eps为半径的圆,含圆上的点)中的最小样本数(包括点本身)。
c)主要属性
core_sample_indices_:核心样本指数。(此参数在代码中有详细的解释)
labels_:数据集中每个点的集合标签给,噪声点标签为-1。
d)算法示例:代码中有详细讲解内容


from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle ##python自带的迭代器模块
from sklearn.preprocessing import StandardScaler
##产生随机数据的中心
centers = [[1, 1], [-1, -1], [1, -1]]
##产生的数据个数
n_samples=750
##生产数据:此实验结果受cluster_std的影响,或者说受eps 和cluster_std差值影响
X, lables_true = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.4,
random_state =0)
##设置分层聚类函数
db = DBSCAN(eps=0.3, min_samples=10)
##训练数据
db.fit(X)
##初始化一个全是False的bool类型的数组
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
‘’’
这里是关键点(针对这行代码:xy = X[class_member_mask & ~core_samples_mask]):
db.core_sample_indices_ 表示的是某个点在寻找核心点集合的过程中暂时被标为噪声点的点(即周围点
小于min_samples),并不是最终的噪声点。在对核心点进行联通的过程中,这部分点会被进行重新归类(即标签
并不会是表示噪声点的-1),也可也这样理解,这些点不适合做核心点,但是会被包含在某个核心点的范围之内
‘’’
core_samples_mask[db.core_sample_indices_] = True
##每个数据的分类
lables = db.labels_
##分类个数:lables中包含-1,表示噪声点
n_clusters_ =len(np.unique(lables)) - (1 if -1 in lables else 0)
##绘图
unique_labels = set(lables)
‘’’
1)np.linspace 返回[0,1]之间的len(unique_labels) 个数
2)plt.cm 一个颜色映射模块
3)生成的每个colors包含4个值,分别是rgba
4)其实这行代码的意思就是生成4个可以和光谱对应的颜色值
‘’’
colors = plt.cm.Spectral(np.linspace(0, 1, len(unique_labels)))
plt.figure(1)
plt.clf()
for k, col in zip(unique_labels, colors):
##-1表示噪声点,这里的k表示黑色
if k == -1:
col = ‘k’
##生成一个True、False数组,lables == k 的设置成True
class_member_mask = (lables == k)
##两个数组做&运算,找出即是核心点又等于分类k的值 markeredgecolor=‘k’,
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], ‘o’, c=col,markersize=14)
‘’’
1)~优先级最高,按位对core_samples_mask 求反,求出的是噪音点的位置
2)& 于运算之后,求出虽然刚开始是噪音点的位置,但是重新归类却属于k的点
3)对核心分类之后进行的扩展
‘’’
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], ‘o’, c=col,markersize=6)
plt.title(‘Estimated number of clusters: %d’ % n_clusters_)
plt.show()

e)效果图
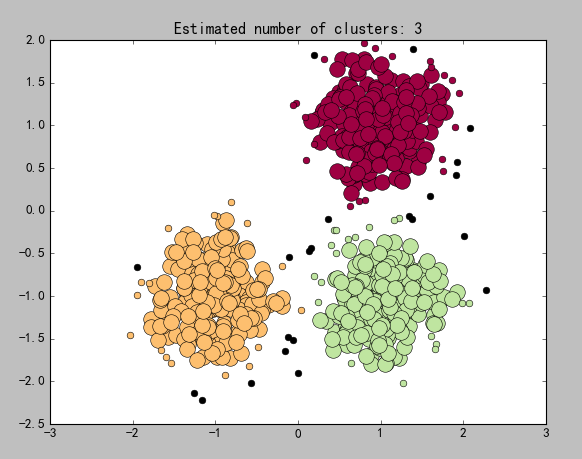
图11
如果不进行第二步中的扩展,所有的小圆点都应该是噪声点(不符合第一步核心点的要求)
5)算法优缺点
a)优点
可以发现任意形状的聚类
b)缺点
随着数据量的增加,对I/O、内存的要求也随之增加。
如果密度分布不均匀,聚类效果较差
7.Birch
1)概述
Birch(利用层次方法的平衡迭代规约和聚类):就是通过聚类特征(CF)形成一个聚类特征树,root层的CF个数就是聚类个数。
2)相关概念:
聚类特征(CF):每一个CF是一个三元组,可以用(N,LS,SS)表示.其中N代表了这个CF中拥有的样本点的数量;LS代表了这个CF中拥有的样本点各特征维度的和向量,SS代表了这个CF中拥有的样本点各特征维度的平方和。
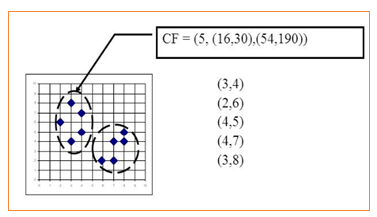
图12
如上图所示:N = 5
LS=(3+2+4+4+3,4+6+5+7+8)=(16,30)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中…(img-PTSQKzYT-1712771044027)]
[外链图片转存中…(img-1cj6LncU-1712771044027)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)


