
热门标签
热门文章
- 1如何使用 GPT 4o API 实现视觉、文本、图像等功能?_gpt4o api
- 2各类远程工具对比
- 3一文读懂Vue开发小程序的技术原理_微信小程序 vuejs
- 4推荐开源项目:JXCategoryView - 灵活高效的分类视图解决方案
- 5基于JAVA(springboot框架)婚纱摄影管理系统 毕业设计开题报告_婚纱影楼管理系统国内外现状
- 6org.springframework.dao.DataRetrievalFailureException数据检索失败的解决方法,亲测有效,已解决,嘿嘿嘿_method threw 'org.springframework.dao.dataretrieva
- 7“文心CV大模型” - VIMER-UFO论文报告
- 8国家开放大学2024年春《教学设计-新疆》第一至十七讲和期末考试参考答案_2024教学设计选择题及答案
- 9Flink: Kafka source & sink_kafka sink和source
- 10【AI落地应用实战】如何让扫描工具更会思考——智能高清滤镜2.0实战测评
当前位置: article > 正文
RLHF强化学习对其算法:PPO、DPO、ORPO_dpo orpo
作者:黑客灵魂 | 2024-07-02 16:42:03
赞
踩
dpo orpo
参考:
https://blog.csdn.net/baoyan2015/article/details/135287298
https://cloud.tencent.com/developer/article/2409553
最新的llama3是PPO、DPO两种方法使用
人类反馈强化学习 (RLHF),它利用人类偏好和指导来训练和改进机器学习模型:
proximal policy optimization (PPO)
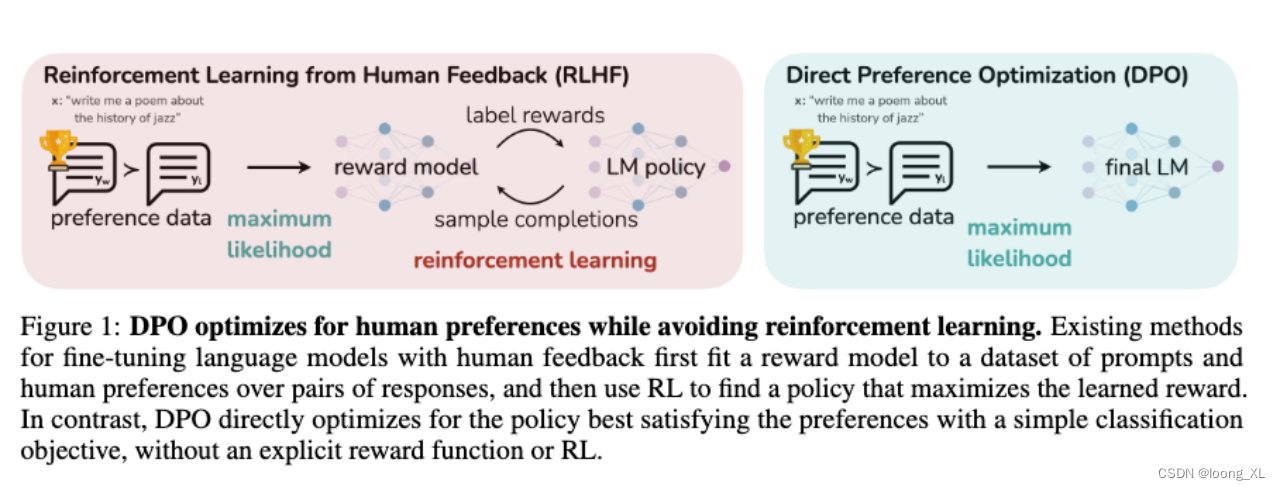
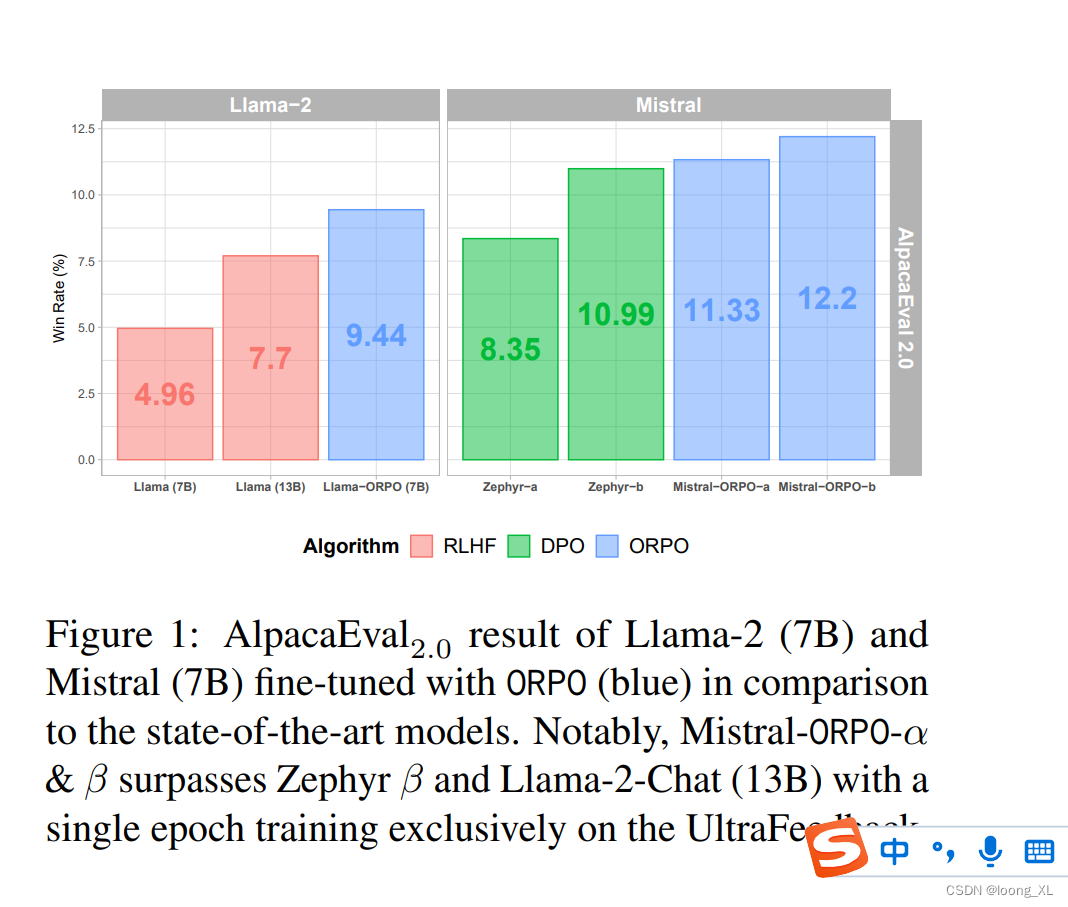
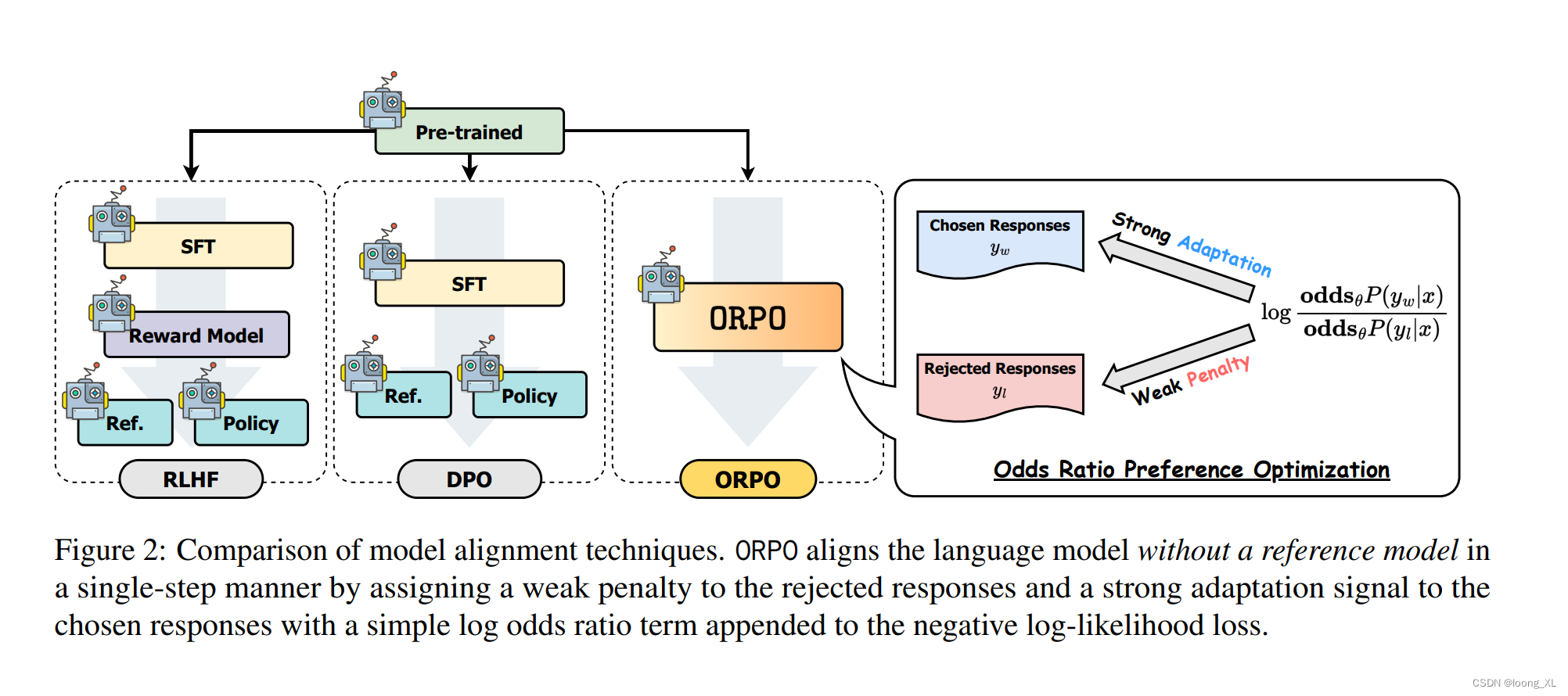
direct policy optimization (DPO)直接偏好优化ORPO(直接相当于合并了监督微调SFT+RLHF)是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。https://medium.com/@zaiinn440/orpo-outperforms-sft-dpo-train-phi-2-with-orpo-3ee6bf18dbf2
PPO、DPO
DPO是一种相对较新的方法,它直接优化用户或专家的偏好,而非传统的累积奖励。PPO(Proximal Policy Optimization)和DPO(Distributed Proximal Policy Optimization)都是基于策略梯度的强化学习算法,它们通过优化策略函数来直接学习一个策略,该策略能够映射观察到的状态到动作的概率分布。
ORPO:
https://arxiv.org/pdf/2403.07691.pdf
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/780243
推荐阅读

相关标签

