
- 1大语言模型(LLM)的进化树,学习LLM看明白这一张图就够了_llm 知识体系
- 2记一次Flink checkpoint超时问题的排查_flink数据库快照一直未完成
- 32021ACL 命名实体识别论文汇总_cross-lingual nested named entities
- 42021年低压电工考试资料及低压电工找答案_一般照明线路中无电的依据是用电笔验电
- 5分类问题中,如果正类样本数比负类样本数多很多,可能会导致什么后果
- 6再过几年,你可能就不用上班了 | 笔记侠AI峰会精编
- 7Nginx配置详细解释:(3)http模块及server模块,location模块_nginx配置server
- 8Kali渗透测试实战指南,不可错过的黑客利器_kali 内网渗透
- 9【Auto.JS】入门宝典—Auto.JS开发使用笔记(随笔和使用心得)
- 10如何在 Kubernetes 上部署一套专属的 LLM
【数值预测案例】(7) CNN-LSTM 混合神经网络气温预测,附TensorFlow完整代码_.一种基于cnn-lstm混合神经网络模型的工艺质量预测方法
赞
踩
大家好,今天和各位分享一下如何使用 Tensorflow 构建 CNN卷积神经网络和 LSTM 循环神经网络相结合的混合神经网络模型,完成对多特征的时间序列预测。
本文预测模型的主要结构由 CNN 和 LSTM 神经网络构成。气温的特征数据具有空间依赖性。本文选择通过在模型前端使用CNN卷积神经网络提取特征之间的空间关系。同时,气温数据又具有明显的时间依赖性,因此在卷积神经网络后添加 LSTM 长短时记忆模型进行时序处理。
1. 获取数据集
数据集自取:https://download.csdn.net/download/dgvv4/49801464
本文使用GPU加速计算,没有GPU的朋友把下面调用GPU的那段代码删了就行。
数据集中后5项特征是气温数据,前三项是时间,选择'actual'列为标签。任务要求,根据连续10天的气温数据,预测5天后的actual气温值
- import tensorflow as tf
- from tensorflow import keras
- from tensorflow.keras import layers
- import pandas as pd
-
- # 调用GPU加速
- gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
- for gpu in gpus:
- tf.config.experimental.set_memory_growth(gpu, True)
-
- # --------------------------------------- #
- #(1)获取数据集
- # --------------------------------------- #
- filepath = 'temps.csv' # 数据集位置
- data = pd.read_csv(filepath)
- print(data.head()) # 查看前五行数据
数据集信息如下:
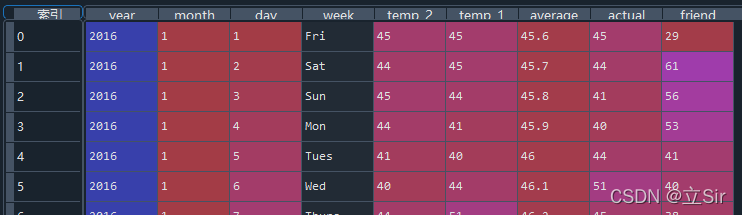
2. 处理时间数据
如上图所示,列表前三列是时间信息,需要将年月日信息组合在一起,从字符串类型转为datetime类型。在选择特征时,时间特征用不上,先把它处理了。
- import datetime # 将时间信息组合成datetime类型的数据
-
- # 获取数据中的年月日信息
- years = data['year']
- months = data['month']
- days = data['day']
-
- dates = [] # 存放组合后的时间信息
-
- # 遍历一一对应的年月日信息
- for year, month, day in zip(years, months, days):
- # 年月日之间使用字符串拼接
- date = str(year) + '-' + str(month) + '-' + str(day)
- # 将每个时间(字符串类型)保存
- dates.append(date)
-
- # 字符串类型的时间转为datetime类型的时间
- times = []
-
- # 遍历所有的字符串类型的时间
- for date in dates:
- # 转为datetime类型
- time = datetime.datetime.strptime(date, '%Y-%m-%d')
- # 逐一保存转变类型后的时间数据
- times.append(time)
-
- # 查看转换后的时间数据
- print(times[:5])
处理后的时间特征如下

3. 特征数据可视化
把每个特征的分布曲线绘制出来,对数据有直观的体会
- import matplotlib.pyplot as plt
- # 指定绘图风格
- plt.style.use('fivethirtyeight')
- # 设置画布,2行2列的画图窗口,第一行画ax1和ax2,第二行画ax3和ax4
- fig, ((ax1,ax2), (ax3,ax4)) = plt.subplots(2, 2, figsize=(20, 10))
-
- # ==1== actual特征列
- ax1.plot(times, data['actual'])
- # 设置x轴y轴标签和title标题
- ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('actual temp')
- # ==2== 前一天的温度
- ax2.plot(times, data['temp_1'])
- # 设置x轴y轴标签和title标题
- ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('temp_1')
- # ==3== 前2天的温度
- ax3.plot(times, data['temp_2'])
- # 设置x轴y轴标签和title标题
- ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('temp_2')
- # ==4== friend
- ax4.plot(times, data['friend'])
- # 设置x轴y轴标签和title标题
- ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('friend')
- # 轻量化布局调整绘图
- plt.tight_layout(pad=2)
- plt.show()
简单绘制一下四个特征随时间的分布情况

4. 数据预处理
首先数据中有一列是分类数据,星期几,需要对这种数据进行one-hot编码,给每一个分类添加一个特征列,如果这一行数据是星期一,那么对应的星期一这列的数值就是1,其他列的数值为0。
然后要选择标签值,预测5天后的气温。标签数据取特征数据中的 'label' 列,并且将这一列集体向上移动5行,那么此时,标签数据中最后的5行会出现空缺值nan。最后5行的特征数据没有对应的标签值,因此需要把最后5行从特征数据和标签数据中删除。
接下来就是对所有的气温数据进行标准化预处理,不要对onehot编码后的星期数据进行标准化。
- # 选择特征, 共6列特征
- feats = data.iloc[:,3:]
- # 对离散的星期几的数据进行onehot编码
- feats = pd.get_dummies(feats)
- # 特征列增加到12项
- print(feats.shape) # (348, 12)
-
- # 选择标签数据,一组时间序列预测5天后的真实气温
- pre_days = 5
- # 选择特征数据中的真实气温'actual'具体向上移动5天的气温信息
- targets = feats['actual'].shift(-pre_days)
- # 查看标签信息
- print(targets.shape) #(348,)
-
- # 由于特征值最后5行对应的标签是空值nan,将最后5行特征及标签删除
- feats = feats[:-pre_days]
- targets = targets[:-pre_days]
- # 查看数据信息
- print('feats.shape:', feats.shape, 'targets.shape:', targets.shape) # (343, 12) (343,)
-
-
- # 特征数据标准化处理
- from sklearn.preprocessing import StandardScaler
- # 接收标准化方法
- scaler = StandardScaler()
- # 对特征数据中所有的数值类型的数据进行标准化
- feats.iloc[:,:5] = scaler.fit_transform(feats.iloc[:,:5])
- # 查看标准化后的信息
- print(feats)
预处理后的数据如下:

5. 时间序列滑窗
这里使用到队列deque,先进先出。指定队列最大长度为10,即时间序列窗口长度为10,根据10天的特征数据预测5天后的气温。如果队列的长度超过10,那么队列会自动将头部的元素删除,将新元素追加到队列的尾部,组成一个新的序列。
对于标签数据,例如range(0,10)天的特征预测第15天的气温,而之前已经将标签值集体向上移动5行,那么第15的度气温标签值对应索引9,即 [max_series_days-1]
- import numpy as np
- from collections import deque # 队列,可在两端增删元素
-
- # 将特征数据从df类型转为numpy类型
- feats = np.array(feats)
-
- # 定义时间序列窗口是连续10天的特征数据
- max_series_days = 10
- # 创建一个队列,队列的最大长度固定为10
- deq = deque(maxlen=max_series_days) # 如果长度超出了10,先从队列头部开始删除
-
- # 创建一个列表,保存处理后的特征序列
- x = []
- # 遍历每一行数据,包含12项特征
- for i in feats:
- # 将每一行数据存入队列中, numpy类型转为list类型
- deq.append(list(i))
- # 如果队列长度等于指定的序列长度,就保存这个序列
- # 如果队列长度大于序列长度,队列会自动删除头端元素,在尾端追加新元素
- if len(deq) == max_series_days:
- # 保存每一组时间序列, 队列类型转为list类型
- x.append(list(deq))
-
- # 保存与特征对应的标签值
- y = targets[max_series_days-1:].values
-
- # 保证序列长度和标签长度相同
- print(len(x)) # 334
- print(len(y)) # 334
-
- # 将list类型转为numpy类型
- x, y = np.array(x), np.array(y)
左图x是一个时间序列滑窗包含的10行特征数据,右图标签y是每一个时间序列滑窗对应一个气温标签值。
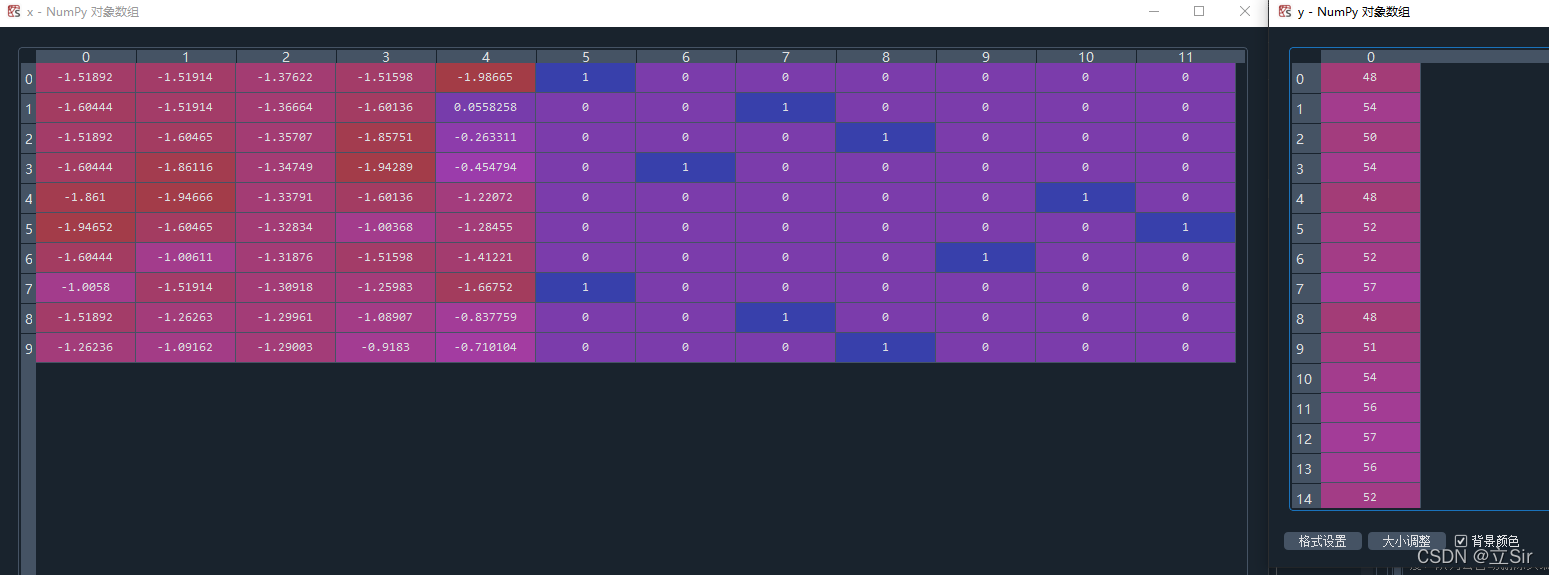
6. 划分数据集
从划分好了的序列中取前80的数据用于训练,剩下20%分别用来验证和测试。对训练数据随机打乱 shuffle() 避免偶然性。构造一个迭代器 iter(),结合 next() 函数从训练集中取出一个batch,查看数据集信息。
- total_num = len(x) # 一共有多少组序列
- train_num = int(total_num*0.8) # 前80%的数据用来训练
- val_num = int(total_num*0.9) # 前80%-90%的数据用来训练验证
- # 剩余数据用来测试
-
- x_train, y_train = x[:train_num], y[:train_num] # 训练集
- x_val, y_val = x[train_num: val_num], y[train_num: val_num] # 验证集
- x_test, y_test = x[val_num:], y[val_num:] # 测试集
-
- # 构造数据集
- batch_size = 128 # 每次迭代处理128个序列
- # 训练集
- train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
- train_ds = train_ds.batch(batch_size).shuffle(10000)
- # 验证集
- val_ds = tf.data.Dataset.from_tensor_slices((x_val, y_val))
- val_ds = val_ds.batch(batch_size)
- # 测试集
- test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test))
- test_ds = test_ds.batch(batch_size)
-
- # 查看数据集信息
- sample = next(iter(train_ds)) # 取出一个batch的数据
- print('x_train.shape:', sample[0].shape) # (128, 10, 12)
- print('y_train.shape:', sample[1].shape) # (128,)
7. 网络构建
输入层的shape为 [None, 10, 12],其中None代表Batch_Size不用写出来,10代表时间序列窗口的大小,12代表数据中的特征个数。
由于这里我使用二维卷积Conv2D,需要在输入数据集中添加通道维度,shape变为 [None, 10, 12, 1] ,和图像处理时类似,使用3*3卷积,步长为1,提取特征
使用池化层下采样,当然也可以使用步长为2的卷积层下采样。下采样时,我选择的池化核大小是[1,2],即只在特征维度上下采样,序列窗口保持不变,下采样方式具体问题具体分析。
在把特征数据从CNN输入至LSTM之前需要调整通道数,融合通道信息,将通道数降为1,然后把通道维挤压掉,shape从四维变为三维,[None,10,6,1]变成[None,10,6]
接下来就是通过LSTM处理数据的时间序列信息,最后经过一个全连接层输出预测结果。全连接层的神经元个数要和标签值的预测个数相同,这里只预测未来某个时间点,神经元个数就是1
- # 输入层要和x_train的shape一致,但注意不要batch维度
- input_shape = sample[0].shape[1:] # [10,12]
-
- # 构造输入层
- inputs = keras.Input(shape=(input_shape)) # [None, 10, 12]
-
- # 调整维度 [None,10,12]==>[None,10,12,1]
- x = layers.Reshape(target_shape=(inputs.shape[1], inputs.shape[2], 1))(inputs)
-
- # 卷积+BN+Relu [None,10,12,1]==>[None,10,12,8]
- x = layers.Conv2D(8, kernel_size=(3,3), strides=1, padding='same', use_bias=False,
- kernel_regularizer=keras.regularizers.l2(0.01))(x)
-
- x = layers.BatchNormalization()(x) # 批标准化
- x = layers.Activation('relu')(x) # relu激活函数
-
- # 池化下采样 [None,10,12,8]==>[None,10,6,8]
- x = layers.MaxPool2D(pool_size=(1,2))(x)
-
- # 1*1卷积调整通道数 [None,10,6,8]==>[None,10,6,1]
- x = layers.Conv2D(1, kernel_size=(3,3), strides=1, padding='same', use_bias=False,
- kernel_regularizer=keras.regularizers.l2(0.01))(x)
-
- # 把最后一个维度挤压掉 [None,10,6,1]==>[None,10,6]
- x = tf.squeeze(x, axis=-1)
-
- # [None,10,6] ==> [None,10,16]
- # 第一个LSTM层, 如果下一层还是LSTM层就需要return_sequences=True, 否则就是False
- x = layers.LSTM(16, activation='relu', kernel_regularizer=keras.regularizers.l2(0.01))(x)
- x = layers.Dropout(0.2)(x) # 随机杀死神经元防止过拟合
-
- # 输出层 [None,16]==>[None,1]
- outputs = layers.Dense(1)(x)
-
- # 构建模型
- model = keras.Model(inputs, outputs)
-
- # 查看模型架构
- model.summary()
网络架构如下:
- Model: "model_12"
- _________________________________________________________________
- Layer (type) Output Shape Param #
- =================================================================
- input_13 (InputLayer) [(None, 10, 12)] 0
- _________________________________________________________________
- reshape_12 (Reshape) (None, 10, 12, 1) 0
- _________________________________________________________________
- conv2d_25 (Conv2D) (None, 10, 12, 8) 72
- _________________________________________________________________
- batch_normalization_13 (Batc (None, 10, 12, 8) 32
- _________________________________________________________________
- activation_13 (Activation) (None, 10, 12, 8) 0
- _________________________________________________________________
- max_pooling2d_13 (MaxPooling (None, 10, 6, 8) 0
- _________________________________________________________________
- conv2d_26 (Conv2D) (None, 10, 6, 1) 72
- _________________________________________________________________
- tf.compat.v1.squeeze_12 (TFO (None, 10, 6) 0
- _________________________________________________________________
- lstm_11 (LSTM) (None, 16) 1472
- _________________________________________________________________
- dropout_14 (Dropout) (None, 16) 0
- _________________________________________________________________
- dense_13 (Dense) (None, 1) 17
- =================================================================
- Total params: 1,665
- Trainable params: 1,649
- Non-trainable params: 16
- _________________________________________________________________
8. 模型训练
使用回归计算的预测值和真实值之间的平均绝对误差作为损失函数,使用预测值和真实值之间的对数均方误差作为训练时的监控指标
- # 网络编译
- model.compile(optimizer = keras.optimizers.Adam(0.001), # adam优化器学习率0.001
- loss = tf.keras.losses.MeanAbsoluteError(), # 标签和预测之间绝对差异的平均值
- metrics = tf.keras.losses.MeanSquaredLogarithmicError()) # 计算标签和预测之间的对数误差均方值。
-
- epochs = 300 # 迭代300次
-
- # 网络训练, history保存训练时的信息
- history = model.fit(train_ds, epochs=epochs, validation_data=val_ds)
由于history中记录了网络训练时,每次迭代包含的损失信息和指标信息,将它们可视化出来
- history_dict = history.history # 获取训练的数据字典
- train_loss = history_dict['loss'] # 训练集损失
- val_loss = history_dict['val_loss'] # 验证集损失
- train_msle = history_dict['mean_squared_logarithmic_error'] # 训练集的百分比误差
- val_msle = history_dict['val_mean_squared_logarithmic_error'] # 验证集的百分比误差
-
- #(11)绘制训练损失和验证损失
- plt.figure()
- plt.plot(range(epochs), train_loss, label='train_loss') # 训练集损失
- plt.plot(range(epochs), val_loss, label='val_loss') # 验证集损失
- plt.legend() # 显示标签
- plt.xlabel('epochs')
- plt.ylabel('loss')
- plt.show()
-
- #(12)绘制训练百分比误差和验证百分比误差
- plt.figure()
- plt.plot(range(epochs), train_msle, label='train_msle') # 训练集指标
- plt.plot(range(epochs), val_msle, label='val_msle') # 验证集指标
- plt.legend() # 显示标签
- plt.xlabel('epochs')
- plt.ylabel('msle')
- plt.show()
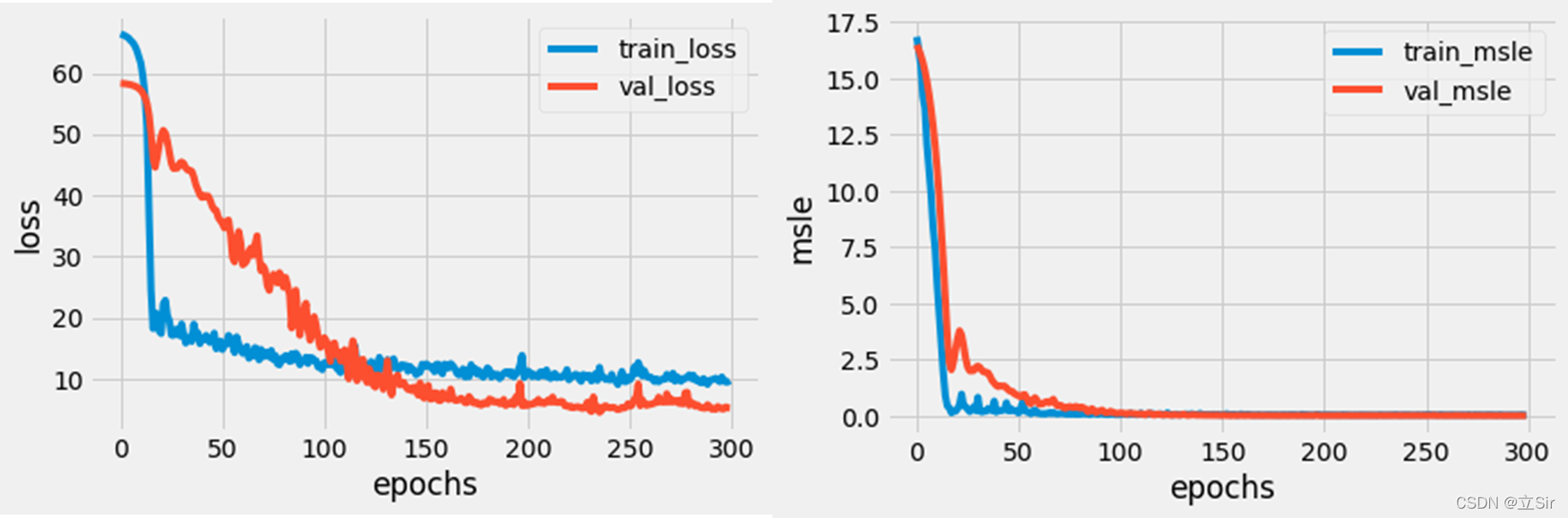
9. 预测阶段
首先使用 evaluate() 对整个测试集计算损失和监控指标,使用 predict() 函数通过测试集的特征值计算预测气温。然后绘制预测值和真实值的对比曲线。
- # 对整个测试集评估
- model.evaluate(test_ds)
-
- # 预测
- y_pred = model.predict(x_test)
-
- # 获取标签值对应的时间
- df_time = times[-len(y_test):]
-
- # 绘制对比曲线
- fig = plt.figure(figsize=(10,5)) # 画板大小
- ax = fig.add_subplot(111) # 画板上添加一张图
- # 绘制真实值曲线
- ax.plot(df_time, y_test, 'b-', label='actual')
- # 绘制预测值曲线
- ax.plot(df_time, y_pred, 'r--', label='predict')
- # 设置x轴刻度
- ax.set_xticks(df_time[::7])
-
- # 设置xy轴标签和title标题
- ax.set_xlabel('Date')
- ax.set_ylabel('Temperature');
- ax.set_title('result')
- plt.legend()
- plt.show()
预测曲线和真实曲线对比如下


