
- 1数据实时传输平台(CDC)与低代码平台(APAAS)数据集成_cdc平台
- 2ZYNQ petalinux系统使用axi_bram进行PL与PS数据交互_ps和pl通过bram批量数据读写
- 3课工场题库自动化脚本原理分析及实现(文章末尾附免费可用版本)_免费脚本题库配置链接
- 4IOS - swift SDK开发_制作 swift sdk
- 5AI产品经理入门全指南资料库_ai产品经理知识库
- 6Phoenix启动过程出现的问题_phoenix启动后没有master
- 7将句子表示为向量:无监督句子表示学习(sentence embedding)
- 8Fine-tuning: 深度解析P-tuning v2在大模型上的应用_ptuning v2原理
- 9Git笔记-Connection reset by 13.229.188.59 port 22 fatal: Could not read from remote repository._connection reset by 180.76.198.77 port 22 fatal: c
- 1010张图看AI趋势:到2025年全球AI企业营收增幅53%_ai产业对gdp的贡献率 图表
深夜震撼发布,一文速览 Llama3_llama3 运行环境
赞
踩
导语
2024年4月18日,Meta AI 正式宣布推出 Llama 3,这标志着开源大型语言模型(LLM)领域的又一重大进步。如同一颗重磅炸弹, Llama 3 以其卓越的性能和广泛的应用前景,预示着 AI 技术的新时代。
模型性能
Llama3 由 Meta 最新公布的自建 24K GPU 集群上训练,使用超过 15T 的数据令牌,训练数据集是 Llama 2 的 7 倍,包括 4 倍的代码数据。
在上下文方面, Llama 3支持 8K 的上下文长度,是 Llama 2 容量的两倍,极大地提高了处理多步骤任务的能力。同时,该模型特别强调在理解、代码生成和指令跟随等复杂任务上的改进性能。
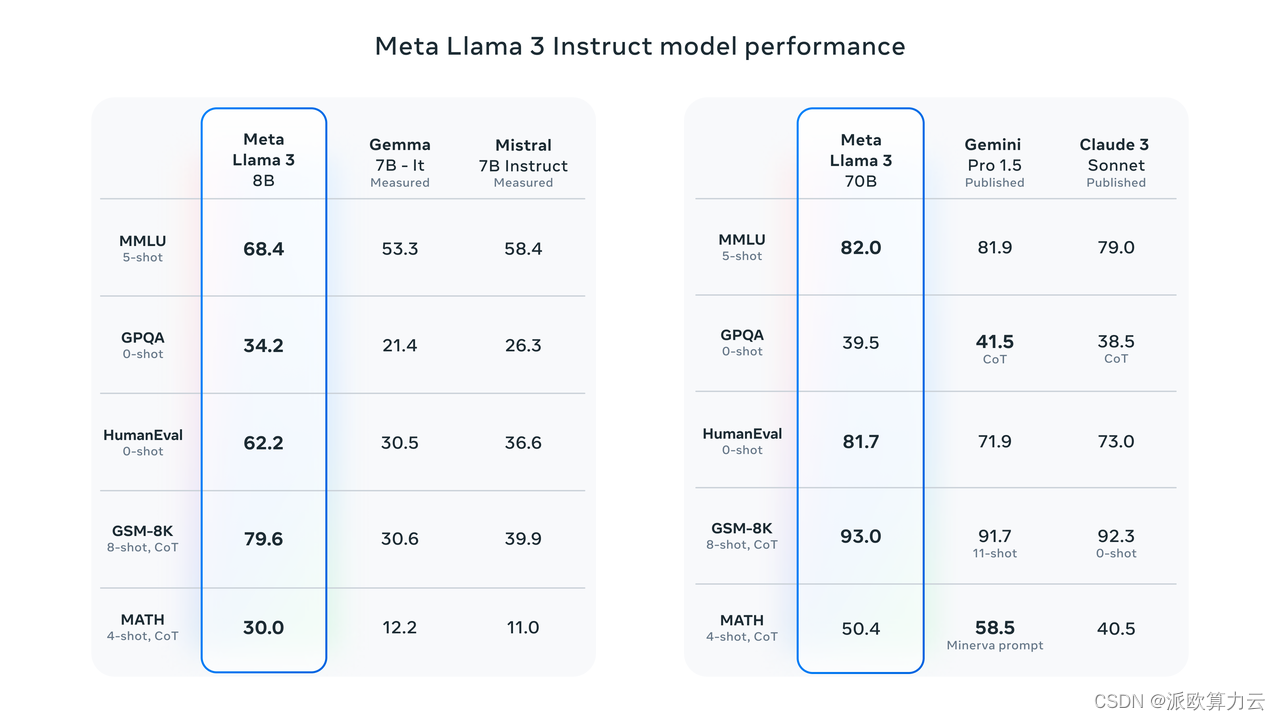
Llama3 8B 和 70B 参数的模型在多个行业基准测试中展示了最先进的性能,特别是在推理和编码任务上。
后期训练程序的改进大大降低了错误拒绝率,提高了对齐度,并增加了模型响应的多样性。
推理、代码生成和指令跟踪等能力也有了很大提高,这使得 Llama 3 的可操控性更强。
模型架构
Llama 3 选择了相对标准的 Transformer 架构。
与 Llama 2 相比,有几个关键的改进。
Llama 3 使用了一个 128K 词库的标记化器,它能更有效地编码语言,从而大幅提高模型性能。
为了提高 Llama 3 模型的推理效率,Meta 采用了高效的分词器和分组查询注意力(GQA),以及在大量公开数据上的预训练,使得 Llama 3 在保持参数规模的同时,显著提升了模型性能。
同时,Meta 在 8192 个标记的序列上训练模型,使用掩码来确保自我注意力不会跨越文档边界。
训练数据
训练数据方面,Llama 3 在超过 15T 的词库上进行了预训练,这些词库都是从公开来源收集
训练数据集是 Llama 2 的七倍,包含的代码数量也是 Llama 2 的四倍。
同时,为了应对多语言使用情况,Llama 3 的预训练数据集中有超过 5% 的高质量非英语数据,涵盖 30 多种语言。
Meta 开发了一系列数据过滤管道。这些管道包括使用启发式过滤器、NSFW 过滤器、语义重复数据删除方法和文本分类器来预测数据质量。
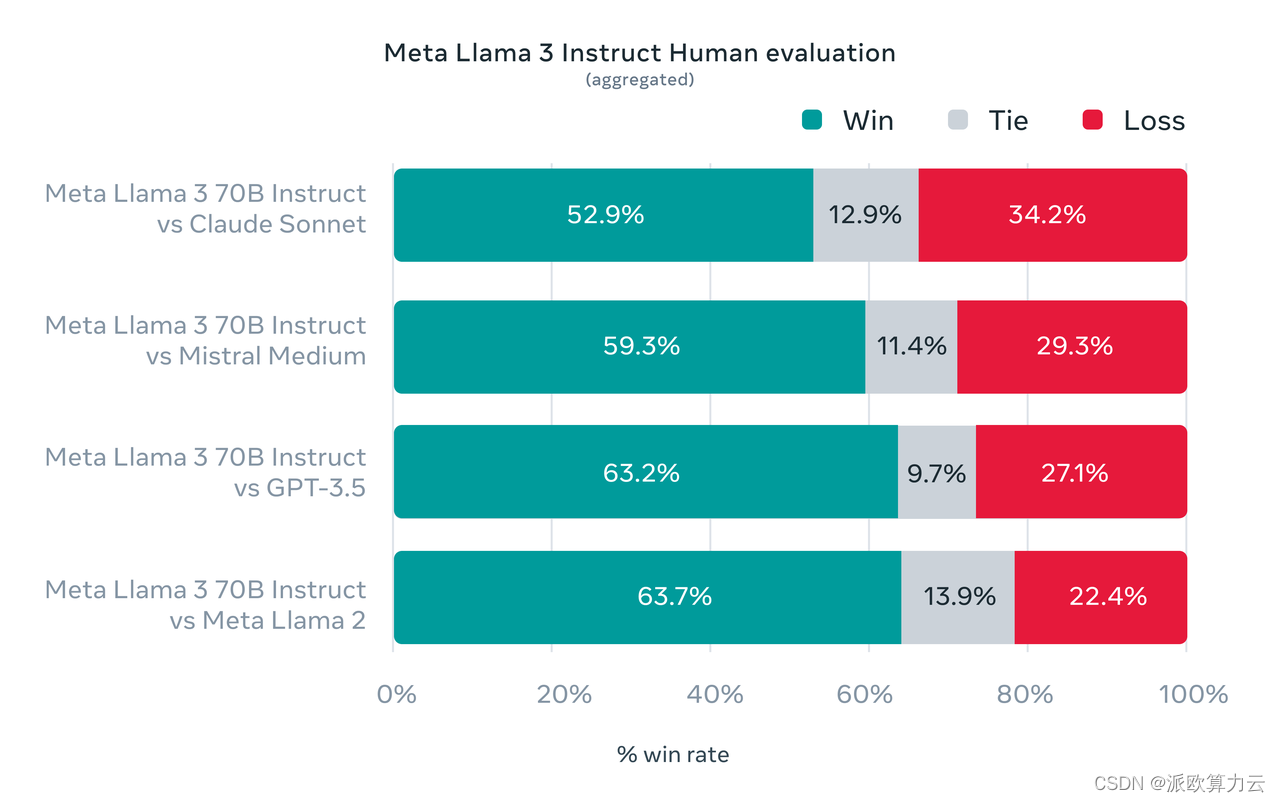
为了寻求在真实世界中的优化, Meta 开发了一个新的高质量的人类评估集。该评估集包含1,800个提示,涵盖12个关键用例:征求建议,头脑风暴,分类,封闭式问题回答,编码,创意写作,提取,居住在角色/人物,开放式问题回答,推理,重写和总结。
如何使用
根据 Meta 官方透露,Llama 3 模型将很快在 AWS、Google Cloud、Hugging Face、Azure 等平台上提供,并得到 AMD、AWS、戴尔、英特尔、NVIDIA 和高通提供的硬件平台的支持。
派欧算力云即将推出 Llama3 预置镜像, 一键运行部署开发环境。节省配置时间,提升开发效率,让您能够快速开始体验,敬请期待!


