
- 1【darknet-yolo系列】yolov4 训练模型操作流程(包含所有资源下载)_yolov4模型训练
- 2使用swift语言编写iOS应用_swift开发ios应用
- 3用c++编写简单的加减乘除_应用指针,编写程序,完成负数的加、减运算。
- 4最新计算机专业开题报告案例14:个性化图书推荐系统的设计与实现
- 5Python中的逻辑运算符“与“和“或“的运算结果的返回类型以及“短路“现象_python的逻辑与
- 6message_filters_ros 消息 过滤
- 7万宾科技可燃气体监测仪,预防闪爆事故
- 8C++图书管理系统,数据结构课程设计(含源码、报告)_c++图书管理系统课程设计报告
- 9完全免费的PDF软件
- 10moondream-开创性的小型视觉语言模型
ACL 2021 | 一文详解美团技术团队7篇精选论文
赞
踩

ACL是计算语言学和自然语言处理领域最重要的顶级国际会议,该会议由国际计算语言学协会组织,每年举办一次。据谷歌学术计算语言学刊物指标显示,ACL影响力位列第一,是CCF-A类推荐会议。美团技术团队共有7篇论文(其中6篇长文,1篇短文)被ACL 2021接收,这些论文是美团技术团队在事件抽取、实体识别、意图识别、新槽位发现、无监督句子表示、语义解析、文档检索等自然语言处理任务上的一些前沿探索及应用。
01 Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder
02 Slot Transferability for Cross-domain Slot Filling
03 Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
04 Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Task-Oriented Dialogue System
05 ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
06 From Paraphrasing to Semantic Parsing: Unsupervised Semantic Parsing via Synchronous Semantic Decoding
07 Improving Document Representations by Generating Pseudo Query Embeddings for Dense Retrieval
计算语言学协会年会(ACL 2021)于2021年8月1日至6日在泰国曼谷举办(虚拟线上会议)。ACL是计算语言学和自然语言处理领域最重要的顶级国际会议,该会议由国际计算语言学协会组织,每年举办一次。据谷歌学术计算语言学刊物指标显示,ACL影响力位列第一,是CCF-A类推荐会议。今年ACL的主题是“NLP for Social Good”。据官方统计信息,本次会议共收到3350篇有效投稿,共计接收710篇主会论文(接受率为21.3%),493篇Findings论文(接受率为14.9%)。
美团技术团队共有7篇论文(其中6篇长文,1篇短文)被ACL 2021接收,这些论文是美团在事件抽取、实体识别、意图识别、新槽位发现、无监督句子表示、语义解析、文档检索等自然语言处理任务上的一些技术沉淀和应用。
针对于事件抽取,我们显示地利用周边实体的语义级别的论元角色信息,提出了一个双向实体级解码器(BERD)来逐步对每个实体生成论元角色序列;针对于实体识别,我们首次提出了槽间可迁移度的概念,并为此提出了一种槽间可迁移度的计算方式,通过比较目标槽与源任务槽的可迁移度,为不同的目标槽寻找相应的源任务槽作为其源槽,只基于这些源槽的训练数据来为目标槽构建槽填充模型;针对于意图识别,我们提出了一种基于监督对比学习的意图特征学习方法,通过最大化类间距离和最小化类内方差来提升意图之间的区分度;针对于新槽位发现,我们首次定义了新槽位识别(Novel Slot Detection, NSD)任务,与传统槽位识别任务不同的是,新槽位识别任务试图基于已有的域内槽位标注数据去挖掘发现真实对话数据里存在的新槽位,进而不断地完善和增强对话系统的能力。
此外,为解决BERT原生句子表示的“坍缩”现象,我们提出了基于对比学习的句子表示迁移方法—ConSERT,通过在目标领域的无监督语料上Fine-Tune,使模型生成的句子表示与下游任务的数据分布更加适配。我们还提出了一种新的无监督的语义解析方法——同步语义解码(SSD),它可以联合运用复述和语法约束解码同时解决语义鸿沟与结构鸿沟的问题。我们还从改进文档的编码入手来提高文档编码的语义表示能力,既提高了效果也提高了检索效率。
接下来,我们将对这7篇学术论文做一个更加详细的介绍,希望能对那些从事相关研究的同学有所帮助或启发,也欢迎大家在文末评论区留言,一起交流。
01 Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder
论文下载
论文作者:习翔宇,叶蔚(北京大学),张通(北京大学),张世琨(北京大学),王全修(RICHAI),江会星,武威
论文类型:Main Conference Long Paper(Oral)
事件抽取是信息抽取领域一个重要且富有挑战性的任务,在自动文摘、自动问答、信息检索、知识图谱构建等领域有着广泛的应用,旨在从非结构化的文本中抽取出结构化的事件信息。事件论元抽取对具体事件的描述信息(称之为论元信息)进行抽取,包括事件参与者、事件属性等信息,是事件抽取中重要且难度极大的任务。绝大部分论元抽取方法通常将论元抽取建模为针对实体和相关事件的论元角色分类任务,并且针对一个句子中实体集合的每个实体进行分离地训练与测试,忽略了候选论元之间潜在的交互关系;而部分利用了论元交互信息的方法,都未充分利用周边实体的语义级别的论元角色信息,同时忽略了在特定事件中的多论元分布模式。
针对目前事件论元检测中存在的问题,本文提出显示地利用周边实体的语义级别的论元角色信息。为此,本文首先将论元检测建模为实体级别的解码问题,给定句子和已知事件,论元检测模型需要生成论元角色序列;同时与传统的词级别的Seq2Seq模型不同,本文提出了一个双向实体级解码器(BERD)来逐步对每个实体生成论元角色序列。具体来说,本文设计了实体级别的解码循环单元,能够同时利用当前实例信息和周边论元信息;并同时采用了前向和后向解码器,能够分别从左往右和从右往左地对当前实体进行预测,并在单向解码过程中利用到左侧/右侧的论元信息;最终,本文在两个方向解码完成之后,采用了一个分类器结合双向编码器的特征来进行最终预测,从而能够同时利用左右两侧的论元信息。
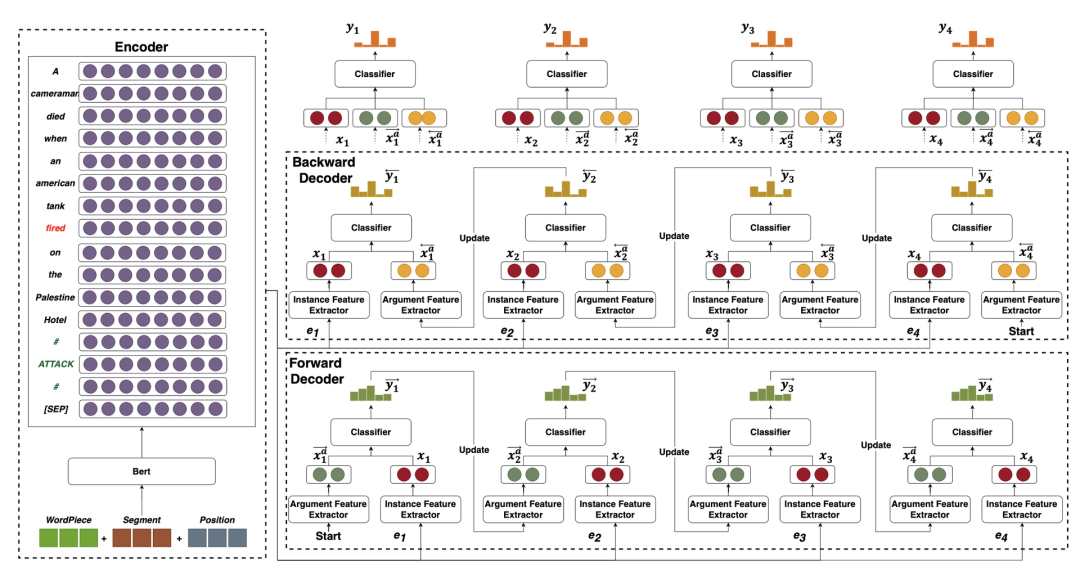
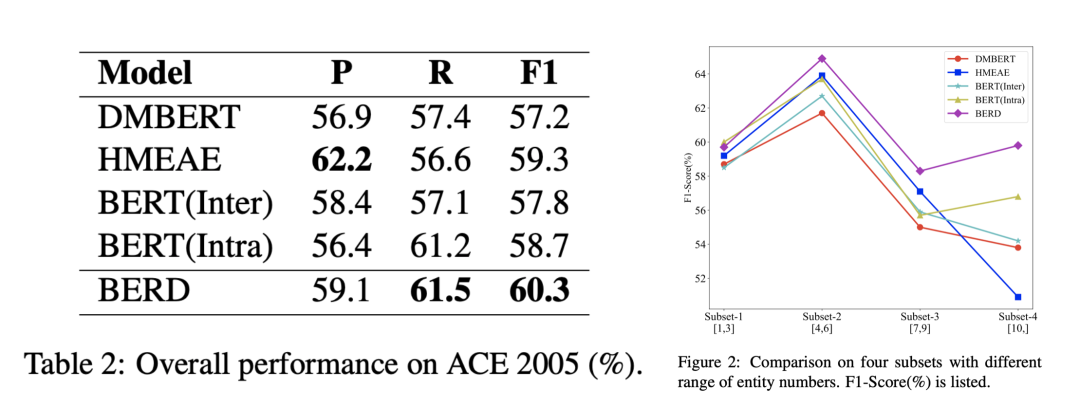
本文在公开数据集ACE 2005上进行了实验,并与多种已有模型以及最新的论元交互方法进行对比。实验结果表明该方法性能优于现有的论元交互方法,同时在实体数量较多的事件中提升效果更加显著。
02 Slot Transferability for Cross-domain Slot Filling
论文下载
论文作者:陆恒通(北京邮电大学),韩卓芯(北京邮电大学),袁彩霞(北京邮电大学),王小捷(北京邮电大学),雷书彧,江会星,武威
论文类型:Findings of ACL 2021, Long Paper
槽填充旨在识别用户话语中任务相关的槽信息,是任务型对话系统的关键部分。当某个任务(或称为领域)具有较多训练数据时,已有的槽填充模型可以获得较好的识别性能。但是,对于一个新任务,往往只有很少甚至没有槽标注语料,如何利用一个或多个已有任务(源任务)的标注语料来训练新任务(目标任务)中的槽填充模型,这对于任务型对话系统应用的快速扩展有着重要的意义。
针对该问题的现有研究主要分为两种,第一种通过建立源任务槽信息表示与目标任务槽信息表示之间的隐式语义对齐,来将用源任务数据训练的模型直接用于目标任务,这些方法将槽描述、槽值样本等包含槽信息的内容与词表示以一定方式进行交互得到槽相关的词表示,之后进行基于“BIO”的槽标注。第二种思路采用两阶段策略进行,将所有槽值看作实体,首先用源任务数据训练一个通用实体识别模型识别目标任务所有候选槽值,之后将候选槽值通过与目标任务槽信息的表示进行相似度对比来分类到目标任务的槽上。
现有的工作,大多关注于构建利用源-目标任务之间关联信息的跨任务迁移模型,模型构建时一般使用所有源任务的数据。但是,实际上,并不是所有的源任务数据都会对目标任务的槽识别具有可迁移的价值,或者不同源任务数据对于特定目标任务的价值可能是很不相同的。例如:机票预定任务和火车票预定任务相似度高,前者的槽填充训练数据会对后者具有帮助,而机票预定任务和天气查询任务则差异较大,前者的训练数据对后者没有或只具有很小的借鉴价值,甚至起到干扰作用。
再进一步,即使源任务和目标任务很相似,但是并不是每个源任务的槽的训练数据都会对目标任务的所有槽都有帮助,例如,机票预定任务的出发时间槽训练数据可能对火车票预定任务的出发时间槽填充有帮助,但是对火车类型槽就没有帮助,反而起到干扰作用。因此,我们希望可以为目标任务中的每一个槽找到能提供有效迁移信息的一个或多个源任务槽,基于这些槽的训练数据构建跨任务迁移模型,可以更为有效地利用源任务数据。
为此,我们首先提出了槽间可迁移度的概念,并为此提出了一种槽间可迁移度的计算方式,基于可迁移度的计算,我们提出了一种为目标任务选择出源任务中能够提供有效迁移信息的槽的方法。通过比较目标槽与源任务槽的可迁移度,为不同的目标槽寻找相应的源任务槽作为其源槽,只基于这些源槽的训练数据来为目标槽构建槽填充模型。具体来说,可迁移度融合了目标槽和源槽之间的槽值表示分布相似度,以及槽值上下文表示分布相似度作为两个槽之间的可迁移度,然后对源任务槽依据其与目标槽之间的可迁移度高低进行排序,用可迁移度最高的槽所对应训练语料训练一个槽填充模型,得到其在目标槽验证集上的性能,依据按照可迁移度排序加入新的源任务槽对应训练语料训练模型并得到对应的验证集性能,选取性能最高的点对应的源任务槽及可迁移度高于该槽的源任务槽作为其源槽。利用选择出来的源槽构建目标槽槽填充模型。
槽填充模型依据槽值信息及槽值的上下文信息对槽值进行识别,所以我们在计算槽间可迁移度时,首先对槽值表示分布与上下文表示分布上的相似性进行了度量,然后我们借鉴了F值对于准确率及召回率的融合方式,对槽值表示分布相似性及槽值上下文表示分布相似性进行了融合,最后利用Tanh将所得到的值归一化到0-1之间,再用1减去所得到的值,为了符合计算得到的值越大,可迁移度越高的直观认知。下式是我们所提出的槽间可迁移度的计算方式:
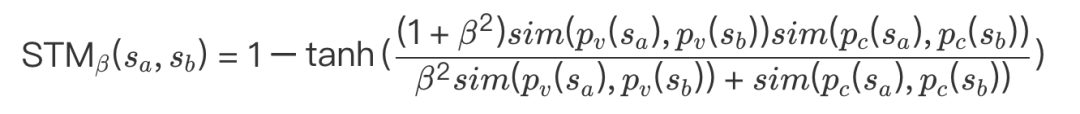
和 分别表示槽a与槽b在槽值表示分布与上下文表示分布上的相似性,我们采用最大均值差异(MMD)来衡量分布之间的相似度。
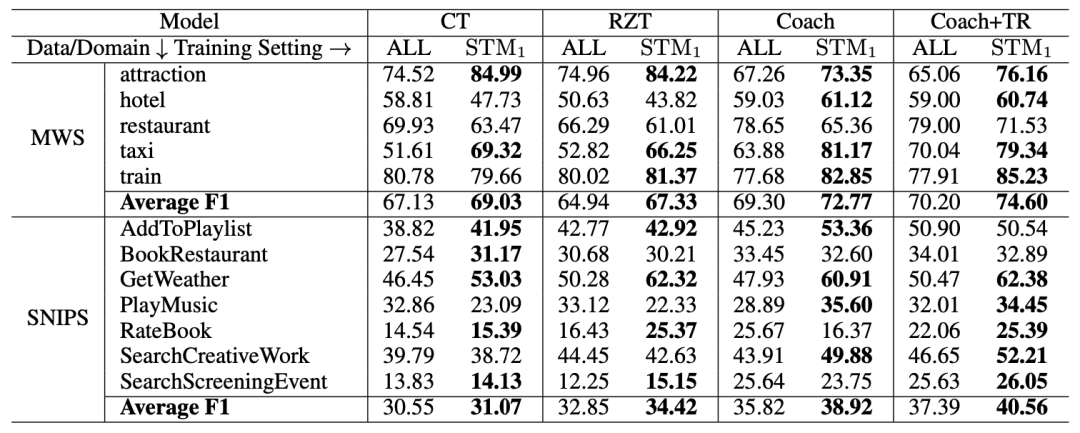
我们并没有提出新的模型,但是我们提出的源槽选择方法可以与所有的已知模型进行结合,在多个已有模型及数据集上的实验表明,我们提出的方法能为目标任务槽填充模型带来一致性的性能提升(ALL所在列表示已有模型原始的性能,STM1所在列表示用我们的方法选出的数据训练的模型性能。)
03 Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
论文下载
论文作者:曾致远(北京邮电大学),何可清,严渊蒙(北京邮电大学),刘子君(北京邮电大学),吴亚楠(北京邮电大学),徐红(北京邮电大学),江会星,徐蔚然(北京邮电大学)
论文类型:Main Conference Short Paper (Poster)
在实际的任务型对话系统中,异常意图检测(Out-of-Domain Detection)是一个关键的环节,其负责识别用户输入的异常查询,并给出拒识的回复。与传统的意图识别任务相比,异常意图检测面临着语义空间稀疏、标注数据匮乏的难题。现有的异常意图检测方法可以分为两类:一类是有监督的异常意图检测,是指训练过程中存在有监督的OOD意图数据,此类方法的优势是检测效果较好,但缺点是依赖于大量有标注的OOD数据,这在实际中并不可行。另一类是无监督的异常意图检测,是指仅仅利用域内的意图数据去识别域外意图样本,由于无法利用有标注OOD样本的先验知识,无监督的异常意图检测方法面临着更大的挑战。因此,本文主要是研究无监督的异常意图检测。
无监督异常意图检测的一个核心问题是,如何通过域内意图数据学习有区分度的语义表征,我们希望同一个意图类别下的样本表征互相接近,同时不同意图类别下的样本互相远离。基于此,本文提出了一种基于监督对比学习的意图特征学习方法,通过最大化类间距离和最小化类内方差来提升特征的区分度。
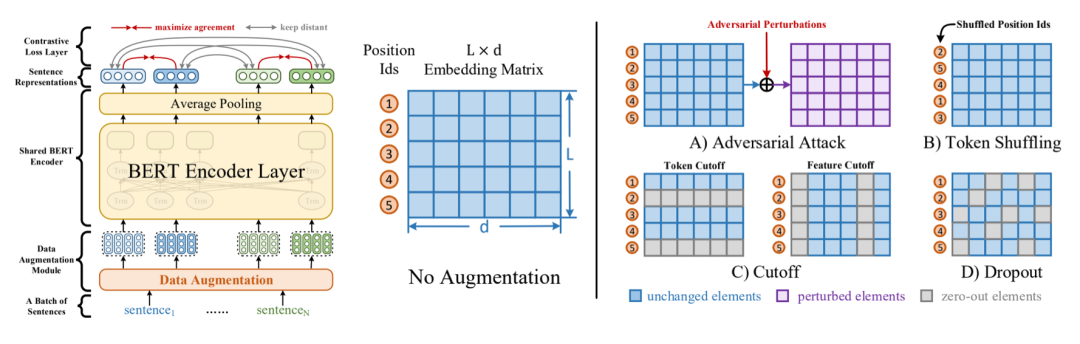
具体来说,我们使用一个BiLSTM/BERT的上下文编码器获取域内意图表示,然后针对意图表示使用了两种不同的目标函数:一种是传统的分类交叉熵损失,另一种是监督对比学习(Supervised Contrastive Learning)损失。监督对比学习是在对比学习的基础上,改进了原始的对比学习仅有一个Positive Anchor的缺点,使用同类样本互相作为正样本,不同类样本作为负样本,最大化正样本之间的相关性。同时,为了提高样本表示的多样性,我们使用对抗攻击的方法来进行虚拟数据增强(Adversarial Augmentation),通过给隐空间增加噪声的方式来达到类似字符替换、插入删除、回译等传统数据增强的效果。模型结构如下:

我们在两个公开的数据集上验证模型的效果,实验结果表明我们提出的方法可以有效的提升无监督异常意图检测的性能,如下表所示。

04 Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Task-Oriented Dialogue System
论文下载
论文作者:吴亚楠(北京邮电大学),曾致远(北京邮电大学),何可清,徐红(北京邮电大学),严渊蒙(北京邮电大学),江会星,徐蔚然(北京邮电大学)
论文类型:Main Conference Long Paper (Oral)
槽填充(Slot Filling)是对话系统中一个重要的模块,负责识别用户输入中的关键信息。现有的槽填充模型只能识别预先定义好的槽类型,但是实际应用里存在大量域外实体类型,这些未识别的实体类型对于对话系统的优化至关重要。
在本文中,我们首次定义了新槽位识别(Novel Slot Detection, NSD)任务,与传统槽位识别任务不同的是,新槽位识别任务试图基于已有的域内槽位标注数据去挖掘发现真实对话数据里存在的新槽位,进而不断地完善和增强对话系统的能力,如下图所示:

对比现有的OOV识别任务和域外意图检测任务,本文提出的NSD任务具有显著的差异性:一方面,与OOV识别任务相比,OOV识别的对象是训练集中未出现过的新槽值,但这些槽值所属的实体类型是固定的,而NSD任务不仅要处理OOV的问题,更严峻的挑战是缺乏未知实体类型的先验知识,仅仅依赖域内槽位信息来推理域外实体信息;另一方面,和域外意图检测任务相比,域外意图检测仅需识别句子级别的意图信息,而NSD任务则面临着域内实体和域外实体之间上下文的影响,以及非实体词对于新槽位的干扰。整体上来看,本文提出的新槽位识别(Novel Slot Detection, NSD)任务与传统的槽填充任务、OOV识别任务以及域外意图检测任务有很大的差异,并且面临着更多的挑战,同时也给对话系统未来的发展提供了一个值得思考和研究的方向。
基于现有的槽填充公开数据集ATIS和Snips,我们构建了两个新槽位识别数据集ATIS-NSD和Snips-NSD。具体来说,我们随机抽取训练集中部分的槽位类型作为域外类别,保留其余类型作为域内类别,针对于一个句子中同时出现域外类别和域内类别的样例,我们采用了直接删除整个样本的策略,以避免O标签引入的bias,保证域外实体的信息仅仅出现在测试集中,更加的贴近实际场景。同时,我们针对于NSD任务提出了一系列的基线模型,整体的框架如下图所示。模型包含两个阶段:
训练阶段:基于域内的槽标注数据,我们训练一个BERT-based的序列标注模型(多分类或者是二分类),以获取实体表征。
测试阶段:首先使用训练的序列标注模型进行域内实体类型的预测,同时基于得到的实体表征,使用MSP或者GDA算法预测一个词是否属于Novel Slot,也即域外类型,最后将两种输出结果进行合并得到最终的输出。

我们使用实体识别的F1作为评价指标,包括Span-F1和Token-F1,二者的区别在于是否考虑实体边界,实验结果如下:
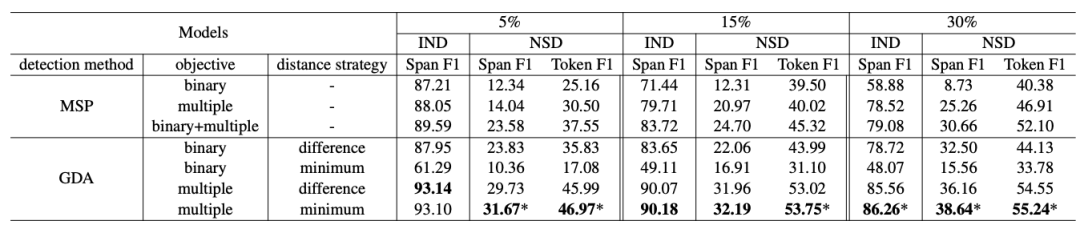
我们通过大量的实验和分析来探讨新槽位识别面临的挑战:1. 非实体词与新实体之间混淆;2. 不充分的上下文信息;3. 槽位之间的依赖关系;4. 开放槽(Open Vocabulary Slots)。
05 ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
论文下载
论文作者:严渊蒙,李如寐,王思睿,张富峥,武威,徐蔚然(北京邮电大学)
论文类型:Main Conference Long Paper (Poster)
句向量表示学习在自然语言处理(NLP)领域占据重要地位,许多NLP任务的成功离不开训练优质的句子表示向量。特别是在文本语义匹配(Semantic Textual Similarity)、文本向量检索(Dense Text Retrieval)等任务上,模型通过计算两个句子编码后的embedding在表示空间的相似度来衡量这两个句子语义上的相关程度,从而决定其匹配分数。尽管基于BERT的模型在诸多NLP任务上取得了不错的性能(通过有监督的Fine-Tune),但其自身导出的句向量(不经过Fine-Tune,对所有词向量求平均)质量较低,甚至比不上Glove的结果,因而难以反映出两个句子的语义相似度。
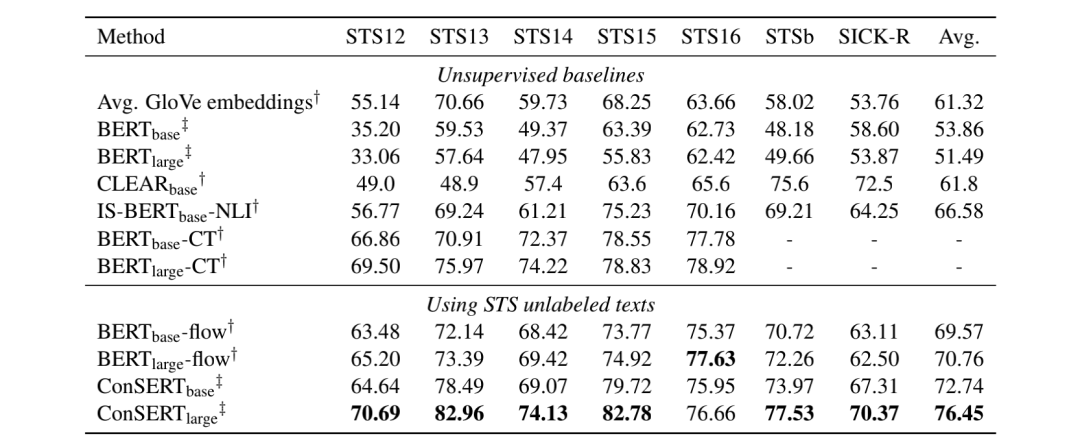
为解决BERT原生句子表示这种“坍缩”现象,本文提出了基于对比学习的句子表示迁移方法—ConSERT,通过在目标领域的无监督语料上fine-tune,使模型生成的句子表示与下游任务的数据分布更加适配。同时,本文针对NLP任务提出了对抗攻击、打乱词序、裁剪、Dropout四种不同的数据增强方法。在句子语义匹配(STS)任务的实验结果显示,同等设置下ConSERT 相比此前的 SOTA (BERT-Flow)大幅提升了8%,并且在少样本场景下仍表现出较强的性能提升。
在无监督实验中,我们直接基于预训练的BERT在无标注的STS数据上进行Fine-Tune。结果显示,我们的方法在完全一致的设置下大幅度超过之前的SOTA—BERT-Flow,达到了8%的相对性能提升。
06 From Paraphrasing to Semantic Parsing: Unsupervised Semantic Parsing via Synchronous Semantic Decoding
论文下载
论文作者:吴杉(中科院软件所),陈波(中科院软件所),辛春蕾(中科院软件所),韩先培(中科院软件所),孙乐(中科院软件所),张伟鹏,陈见耸,杨帆,蔡勋梁
论文类型:Main Conference Long Paper
语义解析(Semantic Parsing)是自然语言处理中的核心任务之一,它的目标是把自然语言转换为计算机语言,从而使得计算机真正理解自然语言。目前语义解析面临的一大挑战是标注数据的缺乏。神经网络方法大都十分依赖监督数据,而语义解析的数据标注非常费时费力。因此,如何在无监督的情况下学习语义解析模型成为非常重要的问题,同时也是有挑战性的问题,它的挑战在于,语义解析需要在无标注数据的情况下,同时跨越自然语言和语义表示间的语义鸿沟和结构鸿沟。之前的方法一般使用复述作为重排序或者重写方法以减少语义上的鸿沟。与之前的方法不同,我们提出了一种新的无监督的语义解析方法——同步语义解码(SSD),它可以联合运用复述和语法约束解码同时解决语义鸿沟与结构鸿沟。

语义同步解码的核心思想是将语义解析转换为复述问题。我们将句子复述成标准句式,同时解析出语义表示。其中,标准句式和逻辑表达式存在一一对应关系。为了保证生成有效的标准句式和语义表示,标准句式和语义表示在同步文法的限制中解码生成。
我们通过复述模型在受限的同步文法上解码,利用文本生成模型对标准句式的打分,找到得分最高的标准句式(如上所述,空间同时受文法限制)。本文给出了两种不同的算法:Rule-Level Inference以语法规则为搜索单元和Word-Level Inference使用词作为搜索单元。
我们使用GPT2.0和T5在复述数据集上训练序列到序列的复述模型,之后只需要使用同步语义解码算法就可以完成语义解析任务。为了减少风格偏差影响标准句式的生成,我们提出了适应性预训练和句子重排序方法。

我们在三个数据集上进行了实验:Overnight(λ-DCS)、GEO(FunQL)和GEOGranno。数据覆盖不同的领域和语义表示。实验结果表明,在不使用有监督语义解析数据的情况下,我们的模型在各数据集上均能取得最好的效果。
07 Improving Document Representations by Generating Pseudo Query Embeddings for Dense Retrieval
论文下载
论文作者:唐弘胤,孙兴武,金蓓弘(中科院软件所),王金刚,张富峥,武威
论文类型:Main Conference Long Paper (Oral)
文档检索任务的目标是在海量的文本库中检索出和给定查询语义近似的文本。在实际场景应用中,文档文档库的数量会非常庞大,为了提高检索效率,检索任务一般会分成两个阶段,即初筛和精排阶段。在初筛阶段中,模型通过一些检索效率高的方法筛选出一部分候选文档,作为后续精排阶段的输入。在精排阶段,模型使用高精度排序方法来对候选文档进行排序,得到最终的检索结果。
随着预训练模型的发展和应用,很多工作开始将查询和文档同时送入预训练进行编码,并输出匹配分数。然而,由于预训练模型的计算复杂度较高,对每个查询和文档都进行一次计算耗时较长,这种应用方式通常只能在精排阶段使用。为了加快检索速率,一些工作开始使用预训练模型单独编码文档和查询,在查询前提前将文档库中的文档编码成向量形式,在查询阶段,仅需利用查询编码和文档编码进行相似度计算,减少了时间消耗。由于这种方式会将文档和查询编码为稠密向量形式,因此这种检索也称作“稠密检索”(Dense Retrival)。
一个基本的稠密检索方法会将文档和查询编码成为一个向量。然而由于文档包含的信息较多,容易造成信息丢失。为了改进这一点,有些工作开始对查询和文档的向量表示进行改进,目前已有的改进方法大致可分为三种,如下图所示:
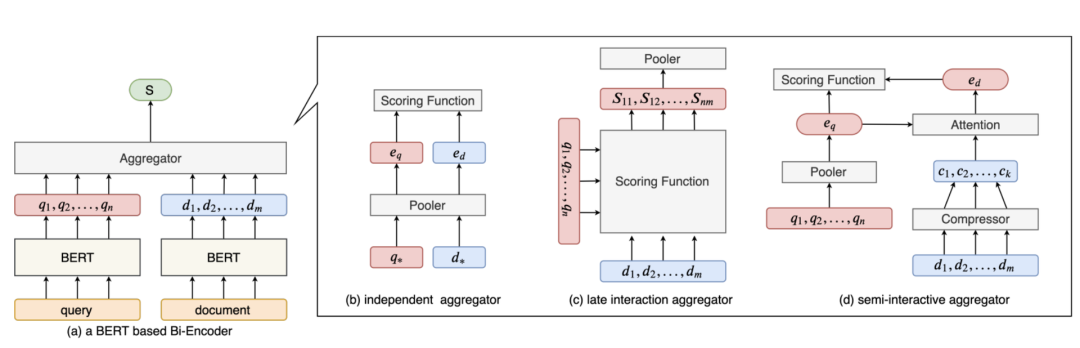
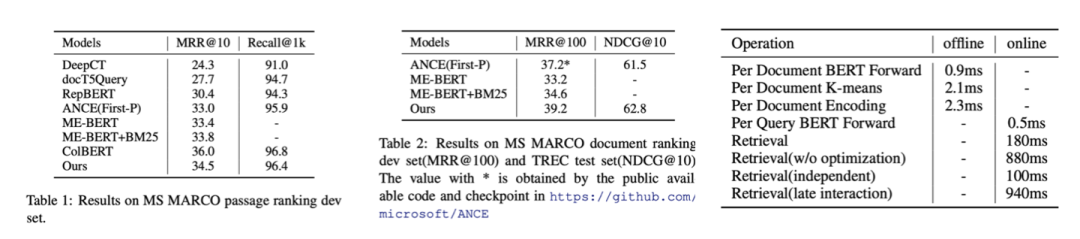
我们的工作从改进文档的编码入手来提高文档编码的语义表示能力。首先,我们认为稠密检索的主要瓶颈在于编码时,文档编码器并不知道文档中的哪部分信息可能会被查询,在编码过程中,很可能造成不同的信息互相影响,造成信息被改变或者丢失。因此,我们在编码文档的过程中,对每个文档构建了多个“伪查询向量”(Pseudo Query Embeddings),每个伪查询向量对应每个文档可能被提问的信息。
具体而言,我们通过聚类算法,将BERT编码的Token向量进行聚类,对每个文档保留Top-k个聚类向量,这些向量包含了多个文档Token向量中的显著语义。另外,由于我们对每个文档保留多个伪查询向量,在相似度计算时可能造成效率降低。我们使用Argmax操作代替Softmax,来提高相似度计算的效率。在多个大规模文档检索数据集的实验表明,我们的方法既可以提高效果也提高了检索效率。
写在后面
以上这些论文是美团技术团队与各高校、科研机构通力合作,在事件抽取、实体识别、意图识别、新槽位发现、无监督句子表示、语义解析、文档检索等领域所做的一些科研工作。论文是我们在实际工作场景中遇到并解决具体问题的一种体现,希望对大家能够有所帮助或启发。
美团科研合作致力于搭建美团各部门与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕人工智能、大数据、物联网、无人驾驶、运筹优化、数字经济、公共事务等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作,欢迎大家跟我们联系(meituan.oi@meituan.com)。
- 一:首先上一张图片
[详细] -->赞
踩
- 一:Device窗口布局和功能实现
[详细] -->赞
踩

