
- 1[314]谷歌翻译_谷歌翻译镜像
- 2卷积神经网络参数量和计算量的计算_卷积参数量计算
- 3C# 调用支付宝API接口_c#支付宝支付api文档
- 4Spark开发实例(SequoiaDB)_spark开发例子
- 5Spring Cloud + Vue前后端分离-第17章 生产打包与发布_springcloud后端打包发布 j
- 6[华中杯]2024ABC题所有小问py代码+高质量完整思路20页重磅更新_太阳能路灯光伏板的朝向设计问题数学建模matlab
- 7python3读写excel文件_13-用 Python 读写 Excel 文件
- 8号称下一代监控系统,来看看它有多强!
- 9Spring boot 3 (3.1.5) Spring Security 设置一_spring boot 3.1.5
- 10Python爬虫怎么挣钱?解析Python爬虫赚钱方式,轻轻松松月入两万,再也不用为钱发愁啦_采集两千万英文数据做网站流量
Dom4j教程详解+XML详解(详解+举例)
赞
踩
1.XML 的介绍
XML(Extensibe Markup Language)表示可扩展的标记语言
XML的标签没有被预定义,也就是说不是固定的,用户可以根据自身需要去定义标签。
XML的作用主要是用来存储数据和传输数据
- 存储数据 是用与存储有层级关系的数据,例如省市区。在java领域XML使用主要是作为框架的配置文件
- Spring application.xml
- Mybatis mybatis.xml
- 传输数据 指的服务提供方返回服务调用方的数据传输格式 比如:json、xml
2.XML元素的组成
编写XML文件,可以些哪些内容?
-
文档声明
<?xml version="1" encodeing="UTF-8" ?>- 1
XML的文档声明是可选的,也就是可以不写,但是日常开发中大家都会写文档声明。
XML的文档声明如果写了,它必须放在XML文件的第一行第一列,必须以<?xml开头,和?>结尾,而且必须包含两个属性:version和encoding- version表示XML的版本,XML目前的版本是1.0
- encoding表示XML的编码,一般都会写UTF-8
-
元素(标签)
元素是XML的重要组成部分,元素也被称为标签
每个XML文件必须要有一个根标签
标签由开始标签和结束标签组成,开始标签和结束标签中间可以写标签,也可以是文本字符串。
标签是可以嵌套使用的,但是不能随便嵌套,必须明确层级关系。
标签名必须遵守命名规则和命名规范
1.标签名不能以数字开头
2.不能使用XML,Xml,xml
3.不能使用空格和冒号
4.命名区分大小写
<users>
<user>
<id>10001</id>
<name>admin</name>
<password>111111</password>
</user>
<user>
<id>10002</id>
<name>xiaoming</name>
<password>666666</password>
</user>
</users>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
属性
属性是标签(元素)的组成部分,属性只能定义在开始标签中,不能定义在结束标签。
属性的定义格式属性名=属性值,属性值需要使用"包含起来。
开始标签中可以定义多个属性,但是多个属性的属性名不能相同。
属性名和标签名一样,也要遵守命名规则和命名规范<users> <user id="10001" country="china" source="Android"> <id>10001</id> <name>admin</name> <password>111111</password> </user> <user id="10002" country="china" source="IOS"> <id>10002</id> <name>xiaoming</name> <password>666666</password> </user> </users>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
-
注释
注释就是对XML标签的说明
IDEA中XML注释的快捷键是Ctrl+/<!--注释-->- 1
-
转义字符
在XML中有些字符是无法识别,此时就需要使用XML的转义字符来表示。
- &使用&来表示
- <使用<来表示
<salary>salary > 15000 & salary < 20000</salary>- 1
-
字符区
CDATA内部所有的内容都会当做文本解析,使用字符区解决在XML中有些字符是无法识别的问题。
IDEA中CDATA的快捷键是CD,然后回车。<![CDATA[ ]]>- 1
- 2
- 3
<salary> <![CDATA[ salary > 15000 & salary < 20000 ]]> </salary>- 1
- 2
- 3
- 4
- 5
3.XML的约束
由于XML的标签是没有预定义,而且目前没有添加约束,在编写XML文件的时候可以添加任意的标签,这样不利于解析。
在XML的技术里可以去编写一个XML约束文件来约束XML编写的规范,这被称为XML约束。
XML约束的类型有如下两种:
1.DTD约束(文件后缀名是。dtd)Java Web项目的web.xml使用的就是DTD约束
2.Schema约束(文件后缀名是,xsd)Spring Framework的application…xml使用的就是Schema约束XSD(XML Schema Definition)
可以根据约束文件的后缀名来判断约束的类型是DTD还是Schema.
为什么有了DTD还要有Schema
Schema约束比DTD约束强大:
1.数据类型更加完善
2.对于元素出现的次数限制更加灵活
在日常开发中(开发业务系统),通常都不会去编写约束文件,但是我们需要根据约束文件编写符合规范的XML文件,因此对于约束文件普通的开发人员看得懂即可。
XML约束—约束XML文件的内容
- 约束XML标签的层级关系(根标签、子标签、子子标签的关系)
- 约束标签(名称、类型)
- 约束标签的属性(属性名、属性类型、属性约束)
4.XML约束-DTD约束
DTD约束的定义
数量词
+表示元素可以出现1-n个
*表示元素可以出现0-n个
,表示必须按照顺序出现
|表示元素可以选取一个
1.约束标签的层级关系
<!ELEMENT >
- 1
<?xml version="1.0" encoding="UTF-8" ?>
<!--约束标签的层级关系-->
<!--定义users标签为根标签,该标签下至少有1个user标签-->
<!ELEMENT users (user+)>
<!--user标签下必须有三个指定顺序的子标签:id,name,password--> 注意这里没有salary
<!ELEMENT user (id,name,password)>
- 1
- 2
- 3
- 4
- 5
- 6
2.约束标签
<!--约束标签-->
<!--id name password这三个标签的标签类型都是字符串-->
<!ELEMENT id (#PCDATA)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT password (#PCDATA)>
- 1
- 2
- 3
- 4
- 5
DTD约束(user.dtd)的定义
<!--约束标签的属性-->
<!--User标签必须包含id属性,属性类型是ID,属性约束是#REQUIRED
User标签必须包含country,属性,属性类型是CDATA,属性约束是#IMPLIED
User标签必须包含platform属性,属性类型是CDATA,属性约束是#FIXED
User标签必须包含source属性,属性类型是枚举,属性约束是Android
-->
<!ATTLIST user
id ID #REQUIRED
country CDATA #IMPLIED
platform CDATA #FIXED "ittimeline"
source (Android|IOS|PC|WeChat) "Android"
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
DTD约束的使用
根据DTD约束文件位置不同,使用方式有如下三种
1.外部DTD-本地DTD,DTD文档在本地磁盘路径,但是和XML文件不是在同一个文件中,DTD文档和XML文件通常是在同一个目录下。
<!DOCTYPE 根元素 SYSTEM "DTD约束的文件名" >
<!DOCTYPE user SYSTEM "user.dtd" >
- 1
- 2
- 3
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE user SYSTEM "user.dtd" > <users> <user id="10001" country="china" source="Android"> <id>10001</id> <name>admin</name> <password>111111</password> <!-- 不满足约束<salary>salary > 15000 & salary < 20000</salary>--> </user> <user id="10002" country="china" source="IOS"> <id>10002</id> <name>xiaoming</name> <password>666666</password> <!-- <salary>--> <!-- <![CDATA[--> <!-- salary > 15000 & salary < 20000--> <!-- ]]>--> <!-- </salary>--> </user> </users>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.外部DTD-公共DTD,DTD文件在网络上,一般都是由框架提供的,也是我们使用最多的。
<!DOCTYPE 根元素 PUBLIC "DTD约束的文件名" "DTD文档的URL">
- 1
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems,Inc.//DTD Web Application
2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
- 1
- 2
3.内部DTD,XML文件和DTD约束在一个XML文件中,DTD约束只会针对当前XML文件有效
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE user [ <!ELEMENT users (user+)> <!ELEMENT user (id,name,password)> <!ELEMENT id (#PCDATA)> <!ELEMENT name (#PCDATA)> <!ELEMENT password (#PCDATA)> <!ATTLIST user id ID #REQUIRED country CDATA #IMPLIED platform CDATA #FIXED "ittimeline" source (Android|IOS|PC|WeChat) "Android"> ]> <users> <user id="10001" country="china" source="Android"> <id>10001</id> <name>admin</name> <password>111111</password> <!-- <salary>salary > 15000 & salary < 20000</salary>--> </user> <user id="10002" country="china" source="IOS"> <id>10002</id> <name>xiaoming</name> <password>666666</password> <!-- <salary>--> <!-- <![CDATA[--> <!-- salary > 15000 & salary < 20000--> <!-- ]]>--> <!-- </salary>--> </user> </users>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
Schema约束
- Schema是新的XML文档约束, 比DTD强大很多,是DTD 替代者;
- Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml。
- Schema 功能更强大,内置多种简单和复杂的数据类型
- Schema 支持命名空间 (一个XML中可以引入多个约束文档)
<?xml version="1.0" ncoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="本文档名称空间"
xmlns="本文档名称空间(缺省)"
elementFormDefault="qualified">
<xs:schema> 是所有XSD文档的根元素,其属性描述文档的名空间及文档引用
xmlns:xs="..." 指示使用xs:作前缀的元素、属性、类型等名称是属于...名称空间的
targetNamespace="..." 指示本文档定义的元素、属性、类型等名称属于...名称空间
xmlns="..." 指示缺省的名空间是...,即没有前缀的元素、属性、类型等名称是属于该名称空间的
elementFormDefault="qualified" 指示使用本XSD定义的XML文档所使用的元素必须在本文档中定义且使用名称空间前缀
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用dom4j解析xml
1.XML解析的方式介绍
在日常开发中常见的XML解析方式有如下两种
- DOM:要求解析器将整个XML文件全部加载到内存中,生成一个Document对象
- 优点:元素和元素之间保留结构、关系,可以针对元素进行增删查改操作
2. 缺点:如果XML文件过大,可能会导致内存溢出
- 优点:元素和元素之间保留结构、关系,可以针对元素进行增删查改操作
- SAX:是一种速度更快,更加高效的解析方式。它是逐行扫描,边扫描边解析,并且以事件驱动的方式来进行具体的解析,每解析一行
都会触发一个事件- 优点:不会出现内存溢出的问题,可以处理大文件
- 缺点:只能读,不能写
解析器就是根据不同的解析方式提供具体的实现,为了方便开发人员来解析XML,有一些方便操作的类库。
dom4j:比较简单的XML解析的类库
Jsoup:功能强大的DOM方式解析的类库,尤其对HTML的解析更加方便
2.使用dom4j解析XML
java项目集成dom4j
1.添加依赖
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.3</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
使用dom4j解析user.xml
步骤
1.创建解析器对象
2.使用解析器对象读取XML文档生成Document对象
3.根据Document对象获取XML的元素(标签)信息
Dom4j重要API说明
org.dom4j.Document常用方法
-
element getRootElement();获取XML文件的根节点- 1
org.dom4j.Element的常用方法
-
String getName(); 返回标签的名称- 1
-
List<Element> elements(); 获取标签的子标签- 1
-
String attributevalue(String name); 获取指定属性名称的属性值- 1
-
String getText();获取标签的文本- 1
-
String elementText(String name);获取指定名称的子标签的文本,返回子标签文本的值- 1
完整实例:
将user.xml放在resouces下即可
<?xml version="1.0" encoding="UTF-8" ?>
<users>
<user id="TB10001" country="chinese">
<id>10001</id>
<name>admin</name>
<password>111111</password>
</user>
<user id="TB10002" country="chinese">
<id>10002</id>
<name>tony</name>
<password>666666</password>
</user>
</users>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
public class Dom4jParseUserXmlTest { public static void main(String[] args) { //1.创建解析器对象 SAXReader saxReader = new SAXReader(); //2.使用解析器对象读取XML文档生成Document对象 try { Document read = saxReader.read( Dom4jParseUserXmlTest.class.getClassLoader().getResource("user.xml")); //3.根据Document对象获取XML的元素(标签)信息 Element rootElement = read.getRootElement(); System.out.println("1.user.xml文件根节点的名字" + rootElement.getName()); System.out.println("2.获取users的子标签列表"); List<Element> usersSubElements = rootElement.elements(); for (Element userElement : usersSubElements) { System.out.println("users标签的子标签的名字是:"+userElement.getName()); System.out.println("users标签的子标签的id属性值:"+userElement.attributeValue("id")); System.out.println("users标签的子标签的country属性值:"+userElement.attributeValue("country")); System.out.println("3.获取user的子标签列表"); List<Element> UserSubElements = userElement.elements(); for (Element userSubElement : UserSubElements) { System.out.println("user标签的子标签:"+userSubElement.getName()); System.out.println("user标签的子标签的文本是:"+userSubElement.getText()); } } //获取users标签的第一个user标签 Element firstUserElement = rootElement.element("user"); //第一个user标签的子标签password的文本 String password = firstUserElement.elementText("password"); System.out.println("第一个user标签的子标签password的文本:"+password); } catch (DocumentException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3.dom4j结合XPath解析XML
XPth可以使用路径表达式来选取XML文档中的元素或者属性节点,节点是沿着路径来选取的。
XPath的文档地址https://www.w3school.com.cn/xpath/index.asp
dom4j集成XPath
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.6</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
dom4j提供基于XPath的API
Document/Element关于XPath的api
-
Node selectsingleNode(String xpathExpression); 根据XPath表达式获取单个标签(元素/节点)- 1
-
List<Node>selectNodes(string xpathExpression); 根据XPath表达式获取多个标签(元素/节点)- 1
XPath的语法
绝对路径方式,以/开头的路径表示绝对路径,绝对路径是从根元素开始写。例如/元素/子元素/子子元素…
相对路径方式:相对于当前节点的元素继续查找的节点,不以/开头,/表示上一个元素,/表示当前元素
全文搜索路径方式:例如//子元素,//子元素//子子元素,子元素//子子元素
//表示无论中间有多少层,直接获取所有子元素所有满足条件的元素
/表示只找一层
谓语(条件筛选)方式例如/元素[@attr1=value’]
package dom4j; import org.dom4j.Document; import org.dom4j.DocumentException; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; import java.util.List; public class Dom4jXPathParseUserXmlTest { public static void main(String[] args) { SAXReader saxReader = new SAXReader(); try { Document document = saxReader.read(Dom4jXPathParseUserXmlTest.class.getClassLoader().getResource("user.xml")); //第一个用户的密码 System.out.println("1.使用绝对路径方式查找元素"); Node element = document.selectSingleNode("/users/user/password"); String password = element.getText(); System.out.println("第一个用户的密码:"+password); System.out.println("2.使用相对路劲查找元素"); Node salaryElement = element.selectSingleNode("../salary"); String salary = salaryElement.getText(); System.out.println("第一个用户的薪水区间:" + salary); System.out.println("3.使用全文搜索的方式"); System.out.println("获取所有ID元素的文本"); List<Node> idNodeList = document.selectNodes("//id"); for (Node node : idNodeList) { Element idElement = (Element) node; System.out.println(idElement.getText()); } //4.谓语(条件筛选)方式例如/元素[@attr1=value'] Element TB10001idElement = (Element) document.selectSingleNode("//user[@id='TB10001']"); List<Element> elementList = TB10001idElement.elements(); for (Element userSubElement : elementList) { userSubElement.setName("idss"); System.out.println("user标签的子标签的名字是:"+userSubElement.getName()); System.out.println("user子标签的文本:"+userSubElement.getText()); } } catch (DocumentException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
添加节点
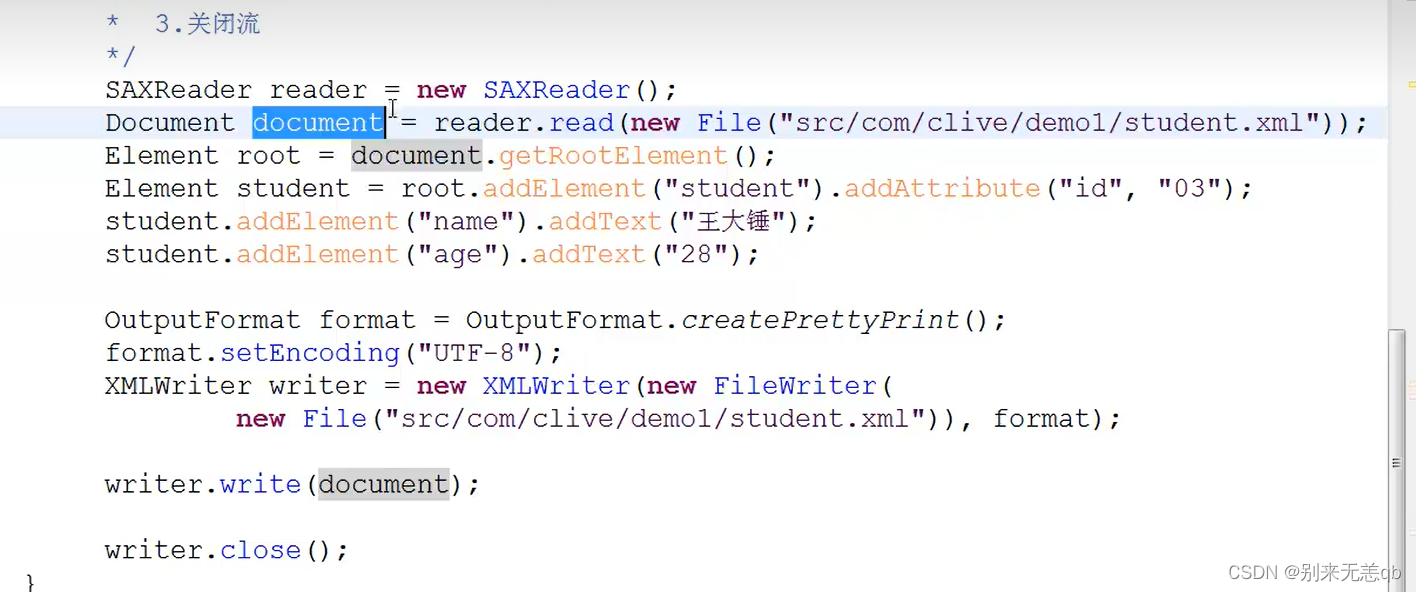
具体实例
后面同步更新

