
- 1驼峰命名法_驼峰命名法实例
- 2数据安全与隐私保护:人工智能与大数据的发展与应用
- 3QT之QPropertyAnimation详细介绍
- 4python 基础词汇及其应用1_paython基础词汇
- 5C++(标准库):17---STL容器之(序列式容器forward_list)_stlea cox
- 6Spring AI教程(十一):深入理解Spring AI的模型和向量数据库_springai 自定义向量模型
- 7基于文心一言AI大模型,编写一段python3程序以获取华为分布式块存储REST接口的实时数据_python调用服务器获取数据
- 8秋招Java后端开发冲刺——基础篇1
- 9第七行:如何使用Python进行自然语言处理(NLP)?
- 10聊聊端到端与下一代自动驾驶系统,以及端到端自动驾驶的一些误区?
你真的看懂扩散模型(diffusion model)了吗?(从DALL·E 2讲起,GAN、VAE、MAE都有)
赞
踩
本文全网原创于CSDN:落难Coder ,未经允许,不得转载!
扩散模型简单介绍
我们来讲一下什么是扩散模型,如果你不了解一些工作,你可能不清楚它究竟是什么。那么我举两个例子说一下:AI作画(输入一些文字就可以得到与你描述相符的图像)和抖音大火的真图生成漫画风图等都是它的成果。如下图是我利用AI生成的漫画图。

这里说的两个例子就表现出了扩散模型已经有的两个能力:文生图以及根据文字/图像对已有图像进行改图,当然这里的工作只是有限的列举,在各个方面扩散模型仍有很多优秀表现。
接下来,我们定义一下扩散模型:扩散模型是根据文本/图像输入生成原创性的贴近真实的图片输出。值得一提的是,这里原创性是至关重要的,很多我们错误理解是:是不是模型学习到了你给的数据集,然后记住了这些数据,进而将输入与输出对应而出图的,这里很明显的强调了是模型原创性的设计,不是原数据集所存在的图像(Fake Image)。
在这里了解技术的同学可能就会产生跟我产生一样的疑问,生图模型不是有GAN吗,为什么还要有扩散模型?这里有一个很专业的回答:GAN模型生图的能力确实是无法比拟的,可以说是具有强大的逼真性,并且一直保持在该领域有良好专业指标(FID score等)。然而最新最热门的扩散模型除了具备生图的逼真性,还兼具了多样性,这也是GAN模型的一大局限。--该解释来自DALL·E 2(最新的扩散模型)论文
关于为什么要叫扩散模型这个问题,其实是来自于热力学,热力学上我们都知道物质会从高浓度往低浓度的地方流动,最终达到一种动态的平衡,而这个过程就是一个扩散过程,由此,扩散模型的名称而来。
从DALL·E 2模型讲起
DALL·E是OpenAI于2021年1月份做出来的一个扩散模型的工作。自从DALL·E出来以后,一大堆工作就开始涌现:
- 2021年5月,清华推出
CogView模型,支持中文生成; - 2021年11月,微软和北大推出了
NUWA(女娲)模型,支持较短视频的生成任务; - 2021年12月,OpenAI推出了
GLIDE; - 2021年12月,百度推出了
ERNIE-ViLG(文心大模型)模型,支持中文生成,参数量巨大(100亿),比肩DALL·E(120亿); - 2022年4月,OpenAI推出了
DALL·E 2(官方名称为unCLIP);
接下来,以DALL·E 2为例,详细看下扩散模型这个领域的发展:
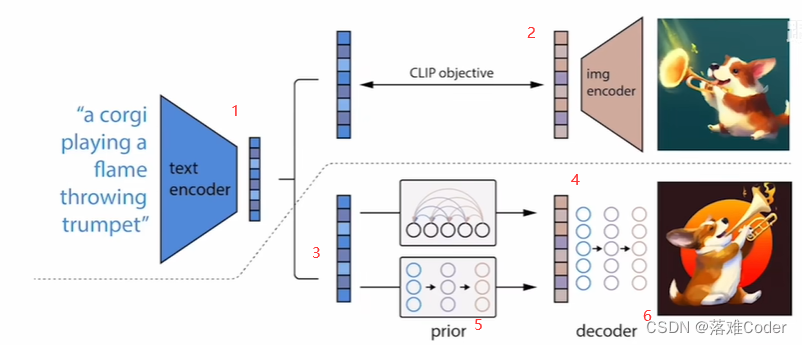
为了方便介绍一些具体的细节介绍,这里我对DALL·E 2论文中的核心架构图进行了编号。
在这个图中,虚线以上部分其实是CLIP(CLIP可以用来做图文匹配任务),虚线以下部分才是DALL·E 2的内容。首先看CLIP,它的工作在于将图像的描述文本(即编号1)做成了文本描述编码器和图像本身(即编号2)做成了图像编码器,之后生成了文本编码和图像编码的配对,然后正确的图像与文字描述就会成为一个正样本,而错误的图像和文字描述会组成一个负样本,从而形成对比学习,利用对比学习,图像和文字(多模态)特征就联系在了一起。这里值得注意的是通过对比学习得到的模型是被锁住的,这里的锁住指的是在训练得到模型以后,该模型不能再进行任何训练和Fine-tune 。
接下来我们继续看DALL·E 2,它其实是一个两阶段的过程,分为prior(即编号5)和decoder(即编号6),由于之前CLIP是有文本特征(即编号1)和图像特征(即编号2)的,在DALL·E 2可以利用输入文本特征生成图像,并且用CLIP的图像特征作为Ground Truth进行监督训练,这样在推理阶段,prior模型就可以利用输入的文字生成图像了,在这里看起来生图任务已经完成了,那么为什么又多了一个decoder(即编号6)呢?这里decoder过程其实就可以理解为64*64图像变成1024*1024这样大图的意思(简单理解,OpenAI有钱,想做的有B格)。
这里解释下前面说到
DALL·E 2官方名称为unCLIP,主要是因为之前的CLIP是想要拿到文本特征和图像特征去做匹配任务,例如图像检索。而到了DALL·E 2应用了该方法,但是又没有完全用,DALL·E 2是一个文字特征生成图像特征进入生成图像的过程,可以理解为CLIP的反过程,即unCLIP。
这里我们完整描述了一整个DALL·E 2模型的论文,对这个扩散模型有了基础的了解,接下来我们可以深入的讲讲扩散模型的知识了。
远古的GAN模型
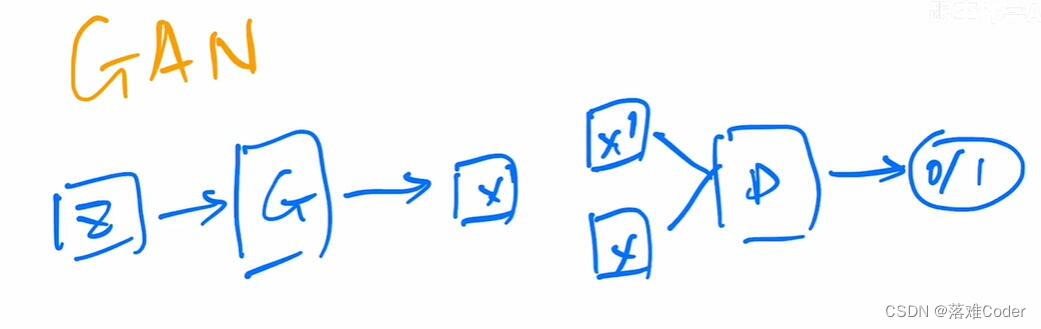
GAN模型可以理解成一个左右手互博的过程,它拥有一个生成器(用于生成噪声的假图像)和一个辨别器(辨别是否是生成的假图像),通过两个网络的互相较量,最终训练出一个保真度极高的图像生成网络模型,所以这也就造就了DeepFake的火爆。然而除了保真度高之外的优良特性,他也有一个致命缺点:由于采取两个网络训练,这里就存在两个网络平衡的问题,如果真的设计不好两个网络,很容易造成整个结果坍塌。还有前面提到的一个缺点就是多样性生成不好。
后来的AE、DAE、VAE、MAE、VQVAE模型
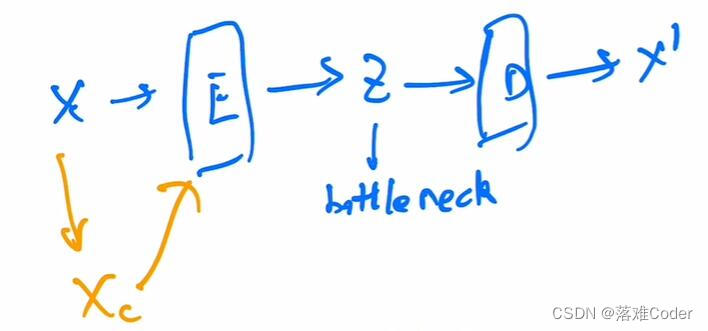
AE、DAE、VAE、MAE、VQVAE这些模型都是采取了一种encoder-decoder的思想。如AE模型,它对于输入X,随机添加一些噪声,之后得到Y,最后让模型能学习利用Y可以重建出来X的过程。
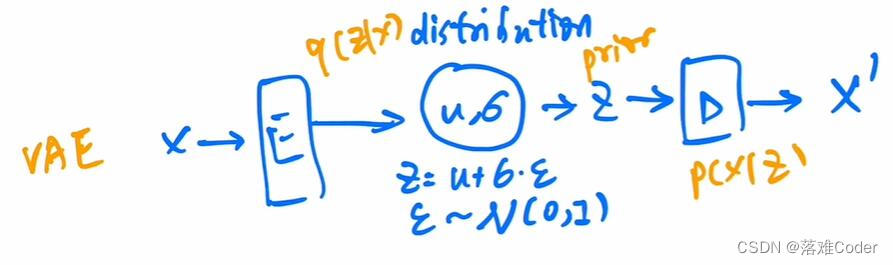
后来的工作,如VAE发现了让模型直接学习噪声从而恢复图像的计算和各种性能上有很大的开销,它开始让模型去学习添加的这些噪声的分布从而让模型有效重建原始的X。再之后的VQVAE则继续改进了这个预测分布(包括均值和方差)的模型,从事了一些其他的研究。
再次回到扩散模型

这里,我们就可以深入的讲解扩散模型的构成了。首先看上图,扩散模型进行一个forward diffusion过程,即从原始X0开始,每次都添加一些正太分布噪声或者其他噪声最终变成XT(X1、X2…XT为不断加入噪声的图像,当T为无穷大时,这个真正的图就变成了一个完全的噪声图,此时就会变成一个各向同性的正太分布)。之后模型就可以进行一个reverse diffusion过程,这个过程其实就是训练一个模型(这个模型是共享的),使得让XT恢复成X(T-1)并最终恢复成X0的过程。由上图可以看到每次reverse diffusion都是一个相同尺寸的图生成另外一个相同尺寸的图像的过程,所以这里很容易就想到了U-Net架构,一个编码-解码的模型,这里将U-Net采用跳跃连接来恢复一些信息,甚至之后在U-Net上加一些Attention等对结构进行改进。大部分时候扩散模型是采用了U-Net,但也不是绝对。
扩散模型的发展历程
扩散模型的概念起源于2015年甚至更早之前,这些年逐渐演变发展:
DDPM(扩散领域开山之作,不是采用U-Net预测图,而是预测噪声【只预测均值,方差设为常数,这样模型也可以有很好的效果】进而恢复图像,同时引入了Time Embedding,用于记录预测的第几步,告诉模型当前这一步是否需要生成更细致图像)。Improved DDPM(让模型又学了方差,同时证明了大模型有更好表现)。Diffusion beats GAN(将模型加大加宽,同时加入classifier guided diffusion,把专业指标做上去,赶超之前的GAN)。GLIDE(classifier-free guided diffusion方法)。DALL·E 2(classifier-free guided diffusion方法同时除了使用classify模型去引导模型学习,使用文本是不是也可以做引导呢,此时引入结合了CLIP,同时做CLIP和classify的guided)。
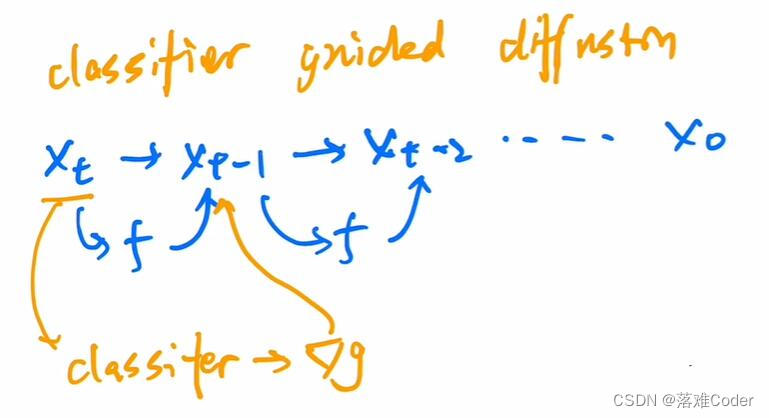
这里着重介绍下
classifier guided diffusion,它其实就是一个简单图像分类器,它可以是基于ImageNet数据集训练,但是又不完全相同于ImageNet,因为需要保持与diffusion(diffusion就是一个输入不断加入噪声的过程)相同,所以需要对ImageNet数据加入噪声再训练得到的一个图像分类模型:
那么这里的图像分类模型有什么用呢?前面我们提到reverse diffusion过程是一个利用U-Net预测XT到X(T-1)的过程,在每一步U-Net预测恢复前一个图像时加入这个图像分类模型去预测当前图像的分类结果,从而干预下一步U-Net模型的采样和生成结果。除了这个工作,后续也有classifier-free guided diffusion等工作。
扩散模型的未来
在生图这个领域,连续霸榜了很久的GAN模型好像已经走到了末尾,已经没有太多的工作去做了,而扩散模型已经击败GAN并且迎来了它发展的最好的时期。

