
- 1执子之手简约唯美的表白网站HTML源码_2022唯美执子之手表白网html源码
- 2【2022应届生看过来】一个无经验的大学毕业生,可以转行做软件测试吗?_软件测试应届没有经验
- 3[沫忘录]Golang基础类型与语法
- 4Pycharm基础——文件操作(IO)技术_pycharm文件操作
- 5智慧校园毕业管理:全面解读毕业批次功能
- 6关于高性能滤波器和普通型滤波器的区别说明
- 7【计算机网络】域名劫持无处遁形:基于HTTPDNS打造可靠且安全的域名解析体系_域名解析接口
- 8基于javaweb+mysql的ssm外卖订餐管理系统(java+ssm+jsp+jquery+ajax+mysql)_外卖系统的前后端开发技术
- 9python选择题_python:选择题系列01
- 10动态链接(ELF文件)_elf动态链接
Stable Diffusion 源码解析(1)_stable diffusion源码
赞
踩
参考1:https://blog.csdn.net/Eric_1993/article/details/129393890
参考2:https://zhuanlan.zhihu.com/p/613337342
1.StableDiffusion基本原理
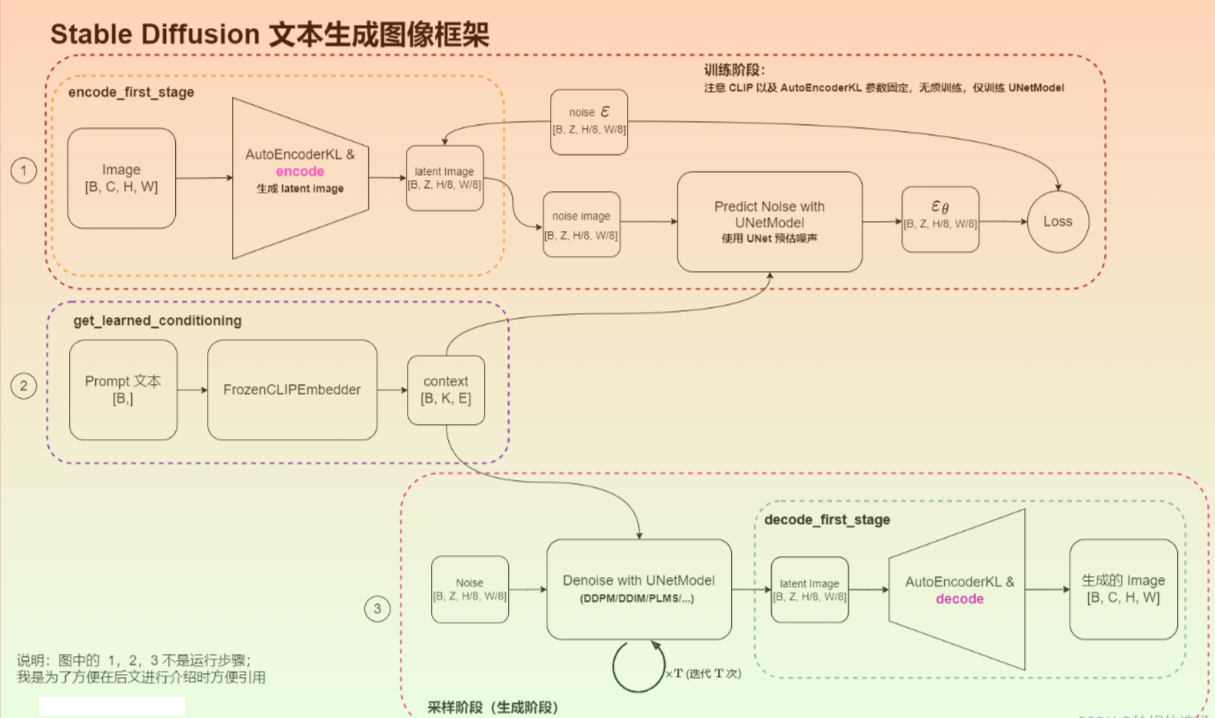
训练阶段 (查看图中 Part 1 和 Part 2),主要包含:
- 使用 AutoEncoderKL 自编码器将图像 Image 从 pixel space 映射到 latent space,学习图像的隐式表达,注意 AutoEncoderKL 编码器已提前训练好,参数是固定的。此时 Image 的大小将从
[B, C, H, W]转换为[B, Z, H/8, W/8],其中Z表示 latent space 下图像的 Channel 数。这一过程在 Stable Diffusion 代码中被称为encode_first_stage; - 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context),其中K表示文本最大编码长度 max length, E 表示 embedding 的大小。这一过程在 Stable Diffusion 代码中被称为get_learned_conditioning; - 进行前向扩散过程(Diffusion Process),对图像的隐式表达进行不断加噪,该过程调用 UNetModel 完成;UNetModel 同时接收图像的隐式表达 latent image 以及文本 embedding context,在训练时以
context作为condition,使用 Attention 机制来更好的学习文本与图像的匹配关系; - 扩散模型输出噪声 ϵ θ \epsilon_{\theta} ϵθ ,计算和真实噪声之间的误差作为 Loss,通过反向传播算法更新 UNetModel 模型的参数,注意这个过程中 AutoEncoderKL 和 FrozenCLIPEmbedder 中的参数不会被更新。
采样阶段(查看图中 Part 2 和 Part 3),也就是我们加载模型参数后,输入提示词就能产出图像的阶段。主要包含:
- 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context); - 随机产出大小为
[B, Z, H/8, W/8]的噪声 Noise,利用训练好的 UNetModel 模型,按照 DDPM/DDIM/PLMS 等算法迭代 T 次,将噪声不断去除,恢复出图像的 latent 表示; - 使用 AutoEncoderKL 对图像的 latent 表示(大小为
[B, Z, H/8, W/8])进行 decode(解码),最终恢复出 pixel space 的图像,图像大小为[B, C, H, W]; 这一过程在 Stable Diffusion 中被称为decode_first_stage。
Stable Diffusion 的模块大致包括:
- FrozenCLIPEmbedder
- UNetModel
- AutoEncoderKL & VQModelInterface (也是一种变分自动编码器,图上没画)
- DDPM、DDIM、PLMS 算法
1.1 UNetModel、FrozenCLIP 模型
画了一下 Stable Diffusion 中使用的 UNetModel,就不分析代码了,看图很容易将代码写出来。Stable Diffusion 采用 UNetModel 这种 Encoder-Decoder 结构来实现扩散的过程,对噪声进行预估, 网络结构如下:
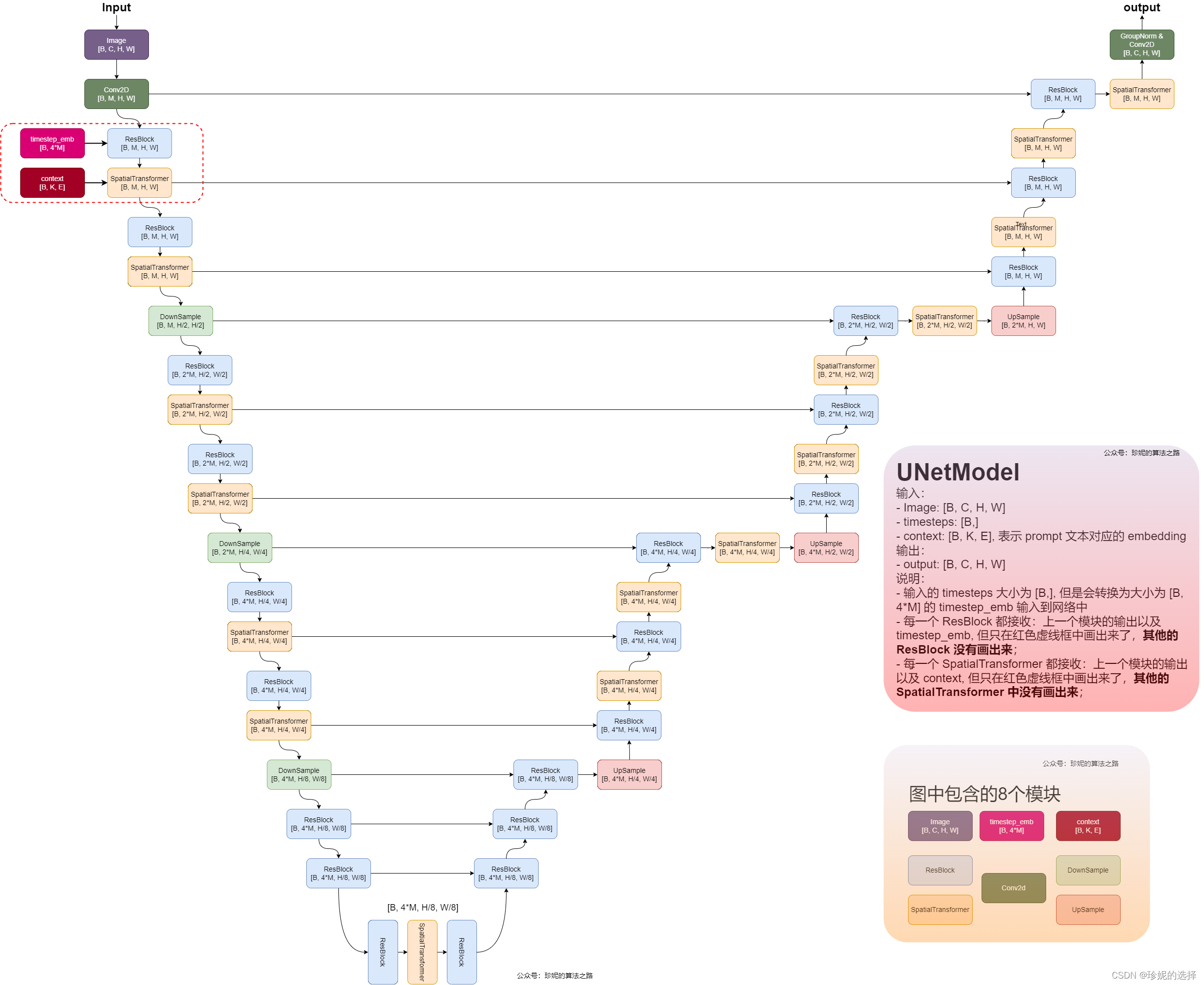
模型的输入包含三个部分:
- 大小为
[B, C, H, W]的图像 image; 注意不用在意表示大小时所用的符号,应将它们视作接口,比如 UNetModel 接收大小为[B, Z, H/8, W/8]的 noise latent image 作为输入时,这里的C就等于Z,H就等于H/8,W就等于W/8; - 大小为
[B,]的 timesteps - 大小为
[B, K, E]的文本 embedding 表示context, 其中K表示最大编码长度,E表示 embedding 大小
模型使用 DownSample 和 UpSample 来对样本进行下采样和上采样,此外出现最多的模块是 ResBlock 以及 SpatialTransformer,其中图中每一个 ResBlock 接收来自上一个模块的输入以及 timesteps 对应的 embedding timestep_emb (大小为 [B, 4*M],M 是可配置的参数);而图中每一个 SpatialTransformer接收来自上一个模块的输入以及 context (Prompt 文本的 embedding 表示),使用 Cross Attention,以 context 为 condition,学习 Prompt 和图像的匹配关系。但图上只在虚线框中显示了两个模块有多个输入,其他模块没有画出来)
可以看到,最后模型的输出大小为 [B, C, H, W], 和输入大小相同,也就是说 UNetModel 不改变输入输出的大小。
下面再分别看看 ResBlock、timestep_embedding、context 以及 SpatialTransformer 的实现。
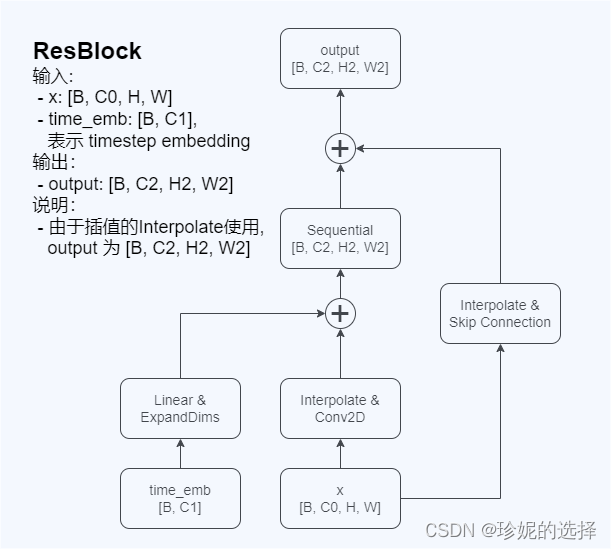
ResBlock 的实现
ResBlock 网络结构图如下,它接受两个输入,图像 x 以及 timestep 对应的 embedding:
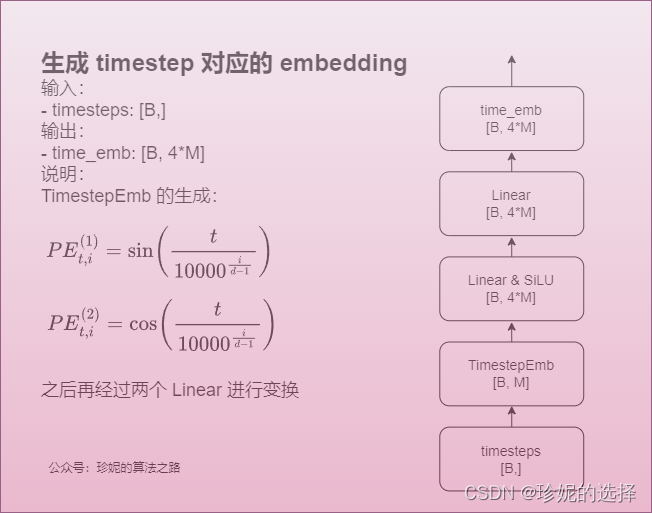
timestep_embedding 实现
timestep_embedding 的生成方式如下,用的是 Tranformer(Attention is All you Need)这篇 paper 中的方法:
Prompt 文本 embedding 的实现
即 context 的实现。Prompt 使用 CLIP 模型进行编码,我没有对 CLIP 模型详细学习,暂时也没有深入看的打算,后续有机会再补充;代码中使用预训练好的 CLIP 生成 context:
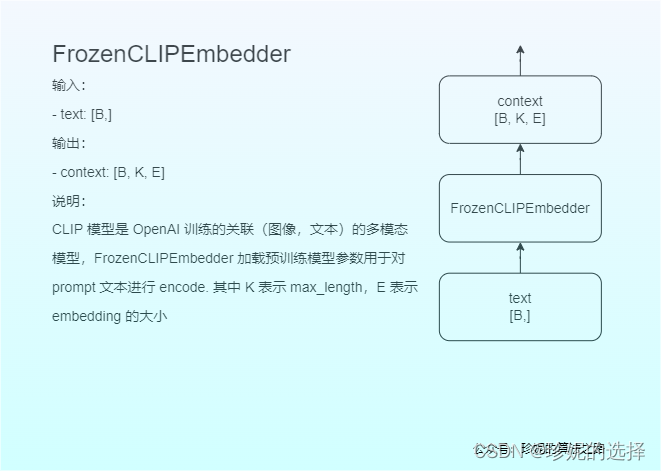
SpatialTransformer 的实现
最后再看下 SpatialTransformer 的实现,其模块比较多,在接收图像作为输入时,还使用 context 文本作为 condition 信息,二者使用 Cross Attention 进行建模。进一步展开 SpatialTransformer, 发现包含 BasicTransformerBlock ,它实际调用 Cross Attention 模块,而在 Cross Attention 模块中,图像信息作为 Query,文本信息作为 Key & Value,模型会关注图像和文本各部分内容的相关性:
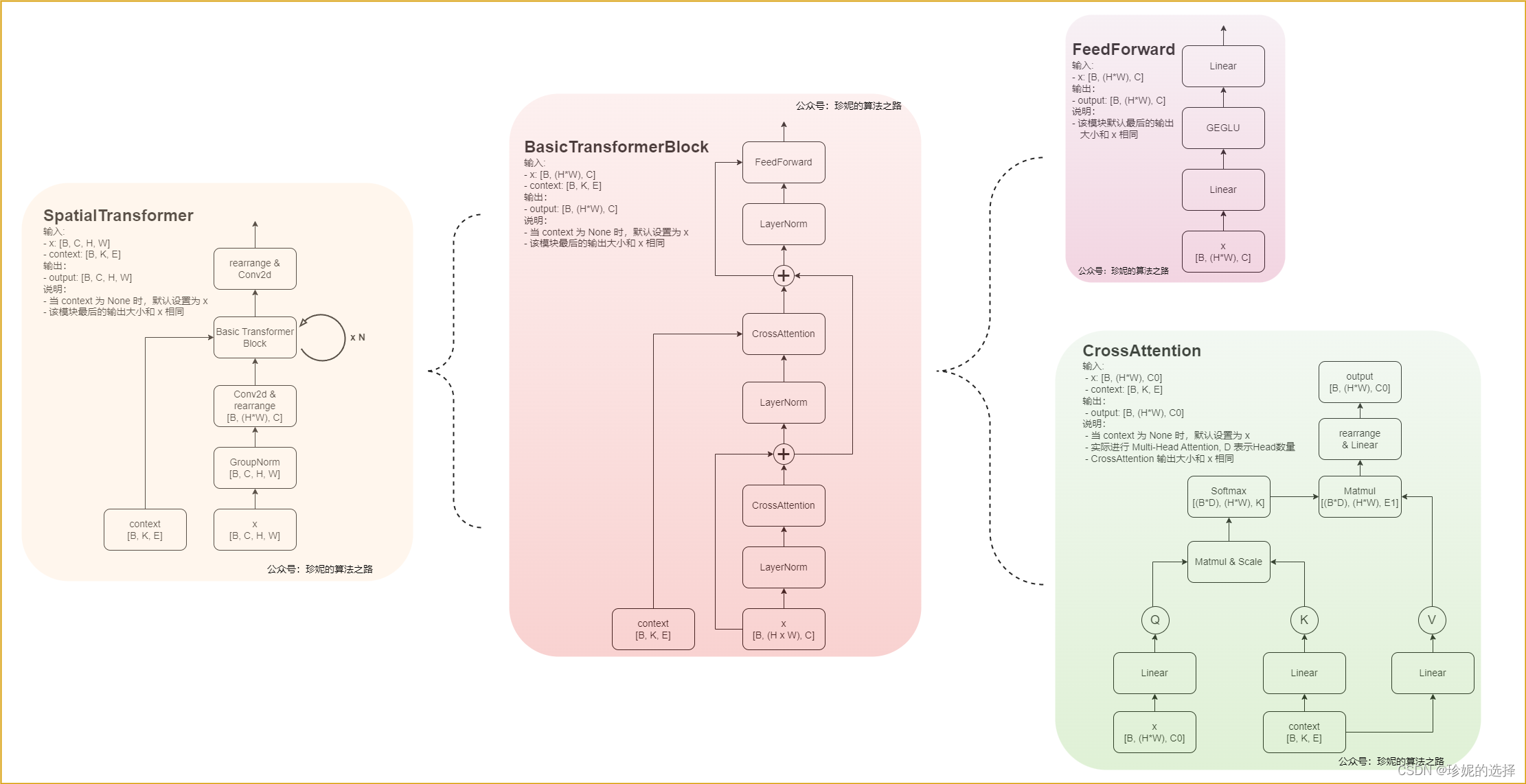
我觉得可以用一种朴素的想法来理解这里 Cross Attention 的作用,比如训练时给定一张马吃草的图,以及文本提示词:“一匹白色的马在沙漠吃草”,在做 Attention 时,文本中的 “马” 这个关键词和图像中的动物(也是 “马”)的关联性更强,因为权重也更大,而 “一匹”、 “白色”、“沙漠”、 “草” 等权重更低;此时,当模型被训练的很好后,模型不仅将可以学习到图像和文本之间的匹配关系,通过 Attention 还可以学习到文本中的各个关键词想突出图像中哪些主体。
1.2 DDPM、DDIM、PLMS算法
扩散模型使用 DDPM、DDIM、PLMS 等采样Sample算法通过迭代去除噪声,从而生成图像的潜在空间(latent space)表示。
在图像生成前,模型会首先在Latent Space中生成一个完全随机的图像,然后噪声预测器会开始工作,从图像中减去预测的噪声。随着这个步骤的不断重复,最终我们得到了一个清晰的图像。Stable Diffusion在每个步骤中都会生成一张新的采样后的图像,整个去噪的过程,即为采样Sample,使用的采样手段,即为采样器Sampler或称为采样方法,
DDPM
对原理进行朴素回顾
DDPM (Denoising Diffusion Probabilistic Models)算法之前在 扩散模型 (Diffusion Model) 简要介绍与源码分析 介绍过,推导有些复杂,这里就用朴素的大白话描述一下我觉得最重要的几个公式,然后分析代码实现,核心是理清楚推导的逻辑链。
首先扩散模型的整个思路是先在图像上不断的加噪,从而对图像进行破坏,然后再对破坏后的图像进行不断的去噪,最后恢复出原始图像。这个过程可以用如下公式描述:
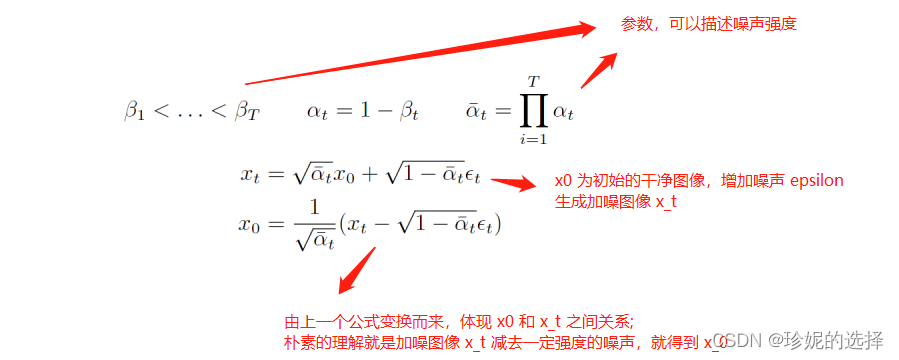
现在的一个问题是如何求逆向阶段的分布,也就是如果给定了一张加噪的图像,我们如何才能求得它前一时刻没有被破坏的那么严重的图像。经过数学高手们的一顿推导,发现两个重要结论:1. 逆向过程也服从高斯分布;2. 在知晓初始干净图像的情况下,我们能通过贝叶斯公式将逆向过程转换成前向过程,从而算出逆向过程的分布; 在公式上体现如下:

算出逆向过程的分布后,我们就可以训练一个模型,去尽力拟合这个分布,那么模型预估出来的结果也应该服从高斯分布:

现在逆向过程的分布有了(可以理解为 label),模型的预估分布也有了,就差一个 Loss 函数,而经过数学高手的又一顿推导,发现 Loss 居然是计算两个分布的 KL 散度,而且还是两个高斯分布的 KL 散度!朴素的说,KL 散度可以用来描述两个分布之间的差距。不得不感慨,数学就是这么神奇,左推右推,最后能得到一个美妙的结果:

多元高斯分布的 KL 散度是有闭式解的,详见维基百科,具体公式如下:
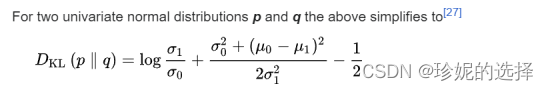
最后得到训练过程和采样过程分别如下:

DDPM 代码分析
再次提醒,我对源码进行了抽象,以伪代码的形式呈现。详细列出每行代码完全没有必要,太多的细节会淹没真正重要的信息。另外注意两点:1. 在实现上,我保持类名、函数名和源码一致,这样就可以方便快速了解类或者函数的功能;2. 函数尽量按调用顺序进行组织;

不客气的说,非常简洁。PyTorch 中 forward() 函数是入口,输出噪声之间的 Loss;
- 采样阶段:
按顺序阅读,核心在 p_sample 函数中,使用重参数技巧生成样本:

针对 DDPM 的改进
下面简单介绍 DDIM 和 PLMS算法,它们均是对 DDPM 算法的改进。DDPM 在采样阶段需要迭代很多次(比如 1000)才能得到一个比较好的效果,而 DDIM、PLMS 算法则尝试使用较少的迭代次数来加速采样过程。下图是 DDIM 论文中给出的实验结果分析:
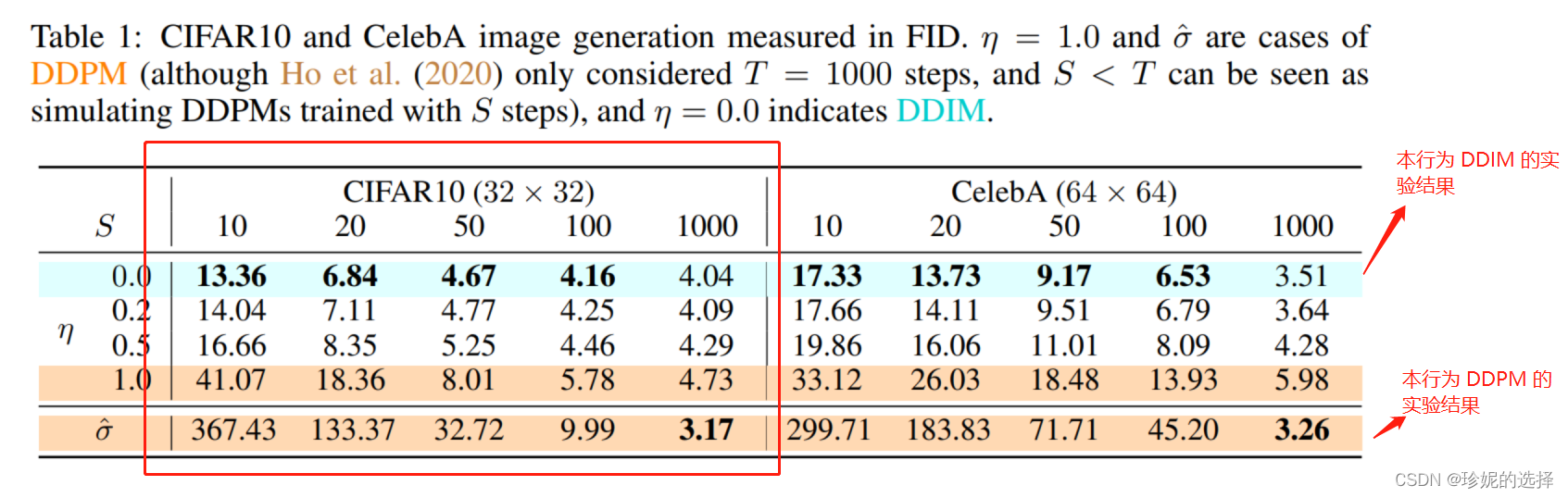
其中第一行(绿线…)是 DDIM 的结果,最后一行是 DDPM 的实验结果,使用 FID 来评估生成图像的质量,该值越小,表示结果越好;S 为迭代次数,只看红框中的 CIFAR10 数据集上的效果,可以发现随着迭代次数的增加,FID 越小,生成图像质量越好;另外可以注意到 DDIM 迭代到第 50 次左右时,就几乎能达到 DDPM 迭代到 1000 次的效果 (4.67 vs. 3.17);
DDIM
DDIM 将图像的采样过程定义为非马尔科夫链:
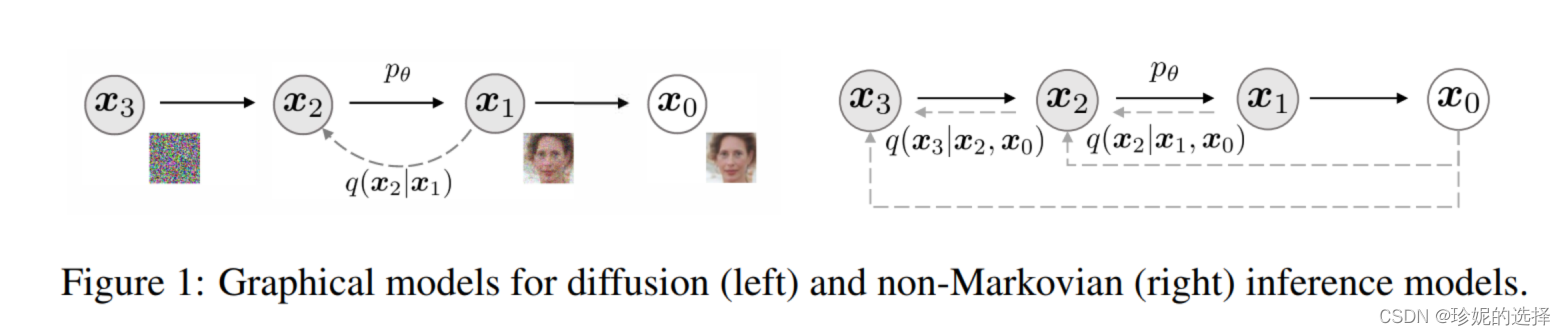
并重新推导了图像的生成公式:
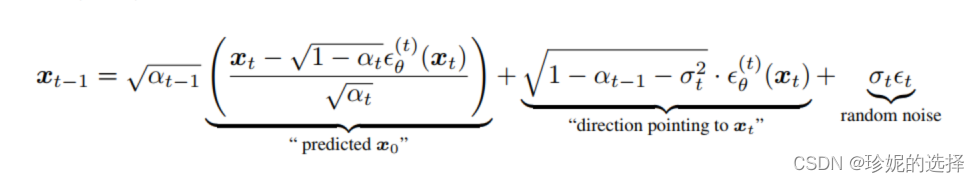
其中
σ
t
\sigma_t
σt, 定义如下:
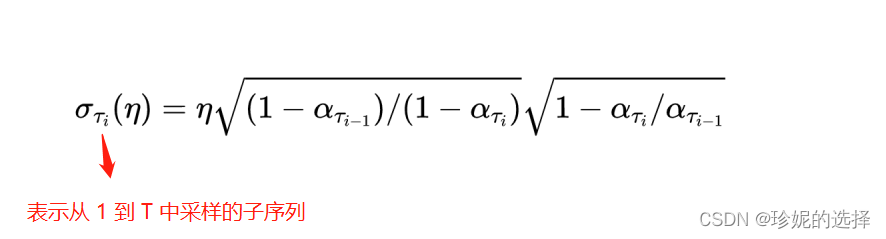
根据推导,如果系数 η = 1, 那么此时采样过程和 DDPM 相同;而当系数 η = 0 时,即为 DDIM 算法的采样过程,注意到此时均方差为 0,图像的生成过程是确定的。另外需要注意在 DDIM paper 的公式中, α t \alpha_t αt以及 β t \beta_t βt 等的含义和 DDPM 论文中不同,它们被重新定义了…
伪代码如下(DDIM 默认只迭代 50 步):

PLMS
PLMS是对DDIM的改进,论文中给出采样过程的公式如下:
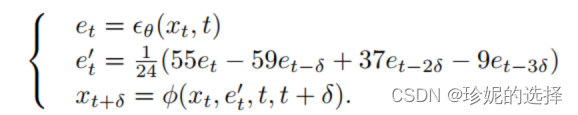 伪代码如下:
伪代码如下:

2. Runwayml SD 源码
参考runwayml的stable-diffusion-v1.5代码,使用SDEdit进行图像编辑推理:先将原始图像经过Inversion加噪作为Sample的起点,在text prompt(condition+uncondition)的引导下迭代Sample,采样噪声,迭代去噪得到编辑后的图像。
2.1 Img2Img Pipeline
Img2Img 图像编辑时,运行scripts/img2img.py,传入text prompt 和 init image:
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img /home/pgao/yue/Stable_Diffusion/data/sketch-mountains-input.jpg --strength 0.8
- 1
总结超参数如下:
--prompt:要渲染的提示文本,默认为 "a painting of a virus monster playing guitar"。
--init-img:输入图像的路径。
--outdir:结果保存的目录,默认为 "outputs/img2img-samples"。
--skip_grid:是否跳过保存网格图像,仅保存单独的样本图像。在评估大量样本时很有帮助。
--skip_save:是否不保存单独的样本图像,用于加速测量。
--ddim_steps:ddim采样步骤的数量。
--plms:是否使用plms采样。
--fixed_code:如果启用,则在所有样本中使用相同的起始编码。
--ddim_eta:ddim采样的eta值(eta=0.0表示确定性采样)。
--n_iter:采样次数。
--C:潜变量通道数。
--f:下采样因子,通常为8或16。
--n_samples:对于每个给定的提示文本,要生成的样本数量,也称为批处理大小。
--n_rows:网格中的行数(默认为n_samples)。
--scale:无条件引导尺度。
--strength:噪声/去噪的强度。1.0表示Inversion完全破坏初始图像中的信息。
--from-file:如果指定,从该文件加载提示文本。
--config:构建模型的配置文件路径。
--ckpt:模型的检查点路径。
--seed:种子值(用于可重复采样)。
--precision:在此精度下评估,可选值为 "full" 或 "autocast",默认为 "autocast"。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
就从入口scripts/img2img.py的main开始阅读,跳过传入参数的parser部分:
- 设置随机种子seed:
seed_everything(opt.seed)
- 1
- 加载Stable Diffusion模型:
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
- 1
- 2
- 3
- 4
其中 opt.config= 'configs/stable-diffusion/v1-inference.yaml',指向一个预定义好的SD model的配置文件,opt.ckpt是预先下载好的模型权重。
然后看load_model_from_config函数,这一函数就定义在同一个文件(img2img.py文件)中,但是它调用了ldm.util中的两个方法instantiate_from_config和get_obj_from_str,将ckpt权重加载到ldm.models.diffusion.ddpm.LatentDiffusion中。这里一起写出来:
def instantiate_from_config(config):
# target = ldm.models.diffusion.ddpm.LatentDiffusion
if not "target" in config:
if config == '__is_first_stage__':
return None
elif config == "__is_unconditional__":
return None
raise KeyError("Expected key `target` to instantiate.")
# 等价于return LatentDiffusion(**config.get("params", dict()))
return get_obj_from_str(config["target"])(**config.get("params", dict()))
def get_obj_from_str(string, reload=False):
# string = ldm.models.diffusion.ddpm.LatentDiffusion
module, cls = string.rsplit(".", 1)
# from ldm.models.diffusion.ddpm import LatentDiffusion
if reload:
module_imp = importlib.import_module(module)
importlib.reload(module_imp)
return getattr(importlib.import_module(module, package=None), cls)
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
if "global_step" in pl_sd:
print(f"Global Step: {pl_sd['global_step']}")
sd = pl_sd["state_dict"]
# 实例化 LatentDiffusion model
model = instantiate_from_config(config.model)
# 为 model 加载权重sd
missing, unexpected = model.load_state_dict(sd, strict=False)
if len(missing) > 0 and verbose:
print("missing keys:")
print(missing)
if len(unexpected) > 0 and verbose:
print("unexpected keys:")
print(unexpected)
model.cuda()
model.eval()
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
其中,missing是一个列表,包含在加载状态字典时模型中缺失的键(参数)。unexpected是一个列表,包含加载状态字典时模型中未预期到的额外键(参数)。理想情况下,两者都是空的。“verbose” 参数通常是一个布尔值或整数,用来控制程序在执行时是否输出详细信息,以及输出信息的程度。
实际上等效于,先实例化ldm.models.diffusion.ddpm.LatentDiffusion,再加载权重:
from ldm.models.diffusion.ddpm import LatentDiffusion
model = LatentDiffusion(**config.model.get("params", dict()))
model.load_state_dict(torch.load(ckpt, map_location="cpu")["state_dict"], strict=False)
- 1
- 2
- 3
原code使用importlib.import_module,来读取字典中的模块名称进行灵活的import。从方便理解代码运行和算法原理的视角来看,在实际使用LatentDiffusion时,上下两种写法是完全等效的。
# 初始化模型的全部逻辑:
from ldm.models.diffusion.ddpm import LatentDiffusion
import torch
from omegaconf import OmegaConf
# 读取config
config = OmegaConf.load(f"{opt.config}")
# 初始化模型并传入config中的参数
model = LatentDiffusion(**config.model.get("params", dict()))
model.load_state_dict(torch.load(ckpt, map_location="cpu")["state_dict"], strict=False)
device = torch.device("cuda")
model = model.to(device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 设置Sampler:
有了model之后是sampler的初始化 (基于命令行传入的 --plms,执行判断语句的第一条):sampler = PLMSSampler(model)
if opt.plms:
raise NotImplementedError("PLMS sampler not (yet) supported")
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
# 设置Noise Schedule
sampler.make_schedule(ddim_num_steps=opt.ddim_steps, ddim_eta=opt.ddim_eta, verbose=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
make_schedule()函数是PLMSSampler和DDIMSampler的函数,设置Noise Schedule的alpha、beta等参数(用于将self.model的参数注册为self的)。先用lambda函数register_buffer将self.model的参数提取copy一份,再用register_buffer为self注册这些参数:
def register_buffer(self, name, attr):
if type(attr) == torch.Tensor:
if attr.device != torch.device("cuda"):
attr = attr.to(torch.device("cuda"))
setattr(self, name, attr)
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
alphas_cumprod = self.model.alphas_cumprod
assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
self.register_buffer('betas', to_torch(self.model.betas))
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
# ddim sampling parameters
ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
ddim_timesteps=self.ddim_timesteps,
eta=ddim_eta,verbose=verbose)
self.register_buffer('ddim_sigmas', ddim_sigmas)
self.register_buffer('ddim_alphas', ddim_alphas)
self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
(1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
1 - self.alphas_cumprod / self.alphas_cumprod_prev))
self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 准备prompt:
紧接着,根据batch_size设置prompt数量。原代码提供了两种输入prompt的方法,分别是命令行输入和从文件读取,不关键。总之最后prompt进入了data这个变量
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
data = list(chunk(data, batch_size))
sample_path = os.path.join(outpath, "samples")
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
grid_count = len(os.listdir(outpath)) - 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 准备编辑的image并转换为latent:
根据batch_size设置init_image数量,并且将images使用VAE encoder编码为latents
assert os.path.isfile(opt.init_img)
init_image = load_img(opt.init_img).to(device)
init_image = repeat(init_image, '1 ... -> b ...', b=batch_size)
init_latent = model.get_first_stage_encoding(model.encode_first_stage(init_image)) # move to latent space
- 1
- 2
- 3
- 4
load_img函数把image转换为tensor,同时完成一系列数据增强:
def load_img(path):
image = Image.open(path).convert("RGB")
w, h = image.size
print(f"loaded input image of size ({w}, {h}) from {path}")
w, h = map(lambda x: x - x % 64, (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=PIL.Image.LANCZOS)
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return 2.*image - 1.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
get_first_stage_encoding函数完成image 到 latent:
def get_first_stage_encoding(self, encoder_posterior):
if isinstance(encoder_posterior, DiagonalGaussianDistribution):
z = encoder_posterior.sample()
elif isinstance(encoder_posterior, torch.Tensor):
z = encoder_posterior
else:
raise NotImplementedError(f"encoder_posterior of type '{type(encoder_posterior)}' not yet implemented")
return self.scale_factor * z
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
到这里,我们有了
model - [LatentDiffusion]sampler - [PLMSSampler]text promptimage latent
这样就可以开始编辑图片了(重新生成)。
- 图像编辑(再生成):
这里有两个重要的部分,一个是PLMSSampler的定义,一个是LatentDiffusion的定义。我们先将这两个模块视作黑箱,假定它们能完美的完成各自的任务,之后再详细看它们的代码。
在开始一张图像的time_step步的迭代sample之前,先计算Inversion的步骤t_enc ,设置推理的精度with autocast("cuda"),关闭梯度with torch.no_grad(),设置ema指数滑动平均with model.ema_scope()。然后开始迭代采样,trange是tqdm的range:
assert 0. <= opt.strength <= 1., 'can only work with strength in [0.0, 1.0]'
t_enc = int(opt.strength * opt.ddim_steps)
print(f"target t_enc is {t_enc} steps")
precision_scope = autocast if opt.precision == "autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
with model.ema_scope():
all_samples = list()
for n in trange(opt.n_iter, desc="Sampling"):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里先简单回忆一下classifier-free guidance的方法:
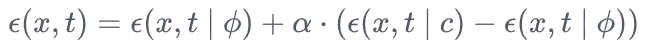
因此除了prompt,也就是上式中c所对应的条件,还需要unconditional的Null text prompt。
# unconditional prompt
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning(batch_size * [""])
# conditional prompt
if isinstance(prompts, tuple):
prompts = list(prompts)
c = model.get_learned_conditioning(prompts)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里可以看到model中的一个方法get_learned_conditioning() : 输入text, 输出text的embedding。self.cond_stage_model是FrozenCLIPEmbedder,self.cond_stage_model.encode()就是FrozenCLIPEmbedder的forward(),完成分别送入CLIPTokenizer和CLIPTextModel,返回编码后的prompt tensor
def get_learned_conditioning(self, c):
if self.cond_stage_forward is None:
if hasattr(self.cond_stage_model, 'encode') and callable(self.cond_stage_model.encode):
c = self.cond_stage_model.encode(c)
if isinstance(c, DiagonalGaussianDistribution):
c = c.mode()
else:
c = self.cond_stage_model(c)
else:
assert hasattr(self.cond_stage_model, self.cond_stage_forward)
c = getattr(self.cond_stage_model, self.cond_stage_forward)(c)
return c
# FrozenCLIPEmbedder
def forward(self, text):
batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
tokens = batch_encoding["input_ids"].to(self.device)
outputs = self.transformer(input_ids=tokens)
z = outputs.last_hidden_state
return z # torch.Size([batch_size, 77, 768])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
接着,为了编辑图像,先采用DDIM Inversion反演原始图像x0,对原始图像的latent进行随机加噪:
# encode (scaled latent)
z_enc = sampler.stochastic_encode(init_latent, torch.tensor([t_enc]*batch_size).to(device))
- 1
- 2
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon
xt=αˉt
x0+1−αˉt
ϵ
用到的stochastic_encode函数用于确定性加噪x0到xt,extract_into_tensor函数用于返回alpha序列中第t个值:
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
@torch.no_grad()
def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
# fast, but does not allow for exact reconstruction
# t serves as an index to gather the correct alphas
if use_original_steps:
sqrt_alphas_cumprod = self.sqrt_alphas_cumprod
sqrt_one_minus_alphas_cumprod = self.sqrt_one_minus_alphas_cumprod
else:
sqrt_alphas_cumprod = torch.sqrt(self.ddim_alphas)
sqrt_one_minus_alphas_cumprod = self.ddim_sqrt_one_minus_alphas
if noise is None:
noise = torch.randn_like(x0)
return (extract_into_tensor(sqrt_alphas_cumprod, t, x0.shape) * x0 +
extract_into_tensor(sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
之后就是图像生成,调用sampler实例的decode方法。
# decode it
samples = sampler.decode(z_enc, c, t_enc, unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,)
- 1
- 2
- 3
传入:采样起点z_enc(原图Inversion的Noise Latent)、condition text embedding c、uncondition text embedding uc、unconditional_guidance_scale opt.scale、需要去噪的步数 t_enc(因为Inversion时只加噪的t_enc步,40步)。
迭代执行p_sample_ddim去噪,p_sample_ddim实现单步去噪,将
x
t
x_t
xt去噪为
x
t
−
1
x_{t-1}
xt−1,最终得到编辑好的
x
0
x_0
x0。
@torch.no_grad()
def decode(self, x_latent, cond, t_start, unconditional_guidance_scale=1.0, unconditional_conditioning=None,
use_original_steps=False):
timesteps = np.arange(self.ddpm_num_timesteps) if use_original_steps else self.ddim_timesteps
timesteps = timesteps[:t_start]
time_range = np.flip(timesteps)
total_steps = timesteps.shape[0]
print(f"Running DDIM Sampling with {total_steps} timesteps")
iterator = tqdm(time_range, desc='Decoding image', total=total_steps)
x_dec = x_latent
for i, step in enumerate(iterator):
index = total_steps - i - 1
ts = torch.full((x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long)
x_dec, _ = self.p_sample_ddim(x_dec, cond, ts, index=index, use_original_steps=use_original_steps,
unconditional_guidance_scale=unconditional_guidance_scale,
unconditional_conditioning=unconditional_conditioning)
return x_dec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
p_sample_ddim实现timestep=t的单步去噪:拼接uc和c的text prompt embedding,self.model.apply_model是Unet预测uc和c引导下的noise,再进行classifier-free guidance的加权组合得到noise e_t,将
x
t
x_t
xt去噪为
x
t
−
1
x_{t-1}
xt−1。
@torch.no_grad()
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None):
b, *_, device = *x.shape, x.device
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
e_t = self.model.apply_model(x, t, c)
# classifier-free guidance
else:
x_in = torch.cat([x] * 2)
t_in = torch.cat([t] * 2)
if isinstance(c, dict):
assert isinstance(unconditional_conditioning, dict)
c_in = dict()
for k in c:
if isinstance(c[k], list):
c_in[k] = [
torch.cat([unconditional_conditioning[k][i], c[k][i]])
for i in range(len(c[k]))
]
else:
c_in[k] = torch.cat([unconditional_conditioning[k], c[k]])
# do it
else:
c_in = torch.cat([unconditional_conditioning, c])
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
if score_corrector is not None:
assert self.model.parameterization == "eps"
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
# select parameters corresponding to the currently considered timestep
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
# current prediction for x_0
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
if quantize_denoised:
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
到这里为止,diffusion的任务已经结束了,x_samples_ddim 再经过decode_first_stage(VAE的decoder),就是最终的结果。
以上就是img2img.py文件的全部内容。这一部分绝大多数代码都是数据的读写和准备工作,核心逻辑部分比较少,还是比较好理解的。
接下来进入ddim文件去看sampler的代码实现。
2.2 DDIMSampler
这一模块的定义在ldm/models/diffusion/ddim.py中。
这一class包含以下方法:
class DDIMSampler(object):
def __init__(self, model, schedule="linear", **kwargs):
super().__init__()
self.model = model
self.ddpm_num_timesteps = model.num_timesteps
self.schedule = schedule
def register_buffer(self, name, attr):
...
setattr(self, name, attr)
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
...
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
self.register_buffer('hyper_params_name', to_torch(self.model.hyper_params_name)) # alpha, beta
...
@torch.no_grad()
def sample(...): # make_schedule_params and ddim_sampling
...
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
samples, intermediates = self.ddim_sampling(...)
return samples, intermediates
@torch.no_grad()
def ddim_sampling(...): # x_t -> x_0
...
for i, step in enumerate(iterator):
img, intermediates = self.p_sample_ddim(...)
return img, intermediates
@torch.no_grad()
def p_sample_ddim(...): # x_t -> x_t-1
...
return x_prev, pred_x0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
其中register_buffer实际功能是:将attr(tensor)设置为name(module)的属性。也就是为模型注册更新变量的,这一简单的方法在make_schedule中被大量的调用,总之就是在生成的每一个step中计算并且更新diffusion过程的各个参数。
def register_buffer(self, name, attr):
if type(attr) == torch.Tensor:
if attr.device != torch.device("cuda"):
attr = attr.to(torch.device("cuda"))
setattr(self, name, attr)
- 1
- 2
- 3
- 4
- 5
接下来就是在上一篇中出现的sampling的入口函数sampler.sample(.....)
def sample(self, S, batch_size, shape, c=None, eta=0., x_T=None, uc_scale=1., uc=None, **kwargs):
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
# sampling
C, H, W = shape
size = (batch_size, C, H, W)
samples, intermediates = self.ddim_sampling(c,size,x_T=x_T,uc_scale=uc_scale,uc=uc,)
return samples, intermediates
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里先用了S,eta生成了参数schedule,将其他的参数[ batch_size, shape, conditioning, unconditional_guidance_scale, ]
接下来看ddim_sampling:返回采样结果x_0和中间结果intermediates
def ddim_sampling(self, cond, shape, x_T=None, uc_scale=1., uc=None,):
device = self.model.betas.device
b = shape[0] # 实际就是batch_size
# 如果x_T不存在,生成随机噪声作为第一步的图片
if x_T is None:
img = torch.randn(shape, device=device)
else:
img = x_T
if timesteps is None:
timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
elif timesteps is not None and not ddim_use_original_steps:
subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
timesteps = self.ddim_timesteps[:subset_end]
intermediates = {'x_inter': [img], 'pred_x0': [img]}
time_range = reversed(range(0,timesteps)) if ddim_use_original_steps else np.flip(timesteps)
total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
print(f"Running DDIM Sampling with {total_steps} timesteps")
iterator = tqdm(time_range, desc='DDIM Sampler', total=total_steps)
for i, step in enumerate(iterator):
index = total_steps - i - 1
ts = torch.full((b,), step, device=device, dtype=torch.long)
img, pred_x0 = self.p_sample_ddim(img, cond, ts, index=index,uc_scale=uc_scale,uc=uc,t_next=ts_next)
if index % log_every_t == 0 or index == total_steps - 1:
intermediates['x_inter'].append(img)
intermediates['pred_x0'].append(pred_x0)
return img, intermediates
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
在这里搭建了关于逐步重建图片的反向去噪过程的for循环,在其中对于每一步的图片都应用了self.p_sample_ddim()这一方法,以下是其核心逻辑。
def p_sample_ddim(self, x, c, t, index, uc_scale=1., uc=None, t_next=None):
b, *_, device = *x.shape, x.device
# classifier-free guidence text condition
x_in = torch.cat([x] * 2)
t_in = torch.cat([t] * 2)
c_in = torch.cat([unconditional_conditioning, c])
# pred classifier-free guidence epsilon_t
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
# params
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
# select parameters corresponding to the currently considered timestep t
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
# current prediction for x_0
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
if quantize_denoised:
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
终于用到了上一篇中提到的Unet model
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
- 1
显然,model对象中定义了apply_model这一函数,接收图像img,step t 和 text prompt 的embedding并返回对应的预测噪声e_t。
之后再通过prediction for x_0、pointing to x_t,基于diffusion model的原理采样下一步的图片x_prev ,即x_t-1。
回看一下上面的内容可以发现sampler在逻辑上并不复杂,但是中间(尤其是make_schedule这一方法中)大量的运算都是基于diffusion model的数学原理的。但是由于这些运算都是预先定义好的,从让代码跑起来/理解每一部分的代码在做什么这样的角度出发的话当作黑箱就可以了。
2.3 LatentDiffusion Model
在这一篇中我们对model的内部进行解读。model 的定义在ldm/models/diffusion/ddpm.py中。
这一文件长达1400+行,非常劝退。其中定义了DDPM,LatentDiffusion以及DiffusionWrapper这3个类。
不过如果仅仅考虑inference阶段的代码逻辑,并且去除掉大量的条件判断的话,事实上可以简化到100行左右。
DDPM:
import torch
import torch.nn as nn
import numpy as np
import pytorch_lightning as pl
from functools import partial
from tqdm import tqdm
from ldm.util import default, instantiate_from_config
from ldm.modules.diffusionmodules.util import make_beta_schedule
class DDPM(pl.LightningModule):
def __init__(self,
unet_config,
timesteps=1000,
beta_schedule="linear",
linear_start=1e-4,
linear_end=2e-2,
cosine_s=8e-3,
**kwargs
):
super().__init__()
self.model = DiffusionWrapper(unet_config)
self.register_schedule(beta_schedule=beta_schedule, timesteps=timesteps,
linear_start=linear_start, linear_end=linear_end, cosine_s=cosine_s)
def register_schedule(self, beta_schedule="linear", timesteps=1000,
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
betas = make_beta_schedule(beta_schedule, timesteps, linear_start=linear_start, linear_end=linear_end,
cosine_s=cosine_s)
alphas = 1. - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1])
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
to_torch = partial(torch.tensor, dtype=torch.float32)
self.register_buffer('betas', to_torch(betas))
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev))
class LatentDiffusion(DDPM):
def __init__(self, first_stage_config, cond_stage_config, scale_factor=1.0, *args, **kwargs):
super().__init__(*args, **kwargs)
self.scale_factor = scale_factor
self.instantiate_first_stage(first_stage_config)
self.instantiate_cond_stage(cond_stage_config)
def register_schedule(self, beta_schedule="linear", timesteps=1000,
linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
super().register_schedule(beta_schedule, timesteps, linear_start, linear_end, cosine_s)
def instantiate_first_stage(self, config):
model = instantiate_from_config(config)
self.first_stage_model = model.eval()
for param in self.first_stage_model.parameters():
param.requires_grad = False
def instantiate_cond_stage(self, config):
model = instantiate_from_config(config)
self.cond_stage_model = model.eval()
for param in self.cond_stage_model.parameters():
param.requires_grad = False
def get_learned_conditioning(self, c):
return self.cond_stage_model.encode(c)
@torch.no_grad()
def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
z = 1. / self.scale_factor * z
return self.first_stage_model.decode(z)
def apply_model(self, x_noisy, t, cond, return_ids=False):
cond = {'c_crossattn': [cond]}
x_recon = self.model(x_noisy, t, **cond)
return x_recon
class DiffusionWrapper(pl.LightningModule):
def __init__(self, diff_model_config):
super().__init__()
self.diffusion_model = instantiate_from_config(diff_model_config)
def forward(self, x, t, c_concat: list = None, c_crossattn: list = None):
cc = torch.cat(c_crossattn, 1)
out = self.diffusion_model(x, t, context=cc)
return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
这里LatentDiffusion继承自DDPM,而它们有:
self.model = DiffusionWrapper(unet_config)
...
class DiffusionWrapper(pl.LightningModule):
def __init__(self, diff_model_config):
self.diffusion_model = instantiate_from_config(diff_model_config)
- 1
- 2
- 3
- 4
- 5
- 6
也就是,初始化LatentDiffusion的时候,同时会实例化一个DiffusionWrapper,并运行DiffusionWrapper的__init__中的instantiate_from_config,读取传入的config中的unet_config这一键值对应的Config字典,来初始化Unet。
如2.1提到的,一系列的模块都这样被初始化。【ctrl+F 搜索 instantiate_from_config 可以看到它被多次调用来进行模块的实例化】
回忆一下,在上一篇中提到,sampler中最后调用了model.apply这一方法来进行图像噪声的预测。sampler中的model实际上是LatentDiffusion的实例。
class LatentDiffusion(DDPM):
def apply_model(self, x_noisy, t, cond, return_ids=False):
cond = {'c_crossattn': [cond]}
x_recon = self.model(x_noisy, t, **cond)
return x_recon
- 1
- 2
- 3
- 4
- 5
可以看到 apply_model这一方法又调用了self.model(),而LatentDiffusion由于继承自DDPM,它的self.model实际上指向的是DiffusionWrapper,所以最终承担这一步运算任务的是DiffusionWrapper.diffusion_model。
diffusion_model 这一变量是用instantiate_from_config根据unet_config这一字典实例化得来的。所以我们去看一下Config配置文件
model:
base_learning_rate: 1.0e-04
target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
...
scheduler_config: # 10000 warmup steps
target: ldm.lr_scheduler.LambdaLinearScheduler
params:
...
unet_config:
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
params:
...
first_stage_config:
target: ldm.models.autoencoder.AutoencoderKL
params:
...
cond_stage_config:
target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
unet_config的target是UNetModel, 层层的嵌套终于快到末端了。
2.4 UNet Model
2.3 中,也就是说调用了UNetModel.forward(x_noisy, t, **cond)
class LatentDiffusion(DDPM):
def apply_model(self, x_noisy, t, cond, return_ids=False):
cond = {'c_crossattn': [cond]}
x_recon = self.model(x_noisy, t, **cond)
return x_recon
- 1
- 2
- 3
- 4
- 5
文件:ldm/modules/diffusionmodules/openaimodel.py
原代码太长了,还是和之前一样,按照原作者给的config删掉用不上的部分,原代码可以简化到不到200行。其中最重要的部分是对UnetModel的定义。
上采样和下采样
- 上采样Upsample:先插值再卷积
class Upsample(nn.Module):
def __init__(self, channels, out_channels=None, padding=1):
super().__init__()
self.conv = nn.Conv2d(channels, out_channels, 3, padding=padding)
def forward(self, x):
x = F.interpolate(x, scale_factor=2, mode="nearest")
x = self.conv(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 下采样Downsample:卷积
class Downsample(nn.Module):
def __init__(self, channels, out_channels=None,padding=1):
super().__init__()
self.op = nn.Conv2d(channels, out_channels, 3, stride=2, padding=padding)
def forward(self, x):
return self.op(x)
- 1
- 2
- 3
- 4
- 5
- 6
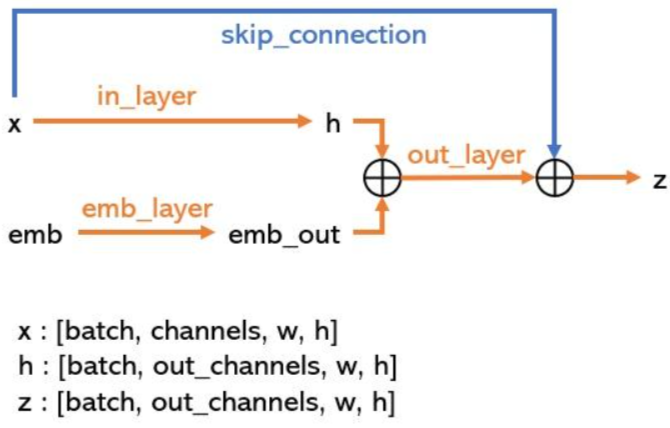
- ResBlock:Resblock同时接受图像和 step embedding 两个输入,网络结构由in layer,out layer,emb layer以及skip connection四个部分组成。
from abc import abstractmethod
import torch as th
import torch.nn as nn
import torch.nn.functional as F
from ldm.modules.diffusionmodules.util import normalization
class TimestepBlock(nn.Module):
@abstractmethod
def forward(self, x, emb):
"""
Apply the module to `x` given `emb` timestep embeddings.
"""
class ResBlock(TimestepBlock):
def __init__(self, channels, emb_channels, dropout, out_channels=None):
super().__init__()
self.channels = channels
self.dropout = dropout
self.out_channels = out_channels or channels
self.in_layers = nn.Sequential(
normalization(channels),
nn.SiLU(),
nn.Conv2d(channels, self.out_channels, 3, padding=1))
self.emb_layers = nn.Sequential(
nn.SiLU(),
nn.Linear(emb_channels,self.out_channels))
self.out_layers = nn.Sequential(
normalization(self.out_channels),
nn.SiLU(),
nn.Dropout(p=dropout),
nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1))
if self.out_channels == channels:
self.skip_connection = nn.Identity()
else:
self.skip_connection = nn.Conv2d(channels, self.out_channels, 1)
def forward(self, x, emb):
h = self.in_layers(x)
emb_out = self.emb_layers(emb).type(h.dtype)
while len(emb_out.shape) < len(h.shape):
emb_out = emb_out[..., None]
h = h + emb_out
h = self.out_layers(h)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
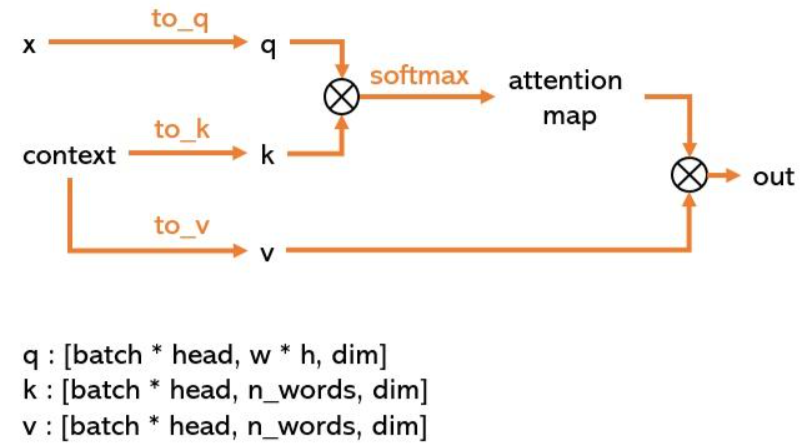
- SpatialTransformer
SpatialTransformer有以下必要的组件:
- CrossAttention
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
context_dim = default(context_dim, query_dim)
self.scale = dim_head ** -0.5
self.heads = heads
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, query_dim),
nn.Dropout(dropout)
)
def forward(self, x, context=None, mask=None):
h = self.heads
q = self.to_q(x)
context = default(context, x)
k = self.to_k(context)
v = self.to_v(context)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
# attention, what we cannot get enough of
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
return self.to_out(out)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
2. BasicTransformerBlock
class FeedForward(nn.Module):
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
super().__init__()
inner_dim = int(dim * mult)
dim_out = default(dim_out, dim)
project_in = nn.Sequential(
nn.Linear(dim, inner_dim),
nn.GELU()
) if not glu else GEGLU(dim, inner_dim)
self.net = nn.Sequential(
project_in,
nn.Dropout(dropout),
nn.Linear(inner_dim, dim_out))
def forward(self, x):
return self.net(x)
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # cross attention
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
def forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
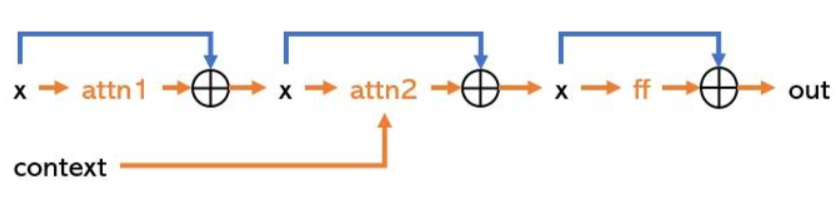
注意这里的attn1是self-attention, attn2才是cross-attention
- 定义spatialTransformer
class SpatialTransformer(nn.Module):
def __init__(self, in_channels, n_heads, d_head,
depth=1, dropout=0., context_dim=None):
super().__init__()
self.in_channels = in_channels
inner_dim = n_heads * d_head
self.norm = Normalize(in_channels)
self.proj_in = nn.Conv2d(in_channels,inner_dim,kernel_size=1,stride=1,padding=0)
self.transformer_blocks = nn.ModuleList(
[BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
for d in range(depth)])
self.proj_out = nn.Conv2d(inner_dim,in_channels,kernel_size=1,stride=1,padding=0)
def forward(self, x, context=None):
b, c, h, w = x.shape
x_in = x
x = self.norm(x)
x = self.proj_in(x)
x = rearrange(x, 'b c h w -> b (h w) c')
for block in self.transformer_blocks:
x = block(x, context=context)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
x = self.proj_out(x)
return x + x_in
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在block中是若干个上面定义的BasicTransformerBlock,数量由参数depth指定
- UNetModel
UNet基于config将上述模块组合起来。

class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
def forward(self, x, emb, context=None):
for layer in self:
if isinstance(layer, TimestepBlock):
x = layer(x, emb)
elif isinstance(layer, SpatialTransformer):
x = layer(x, context)
else:
x = layer(x)
return x
class UNetModel(nn.Module):
def __init__(
self,
image_size,
in_channels,
model_channels,
out_channels,
num_res_blocks,
attention_resolutions,
dropout=0,
channel_mult=(1, 2, 4, 8),
num_heads=-1,
transformer_depth=1, # custom transformer support
context_dim=None
):
super().__init__()
self.image_size = image_size
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.num_heads = num_heads
time_embed_dim = model_channels * 4
self.time_embed = nn.Sequential(
nn.Linear(model_channels, time_embed_dim),
nn.SiLU(),
nn.Linear(time_embed_dim, time_embed_dim),
)
self.input_blocks = nn.ModuleList(
[TimestepEmbedSequential(nn.Conv2d(in_channels, model_channels, 3, padding=1))]
)
self._feature_size = model_channels
input_block_chans = [model_channels]
ch = model_channels
ds = 1
for level, mult in enumerate(channel_mult):
for _ in range(num_res_blocks):
layers = [ResBlock(ch,time_embed_dim,dropout,out_channels=mult * model_channels)]
ch = mult * model_channels
if ds in attention_resolutions:
dim_head = ch // num_heads
layers.append(SpatialTransformer(
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim))
self.input_blocks.append(TimestepEmbedSequential(*layers))
self._feature_size += ch
input_block_chans.append(ch)
if level != len(channel_mult) - 1:
out_ch = ch
self.input_blocks.append(
TimestepEmbedSequential(Downsample(ch, out_channels=out_ch)))
ch = out_ch
input_block_chans.append(ch)
ds *= 2
self._feature_size += ch
dim_head = ch // num_heads
self.middle_block = TimestepEmbedSequential(
ResBlock(ch, time_embed_dim, dropout),
SpatialTransformer(ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim),
ResBlock(ch, time_embed_dim, dropout))
self._feature_size += ch
self.output_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
ich = input_block_chans.pop()
layers = [ResBlock(ch + ich, time_embed_dim, dropout, out_channels=model_channels * mult)]
ch = model_channels * mult
if ds in attention_resolutions:
dim_head = ch // num_heads
layers.append(SpatialTransformer(
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim))
if level and i == num_res_blocks:
out_ch = ch
layers.append(
Upsample(ch, out_channels=out_ch)
)
ds //= 2
self.output_blocks.append(TimestepEmbedSequential(*layers))
self._feature_size += ch
self.out = nn.Sequential(
normalization(ch),
nn.SiLU(),
nn.Conv2d(model_channels, out_channels, 3, padding=1))
def forward(self, x, timesteps=None, context=None, y=None,**kwargs):
hs = []
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb)
h = x.type(th.float32)
for module in self.input_blocks:
h = module(h, emb, context)
hs.append(h)
h = self.middle_block(h, emb, context)
for module in self.output_blocks:
h = th.cat([h, hs.pop()], dim=1)
h = module(h, emb, context)
h = h.type(x.dtype)
return self.out(h)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
3. Diffusers StableDiffusionPipeline源码
本系列文章将深入diffusers的源码一步步进行解析,主要涉及:
-
Stable Diffusion 整体结构 与 模型导出
https://zhuanlan.zhihu.com/p/603161500 -
Text encoder source code
https://zhuanlan.zhihu.com/p/603168346 -
Unet source code
https://zhuanlan.zhihu.com/p/603962505 -
Vae source code

