
- 1CVSS4.0将于2023年底正式发布_cvss4.0 3.1
- 2数据结构(4.1)——树的性质
- 3OpenssH 漏洞修复_openssh漏洞
- 4深度学习论文导航 | 11 LaneNet:基于实例分割方法的车道线检测网络_基于实例分割的车道线检测算法
- 5c++编码规范(五)_禁止使用rand生成伪随机数
- 6GitHub十大Python项目推荐,Star最高26_github 排行 python
- 7vs code配置MySQL,实现连接、查询等功能
- 8Element UI 消息提示 Message_element-ui message
- 9每天一个数据分析题(四百二十九)- 假设检验
- 10小程序消息推送(含源码)java实现小程序推送,springboot实现微信消息推送_微信小程序发送消息通知 java代码
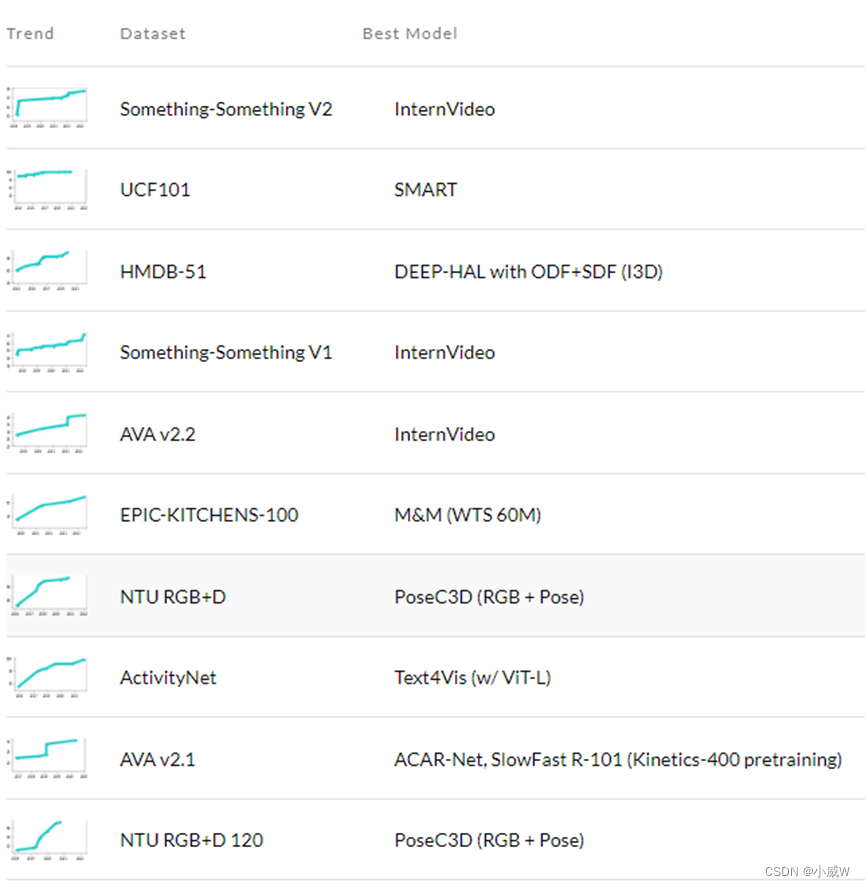
动作识别、检测、分割、解析相关数据集介绍_kinetics数据集
赞
踩
文章目录
本文将列举介绍目前在动作识别、动作检测、动作分割等相关领域的常用数据集和各自的特点。
动作识别
对剪辑后的一段包含特定动作的视频进行分类。
UCF101(UCF101 Human Actions dataset)
UCF101数据集是UCF50的扩展,由13320个视频片段组成,分为101个类别。这101个类别可分为5类(身体运动、人与人互动、人与物互动、乐器演奏和运动)。这些视频剪辑的总时长超过27个小时。所有视频均来自YouTube,固定帧率为25fps,分辨率为320 × 240。
Khurram Soomro, Amir Roshan Zamir, & Mubarak Shah (2012). UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild arXiv: Computer Vision and Pattern Recognition.
可用于:action recoognition
The action categories for UCF101 data set are: Apply Eye Makeup, Apply Lipstick, Archery, Baby Crawling, Balance Beam, Band Marching, Baseball Pitch, Basketball Shooting, Basketball Dunk, Bench Press, Biking, Billiards Shot, Blow Dry Hair, Blowing Candles, Body Weight Squats, Bowling, Boxing Punching Bag, Boxing Speed Bag, Breaststroke, Brushing Teeth, Clean and Jerk, Cliff Diving, Cricket Bowling, Cricket Shot, Cutting In Kitchen, Diving, Drumming, Fencing, Field Hockey Penalty, Floor Gymnastics, Frisbee Catch, Front Crawl, Golf Swing, Haircut, Hammer Throw, Hammering, Handstand Pushups, Handstand Walking, Head Massage, High Jump, Horse Race, Horse Riding, Hula Hoop, Ice Dancing, Javelin Throw, Juggling Balls, Jump Rope, Jumping Jack, Kayaking, Knitting, Long Jump, Lunges, Military Parade, Mixing Batter, Mopping Floor, Nun chucks, Parallel Bars, Pizza Tossing, Playing Guitar, Playing Piano, Playing Tabla, Playing Violin, Playing Cello, Playing Daf, Playing Dhol, Playing Flute, Playing Sitar, Pole Vault, Pommel Horse, Pull Ups, Punch, Push Ups, Rafting, Rock Climbing Indoor, Rope Climbing, Rowing, Salsa Spins, Shaving Beard, Shotput, Skate Boarding, Skiing, Skijet, Sky Diving, Soccer Juggling, Soccer Penalty, Still Rings, Sumo Wrestling, Surfing, Swing, Table Tennis Shot, Tai Chi, Tennis Swing, Throw Discus, Trampoline Jumping, Typing, Uneven Bars, Volleyball Spiking, Walking with a dog, Wall Pushups, Writing On Board, Yo Yo.

Kinetics (Kinetics Human Action Video Dataset)
Kinetics数据集是一个用于视频中人类动作识别的大规模、高质量数据集。该数据集包含约50万个视频剪辑,涵盖400个人类动作类,每个动作类至少400个视频剪辑。每个视频剪辑大约持续10秒,并标有单个动作类。这些视频来自YouTube。
Andrew Zisserman, Joao Carreira, Karen Simonyan, Will Kay, Brian Hu Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, & Mustafa Suleyman (2017). The Kinetics Human Action Video Dataset arXiv: Computer Vision and Pattern Recognition.
可用于:action classification

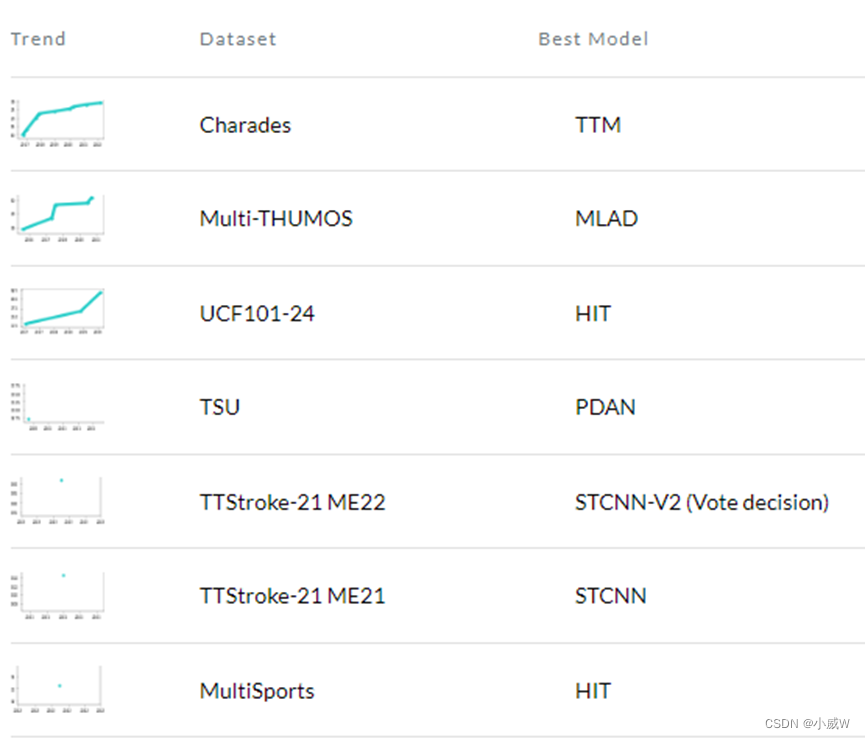
动作检测 / 时序动作定位
找到动作的开始帧和结束帧并进行分类。/检测视频流中的活动,并输出开始和结束时间戳。
Charades
Charades数据集由9848个平均时长为30秒的日常室内活动视频组成,涉及15种室内场景中46种对象类的交互,包含30个动词词汇,可导致157种动作类。该数据集中的每个视频都由多个自由文本描述、动作标签、动作间隔和交互对象的类别进行注释。研究人员向267名不同的用户展示了一个句子,其中包括来自固定词汇的物体和动作,他们录制了一段表演句子的视频。总的来说,该数据集包含157个动作类的66500个时间注释,46个对象类的41104个标签,以及27847个视频的文本描述。在标准分割中,有7986个训练视频和1863个验证视频。
Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, & Abhinav Gupta (2016). Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding arXiv: Computer Vision and Pattern Recognition.
可用于:action classification / action detection

ActivityNet
ActivityNet数据集包含200种不同类型的活动,以及从YouTube上收集的总共849小时的视频。就活动类别和视频数量而言,ActivityNet是迄今为止最大的时间活动检测基准,这使得这项任务特别具有挑战性。1.3版本的数据集总共包含19994个未修剪的视频,并按照2:1:1的比例分为三个互不关联的子集,训练,验证和测试。平均而言,每个活动类别有137个未修剪的视频。每个视频平均有1.41个带有时间边界注释的活动。测试视频的真实注释是不公开的。
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, & Juan Carlos Niebles (2015). ActivityNet: A large-scale video benchmark for human activity understanding Computer Vision and Pattern Recognition.
可用于:Temporal Action Localization / Action Recognition
Multi-THUMOS
MultiTHUMOS数据集包含密集的、多标签的、帧级的动作注释,在THUMOS的14个动作检测数据集中,横跨400个视频,长达30小时。它由65个动作类的38690个注释组成,平均每帧1.5个标签,每个视频10.5个动作类。
Serena Yeung, Olga Russakovsky, Ning Jin, Mykhaylo Andriluka, Greg Mori, & Li Fei-Fei (2015). Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos Cornell University - arXiv.
可用于:Action Detection
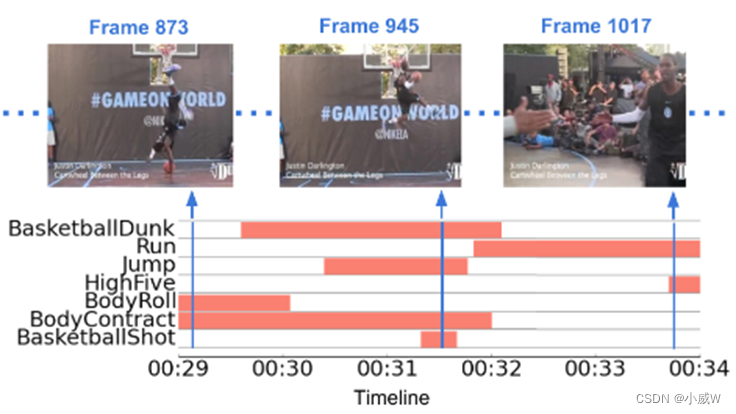
每帧可能有多种标签

UCF101-24
UCF101_24是UCF101数据集的子集,使用了一些不一样的标签。
类别信息有24类。
可用于:Action Detection / Temporal Action Localization

IKEA ASM
大型标记数据集的可用性是应用深度学习方法解决各种计算机视觉任务的关键要求。在理解人类活动的背景下,现有的公共数据集虽然规模很大,但通常仅限于单个RGB摄像机,并且只提供每帧或每剪辑的动作注释。为了能够更丰富地分析和理解人类活动,我们引入了宜家ASM——一个300万帧、多视图、家具组装视频数据集,包括深度、原子动作、对象分割和人体姿势。此外,我们在这个具有挑战性的数据集上对视频动作识别、对象分割和人体姿势估计任务的突出方法进行了基准测试。数据集能够开发整体方法,集成多模态和多视图数据,以更好地执行这些任务。
Yizhak Ben-Shabat, Xin Yu, Fatemeh Sadat Saleh, Dylan Campbell, Cristian Rodriguez-Opazo, Hongdong Li, & Stephen Gould (2020). The IKEA ASM Dataset: Understanding People Assembling Furniture through Actions, Objects and Pose arXiv: Computer Vision and Pattern Recognition.
可用于:Action Recognition 、 Pose Estimation 、 Action Segmentation
AVA
JHMDB
动作分割
为对一段未剪辑视频进行分段,并对每一段视频分配预先定于的动作标签。
动作分割是高水平视频理解中具有挑战性的问题。在其最简单的形式中,动作分割旨在按时间分割一个临时未修剪的视频,并用预定义的动作标签标记每个分割部分。动作分割的结果可以进一步用作各种应用程序的输入,如视频到文本和动作定位。

三个最常用的action segmentation数据集的比较(来源于Yazan Abu Farha, & Juergen Gall (2019). MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation arXiv: Computer Vision and Pattern Recognition.):

Breakfast (The Breakfast Actions Dataset)
相关链接:Action Segmentation数据集介绍——Breakfast
早餐动作数据集包括与早餐准备相关的10个动作,由18个不同厨房的52个不同的人执行。该数据集是最大的完全带注释的数据集之一。这些动作是在“自然环境下”记录的,而不是在单一的受控实验室环境中记录的。它由超过77小时(>4万帧)的录像组成。为了减少数据总量,所有视频都被下采样到320×240像素的分辨率,帧速率为15 fps
Hilde Kuehne, Ali Bilgin Arslan, & Thomas Serre (2014). The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities Computer Vision and Pattern Recognition.

可用于:Action Segmentation
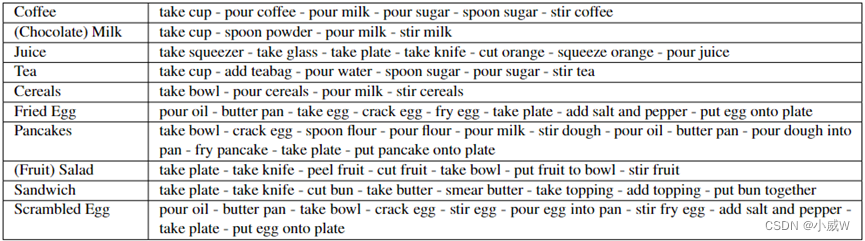
GTEA (Georgia Tech Egocentric Activity)
佐治亚理工学院以自我为中心的活动(GTEA)数据集包含七种类型的日常活动,如做三明治、茶或咖啡。每个活动由4个不同的人完成,总共28个视频。对于每个视频,大约有20个精细的动作实例,如拿面包,倒番茄酱,大约一分钟。
Alireza Fathi, Xiaofeng Ren, & James M. Rehg (2011). Learning to recognize objects in egocentric activities Computer Vision and Pattern Recognition.
可用于:Action Segmentation; Action Localization
50 Salads
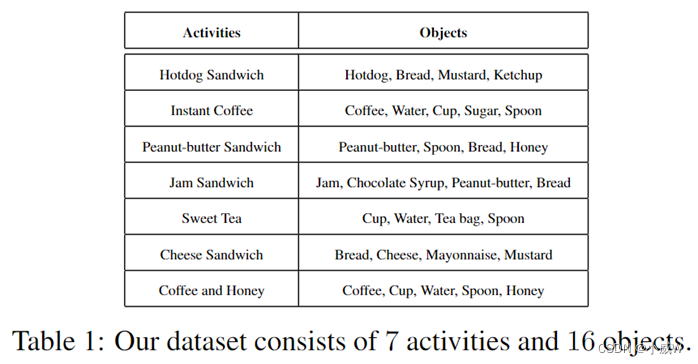
活动识别研究的重点已经从区分全身运动模式转向识别多个实体的复杂交互。操纵手势——以手、工具和可操作物体之间的交互为特征——经常出现在食品制备、制造和装配任务中,并有各种应用,包括情景支持、自动监督和技能评估。为了刺激对识别操纵手势的研究,我们介绍了50 Salads数据集。它捕捉到25个人每人准备两份混合沙拉,包含超过4小时的带注释的加速度计(accelerometer)和RGB-D视频数据。50 salad数据集包括详细的注释、多种传感器类型和每个参与者的两个序列,可用于活动识别、活动发现、序列分析、进度跟踪、传感器融合、迁移学习和用户适应等领域的研究。
可用于:Action Segmentation 、

JIGSAWS (JHU-ISI Gesture and Skill Assessment Working Set)
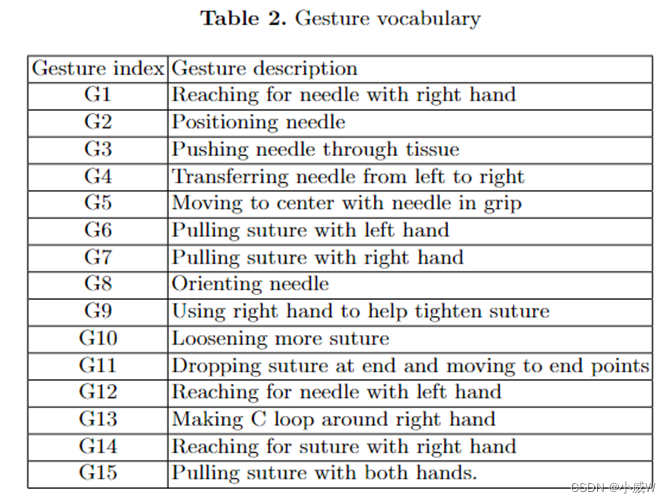
JHU-ISI手势和技能评估工作集(JIGSAWS)是用于人体运动建模的外科活动数据集。数据是通过约翰霍普金斯大学(JHU)和Intuitive Surgical, Inc. (Sunnyvale, CA. ISI)在irb批准的研究中合作收集的。该数据集的发布已得到约翰霍普金斯大学IRB的批准。数据集是使用达芬奇手术系统(da Vinci Surgical System)从八位不同技能水平的外科医生那里获取的,他们在台式模型上重复执行三种基本手术任务:缝合、打结和穿针,这是大多数外科技能培训课程的标准组成部分。JIGSAWS数据集由三个部分组成:
运动学数据:描述机械手运动的笛卡尔位置、方向、速度、角速度和夹持角。
视频数据:内窥镜相机拍摄的立体视频。JIGSAWS任务的示例视频可从官方网页下载。
手动注释包括:
手势(原子手术活动段标签)。
技能(使用改进的客观结构化技术技能评估的全球评分)。
实验设置:一个标准化的交叉验证实验设置,可用于评估自动手术手势识别和技能评估方法。
Yixin Gao, S Swaroop Vedula, Carol E Reiley, Narges Ahmidi, Balakrishnan Varadarajan, Henry C Lin, Lingling Tao, Luca Zappella, Benjamín Béjar, David D Yuh, Chi Chiung, Grace Chen, René Vidal, Sanjeev Khudanpur, & Gregory D Hager (2023). JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling
可用于: Action Segmentation 、 Action Quality Assessment 、 Surgical Skills Sevaluation

COIN
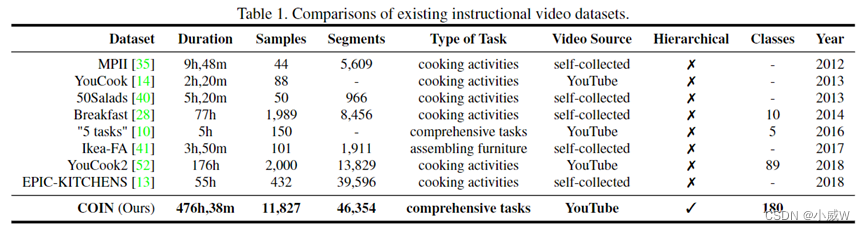
COIN数据集(用于综合教学视频分析的大规模数据集)由11,827个视频组成,涉及与我们日常生活相关的12个领域(例如,车辆,小工具等)中的180个不同任务。这些视频都是从YouTube上收集的。视频的平均长度是2.36分钟。每个视频被标记为3.91个步骤片段,每个片段平均持续14.91秒。该数据集总共包含476小时的视频,其中有46,354个带注释的片段。
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, & Jie Zhou (2019). COIN: A Large-scale Dataset for Comprehensive Instructional Video Analysis Cornell University - arXiv.
可用于:Action Segmentation
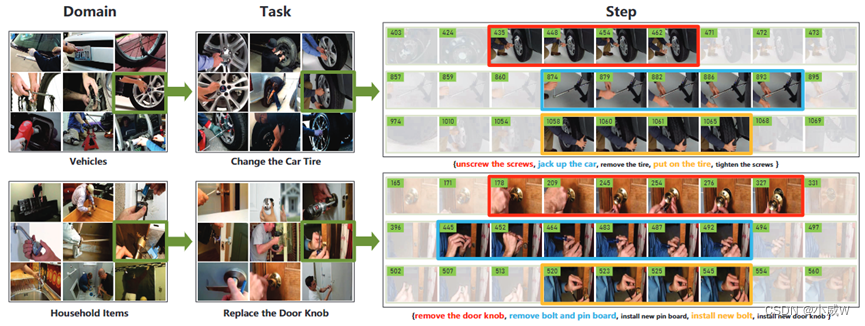
COIN 数据集 很大。
Assembly101
Assembly101是一个新的程序性活动数据集,包含4321个人们组装和拆卸101辆“可拆卸”玩具汽车的视频。参与者在没有固定指令的情况下工作,在动作顺序、错误和纠正方面的序列具有丰富而自然的变化。Assembly101是第一个多视图动作数据集,同时有静态(8)和自我中心(4)记录。序列标注了超过100K粗粒度和1M细粒度的动作片段,以及18M 3D手部姿势。我们以三个动作理解任务为基准:识别、预测和时间分割。此外,我们提出了一种检测错误的新任务。独特的记录格式和丰富的注释集允许我们研究新玩具的泛化,跨视图传输,长尾分布,以及姿势与外观。我们设想Assembly101将成为研究各种活动理解问题的新挑战。
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, & Angela Yao (2023). Assembly101: A Large-Scale Multi-View Video Dataset for Understanding Procedural Activities
可用于:3D Action Recognition 、 Action Segmentation 、 Action Anticipation

MPII Cooking 2 Dataset
为活动识别提供详细注释的数据集。
Marcus Rohrbach, Anna Rohrbach, Michaela Regneri, Sikandar Amin, Mykhaylo Andriluka, Manfred Pinkal, & Bernt Schiele (2016). Recognizing Fine-Grained and Composite Activities Using Hand-Centric Features and Script Data
可以用于:Action Segmentation
动作解析
在一段动作视频中,定义一连串子动作(sub-action),动作解析即定位这些子动作的开始帧。该任务可更好的进行动作间和动作内部的视频理解。
TAPOS
TAPOS是在体育视频上开发的一个新的数据集,该数据集带有子动作的手动注释,并在此基础上进行了时间动作解析的研究。体育活动通常由多个子动作组成,对这种时间结构的认识有利于动作识别。
TAPOS总共包含16,294个有效实例,涉及21个操作类。这些实例的平均持续时间为9.4秒。每个类中的实例数量是不同的,其中最大的跳高类有超过1600个实例,最小的横梁类有200个实例。子动作的平均数量也因类而异,双杠平均有9个子动作,跳远平均有3个子动作。所有实例都分为训练集、验证集和测试集,大小分别为13094、1790和1763。
Dian Shao, Yue Zhao, Bo Dai, & Dahua Lin (2020). Intra- and Inter-Action Understanding via Temporal Action Parsing Cornell University - arXiv.
还没有形成 benchmark

Home Action Genome
家庭行动基因组是一个大规模的室内日常活动的多视角视频数据库。每一个活动都被同步的多视角摄像机捕捉到,包括以自我为中心的视角。有30个小时的视频,有70种日常活动和453种原子活动。
Nishant Rai, Haofeng Chen, Jingwei Ji, Rishi Desai, Kazuki Kozuka, Shun Ishizaka, Ehsan Adeli, & Juan Carlos Niebles (2021). Home Action Genome: Cooperative Compositional Action Understanding… arXiv: Computer Vision and Pattern Recognition.
可用于:动作识别

