
- 1Git——工作区管理_git双工作区
- 2都2024了,还在纠结图片识别?fastapi+streamlit+langchain给你答案!_streamlit fastapi
- 3基于python爬虫下载网站在线视频
- 4热备份路由器协议 —— HSRP_hsrp ping
- 53.1-RNN存在的问题以及LSTM的结构
- 6Bogo排序,真是巨NB啊_bogo sort
- 7hadoop伪分布式环境搭建,完整的详细步骤_伪分布式安装步骤
- 8【消息队列 MQ 专栏】消息队列之 RabbitMQ —— 集群原理与搭建篇
- 9机器翻译 深度学习预处理实战(中英文互译)一_深度学习做机器翻译
- 10c语言运行excel中vba程序,Excel 中如何运行 VBA 代码?
Spark streaming基于kafka 以Receiver方式获取数据 原理和案例实战_kafkareceiver excutor
赞
踩
本博文讲述的内容主要包括:
1,SparkStreaming on Kafka Receiver 工作原理机制
2,SparkStreaming on Kafka Receiver案例实战
3,SparkStreaming on Kafka Receiver源码解析
一:SparkStreaming on Kafka Receiver 简介:
1、Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以从代码中简单理解成Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据了。
2、基于Receiver的方式:
这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。
然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
补充说明:
(1)、Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以,在KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。
(2)、可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
(3)、如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
SparkStreaming on Kafka Receiver 工作原理图如下所示:
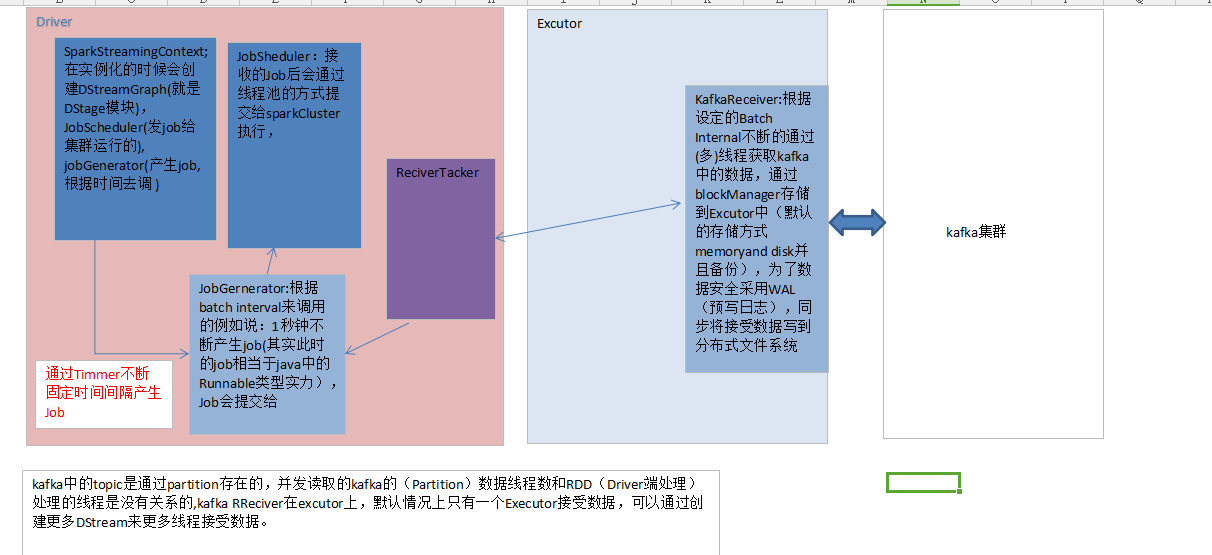
二、SparkStreaming on Kafka Receiver案例实战:
1、在进行SparkStreaming on Kafka Receiver案例的环境前提:
(1)spark 安装成功,spark 1.6.0(local方式除外)
(2)zookeeper 安装成功
(3)kafka 安装成功
(4)启动集群和zookeeper和kafka
在这里我采用local的方式进行试验,代码如下:
- public class SparkStreamingOnKafkaReceiver {
-
- public static void main(String[] args) {
- /* 第一步:配置SparkConf:
- 1,至少两条线程因为Spark Streaming应用程序在运行的时候至少有一条线程用于
- 不断地循环接受程序,并且至少有一条线程用于处理接受的数据(否则的话有线程用于处理数据,随着时间的推移内存和磁盘都会
- 不堪重负)
- 2,对于集群而言,每个Executor一般肯定不止一个线程,那对于处理SparkStreaming
- 应用程序而言,每个Executor一般分配多少Core比较合适?根据我们过去的经验,5个左右的Core是最佳的(一个段子分配为奇数个Core表现最佳,例如3个,5个,7个Core等)
- */
- SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparStreamingOnKafkaReceiver");
- // SparkConf conf = new //SparkConf().setMaster("spark://Master:7077").setAppName(" //SparStreamingOnKafkaReceiver");
- /* 第二步:创建SparkStreamingContext,
- 1,这个是SparkStreaming应用春香所有功能的起始点和程序调度的核心
- SparkStreamingContext的构建可以基于SparkConf参数也可以基于持久化的SparkStreamingContext的内容
- // 来恢复过来(典型的场景是Driver崩溃后重新启动,由于SparkStreaming具有连续7*24
- 小时不间断运行的特征,所以需要Driver重新启动后继续上一次的状态,此时的状态恢复需要基于曾经的Checkpoint))
- 2,在一个Sparkstreaming 应用程序中可以创建若干个SparkStreaming对象,使用下一个SparkStreaming
- 之前需要把前面正在运行的SparkStreamingContext对象关闭掉,由此,我们获取一个重大的启发
- 我们获得一个重大的启发SparkStreaming也只是SparkCore上的一个应用程序而已,只不过SparkStreaming框架想运行的话需要
- */ spark工程师写业务逻辑
- @SuppressWarnings("resource")
- JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(10));
-
- /* 第三步:创建SparkStreaming输入数据来源input Stream
- 1,数据输入来源可以基于File,HDFS,Flume,Kafka-socket等
- 2,在这里我们指定数据来源于网络Socket端口,SparkStreaming连接上该端口并在运行时候一直监听
- 该端口的数据(当然该端口服务首先必须存在,并且在后续会根据业务需要不断地数据产生当然对于SparkStreaming
- 应用程序的而言,有无数据其处理流程都是一样的);
- 3,如果经常在每个5秒钟没有数据的话不断地启动空的Job其实会造成调度资源的浪费,因为并没有数据发生计算
- 所以实际的企业级生成环境的代码在具体提交Job前会判断是否有数据,如果没有的话就不再提交数据
- 在本案例中具体参数含义:
- 第一个参数是StreamingContext实例,
- 第二个参数是zookeeper集群信息(接受Kafka数据的时候会从zookeeper中获取Offset等元数据信息)
- 第三个参数是Consumer Group
- */ 第四个参数是消费的Topic以及并发读取Topic中Partition的线程数
-
- Map<String,Integer> topicConsumerConcurrency = new HashMap<String,Integer>();
- topicConsumerConcurrency.put("HelloKafakaFromSparkStreaming",1);//这里2个的话是指2个接受的线程
-
- JavaPairReceiverInputDStream<String, String> lines = KafkaUtils.createStream(jsc,
- "Master:2181,Worker1:2181,Worker2:2181",
- "MyFirstConsumerGrou",
- topicConsumerConcurrency);
- /*
- * 第四步:接下来就像对于RDD编程一样,基于DStream进行编程!!!原因是Dstream是RDD产生的模板(或者说类
- * ),在SparkStreaming发生计算前,其实质是把每个Batch的Dstream的操作翻译成RDD的操作
- * 对初始的DTStream进行Transformation级别处理
- * */
- JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>,String>(){ //如果是Scala,由于SAM装换,可以写成val words = lines.flatMap{line => line.split(" ")}
-
- @Override
- public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
-
- return Arrays.asList(tuple._2.split(" "));//将其变成Iterable的子类
- }
- });
- // 第四步:对初始DStream进行Transformation级别操作
- //在单词拆分的基础上对每个单词进行实例计数为1,也就是word => (word ,1 )
- JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
-
- @Override
- public Tuple2<String, Integer> call(String word) throws Exception {
- return new Tuple2<String, Integer>(word,1);
- }
-
- });
- //对每个单词事例技术为1的基础上对每个单词在文件中出现的总次数
-
- JavaPairDStream<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){
-
- /**
- *
- */
- private static final long serialVersionUID = 1L;
-
- @Override
- public Integer call(Integer v1, Integer v2) throws Exception {
- // TODO Auto-generated method stub
- return v1 + v2;
- }
- });
- /*
- * 此处的print并不会直接出发Job的支持,因为现在一切都是在SparkStreaming的框架控制之下的
- * 对于spark而言具体是否触发真正的JOb运行是基于设置的Duration时间间隔的
- * 诸位一定要注意的是Spark Streaming应用程序要想执行具体的Job,对DStream就必须有output Stream操作
- * output Stream有很多类型的函数触发,类print,savaAsTextFile,scaAsHadoopFiles等
- * 其实最为重要的一个方法是foreachRDD,因为SparkStreaming处理的结果一般都会放在Redis,DB
- * DashBoard等上面,foreach主要就是用来完成这些功能的,而且可以自定义具体的数据放在哪里!!!
- * */
- wordsCount.print();
-
- // SparkStreaming 执行引擎也就是Driver开始运行,Driver启动的时候位于一条新线程中的,当然
- // 其内部有消息接受应用程序本身或者Executor中的消息
- jsc.start();
- jsc.close();
- }
-
-
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100

2、SparkStreaming on Kafka Receiver运行在集群上的步骤及结果:
- 1,首先启动zookeeper服务:
-
-
- 2,接下来启动Kafka服务
-
-
- 3,在eclipse上观察结果:
三:SparkStreaming on Kafka Receiver源码解析
1,首先看一下KafkaUtils(包含zookeeper的配置等等):
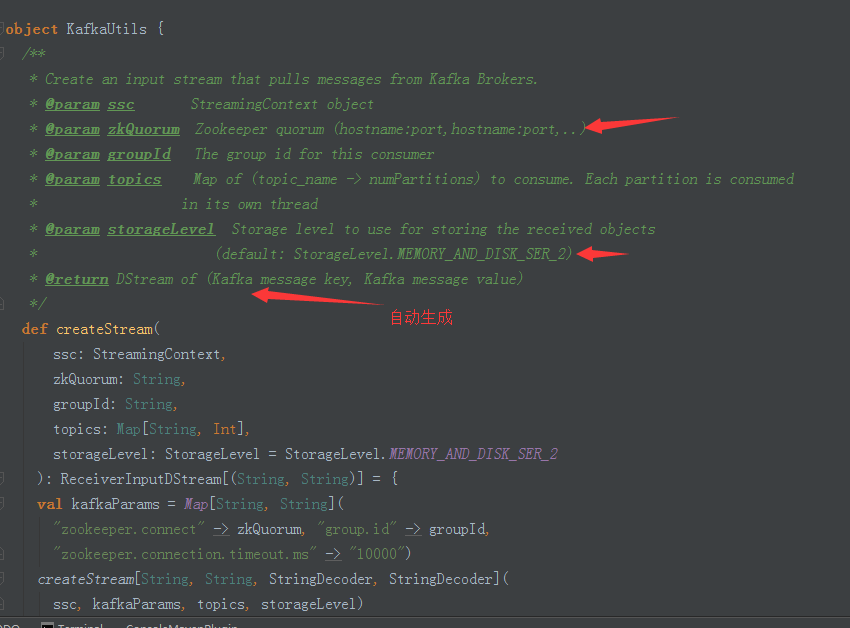
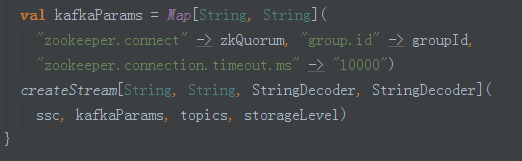
2、在这里创建了KafkaInputDStream:

3、这里证明KafkaInputStream为consumer
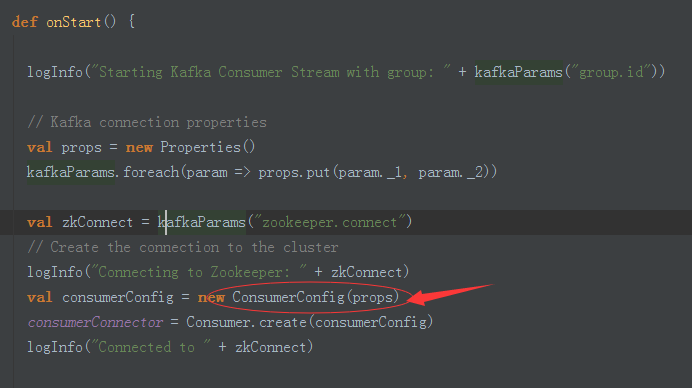
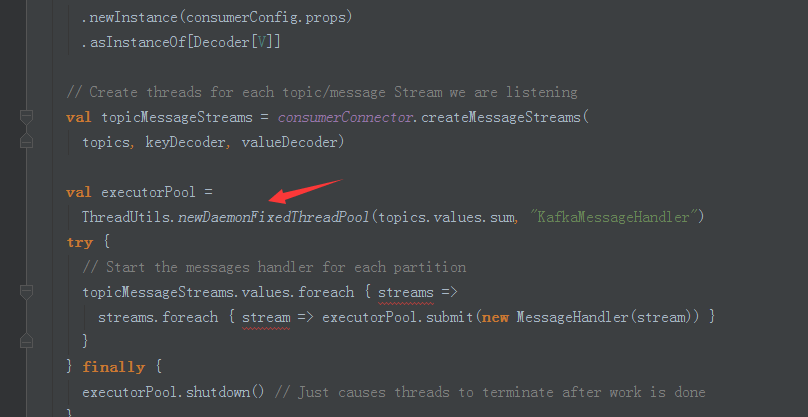
4、在这里拥有线程池(处理topic)
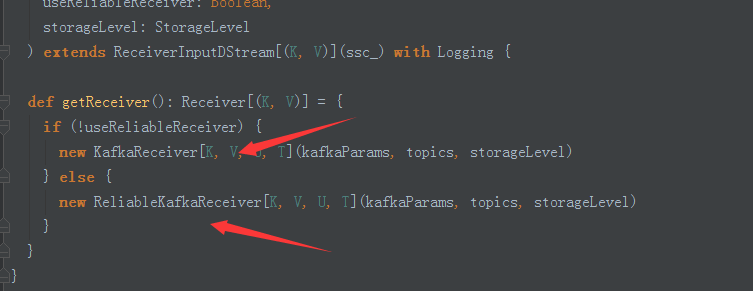
5,不同的接受方式(第一个为wal方式)
补充说明:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。
博文内容源自DT大数据梦工厂Spark课程。相关课程内容视频可以参考:
百度网盘链接:http://pan.baidu.com/s/1slvODe1(如果链接失效或需要后续的更多资源,请联系QQ460507491或者微信号:DT1219477246 获取上述资料)。

