
- 1Docker入门(清晰认识)
- 2Spring Boot整合actuator实现监控管理
- 3Anaconda3安装VSCode提示Please make sure you are connected to the internet!
- 4论文阅读 基于机器学习文本处理的PHP和JSP Web shell检测系统(上海交大)_php word2vec
- 5电池的各类SOC估计方法存在的问题_开路电压soc的缺点
- 6ArcGIS Maps SDK for JavaScript:鼠标进入面要素时改变鼠标指针样式,离开时恢复
- 7【活动感想】筑梦之旅·AI共创工坊 workshop 会议回顾_共创活动workshop
- 8Java实现宿舍管理系统、基于java、JDBC、GUI、MySql、eclipse(含源文件/综合项目/数据库)
- 9个性化定制标注工具labelimg_labelimg软件
- 102024最新最全面的自动化测试学习步骤及路线(超详细)
最全Hive 整合 Spark 全教程 (Hive on Spark),软件测试开发面试问题
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
#### 配置集群
1)核心配置文件
配置core-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> fs.defaultFS hdfs://Bigdata00:9820 hadoop.tmp.dir /opt/module/hadoop-3.1.3/data<property>
<name>hadoop.http.staticuser.user</name>
<value>luanhao</value>
- 1
- 2
- 3
<property>
<name>hadoop.proxyuser.luanhao.hosts</name>
<value>*</value>
- 1
- 2
- 3
2)HDFS配置文件
配置hdfs-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Bigdata00:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)YARN配置文件
配置yarn-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Bigdata00</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
<!-- yarn容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4)MapReduce配置文件
配置mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5)配置workers
- 1
- 2
- 3
- 4
- 5
Bigdata00
6)配置hadoop-env.sh
- 1
- 2
- 3
- 4
- 5
export JAVA_HOME=/opt/module/jdk1.8.0_212
#### 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
配置mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
#### 配置日志的聚集 日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。 日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。 注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。 开启日志聚集功能具体步骤如下: 配置yarn-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
#### 启动集群
(1)如果集群是第一次启动,需要在Bigdata00节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[luanhao@Bigdata00 hadoop-3.1.3]$ bin/hdfs namenode -format
(2)启动HDFS
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了ResourceManager的节点启动YARN
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 hadoop-3.1.3]$ sbin/start-yarn.sh
(4)Web端查看HDFS的Web页面:<http://bigdata00:9870> 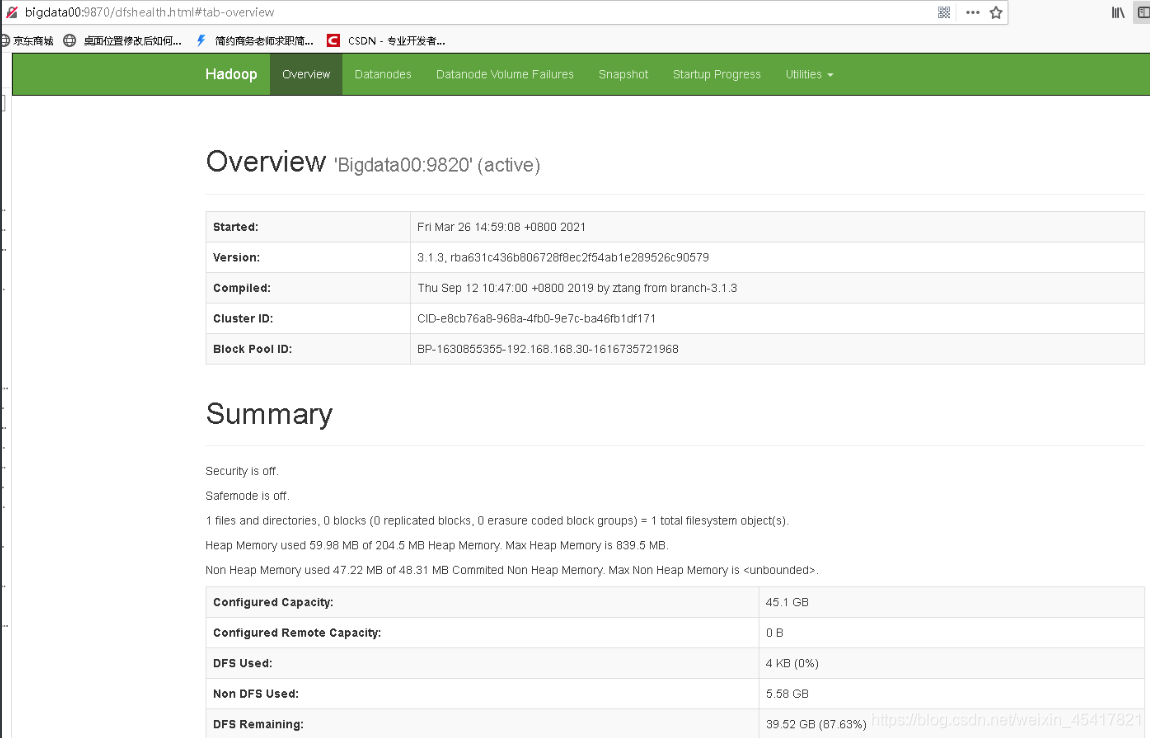 (5)Web端查看SecondaryNameNode :<http://bigdata00:9868/status.html> (单机模式下面什么都没有)  (6)Web端查看ResourceManager :<http://bigdata00:8088/cluster> 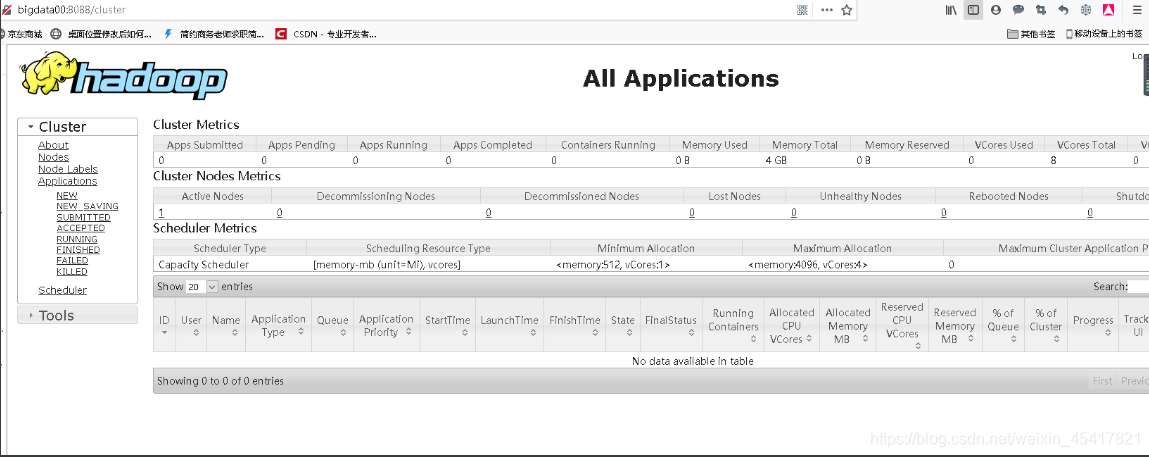 #### LZO压缩配置 1)将编译好后的 hadoop-lzo-0.4.20.jar 放入 hadoop-3.1.3/share/hadoop/common/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
[luanhao@Bigdata00 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[luanhao@Bigdata00 common]$ ls
hadoop-lzo-0.4.20.jar
2)core-site.xml 增加配置支持 LZO 压缩
- 1
- 2
- 3
- 4
- 5
#### Hadoop 3.x 端口号 总结 Hadoop 3.x后,应用的端口有所调整,如下: | 分类 | 应用 | Haddop 2.x | Haddop 3.x | | --- | --- | --- | --- | | NNPorts | Namenode | 8020 | 9820 | | NNPorts | NN HTTP UI | 50070 | 9870 | | NNPorts | NN HTTPS UI | 50470 | 9871 | | SNN ports | SNN HTTP | 50091 | 9869 | | SNN ports | SNN HTTP UI | 50090 | 9868 | | DN ports | DN IPC | 50020 | 9867 | | DN ports | DN | 50010 | 9866 | | DN ports | DN HTTP UI | 50075 | 9864 | | DN ports | Namenode | 50475 | 9865 | | YARN ports | YARN UI | 8088 | 8088 | ### MySQL准备 1)卸载自带的 Mysql-libs(如果之前安装过 mysql,要全都卸载掉)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
[luanhao@Bigdata00 software]$ rpm -qa | grep -i -E mysql|mariadb | xargs -n1 sudo rpm -e --nodeps
2)安装 **mysql** **依赖**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
[luanhao@Bigdata00 software]$ sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
[luanhao@Bigdata00 software]$ sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
3)安装 **mysql-client**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
4)安装 **mysql-server**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
5)启动 **mysql**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo systemctl start mysqld
6)查看 **mysql** **密码**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo cat /var/log/mysqld.log | grep password
配置只要是 root 用户+密码,在任何主机上都能登录 MySQL 数据库。
7)用刚刚查到的密码进入**mysql**(如果报错,给密码加单引号)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[luanhao@Bigdata00 software]$ mysql -uroot -p ‘password’
8)设置复杂密码(由于 **mysql** **密码策略,此密码必须足够复杂**)
- 1
- 2
- 3
- 4
- 5
mysql> set password=password(“Qs23=zs32”);
9)更改 **mysql** **密码策略**
- 1
- 2
- 3
- 4
- 5
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
10)设置简单好记的密码
- 1
- 2
- 3
- 4
- 5
mysql> set password=password(“000000”);
11)进入**msyql** **库**
- 1
- 2
- 3
- 4
- 5
mysql> use mysql
**12**)查询 **user** **表**
- 1
- 2
- 3
- 4
- 5
mysql> select user, host from user;
13)修改 **user** **表,把** **Host** **表内容修改为**%
- 1
- 2
- 3
- 4
- 5
mysql> update user set host=“%” where user=“root”;
14)刷新
- 1
- 2
- 3
- 4
- 5
mysql> flush privileges;
15)退出
- 1
- 2
- 3
- 4
- 5
mysql> quit;
### Hive 准备
**1**)把 **apache-hive-3.1.2-bin.tar.gz**上传到 **linux** **的**/opt/software **目录下**
**2**)解压 **apache-hive-3.1.2-bin.tar.gz** **到**/opt/module目录下面
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[luanhao@Bigdata00 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
**3**)修改 **apache-hive-3.1.2-bin.tar.gz** **的名称为** **hive**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
**4**)修改/etc/profile,添加环境变量
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo vim /etc/profile
添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=
P
A
T
H
:
PATH:
PATH:HIVE_HOME/bin
重启 Xshell 对话框或者 source 一下 /etc/profile 文件,使环境变量生效
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ source /etc/profile
5)解决日志 **Jar** **包冲突,进入**/opt/module/hive/lib 目录(有冲突再做)
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 lib]$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
**Hive** **元数据配置到** **MySQL**
**拷贝驱动**
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[luanhao@Bigdata00 lib]$ cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
**配置** **Metastore** **到** **MySQL**
在$HIVE\_HOME/conf 目录下新建 hive-site.xml 文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[luanhao@Bigdata00 conf]$ vim hive-site.xml
添加如下内容
- 1
- 2
- 3
- 4
- 5
**启动** **Hive**
**初始化元数据库**
**1**)登陆**MySQL**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[luanhao@Bigdata00 conf]$ mysql -uroot -p000000
**2**)新建 **Hive** **元数据库**
- 1
- 2
- 3
- 4
- 5
mysql> create database metastore;
mysql> quit;
**3**)初始化 **Hive** **元数据库**
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 conf]$ schematool -initSchema -dbType mysql -verbose
**启动** **hive** **客户端**
**1**)启动 **Hive** **客户端**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[luanhao@Bigdata00 hive]$ bin/hive
**2**)查看一下数据库
- 1
- 2
- 3
- 4
- 5
hive (default)> show databases;
OK
database_name
default
### Spark 准备
(1)Spark 官网下载 jar 包地址:
http://spark.apache.org/downloads.html
(2)上传并解压解压 spark-3.0.0-bin-hadoop3.2.tgz
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
[luanhao@Bigdata00 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[luanhao@Bigdata00 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置 SPARK\_HOME 环境变量
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ sudo vim /etc/profile
添加如下内容
SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=
P
A
T
H
:
PATH:
PATH:SPARK_HOME/bin
source 使其生效
- 1
- 2
- 3
- 4
- 5
[luanhao@Bigdata00 software]$ source /etc/profile
(4)在**hive** **中创建** **spark** **配置文件**    **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化的资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)** ftware]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(3)配置 SPARK_HOME 环境变量
[luanhao@Bigdata00 software]$ sudo vim /etc/profile
添加如下内容
# SPARK\_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK\_HOME/bin
- 1
- 2
- 3
- 4
- 5
- 6
source 使其生效
[luanhao@Bigdata00 software]$ source /etc/profile
- 1
- 2
(4)在hive 中创建 spark 配置文件
[外链图片转存中…(img-94J0mi9A-1715383395086)]
[外链图片转存中…(img-FGvuSOxQ-1715383395087)]
[外链图片转存中…(img-5EaHZqWn-1715383395087)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

