
- 1【调试工具】iperf 工具的使用_iperf用法进行tcp测试
- 2关于PXIE7301万兆网卡的驱动安装方法分享_万兆网卡驱动
- 32024 Java面试题大全(整理版)1000+面试题附答案详解,最全面详细
- 4链接追踪系列-09.spring cloud项目整合elk显示业务日志
- 5基于集成学习算法的天气预测--python (附源码)_基于人工智能在气象预测中的集成与应用的代码
- 6Spring Cloud Alibaba AI:快速体验通义千问大模型问答_通义千问 spring ai
- 7AI网络爬虫-从当当网批量获取图书信息_ai 爬虫 提示词
- 8python-QQ游戏-连连看-秒杀_python qq连连看
- 9Conda的清理(一下少了14G)_conda clean
- 10elasticsearch配置文件详解_cluster.name
分布式文件存储FastDFS(一)初识FastDFS_fdfs 路径如何分配的
赞
踩
一、FastDFS简介
FastDFS是一款开源的、分布式文件系统(Distributed File System),由淘宝开发平台部资深架构师余庆开发。作为一个分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题,特别适合中小文件(建议范围:4KB < file_size <500MB),对以文件为载体的在线服务,如相册网站、视频网站等等具有显著的效果。
二、FastDFS架构
FastDFS由客户端,跟踪服务器和存储服务器构成,基本架构如下图所示。
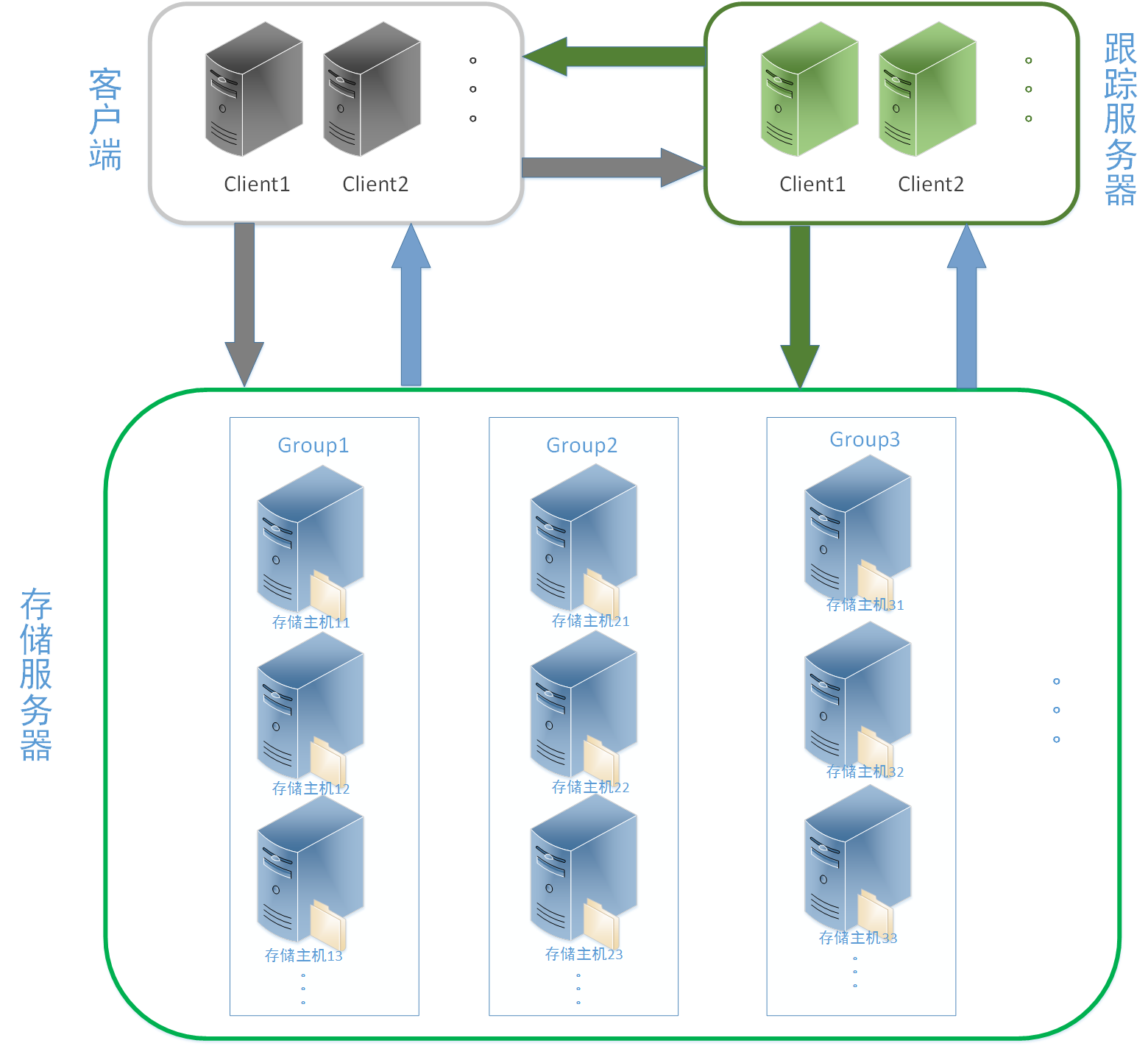
Storage Server
Storage server(后简称storage)以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份,存储空间以group内容量最小的storage为准,所以建议group内的多个storage尽量配置相同,以免造成存储空间的浪费。
以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(group内storage server数量即为该group的副本数),比如将不同应用数据存到不同的group就能隔离应用数据,同时还可根据应用的访问特性来将应用分配到不同的group来做负载均衡;缺点是group的容量受单机存储容量的限制,同时当group内有机器坏掉时,数据恢复只能依赖group内地其他机器,使得恢复时间会很长。
group内每个storage的存储依赖于本地文件系统,storage可配置多个数据存储目录,比如有10块磁盘,分别挂载在/data/disk1-/data/disk10,则可将这10个目录都配置为storage的数据存储目录。
storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
Tracker Server
Tracker是FastDFS的协调者,负责管理所有的storage server和group,每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage serverlist]的映射表。
Tracker需要管理的元信息很少,会全部存储在内存中;另外tracker上的元信息都是由storage汇报的信息生成的,本身不需要持久化任何数据,这样使得tracker非常容易扩展,直接增加tracker机器即可扩展为tracker cluster来服务,cluster里每个tracker之间是完全对等的,所有的tracker都接受stroage的心跳信息,生成元数据信息来提供读写服务。
Client
客户端,作为业务请求的发起方,通过专有接口,使用TCP/IP协议与跟踪器服务器或存储节点进行数据交互。
三、FastDFS的存储策略
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
四、FastDFS的上传过程
FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
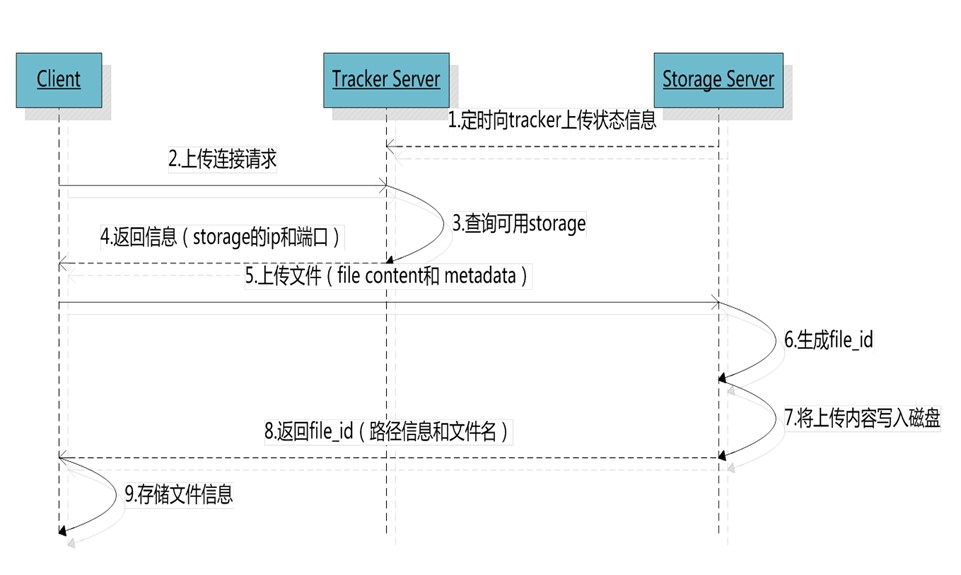
根据前边的讲解,我们知道Storage Server会定期的向Tracker Server发送自己的存储信息。当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,所以客户端上传时可以选择任意一个Tracker。
当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。文件名的格式如下:

五、FastDFS的文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
比如一个group内有A、B、C三个storage server,A向C同步到进度为T1 (T1以前写的文件都已经同步到B上了),B向C同步到时间戳为T2(T2 > T1),tracker接收到这些同步进度信息时,就会进行整理,将最小的那个做为C的同步时间戳,本例中T1即为C的同步时间戳为T1(即所有T1以前写的数据都已经同步到C上了);同理,根据上述规则,tracker会为A、B生成一个同步时间戳。
六、FastDFS的文件下载
客户端uploadfile成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
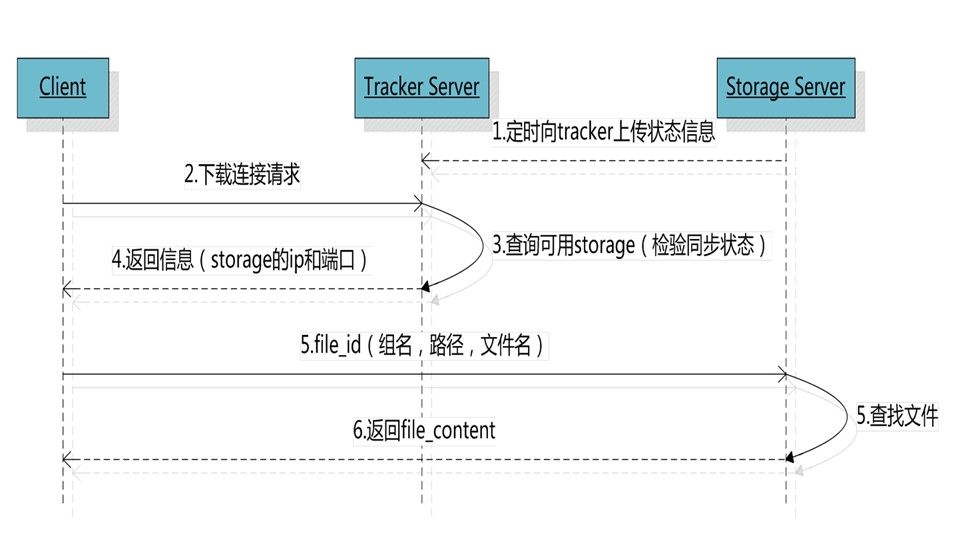
跟upload file一样,在downloadfile时客户端可以选择任意tracker server。tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。
本文是在阅读某大神的文章时进行的整理和摘录,同时加入了自己的一些思考,下面附上大神的链接:http://blog.yunnotes.net/index.php/fastdfs_design/

