
- 1网络安全必会的基础知识(建议收藏)_网络安全基础知识
- 2YOLOv8项目实践——目标检测、实例分割、姿态估计、目标追踪算法原理及模型部署(Python实现带界面)_python yolov8
- 3FPGA-UDP实验_udp数据发送时钟
- 4uniapp开发的跳转到小程序_sweixin.launchminiprogram
- 5【工具推荐】日志查看工具sublime text 和相关的文本行过滤插件【filterLines】_sublime 日志插件
- 6大模型实践:15个大模型提示工程(prompt)技巧_大模型prompt例子
- 7Elasticsearch(ES)集群监控_es监控工具
- 8具身智能有哪些细分研究方向?近400篇论文的综述总结!
- 9【数据结构】二叉树(一)
- 10map相关_map find 只有一个
【论文阅读笔记】Point-Query Quadtree for Crowd Counting, Localization, and More | 用于人群计数、定位和其他的点查询四叉树
赞
踩
【Point-Query Quadtree for Crowd Counting, Localization, and More】用于人群计数、定位和其他的点查询四叉树
pdf地址: https://arxiv.org/abs/2308.13814
- 1
github地址: https://github.com/cxliu0/PET
- 1
本文工作
(1)提供了直观且通用的人群建模:人群计数制定为可分解的点查询过程。点查询设计允许模型接收任意点作为输入,并推断每个点是否是一个人以及它所在的位置。我们的公式自然适合不同的人群相关任务,例如完全监督的人群计数和定位、部分注释学习和点注释细化
(2)点查询四叉树:主要优点是它允许数据相关的分裂,必要时,一个查询点可以分割成多个新的查询点,从而实现稀疏区域和密集区域的动态处理。基于四叉树,我们实例化一个Point quEry Transformer(PET)来实现可分解的点查询。
(3)PET 的另一个关键要素是渐进式矩形窗口注意力,其中查询过程是在局部窗口内执行的,而不是以渐进的方式在整个图像中执行,以实现有效的推理。
一、摘要
我们证明人群计数可以被视为可分解的点查询过程。该公式允许任意点作为输入,并共同推理这些点是否拥挤以及它们所在的位置。查询处理提出了关于必要查询点的数量的根本问题:太少意味着低估,太多会增加计算开销。为了解决这个困境,我们引入了一种可分解的结构,即点查询四叉树,并提出了一种新的计数模型Point quEry Transformer (PET)
二、引言
 图 1:现有技术与我们的点查询计数范式的比较。与 ( a ) 现有技术相比,我们将任意点视为输入,并推理每个点是否是一个人和人所在位置。我们设计了( b )点查询四叉树来处理具有自适应树分裂的密集人群。查询设计使 PET 成为一种直观且通用的方法,使( c )各种应用,例如全监督人群计数和定位、部分注释学习和点注释细化。
图 1:现有技术与我们的点查询计数范式的比较。与 ( a ) 现有技术相比,我们将任意点视为输入,并推理每个点是否是一个人和人所在位置。我们设计了( b )点查询四叉树来处理具有自适应树分裂的密集人群。查询设计使 PET 成为一种直观且通用的方法,使( c )各种应用,例如全监督人群计数和定位、部分注释学习和点注释细化。
人群计数旨在从图像中估计人群的数量。现有的方法通常通过学习密度图等替代目标来解决计数,其中计数是通过集成推断的密度图获得的。尽管有效,但它们不能提供对人群的直观理解,即没有提供实例级信息,这阻碍了高级人群分析。一些方法不是仅仅从图像中预测计数值,而是专注于通过头部边界框[21,26]或单个头部点[3,17,29]来估计人群的细粒度信息。前者将人群计数转换为头部检测问题。然而,由于缺乏框信息,检测精度在理论上并不能保证。相比之下,后者直接输出头部点,绕过边界框估计的容易出错阶段。然而,他们通常需要后处理 [3, 17] 来获得每个人的位置。因此,拥挤的场景可能会导致计数或定位失败。此外,现有技术通常处理特定的计数任务或学习范式;每个都需要定制的设计。这阻碍了它们在不同应用程序或任务中的使用。例如,完全监督的计数模型通常不能很好地解决半监督人群计数[39]。
在这项工作中,我们将人群计数制定为可分解的点查询过程。点查询设计允许模型接收任意点作为输入,并推理每个点是否是一个人及其所在位置。这种设计的一个吸引人的特性是它提供了对人群的直观和通用的建模。具体来说,直觉是每个查询点在物理上对应于一个人或背景。查询点的任意性意味着输入点的位置和数量都是可控制的。因此,通过简单地调整输入,我们的公式自然适合不同的人群相关任务,例如全监督人群计数和定位、部分注释学习 [39] 和点注释细化(图 1c)。
然而,由于输入图像可能包含任意数量的人群,因此预定义查询点的数量并非易事。在实践中,太少的点会导致低估,而太多的点会产生很大的计算成本。为了解决这个陷阱,我们提出了一个可分解的结构——点查询四叉树。四叉树的主要优点是它允许依赖于数据的分裂,其中一个查询点在必要时可以分为几个新的查询点,从而实现稀疏和密集区域的动态处理。基于四叉树,我们实例化一个点quEry Transformer (PET)来实现可分解的点查询,如图1b所示。PET的另一个关键因素是渐进式矩形窗口注意,其中查询过程在本地窗口内执行,而不是整个图像以渐进的方式进行有效的推理。
在四个人群计数基准上的广泛实验表明,PET 表现出许多吸引人的特性:
i) 通用:PET 适用于几个与人群相关的任务,例如全监督人群计数和定位、部分注释学习和点注释细化;
ii) 有效:PET 报告针对最近的方法的最新人群计数和定位性能。特别是,它在ShanghaiTech PartA[42]数据集上实现了49.34的平均绝对误差(MAE);
iii)直观:PET可以继续与对象或背景物理对应的点查询,并输出可解释的点。
这项工作的贡献包括:
• 我们表明,可分解点查询可以成为潜在的统一人群相关任务的通用人群建模思想。
• 我们提出了 PET,一种用于人群计数的点查询 Transformer,其特点是点查询四叉树和渐进矩形窗口注意力。
三、相关方法
我们根据它们是否生成人群实例级信息(即头部边界框或头部点)来划分现有工作。此外,我们还讨论了基于变压器的方法的最新进展。
密度图计数。
大多数最先进的方法使用密度图[11]作为代理学习目标,其中计数值是通过集成预测的密度图来计算的。这些方法从改进损失函数[24,32,34]、处理透视效应[1,40,41]和利用上下文信息[20]等方面推进人群计数的进展。为了缓解密度图与计数值之间的不一致,另一项工作采用局部计数范式[18,19,37,38],将patch的计数值分类为离散的bin。尽管取得了成功,但基于密度图的方法通常不提供实例级预测。相比之下,我们的方法可以以一个点输出每个人的位置,从而能够更直观地理解人群。
定位计数。
另一种替代方法不是预测密度图等中间表示,而是同时估计人群的数量和位置。近年来,这种对人群的细粒度估计引起了极大的兴趣。例如,最近的一些方法 [13, 21, 26] 将计数转换为头部检测问题,预测头部的边界框。然而,从弱点监督生成的伪地真盒容易出错,因此,它不仅阻碍了模型训练,而且会导致框预测不准确。除了边界框之外,几种方法 [3, 17, 29] 直接估计头部点。然而,这些方法通常需要启发式后处理来识别个人人群。与以前的方法不同,我们的方法接收任意点作为输入,并通过显式建模点与其周围环境之间的关系来预测人群。它简化了预测过程,并支持在其他人群相关任务中的应用。
基于 Transformer 的计数。
最近视觉转换器 [2, 5] 的成功引发了它们在各种视觉任务中的应用。最近,许多工作 [6, 14, 15, 30, 31, 36] 致力于将 Transformer 架构部署到人群计数中。由于变压器具有较强的表示能力,现有的方法主要集中在开发一个强大的变压器主干进行特征提取,并将其与预测模块相结合来估计计数值。相比之下,我们提出了一种新的人群计数公式,并使用定制的点查询转换器对其进行实例化。
四、本文方法:通过查询点计算人群
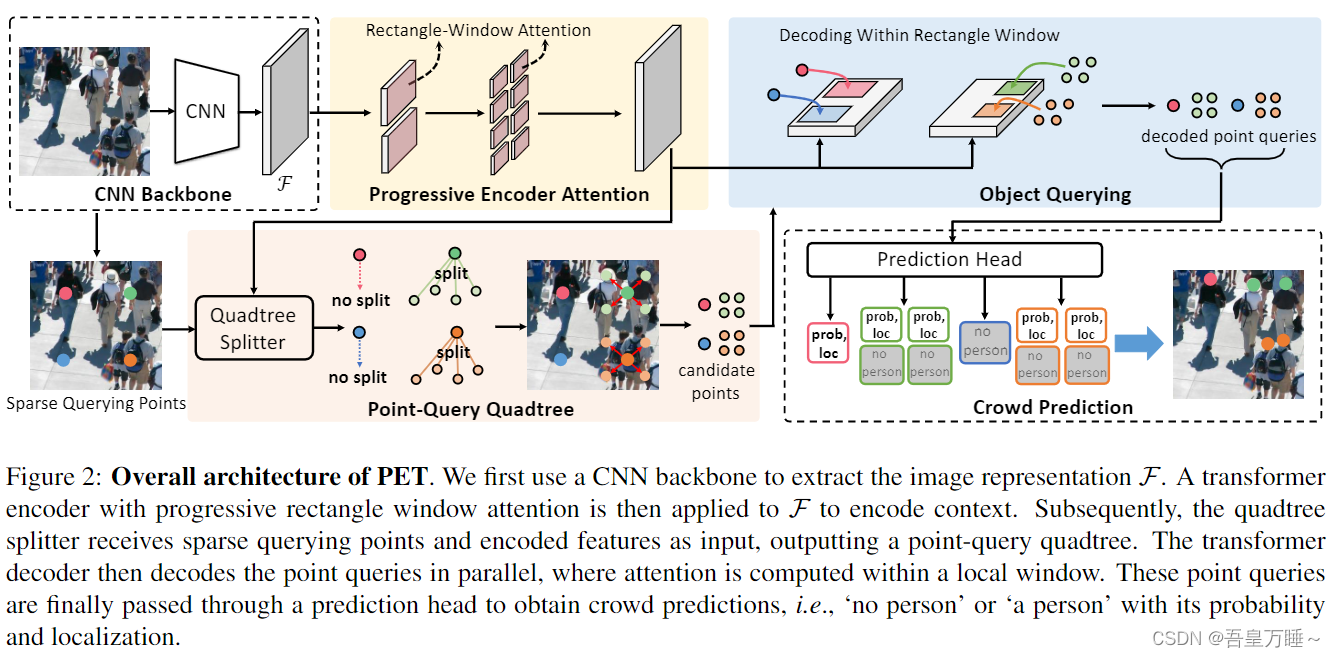 图 2:PET 的整体架构。我们首先使用 CNN 主干提取图像特征 F。然后将具有渐进矩形窗口注意的变压器编码器应用于 F 以编码上下文。随后,四叉树拆分器接收稀疏查询点和编码特征作为输入,输出点查询四叉树。然后变压器解码器并行解码点查询,其中注意力是在局部窗口内计算的。这些点查询最终通过一个预测头来获得人群预测,即“没有人”或“一个人”及其概率和定位。
图 2:PET 的整体架构。我们首先使用 CNN 主干提取图像特征 F。然后将具有渐进矩形窗口注意的变压器编码器应用于 F 以编码上下文。随后,四叉树拆分器接收稀疏查询点和编码特征作为输入,输出点查询四叉树。然后变压器解码器并行解码点查询,其中注意力是在局部窗口内计算的。这些点查询最终通过一个预测头来获得人群预测,即“没有人”或“一个人”及其概率和定位。
3.1. 问题表述
在这项工作中,我们将人群计数制定为可分解的点查询过程。在查询过程中,稀疏点在必要时可以拆分为新的点,以便自适应地处理密集区域。通过这种方式,可以通过查询这些(拆分)输入点来实现计数。
我们用定制的Point quEry TRansformer (PET) 体现了这个公式。在 PET 中,两个成分是必不可少的:
i) 点查询四叉树的设计;
ii) 渐进式矩形窗口注意机制。前者自适应地生成查询点来解决密集的人群预测,后者提高了效率。
3.2.架构概述
PET的整体架构如图2所示。它包括CNN主干、高效的编码器-解码器转换器、点查询四叉树和预测头四个组件。
给定一个输入图像,CNN 主干首先提取图像特征,输出特征 F ∈ Rh×w×c。F 中的每个空间元素都被视为一个标记,这会导致 h × w 标记。然后,这些标记通过变压器编码器传递,该编码器通过渐进式矩形窗口注意实现,以编码上下文信息。这种设计背后的基本原理是效率,因为大量的令牌使得全局注意力的计算成本很高,尤其是对于高分辨率图像。
为了获得对人群的实例级理解,我们构建了一个点查询四叉树来查询人群。点查询四叉树允许在拥塞区域进行依赖于数据的拆分,以便可以自适应地处理密集和稀疏场景。通过接收点查询四叉树和编码特征作为输入,变压器解码器在图像上下文的指导下推理点查询之间的关系,然后并行解码点查询。这些解码的点查询最终通过一个预测头来获取人群预测。
3.3.点查询四叉树
点查询的设计对我们的公式的成功至关重要。考虑到输入图像可能包含任意数量的人群,使用固定数量的查询(如对象检测 [2])是不合理的。为了实现可扩展的人群估计,点查询应该是有意义和灵活的。这产生了三个问题:
1)如何使查询点的数量适应不同的场景;
2)如何表示点查询;
3)如何通过点查询预测人群。我们将它们解决如下。
四叉树构造。
为了使点查询可扩展为稀疏和密集场景,我们提出了一种可分解的结构,称为点查询四叉树。四叉树遵循稀疏到密集的过程,即稀疏查询点首先跨越图像,并自适应地分割成拥挤场景中的密集查询点进行密集人群预测。因此,有必要确定何时拆分稀疏查询点。我们认为拆分过程应该通过检查局部区域来确定,而不是依赖于单个点。因此,我们采用基于区域的四叉树拆分器来构造四叉树。
四叉树分裂。
图 3 说明了点查询四叉树的构建过程。具体地说,我们首先在步幅为K的图像上均匀地设置稀疏查询点,对应于四叉树级别0。然后将四叉树拆分器应用于编码的特征,输出分割映射Ms∈Rh ’ ×w '。Ms中的每个元素表示区域密集的概率,其中1表示密集区域,0表示稀疏区域。最初的密集区域的查询点被分成密集查询点,形成四叉树级别1。这个过程重复,直到达到最大分裂时间L,从而得到L + 1层四叉树。多层四叉树可以通过使用多个四叉树拆分器来预测每一层的拆分图来实现。可以考虑四叉树需要拆分多少次来处理密集区域。在实践中,我们发现拆分一次 (L=1) 通常足以处理人群估计。详细分析请参考补充。
特别是四叉树拆分器由平均池化层和 1×1 卷积层组成,然后是 sigmoid 函数,因此计算成本可以忽略不计。我们在图 4 中展示了四叉树拆分器输出的一些示例,其中红色区域表示需要四叉树拆分的拥塞区域。我们观察到四叉树拆分器可以区分拥塞区域。请注意,分割映射使用 0.5 的阈值进行二值化。
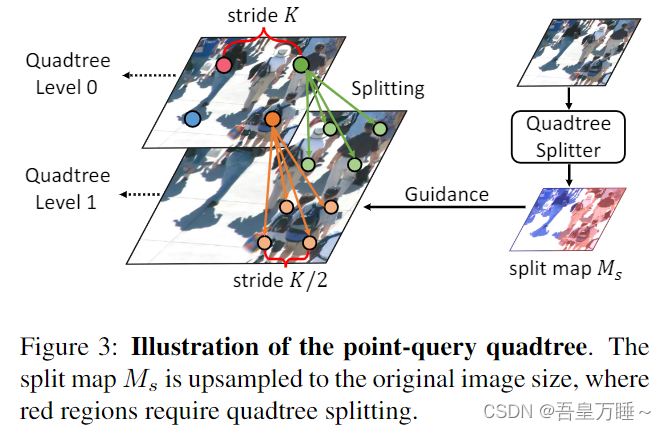
图3:点查询四叉树的说明。将分割映射Ms上采样到原始图像大小,其中红色区域需要四叉树分割。

图 4:拆分图的示例。红色区域表示需要树分裂的拥塞区域。
点查询表示。
给定一个像素位置 (x, y) 的查询点,我们需要将其表示为点查询。我们的直觉告诉我们点查询应该同时包含语义和定位信息。为了对点查询的语义进行编码,我们重新使用了 CNN 特征。从技术上讲,我们将 CNN 特征 F 插值到原始图像大小并对特征向量 Fx,y ∈ R1×1×c 进行采样。对于位置信息,我们采用[2]之后的固定空间位置嵌入。将位置嵌入和 Fx,y 相加以形成点查询表示。
人群预测。
最后一步是通过点查询来预测人群。遵循虚线注释的哲学(每个人一个点),我们通过唯一的点查询来表示每个人。具体来说,我们首先通过变压器解码器传递点查询四叉树以获得解码的表示。然后将预测头应用于解码点查询,输出一组预测人员Q = {qi}N i=1。注意qi由分类概率ci∈[0,1]和归一化像素位置pi = (xi +∆xi, yi +∆yi)组成,其中(xi, yi)为点查询的像素位置,(∆xi,∆yi)为预测偏移量。预测头由具有 ReLU 激活的 MLP 层组成。我们注意到预测头针对不同的图像接收不同数量的查询,因为查询是由点查询四叉树动态生成的。这确保了稀疏和密集的点查询只对相应的区域进行操作,避免了不必要的计算。
3.4.矩形窗口中渐进查询
在这里,我们描述了我们的变压器编码器和解码器的设计。一般来说,我们在矩形窗口内以渐进的方式执行对象查询。
渐进式编码器注意。为了对不同尺度的人群信息进行编码,我们采用了渐进式注意力机制。这个想法是变压器编码器首先检查足够大的区域,然后专注于一个小区域。考虑到透视变化经常出现在人群图像中,我们计算矩形窗口内的注意力。更具体地说,我们设计了一个水平窗口,因为它通常包含比垂直窗口更多的人(图 5)。
 图 5:使用水平窗口的动机。由于透视先验,水平补丁通常包含比垂直补丁更多的人。
图 5:使用水平窗口的动机。由于透视先验,水平补丁通常包含比垂直补丁更多的人。
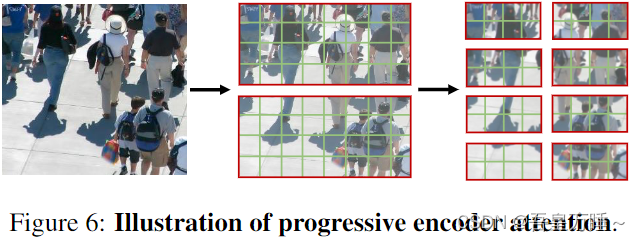 图 6:渐进式编码器注意力的图示。
图 6:渐进式编码器注意力的图示。
渐进式编码器注意的思想如(图6)所示。给定一个输入图像,我们首先在前几个编码器层的相对较大的矩形窗口内计算注意力。每个窗口的大小为se × rese,其中se为矩形窗口的高度,re为纵横比。然后,采用小矩形窗口(大小为 1/2 se × 1/2 rese)在后续编码器层中执行注意力。编码器注意力计算如下:
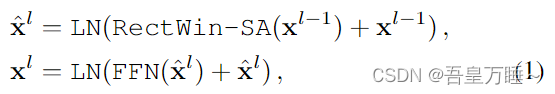 其中 xl−1 和 xl 分别是编码器层 l-1 和层 l 的输出特征。请注意,x0 使用 F 初始化。RectWin-SA、FFN 和 LN 分别表示矩形窗口自注意力、前馈网络和层归一化。得益于渐进式矩形窗口注意的设计,我们可以在线性复杂度下实现高效的计算,这在处理高分辨率图像时特别有用。编码器的详细架构可以在补充材料中找到。
其中 xl−1 和 xl 分别是编码器层 l-1 和层 l 的输出特征。请注意,x0 使用 F 初始化。RectWin-SA、FFN 和 LN 分别表示矩形窗口自注意力、前馈网络和层归一化。得益于渐进式矩形窗口注意的设计,我们可以在线性复杂度下实现高效的计算,这在处理高分辨率图像时特别有用。编码器的详细架构可以在补充材料中找到。
在矩形窗口内解码。
变压器解码器接收点查询四叉树并将图像特征编码为输入,输出解码的点查询。它通过在图像上下文的指导下对点查询之间的关系进行建模来推理人群。直观地说,我们根据周围的点查询和上下文来决定点查询是否是一个人。因此,我们建议在局部窗口内计算解码器注意力。考虑到四叉树的层次结构,我们在解码点查询时也采用了渐进式注意。
从技术上讲,稀疏点查询的注意力是在相对较大的矩形窗口中计算的(大小为 1/2 se × 1/2 rese),密集点查询的窗口大小减少到 1/4 se × 1/4 rese。特别是,解码器注意力计算如下:
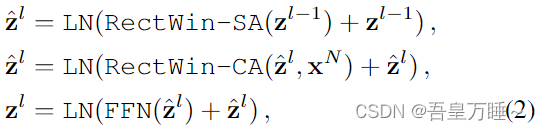 其中 xN 是变压器编码器的最终输出,zl−1 和 zl 分别是解码器层 l -1 和层 l 的输出特征。请注意,z0 使用点查询的表示进行初始化。RectWin-SA 和RectWin-CA 分别表示矩形窗口自注意力和矩形窗口交叉注意力。
其中 xN 是变压器编码器的最终输出,zl−1 和 zl 分别是解码器层 l -1 和层 l 的输出特征。请注意,z0 使用点查询的表示进行初始化。RectWin-SA 和RectWin-CA 分别表示矩形窗口自注意力和矩形窗口交叉注意力。
3.5.网络优化
五、实验结果
4.1.数据集和实现细节
4.2.主要结果


