
- 1CrossOver代替KeyGen Runner运行exe注册机的方法_crossover注册码生成器
- 2粒子群算法笔记_聚类的惯性权重是什么
- 3Vue+Openlayers创建热力图_vue +openlayer 实现热力图
- 4AIGC专栏9——Scalable Diffusion Models with Transformers (DiT)结构解析_dit模型
- 5精通 Postman:使用 POST 请求发送 JSON 数据的全面指南_postman post json
- 6FreeRTOS实时系统_xsuspendedtasklist
- 7ELK日志分析集群部署_elk8.5部署
- 8使用chatglm.cpp本地部署ChatGLM3-6B模型_glam3模型
- 9私有化部署 Llama3 大模型, 支持 API 访问_ollama3 api
- 10多线程、异步导致的时序逻辑Bug_异步时序问题
AIGC:阿里开源大模型通义千问部署与实战_通义大模型部署_通义千问开源部署
赞
踩
1 引言
通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。相较于最初开源的Qwen-7B模型,我们现已将预训练模型和Chat模型更新到效果更优的版本。本仓库为Qwen-7B预训练模型的仓库。
体验地址:https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary
代码地址:https://github.com/QwenLM/Qwen
通义千问-7B(Qwen-7B)主要有以下特点:
- 大规模高质量训练语料:使用超过2.4万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
- 强大的性能:Qwen-7B在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的相近规模开源模型,甚至在部分指标上相比更大尺寸模型也有较强竞争力。具体评测结果请详见下文。
- 覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-7B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
2 通义千问介绍
2.1 介绍
我们开源了Qwen(通义千问)系列工作,当前开源模型的参数规模为18亿(1.8B)、70亿(7B)、140亿(14B)和720亿(72B)。本次开源包括基础模型Qwen,即Qwen-1.8B、Qwen-7B、Qwen-14B、Qwen-72B,以及对话模型Qwen-Chat,即Qwen-1.8B-Chat、Qwen-7B-Chat、Qwen-14B-Chat和Qwen-72B-Chat。模型链接在表格中,请点击了解详情。同时,我们公开了我们的技术报告,请点击上方论文链接查看。
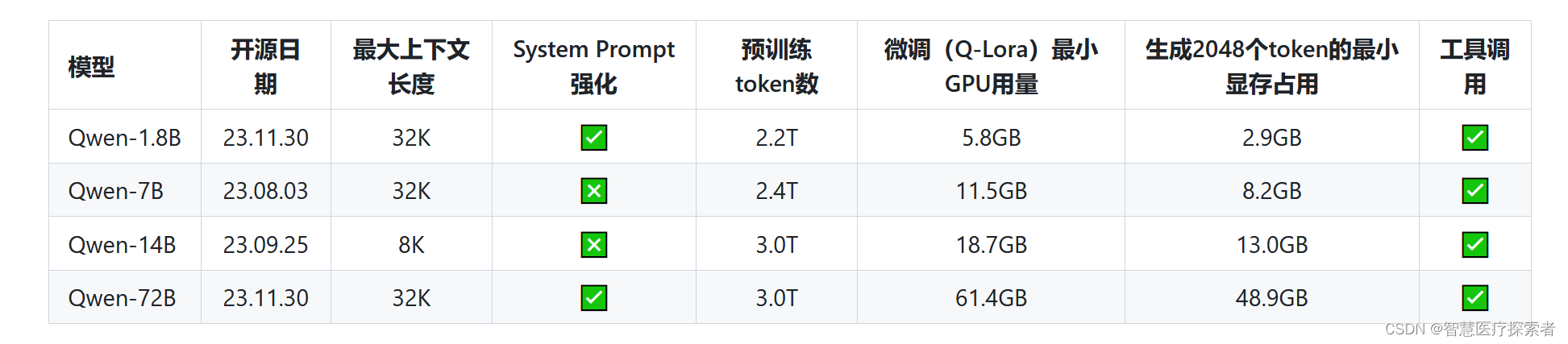
当前基础模型已经稳定训练了大规模高质量且多样化的数据,覆盖多语言(当前以中文和英文为主),总量高达3万亿token。在相关基准评测中,Qwen系列模型拿出非常有竞争力的表现,显著超出同规模模型并紧追一系列最强的闭源模型。此外,我们利用SFT和RLHF技术实现对齐,从基座模型训练得到对话模型。Qwen-Chat具备聊天、文字创作、摘要、信息抽取、翻译等能力,同时还具备一定的代码生成和简单数学推理的能力。在此基础上,我们针对LLM对接外部系统等方面针对性地做了优化,当前具备较强的工具调用能力,以及最近备受关注的Code Interpreter的能力和扮演Agent的能力。我们将各个大小模型的特点列到了下表。
在这个项目中,你可以了解到以下内容
- 快速上手Qwen-Chat教程,玩转大模型推理
- 量化模型相关细节,包括GPTQ和KV cache量化
- 推理性能数据,包括推理速度和显存占用
- 微调的教程,帮你实现全参数微调、LoRA以及Q-LoRA
- 部署教程,以vLLM和FastChat为例
- 搭建Demo的方法,包括WebUI和CLI Demo
- 搭建API的方法,我们提供的示例为OpenAI风格的API
- 更多关于Qwen在工具调用、Code Interpreter、Agent方面的内容
- 长序列理解能力及评测
- 使用协议
2.2 新闻
- 2023.11.30 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/914334
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

