
- 1Git+VsCode安装教程+Gitee进行代码管理
- 2如何搭建可正常使用的CentOS7系统虚拟机节点_centos7建立虚拟站点
- 3深入探索:【人工智能】、【机器学习】与【深度学习】的全景视觉之旅
- 42024年蓝桥杯C/C++解析(b组)_蓝桥杯2024答案b组
- 5Java 线程池 ThreadPoolExecutor 源码分析_java 线程池源码分析
- 6多模态大模型入门指南(非常详细)零基础入门到精通,收藏这一篇就够了
- 7探索协程在 C++ 中的实现方式_c++ 协程
- 8对话系统简介_对话系统主体判断
- 9spark-MLlib
- 10如何使用matplotlib绘制表格-plt.table()_plt table
Python爬虫入门教程(非常详细)_python爬虫自学_爬虫python教程
赞
踩
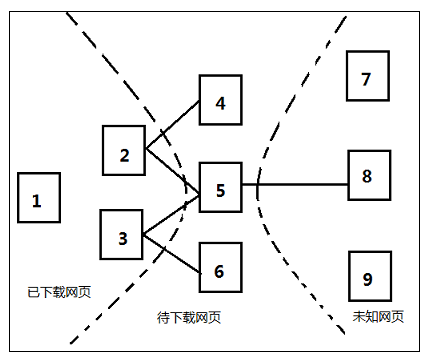
设k值为3,即每抓取3个页面后,重新计算一次PageRank值。
已知有{1,2,3}这3个网页下载到本地,这3个网页包含的链接指向待下载网页{4,5,6}(即待抓取URL队列),此时将这6个网页形成一个网页集合,对其进行PageRank值的计算,则{4,5,6}每个网页得到对应的PageRank值,根据PageRank值从大到小排序,由图假设排序结果为5,4,6,当网页5下载后,分析其链接发现指向未知网页8,这时先给未知网页8一个临时的PageRank值,如果这个值大于网页4和6的PageRank值,则接下来优先下载网页8,由此思路不断进行迭代计算。
5.OPIC策略
此算法其实也是计算页面重要程度。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数大小进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。待下载页面数多的网站优先下载。
二、爬虫的基本流程
首先简单了解关于Request和Response的内容:
Request:浏览器发送消息给某网址所在的服务器,这个请求信息的过程叫做HTTP Request。
Response:服务器接收浏览器发送的消息,并根据消息内容进行相应处理,然后把消息返回给浏览器。这个响应信息的过程叫做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示在页面上。
根据上述内容将网络爬虫分为四个步骤:
1.发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
常见的请求方法有两种,GET和POST。get请求是把参数包含在了URL(Uniform Resource Locator,统一资源定位符)里面,而post请求大多是在表单里面进行,也就是让你输入用户名和秘密,在url里面没有体现出来,这样更加安全。post请求的大小没有限制,而get请求有限制,最多1024个字节。
2.获取响应内容

