
- 1C#使用OpenCvSharp4库读取电脑摄像头数据并实时显示
- 2【新学期】双非本科大三学长经验分享_大三才学人工智能
- 3AIGC产业研究报告2023——视频生成篇
- 4idea快速创建flink项目_flink idea
- 5深度学习第一步——Pytorch-Gpu环境配置:Win11/Win10+Cuda10.2+cuDNN8.5.0+Pytorch1.8.0(步步巨细,少走十年弯路)
- 6python yield函数深入浅出理解
- 7iproute2编译安装_iproute2安装
- 8android之使用Soap协议调用webservice实现手机归属地查询_soap userid
- 9Linux系统之文件共享目录设置方法_linux设置共享目录
- 10python 领英爬虫_linkin简历数据抓取
算法面试之Roberta、Albert_roberta xxlarge版本 多少层
赞
踩
算法面试之Roberta、Albert
Roberta
RoBERTa基本没有什么太大创新,主要是在BERT基础上做了几点调整:
1)训练时间更长,batch size更大,训练数据更多;
2)移除了next predict loss;
3)训练序列更长;
4)动态调整Masking机制。
1.dynamic masking
原本的BERT采用的是static mask的方式,就是在create pretraining data中,先对数据进行提前的mask,为了充分利用数据,定义了dupe_factor,这样可以将训练数据复制dupe_factor份,然后同一条数据可以有不同的mask。注意这些数据不是全部都喂给同一个epoch,是不同的epoch,例如dupe_factor=10, epoch=40, 则每种mask的方式在训练中会被使用4次
dynamic masking: 每一次将训练example喂给模型的时候,才进行随机mask
2.No NSP and Input Format
Segment+NSP:bert style
Sentence pair+NSP:使用两个连续的句子+NSP。用更大的batch size
Full-sentences:如果输入的最大长度为512,那么就是尽量选择512长度的连续句子。如果跨document了,就在中间加上一个特殊分隔符。无NSP。实验使用了这个,因为能够固定batch size的大小。
Doc-sentences:和full-sentences一样,但是不跨document。无NSP。效果最优。
3.Text Encoding
BERT原型使用的是 character-level BPE vocabulary of size 30K,
RoBERTa使用了GPT2的 byte BPE 实现,使用的是byte而不是unicode characters作为subword的单位。
Albert
ALBERT 先通过嵌入矩阵分解和共享参数降低参数量,然后再扩大网络宽度提高参数量。整个过程就很像火箭发动机使用的拉伐尔喷管,管道一缩一放,气流就从亚音速加速到超音速
1.词向量因式分解
不管是 BERT,还是后续在 BERT 基础上改进的模型 XLNet,RoBERTa,他们的嵌入向量维度和隐藏层维度都是相等的,这样能进行残差连接的加和运算。这里以 BERT-base 为例,算下嵌入矩阵的参数量:BERT-base 的词表大小 V=30000,嵌入向量维度 E 和隐藏层维度 H 相等,都是 768,一个嵌入矩阵的参数量就是 V×E,有点大,不好顶
Albert在嵌入向量后面紧接着加了一个全连接层,把 E 映射到 H 维度

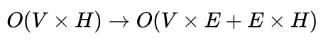
2.跨层参数共享
多头注意力和 FFN 都共享,也就是一份数据在 Transformer 的一个编码层上,来回过 12 遍
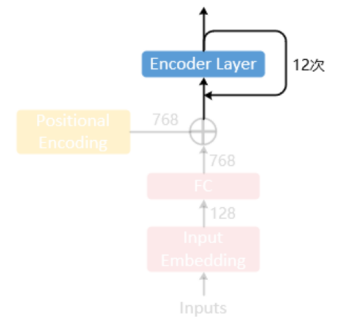
如果共享全部参数,参数量为 12M,是不共享参数时的 13%,参数量降低很多,但平均分数也同样降低很多,最开始均分 82.3,矩阵分解后降到 81.7,现在参数共享后降到 80.1
3.句子顺序预测
仔细分析 NSP 这个任务,它的正样本是选取了两个相邻的 segments,而负样本是选取了两个不同文档的 segments。所以对于模型来说,NSP 有两种方法可以解决:
1.主题预测。如果两个 segments 主题不同说明来自不同文档,进而判断为负样本。
2.连贯性预测。这是 BERT 的本意,让模型判断两个 segment 是不是邻接的。
我们希望模型学到后者,但是前者更好学,并且主题预测和 MLM 任务有些重叠了,所以导致 NSP 这个预训练任务效果不好。
ALBERT 提出了 SOP(Sentence-Order Prediction)。SOP 就是让模型预测两个相邻 segments 有没有被调换前后顺序,如下图:
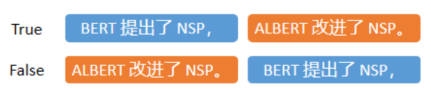
这样模型就只能通过连贯性来预测 True or False,而不会借助主题信息。
4.提分点
预训练用长句
BERT 在预训练的时候,为了加速,前 90% 的 steps 用长度为 128 的句子,而后 10% 的 steps 用长度为 512 的句子,来训练位置编码。
ALBERT 则是反过来,90%-512,10%-128。
长句能激发模型学习文档级别的表示向量,短句则是让模型学习句级的表示向量,ALBERT 用更多的长句,模型内部的向量会更高级、更抽象,所以效果有所提升。
遮挡多个连续词
ALBERT 借鉴 SpanBERT 中的方法,改进了 BERT 的 MLM 任务,每次不随机遮一个词,而是随机遮连续的多个词,连续多个词具有更完整的语义,提高了预训练的难度,有利于下游微调任务。
下一篇将介绍spanBert
扩大模型参数
用于屠榜的 ALBERT 并不是 base 配置,而是 xxlarge 配置。ALBERT-xxlarge 的平均分比 BERT-large 高了 3.5,参数量是 BERT-large 的 70%,但速度是 0.3 倍。所以可见 ALBERT 通过共享参数把参数量压下来了,但该计算的还得计算,计算量是不会减小的。
ALBERT-xxlarge 层数是 12,而不是 24,因为作者通过实验发现,当隐藏层维度是 4096 时,24 层和 12 层效果一样,也就是说模型到达了深度极限。
增加预训练数据
BERT 使用的预训练数据是 Wikipedia 和 BOOKCORPUS 两个数据集,而 ALBERT 使用了 XLNet 和 RoBERTa 中都使用到的额外预训练数据集
去掉 Dropout 层
因为共享参数降低了参数量,参数量下降对模型来说是一种正则化,所以这个时候再搭配 Dropout 效果就会下降,因为有点过度正则化了。ALBERT 在去掉 Dropout 后,平均分数提高了0.3
上一篇:算法面试之BERT细节
下一篇:算法面试之SpanBERT
注:本专题大部分内容来自于总结,若有侵权请联系删除。
- 记录一下embedding_lookup根据词的索引来获取embedding输入是[batch_size,seq_lenth]输出[batch_size,seq_lenth,embeding_size]defembedding_lookup... [详细]
赞
踩
- STM32F103C8T6智能小车舵机超声波避障使用舵机带动超声波转动不同角度,完成左右前三个方向的距离测量、判断后完成避障注意点:1、以下代码没有给出延时(Delay)和小车行进(MotorRun)部分的代码,他们比较简单,受篇幅限制这里... [详细]
赞
踩
- 基于STM32f103c8t6的简单红外循迹避障小车制作_超声避障小车单机模块stm32f103c8t6超声避障小车单机模块stm32f103c8t6目录一、硬件部分1、模块选择(1)电源(2)车模(3)电机(4)巡迹及避障(5)其它2、硬... [详细]
赞
踩
- 了解到5G网络优化工程师也是偶然的机会,在某红平台上看到这个行业,适合0基础人群,所学的内容对数学和逻辑要求不高,大部分是实操和理论知识。自己很心动,也去搜集很多资料,后来进一步了解到,他的校区就在武汉,离我的学校很近。也很感激优橙教育的老... [详细]
赞
踩
- 打包失败截图:1、证书找不到NOcertificatematching‘‘for‘’codesingingisrequired….由于更新过证书配置,导致新证书没有导入到Jenkins中。配置步骤:Jenkins-系统管理-keychain... [详细]
赞
踩
 本文主要讲解了线性表和顺序表的定义,并结合图文对顺序表的基本操作进行了实现,更多精彩内容等你来浏览。【图解数据结构】顺序表实战指南:手把手教你详细实现(超详细解析)... [详细]
本文主要讲解了线性表和顺序表的定义,并结合图文对顺序表的基本操作进行了实现,更多精彩内容等你来浏览。【图解数据结构】顺序表实战指南:手把手教你详细实现(超详细解析)... [详细]赞
踩
- 菜单界面有五个功能选择按钮:1、电子相册,进入后可以选择手动播放和自动播放照片,照片切换时会有ppt动画,点击中间的“电子相册”可以返回菜单界面。2、语音识别(没有做)3、监控系统,点击进入后右边会有“打开相机”“录像”“播放”“拍照”“返... [详细]
赞
踩
- 如何在window安装Docker_docker安装win10docker安装win10在Windows10上安装Docker分为两种方式:使用DockerDesktopforWindows和安装Docker工具包。以下是两种方式的详细说明... [详细]
赞
踩
- Windows11安装提示此电脑必须支持TPM2.0/ThePCmustsupportTPM2.0安装win11时如果有以上提示可将镜像根目录中的appraiserres.dll替换为win10的appraiserres.dllapprai... [详细]
赞
踩
- 校园管理小程序开发的学习_宿舍报修小程序宿舍报修小程序一,老规矩先看效果图1-1小程序端登录页注册页首页校园资讯新闻详情校园论坛校园表白墙失物招领帖子详情和评论个人中心宿舍教室维修报修填写信息我的维修订单饭卡充值支付可选择充值金额,由于我们... [详细]
赞
踩
- ps-aux|sort-r-g-k5|sed-n'$p'&&ps-aux|sort-r-g-k5|sed-n'1,10p'1.CPU占用最多的前10个进程:psauxw|head-1;psauxw|sort-rn-k3|head-102.内... [详细]
赞
踩
- 楔子说起读开源项目源码,很多朋友觉得高大上、大佬牛逼,云云~挡在很多人面前的不是源码怎么读,而是不知道如何导入源码到开发工具以及如何调试源码。本文将以spring-cloud-gateway源码导入一个简单的SpringBoot项目中举例,... [详细]
赞
踩
- 点击蓝色的小球。idea打包跳过测试IDEA操作点击蓝色的小球手动命令mvncleanpackage-Dmaven.test.skip=true1#下载源码多版本docker&dockercompose的快速安装_18一20docker18一20dockerUbuntu(18,20,21)多版本docker&dockercompose的快速安装多版本Ub... [详细]
赞
踩
- 纯净版虚拟机配置,安装docker,mysql等,镜像打包_centos部署网心云centos部署网心云系统内核要求3.1以上虚拟机网络配置vi/etc/sysconfig/network-scripts/ifcfg-ens33 ... [详细]
赞
踩
- 1、需求分析测试目的:为什么测?目的在于测试系统相关性能能否满足业务需求。通常分以下两种情况:1)新项目上线2)老项目优化如果是老项目优化,可考虑是否存有历史测试方案,如果有可以参考,或许可以省事很多。测试对象:要测啥?测试对象可以归结为“... [详细]
赞
踩
- 目录1、使用背景2、操作步骤2.1、查看记录Fiddler安装负载机的ip2.2、确保电脑,手机在同一个局域网内2.3、设置fiddler2.4、手机wifi设置3、开始测试1、使用背景测试的时候,有时候需要对某个app进行流量数据抓包,进... [详细]
赞
踩
- Unity游戏实例开发集合之FlyPin(见缝插针)休闲小游戏快速实现目录Unity游戏实例开发集合之FlyPin(见缝插针)休闲小游戏快速实现一、简单介绍二、FlyPin(见缝插针)游戏内容与操作三、游戏代码框架四、知识点五、游戏效果预览... [详细]
赞
踩

