- 12023华为OD面试手撕真题【最长的连续绿色衣服的士兵】_华为面试手撕
- 2SRC漏洞挖掘--CNVD国家信息安全漏洞共享平台
- 3VC++界面编程之--仿Facebook透明登录窗口_[main_dlg.xml] - change state to retry
- 4OpenHarmony实战:烧录Hi3516DV300开发板
- 5内存溢出的几种原因和解决方法_解决内存溢出
- 6el-upload与springboot使用_el-upload springboot
- 7Python实现飞书机器人定时发送文本、图片等群消息_飞书机器人发送图片
- 8七. 图像生成文本
- 9SQL Server 中,删除表数据有以下几种方式_sql sever删除表格中的数据
- 10基于SpringBoot+Vue高校奖助学金系统设计和实现(源码+LW+部署讲解)
Transformer模型架构解析_add&norm模块
赞
踩
参考:
https://www.bilibili.com/video/BV1UL411g7aX/?spm_id_from=333.880.my_history.page.click&vd_source=de203b26ba8599fca1d56a5ac83a051c
一、什么是Transformer
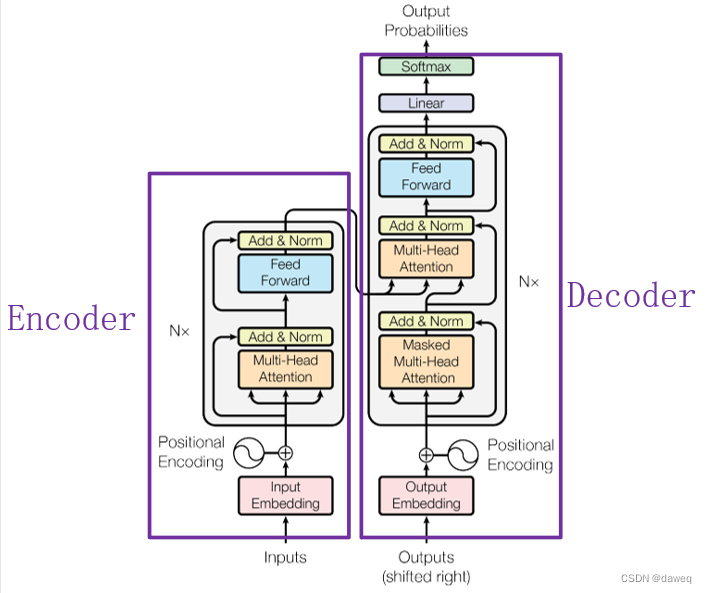
Transformer和RNN,CNN不一样,整个网络结构完全由Attention机制以及前馈神经网络组成。
上述的图的Transformer可以说是一个使用“self attention”的Seq2seq模型(原论文)。
二、详细解析Transformer
(1)Encoder部分
Input:数据输入
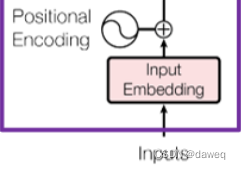
Input Embedding:将输入的词构成词向量。
如:我(-1.2188,1.1676,-1.0574,-0.1188)
很(-0.9078,0.3452,-0.5713,-0.2351)
好(1.0076,-0.7529,-0.225,-0.4327)
(4维只是为了便于理解,实际上维度很高)
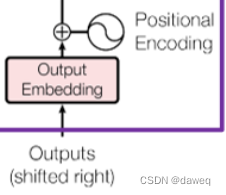
Positional Encoding:
Positional Encoding是维度和输入相同的向量,它的作用是用很小的数值去区分每一个词行向量。(在传统RNN模型中,一句话的词向量是一个一个词理解的,而在Transformer模型中,一句话的所有词是一起输入进去的)。具体来说这里是用的余弦和正弦函数去区分偶数位和奇数位的词。在Input Embedding与Positional Encoding相加后,输出相同维数的向量。
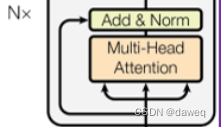
Multi-Head Attention:
这是一种注意力机制,Multi-Head指有多个self-attention head。这里一共有两个,所以需要将输入词向量拆成两份,具体来说:
我(-1.2188,1.1676,-1.0574,-0.1188)
很(-0.9078,0.3452,-0.5713,-0.2351)
好(1.0076,-0.7529,-0.225,-0.4327)
可以拆(-1.2188,1.1676,),(-0.9078,0.3452),(1.0076,-0.7529)
和(-1.0574,-0.1188),(-0.5713,-0.2351),(-0.225,-0.4327)
即将数据从一个层面切断。
在拆分后,将数据复制三份,分别作为"value",“key”,"query"三种数据同时传入。
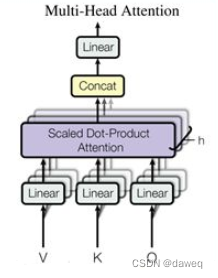
“value”,“key”,"query"三种数据传入后,第一步是分别进入一个线性层后,再通过一个Scaled Dot-Product Attention模块。这里这个模块的具体构造是:
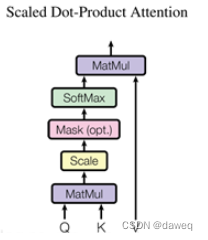
“value”,“key”,"query"的大小分别是3x2,3x2,3x2。(按照我很好这个例子)。MatMul首先将query和key矩阵进行矩阵乘法得到3x3的矩阵,经过Scale模块,它的效果是所有矩阵元素/根号下dmodel。dmodel是词向量的长度,这个例子下是4。再经过softMax后与value进行矩阵乘法。得到一个3x2矩阵。
将两个head计算的矩阵重新Concat成一个3X4的矩阵,再经过一个线性层,输出。
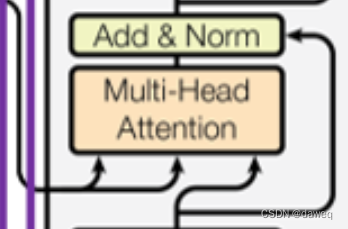
Add&Norm模块首先将Attention后的向量和初始未经Attention的向量做加法,然后经过一个layer norm模块,最后输出的还是一个4x3的数据(即矩阵大小不变,在这个模块里也有可以训练的参数)。

接下来的模块Feed Forward是一个前馈网络,是许多线性层和激活层组合在一起的,前馈后再进行一个Add&Norm模块。
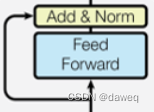
所以最后输出的数据是一个4x3的矩阵。
(2)Decoder部分
首先我们要知道在这个模型中,一个样本是一组数据构成的比如这个例子的样子是{我很好,I am fine}。按理说在output时,是从起始Token出发一个词一个词输入,但是我们也可以把它设定成一个矩阵,一起输入。具体可以参考https://blog.csdn.net/anshiquanshu/article/details/112384896这篇文章中decoder的描述。
输入起始Token----->预测第一个单词(与第一个单词做交叉熵损失)----->Token和第一个单词一起----->预测第二个单词(与第二个单词做交叉熵损失)----->……
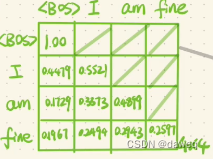
这里和Encoder的第一部分类似,只是这里是Masked Attention。这里的mask是sequence mask它只在Decoder中才用到,它是为了使得decoder看不到后续的数据,因为解码只能依赖于t和t之前的的输出,不能依赖t后的。
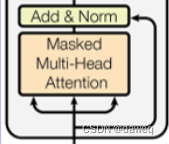
输出,所以我们要把后面的信息隐藏起来,具体的做法就是如下图。
这里将decoder中的数据作为query,再将encoder中的输出拿来做value和key。经过Multi-Head Attention后,经过Add&Norm后经过前馈网络,最后经过一个线性层和softmax层输出预测结果。