
- 1设计模式之代理模式
- 2《数据结构》C语言版(清华严蔚敏考研版) 全书知识梳理 + 练习习题详解(超详细清晰易懂)_严蔚敏《数据结构》(c语言版)典型习题和考研真题详解
- 3git如何使用代理clone
- 4Chrome浏览器http自动跳https问题_谷歌http跳转问题
- 5Hadoop配置集群的详细步骤_(==首次启动==)格式化namenode ```shell hdfs namenode -form
- 6【MySQL】数据库排查慢查询、死锁进程排查、预防以及解决方法_mysql查询死锁进程
- 7pip install遇到OSError错误_pip 安装os
- 8C语言—数组详解_数组c语言
- 9免费版NAC预览_natshell免费版
- 10Spring源码:Spring EL表达式源码分析_beanexpressionresolver
关键点匹配
赞
踩
要看的文章:SpyNet [31], PWC-Net [38] and LiteFlowNet [14],SelFlow(自监督)
能检测遮挡的光流:
UnFlow: Unsupervised learning of optical flow with a bidirectional census loss
Occlusion aware unsupervised learning of optical flow
Unsupervised learning of multi-frame optical flow with occlusions
Ddflow: Learning optical flow with unlabeled data distillation
Back to basics:Unsupervised learning of optical flow via brightness constancy and motion smoothness
Unsupervised deep learning for optical flow estimation
. Unsupervised monocular depth estimation with left-right consistency.
Optical flow estimation with channel constancy. 2014ECCV
-
Image quality assessment:from error visibility to structural similarity. 2004
-
Learning dense correspondence via 3d-guided cycle consistency 2016 CVPR
Convolutional neural network architecture for geometric matching CVPR 2017
SIFT+RANSAC的进化版:
更好的特征描述:Superpoint: Self-supervised interest point detection and description. 2018
Geometric image correspondence verification by dense pixel matching 2019
Geodesc:Learning local descriptors by integrating geometry constraints. 2018
Working hard to know your neighbor’s margins: Local descriptor learning loss NIPS2017
R2d2: Reliable and repeatable detector and descripto NIPS 2019
L2-net: Deep learning of discriminative patch descriptor in euclidean space CVPR 2017
RANSAC:Learning two-view correspondences and geometry using order-aware network ICCV 2019
Deep fundamental matrix estimation ECCV 2018
Pointnet: Deep learning on point sets for 3d classification and segmentation CVPR 2017
Neural nearest neighbors networks NIPS 2018
跨模态的匹配:
Unsupervised discovery of mid-level discriminative patches ECCV 2012 使用中间层的特征对于跨模态的匹配效果更好
Painting-to-3D Model Alignment Via Discriminative Visual Elements (代码:https://www.di.ens.fr/willow/research/painting_to_3d/)
Discovering Visual Patterns in Art Collections with Spatially-consistent Feature Learning CVPR 2019
光流:
Flow Fields: Dense Correspondence Fields for Highly Accurate Large Displacement Optical Flow Estimation 大范围光流场估计 2015ICCV
使用局部特征进行光流匹配:Large displacement optical flow CVPR 2009
: Epicflow: Edge-preserving interpolation of correspondences for optical flow
Flow fields: Dense correspondence fields for highly accurate large displacement optical flow estimation
: Efficient coarse-to-fine patchmatch for large displacement optical flow
超越视觉相似性的光流:SIFTFlow,FlowWeb: Joint Image Set Alignment by
Weaving Consistent, Pixel-wise Correspondences
Do Convnets Learn Correspondence?
Universal correspondence network
Neighbourhood consensus networks
深度光流:Geonet: Unsupervised learning of dense depth, optical flow and camera pose
Learning correspondence from the cycle-consistency of time CVPR 2019
: Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume CVPR 2018
Dgc-net: Dense geometric correspondence network
Geometric image correspondence verification by dense pixel matching
making convolutional networks shift-invariant again
1、立体匹配算法主要可分为两大类:基于局部约束和基于全局约束的立体匹配算法.
(一)基于全局约束的立体匹配算法:在本质上属于优化算法,它是将立体匹配问题转化为寻找全局能量函数的最优化问题,其代表算法主要有图割算法、置信度传播算法和协同优化算法等.全局算法能够获得较低的总误匹配率,但算法复杂度较高,很难满足实时的需求,不利于在实际工程中使用.
(二)基于局部约束的立体匹配算法:主要是利用匹配点周围的局部信息进行计算,由于其涉及到的信息量较少,匹配时间较短,因此受到了广泛关注,其代表算法主要有 SAD、SSD、NCC等
1.SuperGlue: Learning Feature Matching with Graph Neural Networks(2020)
使用新的架构(superGlue)来学习特征点间的匹配的过程(图神经网络GNN),而不是学习局部特征。但是,这篇文章内部真的没有看懂。
代码路径:https://github.com/magicleap/SuperGluePretrainedNetwork

网络结构:

代码:
(1)keypoint encoder
对应于文中
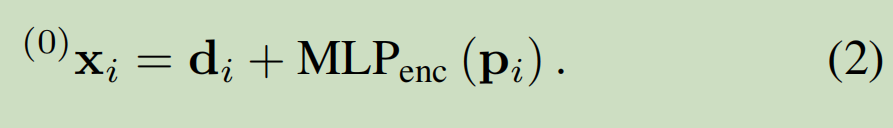
self.config['descriptor_dim']的默认值为[256], self.config['keypoint_encoder']的默认值为[32, 64, 128, 256]
self.kenc = KeypointEncoder(self.config['descriptor_dim'], self.config['keypoint_encoder'])
def __init__(self, feature_dim, layers):
self.encoder = MLP([3] + layers + [feature_dim]) #self.encoder = MLP([3] +self.config['keypoint_encoder'] + [self.config['descriptor_dim']]),所以self.encoder = MLP[3,32, 64, 128, 256,256]
其中,MLP是多个1维的卷积,类似于FC,从通道3(x,y,c)依次变为通道[32, 64, 128, 256],再变为256 descriptor_dim。
layers.append( nn.Conv1d(channels[i - 1], channels[i], kernel_size=1, bias=True))
desc0 = desc0 + self.kenc(kpts0, data['scores0'])
def forward(self, kpts, scores):
inputs = [kpts.transpose(1, 2), scores.unsqueeze(1)]
return self.encoder(torch.cat(inputs, dim=1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- Graph Neural Network with multiple self and cross-attention layers
默认值:self.config['descriptor_dim']=256,self.config['GNN_layers']= ['self', 'cross'] * 9, self.gnn = AttentionalGNN( self.config['descriptor_dim'], self.config['GNN_layers']) self.layers = nn.ModuleList([ AttentionalPropagation(feature_dim, 4) for _ in range(len(layer_names))]) #len(layer_names)=18, AttentionalPropagation(feature_dim, 4) self.attn = MultiHeadedAttention(num_heads, feature_dim) #MultiHeadedAttention(4, 256) self.dim = d_model // num_heads #256//4=64 self.num_heads = num_heads #4 self.merge = nn.Conv1d(d_model, d_model, kernel_size=1) #nn.Conv1d(256, 256, kernel_size=1) self.proj = nn.ModuleList([deepcopy(self.merge) for _ in range(3)]) forward的时候:def forward(self, query, key, value): query, key, value = [l(x).view(batch_dim, self.dim, self.num_heads, -1)for l, x in zip(self.proj, (query, key, value))] #self.merge( self.mlp = MLP([feature_dim*2, feature_dim*2, feature_dim]) #MLP([256*2, 256*2, 256]) desc0, desc1 = self.gnn(desc0, desc1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.Flow2Stereo: Effective Self-Supervised Learning of Optical Flow and Stereo Matching
采用自监督的方式,能够使用两个时间(t,t+1)和两个视角的4张图像,估计出图像间的光流和立体视差。
(1)首先,计算两个时间(t,t+1)和两个视角的4张图像,他们之间所满足的四边形限制和三角形限制
(2)采用两阶段的策略,teacher model和student model,其中teacher model阶段的损失函数为Photometric loss(基于:对于没有遮挡的像素的亮度一致性假设),三角形限制和四边形限制;student model阶段的损失函数为自监督损失(基于teacher model预测的光流和confidence map)
四边形限制和三角形限制的计算:


两阶段的网络:

3. Ddflow: Learning optical flow with unlabeled data distillation
(1)在无监督学习中,使用亮度一致性构建损失函数是合理的,但是这条法则并不适用于有遮挡的像素
(2)所以,首先训练teacher model。其中,在训练teacher model时可以根据前项光流和后项光流的不一致性识别被遮挡的像素(这个假设不是完全成立的)。训练teacher model时只使用了亮度一致性损失
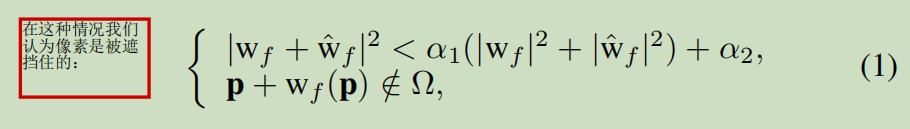
(3)训练完teacher model后,训练student model。对于有遮挡的地方,采用teacher model的预测结果作为label,计算损失。对于没有遮挡的地方,使用亮度一致性损失。

5.UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss
(1)定义被遮挡的区域:因为遮挡区域不满足亮度一致性假设,所以单独处理被遮挡的区域。我们假设对于没有遮挡的区域,前向flow(I1->I2)应该是后向flow(I2->I1)的inverse,而对于遮挡的区域,即为此条假设不成立的地方:
(2)对于没有遮挡的区域,自监督的损失由3部分组成:亮度一致性损失ED,光流平滑性ES(smooth),前后向光流的一致相反性EC.对于被遮挡的区域,只计算光流平滑性损失。
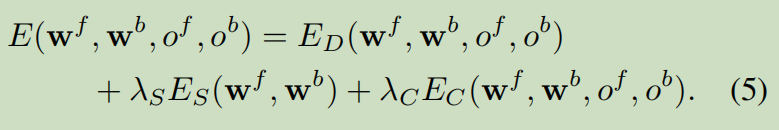

(3)在计算损失时,因为在网络中采用了金字塔结构,所以我们对每层都计算损失并加权
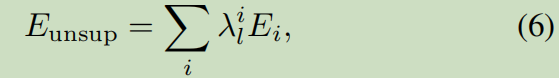

6. Occlusion aware unsupervised learning of optical flow
(1)指出当前无监督的算法中,因为不能很好的处理遮挡和大的运动,导致算法表现能力较差。遮挡使得我们不能完整的重建ref Image.

(2)网络的整体框架
计算occlusion map(O:为0的像素表示在I1中存在,在I2中不存在):判定是否为occlusion的思想:上图的Image2根据backward flow倒推为warped Image1时,warped Image1中有哪些位置的像素不会被填补,这些没有像素被填补的地方记为occluded(只在Image1中存在,Image2中不存在)。当然,warped Image1中某些位置的像素不会填补多次。

无监督的损失项包括亮度一致性损失和光流平滑性损失。其中亮度一致性损失只在non-occluded的像素计算,且计算亮度和图像梯度。光流平滑性损失对整张图计算,包括1阶导数和二阶导数。

Alibaration study中指出直方图均衡化增强图像对比度也能提高效果。
Back to basics:Unsupervised learning of optical flow via brightness constancy and motion smoothness 和 Unsupervised deep learning for optical flow estimation
没有考虑遮挡,用简单的计算光流+warp+brightness loss的方式,来自监督的学习光流
3.RANSAC-Flow

SSIM相似性
(1)第一步:用稀疏特征点+ransac进行粗略匹配:conv4 layer of ResNet-50 network作为提取图像的特征,来获取image pairs中对应的匹配点;在多种尺度上寻找匹配点,在哥哥尺度上不一致的匹配点被除去;
(2)第二步:使用光流对已粗匹配的图像进行细匹配。
2.1:因为每次homography对齐,只有一部分区域被对齐,所以我们希望光流只对这部分进行改善。所以我们引入M(matchability mask)
2.2:损失函数的构成:reconstrcution loss+cycle-consistency loss+matchabilitiy loss,一半计算光流还有smooth loss
reconstrcution loss:使用sturctural similarity(SSIM)作为鲁邦的评价(这里一般光流使用强度损失,为了避免亮度影响使用强度梯度损失,进一步可以用SIFT-flow特征损失),此处用SSIM
cycle-consistency loss: source->target的光流与target->source的光流具有可逆性。这个性质只针对没有遮挡的地方,所以有些研究专门计算遮挡的地方,来排除遮挡的地方的损失
matchability loss:这个损失时为了避免matchability mask过小
优化上述损失函数的方法:构建数据集,用无监督的方式训练深度学习网络
训练时,首先用ResNet18的conv3获得输入图像的特征图,记特征图大小为WH,将source的特征图每个位置都与target对应特征图周围77的位置求向量相似性(向量余弦相似性),从而得到WH49的特征图(49为通道数),然后将WH49的特征图送入全卷积中计算光流flow和Mask
可以与FlowNet中预测光流的方式做比较:
(3)使用上述的(1)和(2)迭代优化:每次迭代时,获取的匹配点中,将已经是前面的homographyies的内点的匹配点去除,将落在前面所有的M中的匹配点去除,用剩下的匹配点计算ransac,做光流对齐。这个步骤会持续几次,直到找不到足够的匹配点
进一步对loss的说明:
(1)SSIM:参考https://zhuanlan.zhihu.com/p/67199699 用于评价两幅图像的相似性
目的:尽量设计一个能体现结构上的相似程度的量
SSIM是基于局部图案的亮度、对比度进行计算的。

